【NLP实战】基于Bert和双向LSTM的情感分类【下篇】

文章目录
- 前言
- 简介
- 第一部分
-
- 关于pytorch lightning保存模型的机制
- 关于如何读取保存好的模型
- 完善测试代码
- 第二部分
-
- 第一次训练出的模型的过拟合问题
- 如何解决过拟合
- 后记
前言
本文涉及的代码全由博主自己完成,可以随意拿去做参考。如对代码有不懂的地方请联系博主。
博主page:issey的博客 - 愿无岁月可回首
本系列文章中不会说明环境和包如何安装,这些应该是最基础的东西,可以自己边查边安装。
许多函数用法等在代码里有详细解释,但还是希望各位去看它们的官方文档,我的代码还有很多可以改进的方法,需要的函数等在官方文档都有说明。
简介
本系列将带领大家从数据获取、数据清洗,模型构建、训练,观察loss变化,调整超参数再次训练,并最后进行评估整一个过程。我们将获取一份公开竞赛中文数据,并一步步实验,到最后,我们的评估可以达到排行榜13位的位置。但重要的不是排名,而是我们能在其中学到很多。
本系列共分为三篇文章,分别是:
- 上篇:数据获取,数据分割与数据清洗
- 中篇:模型构建,改进pytorch结构,开始第一次训练
- 下篇:测试与评估,绘图与过拟合,超参数调整
本文为该系列第三篇文章,也是最后一篇。本文共分为两部分,在第一部分,我们将学习如何使用pytorch lightning保存模型的机制、如何读取模型与对测试集做测试。第二部分,我们将探讨前文遇到的过拟合问题,调整我们的超参数,进行第二轮训练,并对比两次训练的区别。我们还将基于pytorch lightning实现回调函数,保存训练过程中val_loss最小的模型。最后,将我们第二轮训练的best model进行评估,这一次,模型在测试集上的表现将达到排行榜第13位。
第一部分
关于pytorch lightning保存模型的机制
官方文档:Saving and loading checkpoints (basic) — PyTorch Lightning 2.0.1 documentation
简单来说,每次用lightning进行训练时,他都会自动保存最近epoch训练出的model参数在checkpoints里。而checkpoints默认在lightning_logs目录下。
你还可以同时保存某次训练的参数,或者写回调函数改变它保存模型的机制(这个我们待会儿会用到)。当然你也可以设置不让它自动保存模型。这一切都在官方文档里。博主就不细讲这些细节了,建议读者自己做实验。
现在我们知道了重要的两件事:
- 默认情况下,它会自动保存最近一次epoch训练结束后的模型。
- 我们只需要写回调函数,就可以改变它保存模型的机制。
关于如何读取保存好的模型
官方文档:Deploy models into production (basic) — PyTorch Lightning 2.0.1 documentation
根据文档,你还可以不用pytorch lightning,将模型读取到单纯的pytorch中,也可以使用。
感觉这部分讲的有点水?因为都在文档里,感觉没有需要逐一说明的地方。
现在,完善我们进行测试的代码。
完善测试代码
有几点需要说明:我们在测试时还计算了常用的评估标准:acc,recall,pre,f1。这里博主将通常需要用到的评估标准写法逐一列出了。我是根据函数说明一点一点摸索出来的,所以一并写出来方便以后用。
import torch
from datasets import load_dataset # hugging-face dataset
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import torch.nn as nn
from transformers import BertTokenizer, BertModel
import torch.optim as optim
from torch.nn.functional import one_hot
import pytorch_lightning as pl
from pytorch_lightning import Trainer
from torchmetrics.functional import accuracy, recall, precision, f1_score # lightning中的评估
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
from pytorch_lightning.callbacks import ModelCheckpoint# todo:自定义数据集
class MydataSet(Dataset):def __init__(self, path, split):self.dataset = load_dataset('csv', data_files=path, split=split)def __getitem__(self, item):text = self.dataset[item]['text']label = self.dataset[item]['label']return text, labeldef __len__(self):return len(self.dataset)# todo: 定义批处理函数
def collate_fn(data):sents = [i[0] for i in data]labels = [i[1] for i in data]# 分词并编码data = token.batch_encode_plus(batch_text_or_text_pairs=sents, # 单个句子参与编码truncation=True, # 当句子长度大于max_length时,截断padding='max_length', # 一律补pad到max_length长度max_length=200,return_tensors='pt', # 以pytorch的形式返回,可取值tf,pt,np,默认为返回listreturn_length=True,)# input_ids:编码之后的数字# attention_mask:是补零的位置是0,其他位置是1input_ids = data['input_ids'] # input_ids 就是编码后的词attention_mask = data['attention_mask'] # pad的位置是0,其他位置是1token_type_ids = data['token_type_ids'] # (如果是一对句子)第一个句子和特殊符号的位置是0,第二个句子的位置是1labels = torch.LongTensor(labels) # 该批次的labels# print(data['length'], data['length'].max())return input_ids, attention_mask, token_type_ids, labels# todo: 定义模型,上游使用bert预训练,下游任务选择双向LSTM模型,最后加一个全连接层
class BiLSTMClassifier(nn.Module):def __init__(self, drop, hidden_dim, output_dim):super(BiLSTMClassifier, self).__init__()self.drop = dropself.hidden_dim = hidden_dimself.output_dim = output_dim# 加载bert中文模型,生成embedding层self.embedding = BertModel.from_pretrained('bert-base-chinese')# 去掉移至gpu# 冻结上游模型参数(不进行预训练模型参数学习)for param in self.embedding.parameters():param.requires_grad_(False)# 生成下游RNN层以及全连接层self.lstm = nn.LSTM(input_size=768, hidden_size=self.hidden_dim, num_layers=2, batch_first=True,bidirectional=True, dropout=self.drop)self.fc = nn.Linear(self.hidden_dim * 2, self.output_dim)# 使用CrossEntropyLoss作为损失函数时,不需要激活。因为实际上CrossEntropyLoss将softmax-log-NLLLoss一并实现的。def forward(self, input_ids, attention_mask, token_type_ids):embedded = self.embedding(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)embedded = embedded.last_hidden_state # 第0维才是我们需要的embedding,embedding.last_hidden_state = embedding[0]out, (h_n, c_n) = self.lstm(embedded)output = torch.cat((h_n[-2, :, :], h_n[-1, :, :]), dim=1)output = self.fc(output)return output# todo: 定义pytorch lightning
class BiLSTMLighting(pl.LightningModule):def __init__(self, drop, hidden_dim, output_dim):super(BiLSTMLighting, self).__init__()self.model = BiLSTMClassifier(drop, hidden_dim, output_dim) # 设置modelself.criterion = nn.CrossEntropyLoss() # 设置损失函数self.train_dataset = MydataSet('./data/archive/train_clean.csv', 'train')self.val_dataset = MydataSet('./data/archive/val_clean.csv', 'train')self.test_dataset = MydataSet('./data/archive/test_clean.csv', 'train')def configure_optimizers(self):optimizer = optim.AdamW(self.parameters(), lr=lr)return optimizerdef forward(self, input_ids, attention_mask, token_type_ids): # forward(self,x)return self.model(input_ids, attention_mask, token_type_ids)def train_dataloader(self):train_loader = DataLoader(dataset=self.train_dataset, batch_size=batch_size, collate_fn=collate_fn,shuffle=True)return train_loaderdef training_step(self, batch, batch_idx):input_ids, attention_mask, token_type_ids, labels = batch # x, y = batchy = one_hot(labels + 1, num_classes=3)# 将one_hot_labels类型转换成floaty = y.to(dtype=torch.float)# forward passy_hat = self.model(input_ids, attention_mask, token_type_ids)y_hat = y_hat.squeeze() # 将[128, 1, 3]挤压为[128,3]loss = self.criterion(y_hat, y) # criterion(input, target)self.log('train_loss', loss, prog_bar=True, logger=True, on_step=True, on_epoch=True) # 将loss输出在控制台return loss # 必须把log返回回去才有用def val_dataloader(self):val_loader = DataLoader(dataset=self.val_dataset, batch_size=batch_size, collate_fn=collate_fn, shuffle=False)return val_loaderdef validation_step(self, batch, batch_idx):input_ids, attention_mask, token_type_ids, labels = batchy = one_hot(labels + 1, num_classes=3)y = y.to(dtype=torch.float)# forward passy_hat = self.model(input_ids, attention_mask, token_type_ids)y_hat = y_hat.squeeze()loss = self.criterion(y_hat, y)self.log('val_loss', loss, prog_bar=False, logger=True, on_step=True, on_epoch=True)return lossdef test_dataloader(self):test_loader = DataLoader(dataset=self.test_dataset, batch_size=batch_size, collate_fn=collate_fn, shuffle=False)return test_loaderdef test_step(self, batch, batch_idx):input_ids, attention_mask, token_type_ids, labels = batchtarget = labels + 1 # 用于待会儿计算acc和f1-scorey = one_hot(target, num_classes=3)y = y.to(dtype=torch.float)# forward passy_hat = self.model(input_ids, attention_mask, token_type_ids)y_hat = y_hat.squeeze()pred = torch.argmax(y_hat, dim=1)acc = (pred == target).float().mean()loss = self.criterion(y_hat, y)self.log('loss', loss)# task: Literal["binary", "multiclass", "multilabel"],对应[二分类,多分类,多标签]# average=None分别输出各个类别, 不加默认算平均re = recall(pred, target, task="multiclass", num_classes=class_num, average=None)pre = precision(pred, target, task="multiclass", num_classes=class_num, average=None)f1 = f1_score(pred, target, task="multiclass", num_classes=class_num, average=None)def log_score(name, scores):for i, score_class in enumerate(scores):self.log(f"{name}_class{i}", score_class)log_score("recall", re)log_score("precision", pre)log_score("f1", f1)self.log('acc', accuracy(pred, target, task="multiclass", num_classes=class_num))self.log('avg_recall', recall(pred, target, task="multiclass", num_classes=class_num, average="weighted"))self.log('avg_precision', precision(pred, target, task="multiclass", num_classes=class_num, average="weighted"))self.log('avg_f1', f1_score(pred, target, task="multiclass", num_classes=class_num, average="weighted"))def test():# 加载之前训练好的最优模型参数model = BiLSTMLighting.load_from_checkpoint(checkpoint_path=PATH,drop=dropout, hidden_dim=rnn_hidden, output_dim=class_num)trainer = Trainer(fast_dev_run=False)result = trainer.test(model)print(result)
输出:也就是上一篇末尾提前剧透的截图。

第二部分
第一次训练出的模型的过拟合问题
为什么提到之前的模型有过拟合问题呢?让我们打开tensorboard,观察train_loss和val_loss。
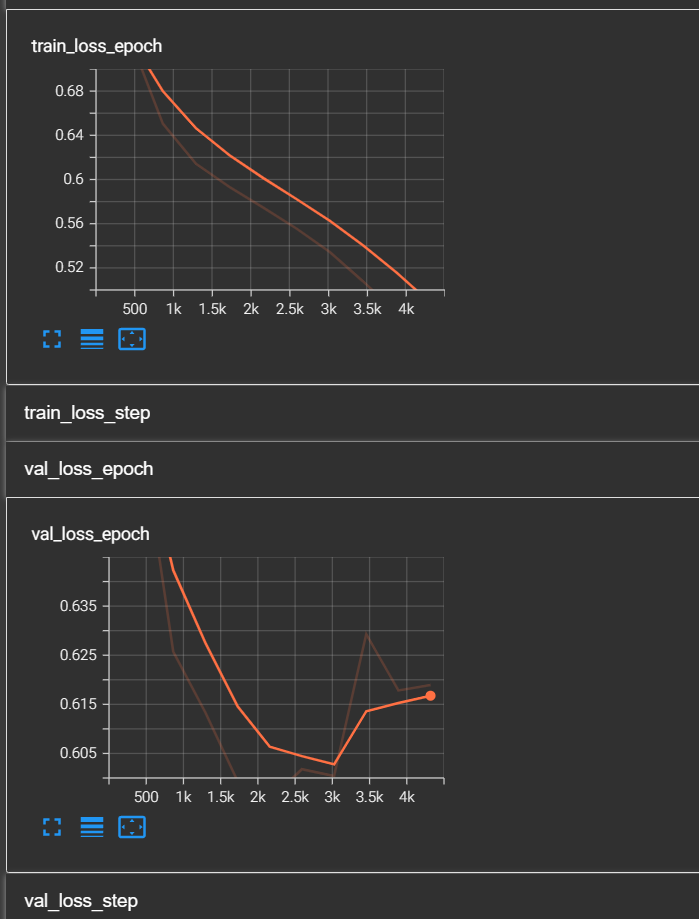
train_loss还没有收敛的趋势,但是val_loss已经出现了反弹的趋势。如果这还不算过拟合的预兆,博主做了第二个实验,我读取了第一次模型训练好的参数,并在次基础上继续训练,于是出现了以下的图像:
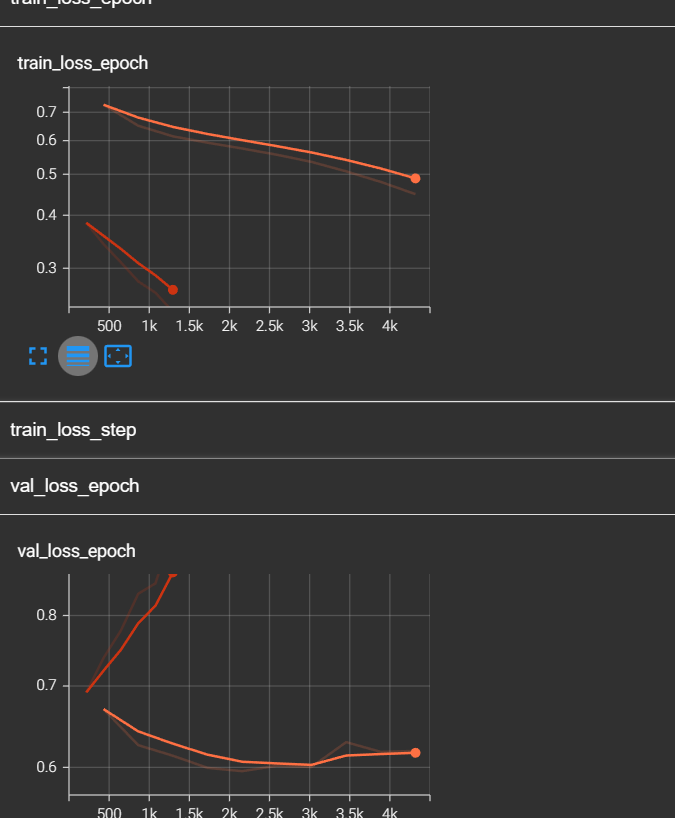
红色的线。可以看到,train_loss跟着橙色的线继续下降的,而val_loss直线上升,并且train_loss低于0.3时,val_loss高达0.9+。于是我们可以断定,过拟合了!
如何解决过拟合
最简单的方式是调参,我将batch_size由128调整到了256,将drop从0.4调整到了0.5,再次进行训练。同时,为了防止第二次也过拟合,我加入了回调函数,这个回调函数将保存过拟合之前最好的一组模型。这个回调函数的作用极为重要。下面给出最终版本的train代码:
def train():# 增加过拟合回调函数,提前停止,经过测试发现不太好用,因为可能会停止在局部最优值early_stop_callback = EarlyStopping(monitor='val_loss', # 监控对象为'val_loss'patience=4, # 耐心观察4个epochmin_delta=0.0, # 默认为0.0,指模型性能最小变化量verbose=True, # 在输出中显示一些关于early stopping的信息,如为何停止等)# 增加回调最优模型,这个比较好用checkpoint_callback = ModelCheckpoint(monitor='val_loss', # 监控对象为'val_loss'dirpath='checkpoints/', # 保存模型的路径filename='model-{epoch:02d}-{val_loss:.2f}', # 最优模型的名称save_top_k=1, # 只保存最好的那个 mode='min' # 当监控对象指标最小时)# Trainer可以帮助调试,比如快速运行、只使用一小部分数据进行测试、完整性检查等,# 详情请见官方文档https://lightning.ai/docs/pytorch/latest/debug/debugging_basic.html# auto自适应gpu数量trainer = Trainer(max_epochs=epochs, log_every_n_steps=10, accelerator='gpu', devices="auto", fast_dev_run=False,precision=16, callbacks=[checkpoint_callback])model = BiLSTMLighting(drop=dropout, hidden_dim=rnn_hidden, output_dim=class_num)trainer.fit(model)if __name__ == '__main__':# todo:定义超参数batch_size = 256epochs = 30dropout = 0.5rnn_hidden = 768rnn_layer = 1class_num = 3lr = 0.001PATH = 'PATH'token = BertTokenizer.from_pretrained('bert-base-chinese')train()# test()把他加入到上面的代码就行了。
关于回调函数的说明在代码里。
在第二天早上,我拿到了这次训练的结果:
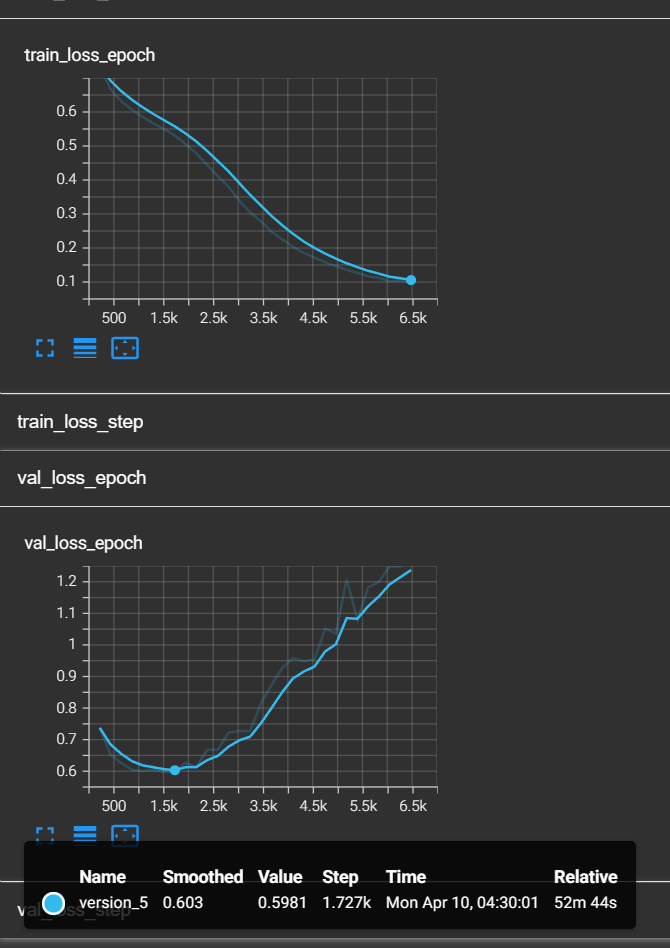
对比第一个模型:
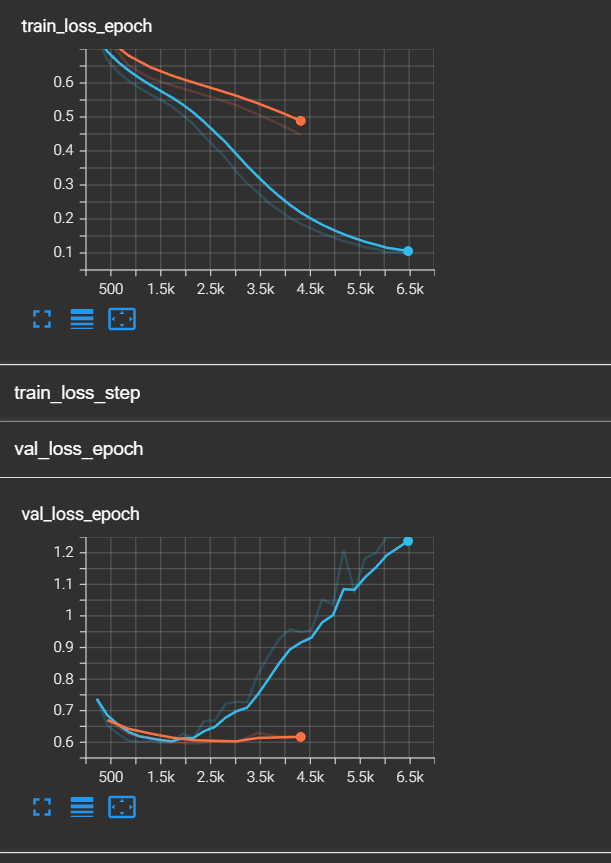
好吧,这次还是过拟合了,而且train loss居然低于了0.1,说明模型太复杂了。不过!由于我们的回调函数的存在,我们及时保存了val_loss最小时的模型。现在,将我们的模型路径换成best model,再次对测试集进行评估,我们会得到以下结果:
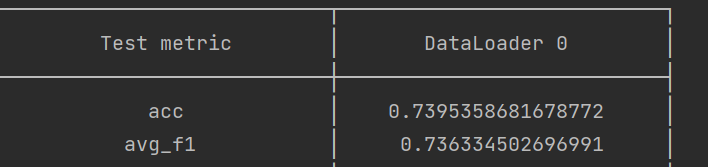
现在,它在排行榜第13位。

后记
终于写完了,一天肝完三篇文章。前面实验时在边实验边记录,所以写的比较快。
好像也没什么要写成后记的,该说的也都说完了。这三篇文章,其实就是这次实验的后记(笑)。
歇一歇,累~
还有很多不知道和要改进的地方,继续努力吧。