hadoop伪分布式安装

文章目录
-
- 1. 将安装包hadoop-3.1.3.tar.gz上次至linux中
- 2. 进行解压操作
- 3. 修改目录名称
- 4. 配置环境变量
- 5. 修改自定义配置文件
-
- 5.1 hadoop-env.sh
- 5.2 core-site.xml
- 5.3 hdfs-site.xml
- 5.4 workers
- 6. 格式化集群
- 7. 免密登录
- 8. 启动hdfs
- 9. 关闭hdfs
1. 将安装包hadoop-3.1.3.tar.gz上次至linux中
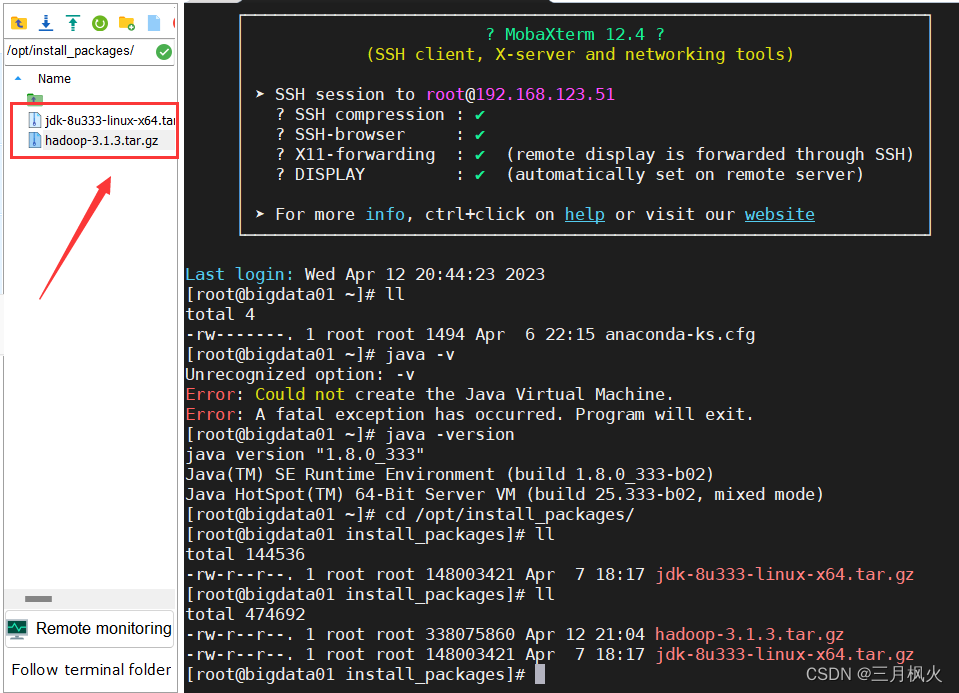
2. 进行解压操作
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/softs/
##tar: 解压打包的命令
##z: 当前压缩类型为.tar. gz
##x: 代表是解压命令
##v: 代表在解压过程中显示执行过程
##f: 代表指定打包后的文件名
##C: 指定解压后的目录
3. 修改目录名称
--替换目录
cd /opt/softs
--修改目录名称
mv hadoop-3.1.3/ hadoop3.1.3/
4. 配置环境变量
--编辑环境变量配置文件
vim /etc/profile--在文件添加如下配置项##JAVA_HOME
export JAVA_HOME=/opt/softs/jdk1.8.0
export PATH=$PATH:$JAVA_HOME/bin##HADOOP_HOME
export HADOOP_HOME=/opt/softs/hadoop3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbinexport HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root--保存退出后需要使环境变量配置文件的改动生效
source /etc/profile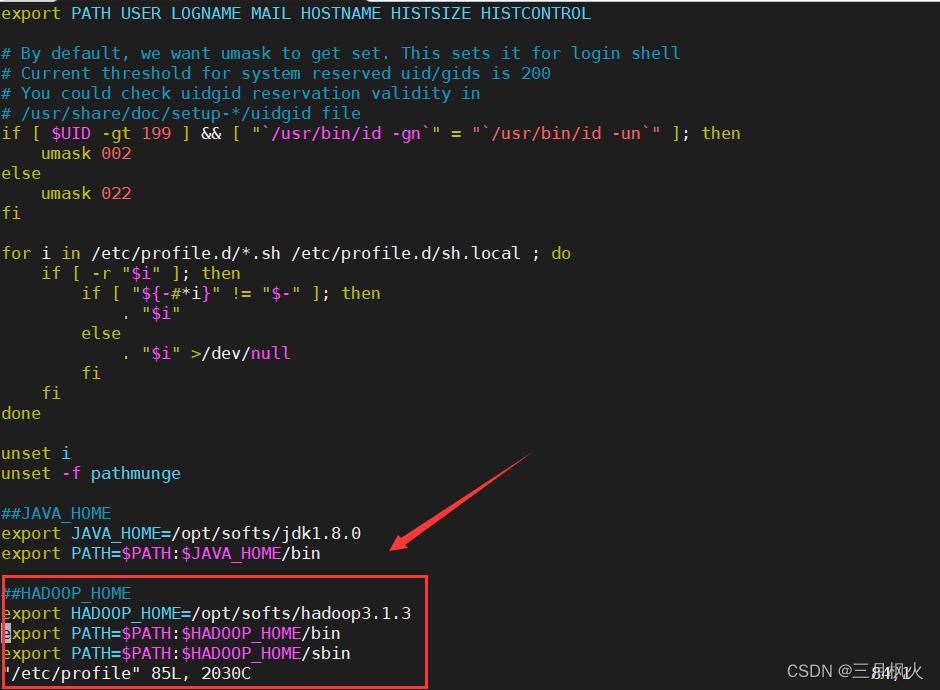
输出hadoop环境变量 :
echo $HADOOP_HOME

5. 修改自定义配置文件
自定义文件的路径: $HADOOP_HOME/etc/hadoop
5.1 hadoop-env.sh
配置如下
cd /opt/softs/hadoop3.1.3/etc/hadoop
ll
vim hadoop-env.sh-- 修改JAVA_HOME的配置
export JAVA_HOME=/opt/softs/jdk1.8.05.2 core-site.xml
配置如下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://bigdata02:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/softs/hadoop3.1.3/data</value></property></configuration>5.3 hdfs-site.xml
配置如下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- HDFS数据副本数 --><property><name>dfs.replication</name><value>1</value></property><!-- namenode数据的存储目录 --><property><name>dfs.namenode.name.dir</name><value>file:/opt/softs/hadoop3.1.3/data/dfs/name</value></property><!-- datanode数据的存储目录 --><property><name>dfs.datanode.data.dir</name><value>file:/opt/softs/hadoop3.1.3/data/dfs/data</value></property></configuration>
5.4 workers
配置作为datanode节点的hostname
bigdata02
6. 格式化集群
如果集群是第一次启动,需要在NameNode节点处进行格式化,格式化后,会产生新的集群id
如果对集群进行重新格式化时,需要先停止NameNode和DataNode的运行,并且需要删除所有节点上data和logs目录。然后再进行重新格式化
-- 格式化命令
hdfs namenode -format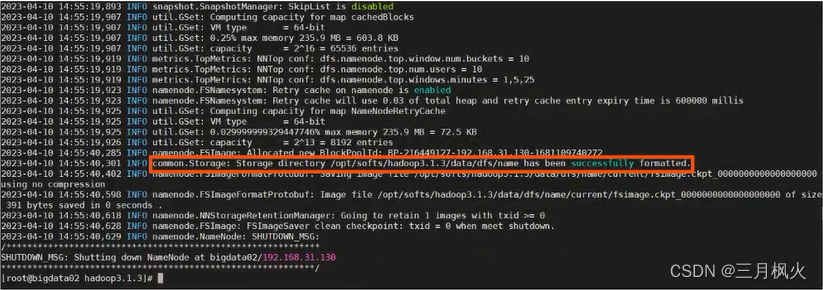
7. 免密登录
-- 切换到/root目录
cd /root-- 查看隐藏目录
1s -al
#a 显示所有的文件(包含隐藏文件)
#l 详细信息显示-- 切换目录
cd .ssh--执行创建公钥和私钥的命令
ssh-keygen -t rsa
然后可以回车3次生成两个文件: id_rsa(私钥),id_rsa.pub(公钥)--将公钥拷贝到要免密登录的节点上
ssh-copy-id bigdata02-- ssh登录测试
ssh root@bigdata028. 启动hdfs
-- 启动hdfs命令
start-dfs.sh
查看服务启动情况
jps
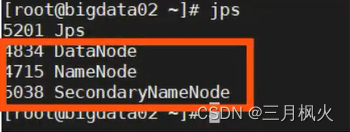
有上述三个服务时代表hdfs启动成功
9. 关闭hdfs
stop-dfs.sh