Greenplum数据库执行器——PartitionSelector执行节点

为了能够对分区表有优异的处理能力,对于查询优化系统来说一个最基本的能力就是做分区裁剪partition pruning,将query中并不涉及的分区提前排除掉。如下执行计划所示,由于单表谓词在parititon key上,在优化期间即可确定哪些可以分区可以避免访问,即静态pruning。
explain select * from test where collecttime > '2023-02-22 00:00:00' and collecttime < '2023-02-28 00:00:00';QUERY PLAN
-------------------------------------------------------------------------------------------------------------
Gather Motion 12:1 (slice1; segments: 12) (cost=0.00..431.18 rows=39 width=1626)-> Sequence (cost=0.00..431.02 rows=4 width=1626)-> Partition Selector for test (dynamic scan id: 1) (cost=10.00...100.00 rows=9 width=4)Partition selected: 6 (out of 33)-> Dynamic Seq Scan on test (dynamic scan id: 1) (cost=0.00...431.02 rows=4 width=1626)Filter: ((collecttime > '2023-02-22 00:00:00'::timestamp without time zone) AND (collecttime < '2023-02-28 00:00:00'::timestamp without time zone))
Optimizer: Pivotal Optimizer (GPORCA) explain select * from test where collecttime > '2023-02-22 00:00:00' and collecttime < '2023-02-28 00:00:00'; QUERY PLAN
-------------------------------------------------------------------------------------------------------------
Gather Motion 12:1 (slice1; segments: 12) (cost=0.00..431.18 rows=6 width=3748)-> Append (cost=0.00...0.00 rows=1 width=3748)-> Seq Scan on test_1_prt_p20230222_1 (cost=0.00..0.00 rows=1 width=3748)Filter: ((collecttime > '2023-02-22 00:00:00'::timestamp without time zone) AND (collecttime < '2023-02-28 00:00:00'::timestamp without time zone))...-> Seq Scan on test_1_prt_p20230227_1 (cost=0.00..0.00 rows=1 width=3748)Filter: ((collecttime > '2023-02-22 00:00:00'::timestamp without time zone) AND (collecttime < '2023-02-28 00:00:00'::timestamp without time zone))
Optimizer: Postgres query optimizer
如下语句date_id的值将需要根据date_dim表的动态输出决定,因此对orders表的partition pruning只能在执行期完成,类似的例子还有动态绑定变量,称为动态pruning。
SELECT avg(amount) FROM ordersWHERE date_id IN (SELECT date_id FROM date_dim WHERE year = 2013 AND month BETWEEN 10 AND 12);
引入了3个新的算子来做pruning(PartitionSelector、DynamicScan、Sequence):Sequence用于描述PartitionSelector->DynamicScan的生产消费关系,确定谁先执行;PartitionSelector根据谓词生成相关partition ids,主要实现了做partition选择的功能,并将筛选后的ids传递给DynamicScan;DynamicSeqScan物理scan算子,基于PartitionSelector传递的ids,在做table scan时跳过不需要的partition。上一节已经描述过DynamicScan的执行流程了,该节主要介绍Partition Selector。
Partition Selector
Partition Selector用于计算和传播(Compute and propagate)使用Dynamic table scan的分区表oid。执行PartitionSelector有两种途径:Constant partition elimination和Join partition elimination,如下图:
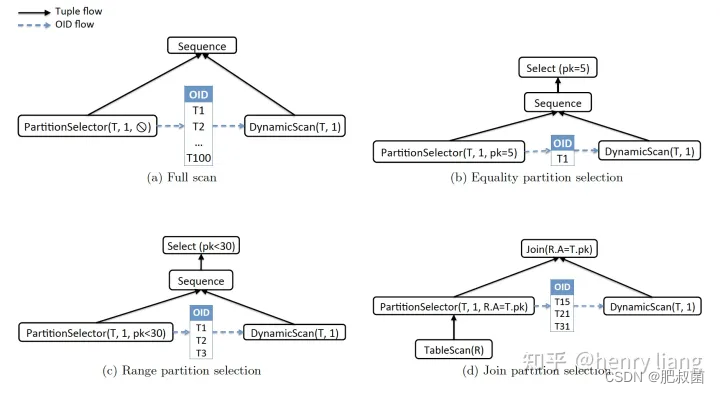
(a) 表示做full table scan,这时是没有filter的,PartitionSelector直接生成全量partition T1 -> T100给DynamicScan。
(b/c) 表示在partition key(PK)上有单表条件(PK=5/PK<30),这时可以只选出目标分区给DynamicScan。
(d) 表示了两表 R join T on R.A = T.PK,由于T表是partition table,其scan算子是DynamicScan。这里有所不同的是,对T的过滤需要基于R.A列的值,因此PartitionSelector要加在R的scan上方,用来获取R.A列的value用于过滤分区,并传递给右侧T的DynamicScan。另外可以看到这里不再有Sequence算子了,由于这里Join算子已经保障了R和T执行的先后顺序(先R后T),也就保证了PartitionSelector->DynamicScan的顺序,Sequence不再必要。
Constant partition elimination
PartitionSelector评估常量分区约束(constant partition constraints)来计算和传播(Compute and propagate)分区表oid。It only need to be called once.
1. Constant partition eliminationPlan structure:Sequence # 是一个同步的概念,用于描述PartitionSelector->DynamicScan的生产消费关系,确定谁先执行|--PartitionSelector # PartitionSelector根据谓词生成相关partition ids,主要实现了做partition选择的功能,并将筛选后的ids传递给DynamicScan|--DynamicSeqScan # 物理scan算子,基于PartitionSelector传递的ids,在做table scan时跳过不需要的partition
Join partition elimination
PartitionSelector与DynamicSeqScan、DynamicIndexScan或DynamicBitmapHeapScan位于同一切片slice中。它是为来自其子节点的每个元组执行的。它使用输入元组评估分区约束,并传播匹配的分区表Oids。
2. Join partition eliminationPlan structure:...:|--DynamicSeqScan|--...|--PartitionSelector|--...
可以有其他节点使用PartSelected qual来过滤行,而不是动态表扫描,根据选择的分区来过滤行。目前,ORCA使用动态表扫描,而非ORCA计划器生成的计划可以使用具有PartSelected quals的门控Result节点来排除不需要的分区。Instead of a Dynamic Table Scan, there can be other nodes that use a PartSelected qual to filter rows, based on which partitions are selected. Currently, ORCA uses Dynamic Table Scans, while plans produced by the non-ORCA planner use gating Result nodes with PartSelected quals, to exclude unwanted partitions.
src/backend/gpopt/translate/CTranslatorDXLToPlStmt.cpp文件中的Plan *CTranslatorDXLToPlStmt::TranslateDXLPartSelector(const CDXLNode *partition_selector_dxlnode, CDXLTranslateContext *output_context, CDXLTranslationContextArray *ctxt_translation_prev_siblings)函数将DXL PartitionSelector转化为GPDB PartitionSelector节点。
src/backend/optimizer/plan/planpartition.c文件中的Plan *create_partition_selector_plan(PlannerInfo *root, PartitionSelectorPath *best_path)函数从PartitionSelectorPath结构体创建一个PartitionSelector plan。
ExecInitPartitionSelector
首先介绍PartitionSelector node,其通过给定的root表OID找到叶子子分区表的集合和可选选择谓词。它隐藏了分区选择和传播的逻辑,而不是用它来污染计划,使计划看起来一致且易于理解。很容易找到分区选择在计划中发生的位置。(It hides the logic of partition selection and propagation instead of polluting the plan with it to make a plan look consistent and easy to understand. It will be easy to locate where partition selection happens in a plan.)
PartitionSelection可以以如下三种方式运行,A PartitionSelection can work in three different ways:
- Dynamic selection, based on tuples that pass through it.
- Dynamic selection, with a projected tuple.
- Static selection, performed at beginning of execution.
PartitionSelector结构体除了包含DynamicScan算子唯一编号和PartitionSelector算子唯一编号、root表oid和该分区表的层级外。还包含了如上三种运行方式的变量。比如对于Dynamic selection, based on tuples that pass through it来说,levelExpressions就是保存了每个分区层级使用的谓词表达式、levelEqExpressions就是保存了每个分区层级使用的等值表达式、最后应用的剩余谓词residualPredicate、传播表达式propagationExpression。对于Dynamic selection, with a projected tuple,partTabTargetlist是用于动态选择的字段,通过将输入元组投影到具有与分区表中相同位置的分区键值的元组。对于Static selection, performed at beginning of execution,staticPartOids是静态选择的分区子表oid和staticScanIds用于传播静态选择的分区子表oid的扫描id。
typedef struct PartitionSelector{Plan plan;Oid relid; /* OID of target relation */int nLevels; /* number of partition levels */int32 scanId; /* id of the corresponding dynamic scan */ // 每个DynamicScan算子有其唯一编号int32 selectorId; /* id of this partition selector */ // 每个PartitionSelector算子有其唯一编号/* Fields for dynamic selection */List *levelEqExpressions; /* list of list of equality expressions used for individual levels */List *levelExpressions; /* predicates used for individual levels */Node *residualPredicate; /* residual predicate (to be applied at the end) */Node *propagationExpression; /* propagation expression */Node *printablePredicate; /* printable predicate (for explain purposes) *//* Fields for dynamic selection, by projecting input tuples to a tuple that has the partitioning key values in the same positions as in the partitioned table. */List *partTabTargetlist;/* Fields for static selection */bool staticSelection; /* static selection performed? */List *staticPartOids; /* list of statically selected parts */List *staticScanIds; /* scan ids used to propagate statically selected part oids */
} PartitionSelector;
ExecInitPartitionSelector函数为Orca生成的PartitionSelector节点创建运行时状态信息,并初始化外部子节点(如果存在)。Create the run-time state information for PartitionSelector node produced by Orca and initializes outer child if exists. 其主要执行的步骤如下:
- 调用initPartitonSelection创建PartitionSelectorState,其levelPartRules中的每个元素都是每层子分区的PartitionRule信息(我们知道分区表除了root表之外的inheritor和leaf分区在pg_partition_rule中都有一个条目,其信息就是PartitionRule);为levelEqExpressions、levelExpressions、residualPredicate、propagationExpression初始化表达式执行ExprState列表。
- 对于ParitionSelector来说,其没有Inner plan也就是没有右子树,这里仅仅需要调用ExecInitNode初始化psstate->lefttree即可,也就是Join partition elimination这种情况。
- 如果PartitionSeletor.partTabTargetlist不为NIL,partTabTargetlist是用于动态选择的字段,通过将输入元组投影到具有与分区表中相同位置的分区键值的元组。初始化投影,以生成一个元组,该元组的分区键列位于与分区表中相同的位置。
PartitionSelectorState *ExecInitPartitionSelector(PartitionSelector *node, EState *estate, int eflags){PartitionSelectorState *psstate = initPartitionSelection(node, estate); ExecInitResultTupleSlot(estate, &psstate->ps); /* tuple table initialization */ExecAssignResultTypeFromTL(&psstate->ps);ExecAssignProjectionInfo(&psstate->ps, NULL);/* initialize child nodes */if (NULL != outerPlan(node)){ outerPlanState(psstate) = ExecInitNode(outerPlan(node), estate, eflags); }/* Initialize projection, to produce a tuple that has the partitioning key columns at the same positions as in the partitioned table. */if (node->partTabTargetlist){ // partition key target listList *exprStates = (List *) ExecInitExpr((Expr *) node->partTabTargetlist, (PlanState *) psstate);psstate->partTabDesc = ExecTypeFromTL(node->partTabTargetlist, false);psstate->partTabSlot = MakeSingleTupleTableSlot(psstate->partTabDesc);psstate->partTabProj = ExecBuildProjectionInfo(exprStates, psstate->ps.ps_ExprContext, psstate->partTabSlot, ExecGetResultType(&psstate->ps));}return psstate;
}

ExecPartitionSelector
从root表获取PartitionNode和access method。首先看一下DynamicTableScanInfo的List *partsMetadata,其存放了所有相关分区表的分区元数据。getPartitionNodeAndAccessMethod从root表获取PartitionNode和accessMethod,其实就是调用findPartitionMetadataEntry函数,该函数从partsMetadata列表中查找到相应partition oid的PartitionMetadata对象(输入参数为partsMetadata: list of PartitionMetadata、partOid: Part Oid;输出参数为partsAndRules: output parameter for matched PartitionNode;accessMethods: output parameter for PartitionAccessMethods)。PartitionMetadata结构体其实就包含了PartitionNode *partsAndRules和PartitionAccessMethods *accessMethods两个成员
if (NULL == node->rootPartitionNode){getPartitionNodeAndAccessMethod(ps->relid,estate->dynamicTableScanInfo->partsMetadata,estate->es_query_cxt,&node->rootPartitionNode,&node->accessMethods);
}
/* ----------------------------------------------------------------* getPartitionNodeAndAccessMethod Retrieve PartitionNode and access method from root table* ---------------------------------------------------------------- */
void getPartitionNodeAndAccessMethod(Oid rootOid, List *partsMetadata, MemoryContext memoryContext, PartitionNode **partsAndRules, PartitionAccessMethods **accessMethods){findPartitionMetadataEntry(partsMetadata, rootOid, partsAndRules, accessMethods);(*accessMethods)->part_cxt = memoryContext;
}
void findPartitionMetadataEntry(List *partsMetadata, Oid partOid, PartitionNode **partsAndRules, PartitionAccessMethods **accessMethods){ListCell *lc = NULL;foreach(lc, partsMetadata){PartitionMetadata *metadata = (PartitionMetadata *) lfirst(lc);*partsAndRules = findPartitionNodeEntry(metadata->partsAndRules, partOid);if (NULL != *partsAndRules){/* accessMethods define the lookup access methods for partitions, one for each level */*accessMethods = metadata->accessMethods;return;}}
}
描述findPartitionNodeEntry函数之前,需要了解一下pg_partition和pg_partition_rule系统表,每个分区父表(root table和intermediate table)在其中都有一个条目,且该条目有标识自己的oid,也就是Partition结构体中的partid;而parrelid字段就是该表的oid;parkind指明分区类型list或range;level是分区树的层级。PartitionRule结构体则代表pg_partition_rule系统表中的条目,除了root table,intermediate table和leaf table都应该有对应的条目,同样每个条目都有标识自己的oid(parruleid),paroid则代表该分区表的oid,通过parparentrule可以关联父表的rule条目,从而组成自下而上的父子链。
struct PartitionNode{NodeTag type;Partition *part; List *rules; /* rules for this level */ struct PartitionRule *default_part;
};
typedef struct Partition{NodeTag type;Oid partid; /* OID of row in pg_partition. */Oid parrelid; /* OID in pg_class of top-level partitioned relation */char parkind; /* 'r', 'l', or (unsupported) 'h' */int16 parlevel; /* depth below parent partitioned table */bool paristemplate; /* just a template, or really a part? */int16 parnatts; /* number of partitioning attributes */AttrNumber *paratts;/* attribute number vector */ Oid *parclass; /* operator class vector */
} Partition;
typedef struct PartitionRule{NodeTag type;Oid parruleid; Oid paroid; Oid parchildrelid; Oid parparentrule;bool parisdefault; char *parname; Node *parrangestart; bool parrangestartincl;Node *parrangeend; bool parrangeendincl; Node *parrangeevery; List *parlistvalues;int16 parruleord; List *parreloptions; Oid partemplatespaceId; /* the tablespace id for the template (or InvalidOid for non-template rules */struct PartitionNode *children; /* sub partition */
} PartitionRule;
findPartitionNodeEntry函数用于通过给定分区表oid查找到PartitonNode,如果partitionNode代表的是给定partOid,则返回该partitonNode;如果不是,有可能partOid是PartitionNode的子分区,通过递归子分区,获取到以partOid对应的PartitionNode并返回。
static PartitionNode *findPartitionNodeEntry(PartitionNode *partitionNode, Oid partOid){if (NULL == partitionNode){ return NULL; }if (partitionNode->part->parrelid == partOid){ return partitionNode; } ListCell *lcChild = NULL; /* check recursively in child parts in case we have the oid of an intermediate node */foreach(lcChild, partitionNode->rules){PartitionRule *childRule = (PartitionRule *) lfirst(lcChild);PartitionNode *childNode = findPartitionNodeEntry(childRule->children, partOid);if (NULL != childNode){ return childNode; }} if (NULL != partitionNode->default_part){ /* check recursively in the default part, if any */childNode = findPartitionNodeEntry(partitionNode->default_part->children, partOid);}return childNode;
}
Static selection
如果PartitionSelector.staticSelection为true,需要执行Static selection, performed at beginning of execution。staticPartOids是静态选择的分区子表oid和staticScanIds用于传播静态选择的分区子表oid的扫描id。
TupleTableSlot *ExecPartitionSelector(PartitionSelectorState *node){PartitionSelector *ps = (PartitionSelector *) node->ps.plan; EState *estate = node->ps.state;if (ps->staticSelection){/* propagate the part oids obtained via static partition selection */partition_propagation(estate, ps->staticPartOids, ps->staticScanIds, ps->selectorId);return NULL;}
首先学习一下InsertPidIntoDynamicTableScanInfo函数用于将分区oid插入dynamicTableScanInfo的pidIndexes[scanId],如果partOid分区oid为非法oid,该函数将不会插入该oid,但是会确保dynamicTableScanInfo的pidIndexes[scanId]的HTAB(该HTAB的key为partition table oid,entry为partition table oid和selectorId列表的组合)存在。从DynamicSeqScan的逻辑可知,需要扫描的分区oid就存在于dynamicTableScanInfo的pidIndexes[scanId]中。partition_propagation函数就是将该selector为不同DynamicScan裁剪的分区oid放入dynamicTableScanInfo->pidIndexes缓冲中,供DynamicScan扫描。
static void partition_propagation(EState *estate, List *partOids, List *scanIds, int32 selectorId){ListCell *lcOid = NULL; ListCell *lcScanId = NULL;forboth (lcOid, partOids, lcScanId, scanIds) {Oid partOid = lfirst_oid(lcOid); int scanId = lfirst_int(lcScanId);InsertPidIntoDynamicTableScanInfo(estate, scanId, partOid, selectorId);}
}
void InsertPidIntoDynamicTableScanInfo(EState *estate, int32 index, Oid partOid, int32 selectorId){DynamicTableScanInfo *dynamicTableScanInfo = estate->dynamicTableScanInfo;MemoryContext oldCxt = MemoryContextSwitchTo(estate->es_query_cxt);if (index > dynamicTableScanInfo->numScans){ increaseScanArraySize(estate, index); } // 对array扩容if ((dynamicTableScanInfo->pidIndexes)[index - 1] == NULL){ dynamicTableScanInfo->pidIndexes[index - 1] = createPidIndex(estate, index); } // 为该index创建HTABif (partOid != InvalidOid){bool found = false;PartOidEntry *hashEntry = hash_search(dynamicTableScanInfo->pidIndexes[index - 1], &partOid, HASH_ENTER, &found);if (found){hashEntry->selectorList = list_append_unique_int(hashEntry->selectorList, selectorId);}else{hashEntry->partOid = partOid; hashEntry->selectorList = list_make1_int(selectorId);}}MemoryContextSwitchTo(oldCxt);
}
Dynamic selection
如果NULL != outerPlanState(node),则需要处理Join partition elimination。调用ExecProcNode(outerPlan)执行partitionselector的左子树的执行计划。如果inputSlot为null,其实就是说明outerPlan没有匹配的tuple了,也就是说明不需要继续判定哪些分区需要扫描了。
PlanState *outerPlan = outerPlanState(node);TupleTableSlot *inputSlot = ExecProcNode(outerPlan);if (TupIsNull(inputSlot)){ /* no more tuples from outerPlan *//* Make sure we have an entry for this scan id in dynamicTableScanInfo. Normally, this would've been done the first time a partition is selected, but we must ensure that there is an entry even if no partitions were selected. (The traditional Postgres planner uses this method.) */if (ps->partTabTargetlist) InsertPidIntoDynamicTableScanInfo(estate, ps->scanId, InvalidOid, ps->selectorId);else LogPartitionSelection(estate, ps->selectorId);return NULL;}
如果有partitioning投影(Dynamic selection, with a projected tuple),将输入tuple投影成看上去来自partitioned table的tuple,然后使用selectPartitionMulti函数选择分区。(Postgres planner使用这种方式)
ListCell *lc;TupleTableSlot *slot = ExecProject(node->partTabProj, NULL); slot_getallattrs(slot);List *oids = selectPartitionMulti(node->rootPartitionNode,slot_get_values(slot),slot_get_isnull(slot),slot->tts_tupleDescriptor,node->accessMethods);foreach (lc, oids){InsertPidIntoDynamicTableScanInfo(estate, ps->scanId, lfirst_oid(lc), ps->selectorId);}list_free(oids);
selectPartitionMulti函数通过提供的partition node、tuple values nullness和partition state,找到匹配的叶子分区。该函数和selectPartition相似,但是对于nulls的处理不同。该函数的处理方式是,如果有partitioning key的值为null,则所有子分区都被认为是匹配的;如果没有partitioning key的值为null,调用selectPartition1获取对应partitioning key值下的子分区。The input values/isnull should match the layout of tuples in the partitioned table.
List *selectPartitionMulti(PartitionNode *partnode, Datum *values, bool *isnull, TupleDesc tupdesc, PartitionAccessMethods *accessMethods){List *leafPartitionOids = NIL;List *inputList = list_make1(partnode);while (list_length(inputList) > 0){ // 按层处理,这里的InputList是每层分区表的PartitionNode列表List *levelOutput = NIL; ListCell *lc = NULL; foreach(lc, inputList){ // 遍历所有PartitionNodePartitionNode *candidatePartNode = (PartitionNode *) lfirst(lc);bool foundNull = false;for (int i = 0; i < candidatePartNode->part->parnatts; i++){ // 遍历该partition node的所有分区键AttrNumber attno = candidatePartNode->part->paratts[i]; if (isnull[attno - 1]){ /* If corresponding value is null, then we should pick all of its children (or itself if it is a leaf partition) */foundNull = true;if (IsLeafPartitionNode(candidatePartNode)){ /* Extract out Oids of all children */leafPartitionOids = list_concat(leafPartitionOids, all_partition_relids(candidatePartNode));}else {levelOutput = list_concat(levelOutput, PartitionChildren(candidatePartNode));}}}/* If null was not found on the attribute, and if this is a leaf partition, then there will be an exact match. If it is not a leaf partition, then we have to find the right child to investigate. */if (!foundNull) {if (IsLeafPartitionNode(candidatePartNode)){Oid matchOid = selectPartition1(candidatePartNode, values, isnull, tupdesc, accessMethods, NULL, NULL);if (matchOid != InvalidOid){ leafPartitionOids = lappend_oid(leafPartitionOids, matchOid); }}else{PartitionNode *childPartitionNode = NULL;selectPartition1(candidatePartNode, values, isnull, tupdesc, accessMethods, NULL, &childPartitionNode);if (childPartitionNode){ levelOutput = lappend(levelOutput, childPartitionNode); }}}}list_free(inputList); inputList = levelOutput; /* Start new level */}return leafPartitionOids;
}
如果没有partitioning投影,则利用levelEqExpressions和levelExpressions来选择分区。(ORCA使用这种方式)
typedef struct SelectedParts{ /* SelectedParts node: This is the result of partition selection. It has a list of leaf part oids and the corresponding ScanIds to which they should be propagated */List *partOids;List *scanIds;
} SelectedParts;SelectedParts *selparts = processLevel(node, 0 /* level */, inputSlot); if (NULL != ps->propagationExpression){ /* partition propagation */partition_propagation(estate, selparts->partOids, selparts->scanIds, ps->selectorId);}list_free(selparts->partOids); list_free(selparts->scanIds); pfree(selparts);
processLevel函数返回符合predicates处于指定分区层级的分区表oid。如果处理intermediate层级,存储符合要求的分区oid,继续下一个层级分区;如果处于叶子层级,获取满足要求的分区oid。其执行流程如下所示:
- 首先获取指定层级的谓词表达式equalityPredicate和generalPredicate,定位到root PartitionNode,如果level为0,则parentNode为node->rootPartitionNode;否则为node->levelPartRules[level - 1]->children。
- 调用partition_rules_for_equality_predicate和partition_rules_for_general_predicate获取匹配equalityPredicate和generalPredicate谓词的PartitionRule列表。如果没有上述谓词,则需要把下一个层级的PartitionRule全部返回。
- 遍历satisfied PartitionRules,如果当前层级为叶子层级,调用eval_part_qual函数处理residual predicate,调用eval_propagation_expression函数propagationExpression获取scanId,将partoid和scanId设置到selparts;否则需要递归调用
processLevel(node, level + 1, inputTuple)到next level’s partition elimination
SelectedParts *processLevel(PartitionSelectorState *node, int level, TupleTableSlot *inputTuple){SelectedParts *selparts = makeNode(SelectedParts); selparts->partOids = NIL; selparts->scanIds = NIL;PartitionSelector *ps = (PartitionSelector *) node->ps.plan;/* get equality and general predicate for the current level */ // 获取指定层级的谓词表达式List *equalityPredicate = (List *) lfirst(list_nth_cell(ps->levelEqExpressions, level));Expr *generalPredicate = (Expr *) lfirst(list_nth_cell(ps->levelExpressions, level));/* get parent PartitionNode if in level 0, it's the root PartitionNode */PartitionNode *parentNode = node->rootPartitionNode;if (0 != level){parentNode = node->levelPartRules[level - 1]->children;}/* list of PartitionRule that satisfied the predicates */List *satisfiedRules = NIL; if (NULL != equalityPredicate){ /* If equalityPredicate exists */List *chosenRules = partition_rules_for_equality_predicate(node, level, inputTuple, parentNode);satisfiedRules = list_concat(satisfiedRules, chosenRules);}else if (NULL != generalPredicate) /* If generalPredicate exists */{List *chosenRules = partition_rules_for_general_predicate(node, level, inputTuple, parentNode);satisfiedRules = list_concat(satisfiedRules, chosenRules);}else { /* None of the predicate exists *// Neither equality predicate nor general predicate exists. Return all the next level PartitionRule.* WARNING: Do NOT use list_concat with satisfiedRules and parentNode->rules. list_concat will destructively modify satisfiedRules to point to parentNode->rules, which will then be freed when we free satisfiedRules. This does not apply when we execute partition_rules_for_general_predicate as it creates its own list. */ListCell *lc = NULL; foreach(lc, parentNode->rules){PartitionRule *rule = (PartitionRule *) lfirst(lc); satisfiedRules = lappend(satisfiedRules, rule);}if (NULL != parentNode->default_part){satisfiedRules = lappend(satisfiedRules, parentNode->default_part);}}/* Based on the satisfied PartitionRules, go to next level or propagate PartOids if we are in the leaf level */ListCell *lc = NULL;foreach(lc, satisfiedRules){PartitionRule *rule = (PartitionRule *) lfirst(lc);node->levelPartRules[level] = rule; if (level == ps->nLevels - 1){ /* If we already in the leaf level */bool shouldPropagate = true; if (NULL != ps->residualPredicate){ /* if residual predicate exists */ shouldPropagate = eval_part_qual(node->ps.ps_ExprContext, inputTuple, node->residualPredicateExprStateList); /* evaluate residualPredicate */}if (shouldPropagate){if (NULL != ps->propagationExpression){if (!list_member_oid(selparts->partOids, rule->parchildrelid)){selparts->partOids = lappend_oid(selparts->partOids, rule->parchildrelid);int scanId = eval_propagation_expression(node, rule->parchildrelid);selparts->scanIds = lappend_int(selparts->scanIds, scanId);}}}}else{ /* Recursively call this function for next level's partition elimination */SelectedParts *selpartsChild = processLevel(node, level + 1, inputTuple);selparts->partOids = list_concat(selparts->partOids, selpartsChild->partOids);selparts->scanIds = list_concat(selparts->scanIds, selpartsChild->scanIds);pfree(selpartsChild);}}list_free(satisfiedRules); node->levelPartRules[level] = NULL; /* After finish iteration, reset this level's PartitionRule */return selparts;
}

https://zhuanlan.zhihu.com/p/367068030