循环依赖详解及解决方案

介绍
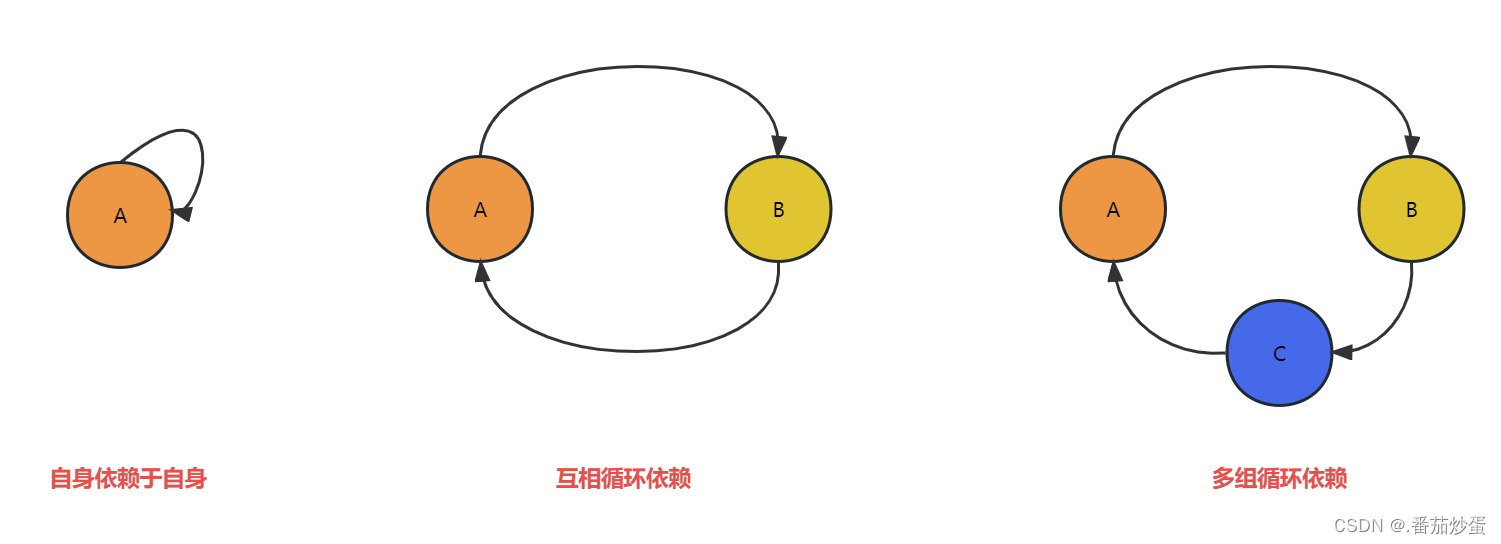
上图就是循环依赖的三种情况,虽然方式不同,但是循环依赖的本质是一样的,就A的完整创建要依赖与B,B的完整创建要依赖于A,相互依赖导致没办法完整创建造成失败.
循环依赖代码演示
public class Demo {public static void main(String[] args) {new Demo1();}
}class Demo1{private Demo2 demo2 = new Demo2();
}class Demo2 {private Demo1 demo1 = new Demo1();
}

上述代码就是最基本的循环依赖的场景,Demo1依赖Demo2,Demo2依赖Demo1,然后就报错了,而上面的这种设计情况是无解的.
分析问题
首先我们要明确一点就是如果这个对象A还没创建成功,在创建的过程中要依赖另一个对象B,而另一个对象B也是在创建中要依赖对象A,这种肯定是无解的,这时我们就要缓缓思路,我们先把A创建出来,但是还没有完成初始化操作,也就是这是一个半成品对象,然后再赋值的时候提前把A暴露出来,然后创建B,让B创建完成后找到暴露出来的A完成整体的实例化,这时再把B交给A完成A的后续操作.从而解决循环依赖,也就是下图:

代码解决
public class Demo {/* 保存提前暴露的对象,也就是半成品对象*/private final static Map<String, Object> singletonObjects = new ConcurrentHashMap<>();public static void main(String[] args) throws Exception {System.out.println(getBean(Demo1.class).getDemo2());System.out.println(getBean(Demo2.class).getDemo1());}private static <T> T getBean(Class<T> clazz) throws Exception {// 获取beanNameString beanName = clazz.getName().toLowerCase();// 查找缓存中是否存在半成品对象if (singletonObjects.containsKey(beanName)) {return (T) singletonObjects.get(beanName);}// 缓存中不存在半成品对象,反射进行实例化T res = clazz.newInstance();// 将实例化后的对象储存到缓存singletonObjects.put(beanName, res);// 获取所有属性Field[] fields = res.getClass().getDeclaredFields();// 循环进行属性填充for (Field field : fields) {// 针对private修饰field.setAccessible(Boolean.TRUE);// 获取属性类型Class<?> fieldClazz = field.getType();// 获取属性beanNameString filedBeanName = fieldClazz.getName().toLowerCase();// 属性填充,查找缓存是否有对应属性,没有就递归调用field.set(res, singletonObjects.containsKey(filedBeanName) ? singletonObjects.get(filedBeanName) : getBean(fieldClazz));}return res;}
}class Demo1 {private Demo2 demo2;public Demo2 getDemo2() {return demo2;}public void setDemo2(Demo2 demo2) {this.demo2 = demo2;}
}class Demo2 {private Demo1 demo1;public Demo1 getDemo1() {return demo1;}public void setDemo1(Demo1 demo1) {this.demo1 = demo1;}
}

在上面的方法中核心就是getBean方法,Demo1创建后填充属性时依赖Demo2,那么就去创建Demo2,在创建Demo2开始填充时发现依赖Demo1,但此时Demo1这个半成品对象已经放在缓存singletonObjects中了,所以Demo2正常创建,再结束递归把Demo1也创建完整了.

Spring循环依赖
针对Spring中Bean对象的各种场景,支持的方案不一样
- 单例
- 构造注入:无解,避免栈溢出,需要检测是否存在循环依赖的情况,如果有直接抛异常
- 设值注入:三级缓存–>提前暴露
- 原型
- 构造注入:无解,避免栈溢出,需要检测是否存在循环依赖的情况,如果有直接抛异常
- 设置注入:不支持循环依赖
Spring是如何解决循环依赖问题的?上述代码中对象的生命周期就两个:创建对象和属性填充,而Spring涉及到对象生命周期的方法就很多了,简单举例,如下图:

基于对上述代码的了解,我们知道肯定需要在调用构造方法创建完成后再暴露对象,再Spring中提供了三级缓存来处理这个事情,如下图:

对应到源码中具体处理循环依赖的流程如下:

上面就是Spring的生命周期方法和循环依赖出现相关的流程了.下面就是放入三级缓存的源码:
/* 添加对象到三级缓存 @param beanName* @param singletonFactory*/
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {// 确保singletonFactory不为nullAssert.notNull(singletonFactory, "Singleton factory must not be null");// 使用singletonObjects进行加锁,保证线程安全synchronized (this.singletonObjects) {//如果singletonObjects缓存中没有该对象if (!this.singletonObjects.containsKey(beanName)) {// 将对象放置到singletonFactories(三级缓存)中this.singletonFactories.put(beanName, singletonFactory);// 从earlySingletonObjects(二级缓存)中移除该对象this.earlySingletonObjects.remove(beanName);// 将beanName添加到已经注册的单例集中this.registeredSingletons.add(beanName);}}
}
放入二级缓存的源码:
/* 返回在给定名称下注册的(原始)单例对象.检查已经实例化的单例,并允许对当前创建的单例进行早期引用(解决循环引用) @param beanName* @param allowEarlyReference* @return*/
protected Object getSingleton(String beanName, boolean allowEarlyReference) {// 不需要完全获取单例锁的情况下快速检查现有实例Object singletonObject = this.singletonObjects.get(beanName);// 如果单例对象为空,并且当前单例正在创建中,则尝试获取早期单例对象if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {singletonObject = this.earlySingletonObjects.get(beanName);// 如果早期单例对象为空,并且允许早期引用,则再完全获取单力所的情况下创建早期单例对象if (singletonObject == null && allowEarlyReference) {synchronized (this.singletonObjects) {// 检查早期单例对象是否存在singletonObject = this.singletonObjects.get(beanName);// 如果早期对象仍然为空则创建单例对象if (singletonObject == null) {// 从二级缓存获取singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null) {// 获取不到对象从三级缓存中获取ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);if (singletonFactory != null) {singletonObject = singletonFactory.getObject();// 获取到添加到二级缓存并从三级缓存中移除该对象this.earlySingletonObjects.put(beanName, singletonObject);this.singletonFactories.remove(beanName);}}}}}}return singletonObject;
}
放入一级缓存中的源码:
/* 将单例对象添加到一级缓存 @param beanName* @param singletonObject*/
protected void addSingleton(String beanName, Object singletonObject) {// 使用singletonObjects进行加锁,保证线程安全synchronized (this.singletonObjects) {// 将映射关系添加到一级缓存this.singletonObjects.put(beanName, singletonObject);// 从三级缓存;二级缓存中移除该对象this.singletonFactories.remove(beanName);this.earlySingletonObjects.remove(beanName);// 将beanName添加到已经注册的单例集中this.registeredSingletons.add(beanName);}
}
总结
三级缓存分别有什么作用
- singletonObjects:缓存经过了完整生命周期的bean
- earlySingletonObjects:缓存未经过完整生命周期的bean,如果某个bean出现了循环依赖,就会提前把这个暂时未经过完整生命周期的bean放入earlySingletonObjects中,如果这个bean要经过AOP,那么就会把代理对象放入到earlySingletonObjects中,否则就是把原始对象放入earlySingletonObjects,但是不管怎么样就是代理对象,代理对象所代理的原始对象也是没有经过完整生命周期的,所以放入earlySingletonObjects我们就可以统一认为是未经过完整生命周期的bean
- singletonFactories:缓存的是一个ObjectFactory,也就是一个Lambda表达式,在每个bean的生成过程中,经过实例化得到一个原始对象后,都会提前基于原始对象暴露一个Lambda表达式,并保存到三级缓存中,这个Lambda表达式可能用到,也可能用不到, 如果当前bean没有出现循环依赖,那么这个Lambda表达式就没有用,当前bean按照自己的生命周期正常执行,执行完直接把当前bean放入singletonObjects中,如果当前bean在依赖注入时出现了循环依赖,则从三级缓存中拿到Lambda表达式,并执行Lambda表达式得到一个对象,并把得到的对象放入到二级缓存(如果当前bean需要AOP,那么执行Lambda表达式,得到的就是对应的代理对象,如果无需AOP,则直接得到一个原始对象)
- 其实还要一个缓存,用来记录某个原始对象是否进行过AOP了
为什么需要三级缓存
如果A的原始对象注入给B的属性之后,A的原始对象进行了AOP产生了一个代理对象,此时就会出现,对于A而言,它的bean对象应该是AOP之后的代理对象,而B的a属性对应的不是AOP之后的代理对象,这就产生了冲突,B依赖的A和最终的A不是同一个对象,三级缓存主要处理的是AOP的代理对象,存储的是一个ObjectFactory