日撸 Java 三百行day28-30

文章目录
- 说明
- day28-30 Huffman 编码 (节点定义与文件读取)
-
- 1.建树过程(以图为例)
- 2.哈夫曼树特点
- 3.分析代码过程
-
- 3.1 抽象成员变量
- 3.2结合文章梳理思路
-
- 1.读文本
- 2.解析文本内容:
- 3.建树
- 4.生成哈夫曼编码
- 5.编码
- 6.解码
- 4.其他
-
- 4.1 java 类型强转
- 4.2 java异常处理
说明
闵老师的文章链接: 日撸 Java 三百行(总述)_minfanphd的博客-CSDN博客
自己也把手敲的代码放在了github上维护:https://github.com/fulisha-ok/sampledata
day28-30 Huffman 编码 (节点定义与文件读取)
1.建树过程(以图为例)
step1: 权重1,2,3,4 ;选取权重最小的两个节点1,2 作为左右节点,已建一棵树(也可以看作一个大节点),
step2: 权重1,2,3,4,(3),选取权重最小的两个节点3,3 建树
step3:权重 1,2,3,4,(3),(6) 选取权重最小的两个节点4,6 建树 当节点已经完了,建树完毕。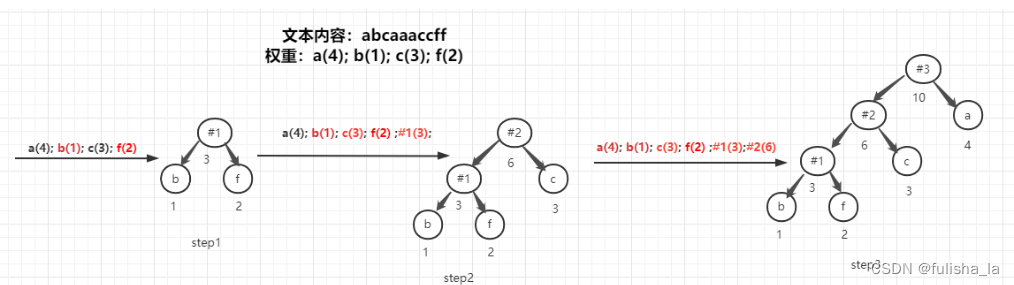
2.哈夫曼树特点
3.分析代码过程
3.1 抽象成员变量
结合上面手动建树过程,抽象哈夫曼树节点的成员变量:节点字符,权重,左右孩子节点,双亲节点。
正如闵老师在文章所说,可以将起抽象为一个结点类,在这个Huffman类中引入结点类即可使用。
/* An inner class for Huffman nodes.*/class HuffmanNode {/* The char. Only valid for leaf nodes.*/char character;/* Weight. It can also be double.*/int weight;/* The left child.*/HuffmanNode leftChild;/* The right child.*/HuffmanNode rightChild;/* The parent. It helps constructing the Huffman code of each character.*/HuffmanNode parent;/* The first constructor*/public HuffmanNode(char paraCharacter, int paraWeight, HuffmanNode paraLeftChild,HuffmanNode paraRightChild, HuffmanNode paraParent) {character = paraCharacter;weight = paraWeight;leftChild = paraLeftChild;rightChild = paraRightChild;parent = paraParent;}}
3.2结合文章梳理思路
以前仅限于在课本上手动构造哈夫曼树,现在要把他转换为代码,刚开始还是有难度,但是仔细去读代码,分析,对自己的思维有很大的提升
1.读文本
给一串文本(文本内容仅只含ASCII码上的),读文本内容返回字符串内容。
/* Read text* @param paraFilename The text filename.*/public void readText(String paraFilename){try {inputText = Files.newBufferedReader(Paths.get(paraFilename), StandardCharsets.UTF_8).lines().collect(Collectors.joining("\\n"));} catch (Exception ee) {System.out.println(ee);System.exit(0);}System.out.println("The text is:\\r\\n" + inputText);}2.解析文本内容:
-
分析
获取字符串内容,解析字符串并利用数组来存储,即包括字符存储,字符对应的权重(字符出现的个数),而要存储这两类值,借助了一个辅助数组(长度是ASCII码总个数,因为ASCII码十进制是从0开始的,所以就可以一一对应字符即强转)遍历数组,将对应的字符出现的个数存储到这个辅助数组下,这样即可以知道有那些字符(索引值),又可以知道字符的权重(数组本身值)。结合这个辅助数组即可对字符存储和字符对应权重的数组赋值了。(这里借助了一个辅助数组来解析文本,在思考是否可以用Map键值对来实现。键可以存放字符也可以存放字符的ASCII码值,而值存放相应字符出现的次数)我认为对哈夫曼树中最关键的就是这一步,解析文本内容。如tempCharCounts这个辅助数组,如果他的值没有弄好就会导致后面一系列的操作会出现问题。 -
代码
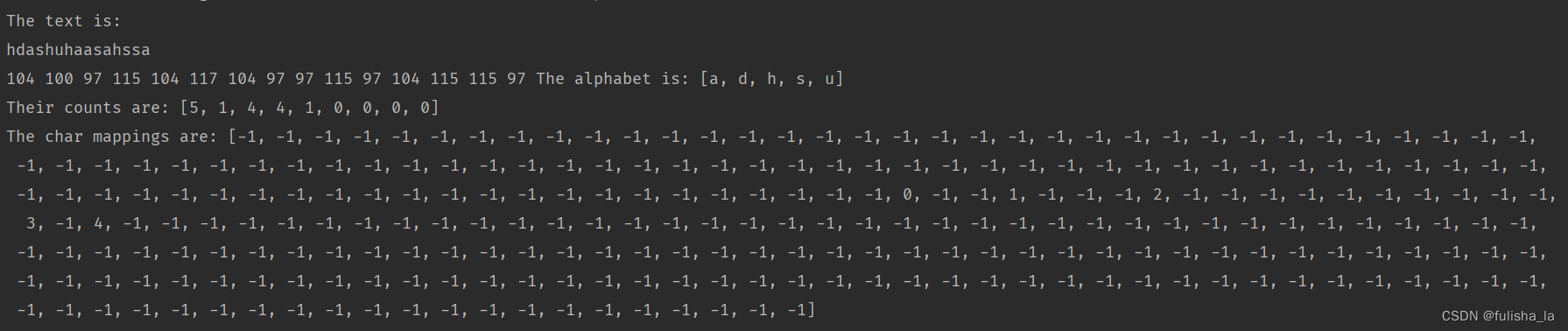
public void constructAlphabet(){//initializeArrays.fill(charMapping, -1);// The count for each char. At most NUM_CHARS chars.int[] tempCharCounts = new int[NUM_CHARS];//The index of the char in the ASCII charsetint tempCharIndex;char tempChar;for (int i = 0; i < inputText.length(); i++){tempChar = inputText.charAt(i);tempCharIndex = (int)tempChar;System.out.print("" + tempCharIndex + " ");tempCharCounts[tempCharIndex]++;}// Step 2. Scan to determine the size of the alphabetalphabetLength = 0;for (int i = 0; i < 255; i++){if (tempCharCounts[i] > 0){alphabetLength++;}}//step3. Compress to the alphabetalphabet = new char[alphabetLength];charCounts = new int[2 * alphabetLength - 1];int tempCounter = 0;for (int i = 0; i < NUM_CHARS; i++) {if (tempCharCounts[i] > 0) {alphabet[tempCounter] = (char) i;charCounts[tempCounter] = tempCharCounts[i];charMapping[i] = tempCounter;tempCounter++;}}System.out.println("The alphabet is: " + Arrays.toString(alphabet));System.out.println("Their counts are: " + Arrays.toString(charCounts));System.out.println("The char mappings are: " + Arrays.toString(charMapping));}
3.建树
在解析文本内容后我们得到的以下两个数组是就建树的关键。其中通过两组循环来找最数组中权重最小的左右两个结点,自底向上建哈夫曼树。这里借助了boolean类型的tempProcessed数组来标记结点是否已经被选过。循环的开始和结束位置需要留意以下。通过我们手动建树过程也知道。
1.找一个最小结点作为左子树
2.找一个第二小结点作为右子树
3.两个结点相加的值形成一个新结点,又参与建树过程
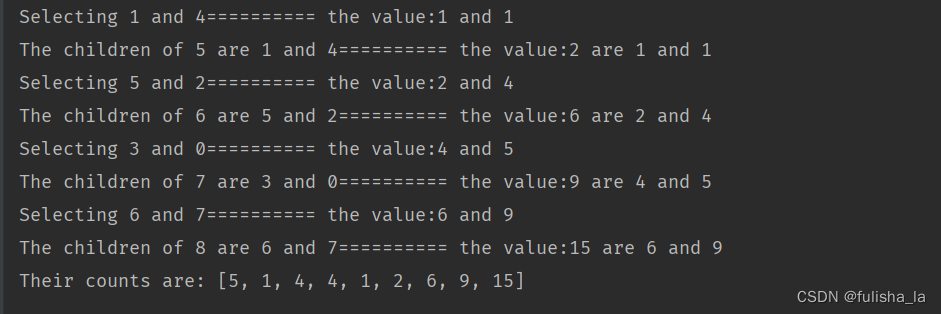
/* Construct the tree.*/public void constructTree(){// Step 1. Allocate space.nodes = new HuffmanNode[alphabetLength * 2 - 1];boolean[] tempProcessed = new boolean[alphabetLength * 2 - 1];// Step 2. Initialize leaves.for (int i = 0; i < alphabetLength; i++) {nodes[i] = new HuffmanNode(alphabet[i], charCounts[i], null, null, null);}// Step 3. Construct the tree.int tempLeft, tempRight, tempMinimal;for (int i = alphabetLength; i < 2 * alphabetLength - 1; i++) {// Step 3.1 Select the first minimal as the left child.tempLeft = -1;tempMinimal = Integer.MAX_VALUE;for (int j = 0; j < i; j++) {if (tempProcessed[j]) {continue;}if (tempMinimal > charCounts[j]) {tempMinimal = charCounts[j];tempLeft = j;}}tempProcessed[tempLeft] = true;// Step 3.2 Select the second minimal as the right child.tempRight = -1;tempMinimal = Integer.MAX_VALUE;for (int j = 0; j < i; j++) {if (tempProcessed[j]) {continue;}if (tempMinimal > charCounts[j]) {tempMinimal = charCounts[j];tempRight = j;}}tempProcessed[tempRight] = true;System.out.println("Selecting " + tempLeft + " and " + tempRight + "========== the value:" + charCounts[tempLeft] + " and " + charCounts[tempRight]);// Step 3.3 Construct the new node.charCounts[i] = charCounts[tempLeft] + charCounts[tempRight];nodes[i] = new HuffmanNode('*', charCounts[i], nodes[tempLeft], nodes[tempRight], null);// Step 3.4 Link with children.nodes[tempLeft].parent = nodes[i];nodes[tempRight].parent = nodes[i];System.out.println("The children of " + i + " are " + tempLeft + " and " + tempRight+ "========== the value:" + charCounts[i] +" are " + charCounts[tempLeft] + " and " + charCounts[tempRight]);}System.out.println("Their counts are: " + Arrays.toString(charCounts));}
4.生成哈夫曼编码
建树成功后,要对叶子节点上的每一个字符进行编码(左0右1)来产生编码,并存在一个字符数组中。在生成哈夫曼编码,利用了一个双重循环,外层循环是循环需要编码的字符个数,内层循环是对每一个字符从底向上去判断他的双亲进行编码(通过双亲结点向上),则打印的时候就是以我们正常的从上向下读的编码.
例如:
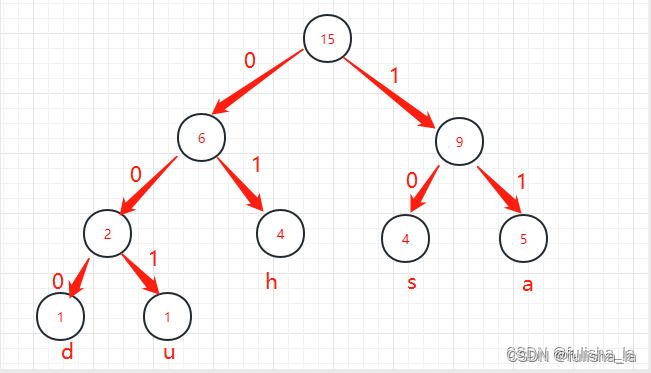
我们以a为例,
- 判断a结点是否有双亲结点,有9,则判断9右孩子为a,则编码拼接tempCharCode = 1
- 再往上走,9的双亲结点为15,15的右孩子为9,则拼接tempCharCode = 11
- 再走没有双亲跳出循环
5.编码
输入字符串,结合生成的哈夫曼编码的字符串数组 拼接成字符串即可
/* Encode the given string.* @param paraString* @return*/public String coding(String paraString) {String resultCodeString = "";int tempIndex;for (int i = 0; i < paraString.length(); i++) {// From the original char to the location in the alphabet.tempIndex = charMapping[(int) paraString.charAt(i)];// From the location in the alphabet to the code.resultCodeString += huffmanCodes[tempIndex];}return resultCodeString;}
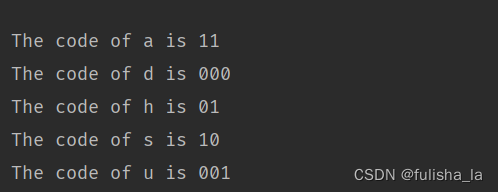
我输入的测试是:hdashuhaasahssa
6.解码
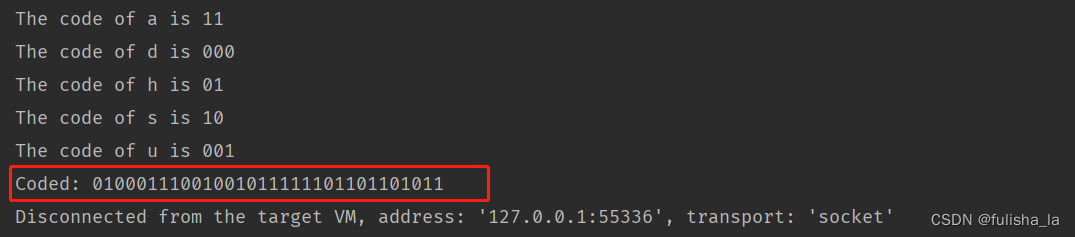
输入编码字符串,在解码的时候 我们就要从根开始去循环字符串编码,遇到0就往左子树走,遇到1就往右子树走,直到遇到的结点左子树为null(根据哈夫曼树的特点,哈夫曼树的度只能为0或2,只要左子树为null,右子树一定为null,故不用判断右子树),说明第一个字符的编码走完(在哈夫曼树中,字符结都在叶子结点上),又重新回到根节点走下一个字符的编码。
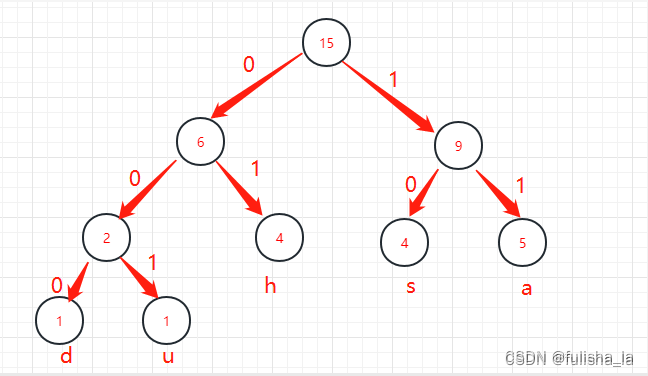
还是以这张图为例,给的字符串编码为01000111001001011111101101101011
- 15为根结点,读入编码0 ,跳转到根结点的左子树的根结点6
- 结点6的左孩子不为空,则继续判断第二个编码 1,则1跳到右子树,根结点为4
- 4 的左孩子为空(则右孩子也为空),则输出对应结点的字符h
- 然后又将结点跳到根结点15 继续接下来编码的判断
/* Decode the given string.* @param paraString The given string.* @return*/public String decoding(String paraString){String resultCodeString = "";HuffmanNode tempNode = getRoot();for (int i = 0; i < paraString.length(); i++) {if (paraString.charAt(i) == '0') {tempNode = tempNode.leftChild;System.out.println(tempNode);} else {tempNode = tempNode.rightChild;System.out.println(tempNode);}if (tempNode.leftChild == null) {System.out.println("Decode one:" + tempNode.character);// Decode one char.resultCodeString += tempNode.character;// Return to the root.tempNode = getRoot();}}return resultCodeString;}
4.其他
4.1 java 类型强转
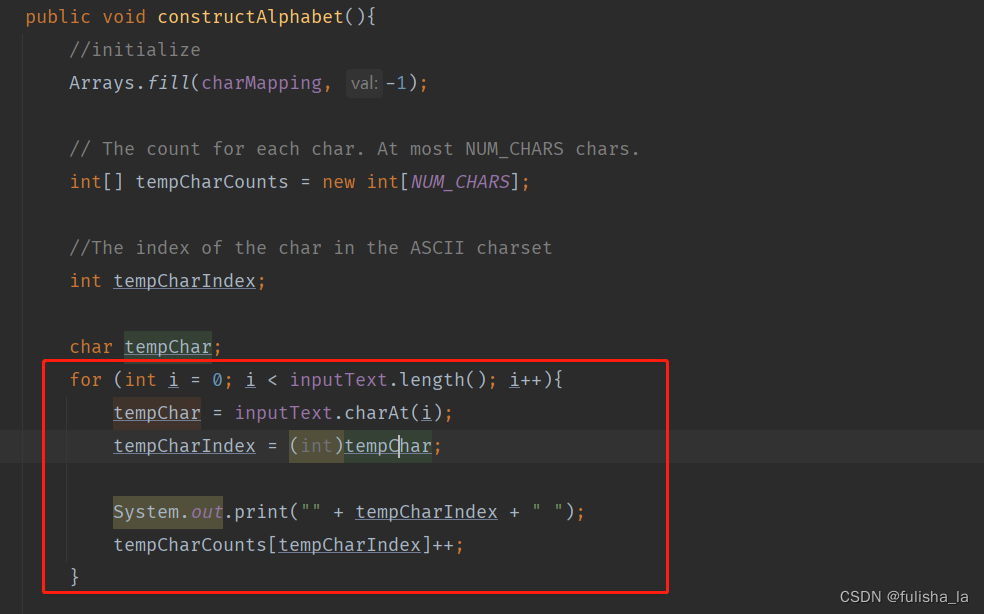
char类型转int:在char类型字符运行时实际上底层还是会转换为ASCII表中对应的整数,所以char类型可以转为int型。
(1)在java中,将char类型转为int,则他返回的值是给定的ASCII码值,如代码中
4.2 java异常处理
在本次文章中,读文本用到了异常处理,在java中会经常用到异常处理
- try-catch
将可能会发生异常的代码放在try中,如果发生异常可以通过catch去捕获,再对异常进行处理 - try-catch-finally
finally是必须要执行的代码,即无论代码是否正常还是错误都会执行这个里面的代码,在一些需要文件读入读出时就会加上finally,来确保关闭文件的输入输出流等。
try {// 可能会抛出异常的代码
} catch (type1 e) {// 处理 type1 异常的代码
} catch (type2 e) {// 处理 type2 异常的代码
} finally {// 在 try 或 catch 块中抛出异常后执行的代码
}- throw直接抛出异常
这个异常的抛出主要是在方法中进行手动抛出, 可以结合try-catch一起使用 - throws抛出异常
这个一般是放在方法的声明上,对可能出现的异常进行抛出
/* Read text* @param paraFilename The text filename.*/public void readText(String paraFilename){try {inputText = Files.newBufferedReader(Paths.get(paraFilename), StandardCharsets.UTF_8).lines().collect(Collectors.joining("\\n"));} catch (Exception ee) {System.out.println(ee);System.exit(0);}System.out.println("The text is:\\r\\n" + inputText);}