2s-AGCN 论文解读

- 论文名称:Two-stream adaptive graph convolutional networks for
skeleton-based action recognition - 论文下载:https://arxiv.org/pdf/1805.07694.pdf
- 论文代码:https://github.com/lshiwjx/2s-AGCN
论文:基于骨骼动作识别的双流自适应图卷积网络
从名字可以看出,文章主要创新点有两个,一个是双流网络,另外一个是自适应性。
摘要
对于动作识别而言,骨骼数据的二阶信息(骨骼的长度和方向)自然信息量更大,分辨力更强,而现有方法很少对其进行研究。在这项工作中,我们提出了一种新的双流自适应图卷积网络(2s-AGCN)用于基于骨骼的动作识别。
我们的模型中的图的拓扑可以通过BP算法以端到端的方式统一或单独地学习。这种数据驱动的方法增加了模型构造图的灵活性,并带来了更多的通用性,以适应各种数据样本。
此外,提出了一阶信息和二阶信息同时建模的双流框架,显著提高了识别精度。
在 NTU-RGBD 和 KineticsSkeleton 两个大规模数据集上进行的大量实验表明,我们的模型的性能大大超过了目前的水平。
引入
ST-GCN 中的图构造过程存在三个缺点:
- ST-GCN 中使用的骨架图是启发式预定义的,仅表示人体的物理结构。因此,对于动作识别任务,它不能保证是最优的。例如,两只手之间的关系对于识别“鼓掌”和“阅读”等类别很重要。然而,ST-GCN 很难捕捉到两只手之间的依赖关系,因为它们在预定义的基于人体的图形中彼此相距很远。
- GCNs 的结构是分层的,不同的层包含多层次的语义信息。然而,ST-GCN
中应用的图的拓扑结构是固定在所有层上的,缺乏对所有层中包含的多层语义信息建模的灵活性和能力; - 对于不同动作类的所有样本,一个固定的图结构不一定是最优的。对于“擦脸”和“摸头”这样的动作类,手和头之间的联系应该更强,但对于其他一些动作类则不是这样,如“跳起来”和“坐下”。这一事实表明,图结构应该是数据相关的,然而,ST-GCN 不支持。
为了解决上述问题,本文提出了一种新的自适应图卷积网络。它将两种类型的图参数化,其结构与模型的卷积参数一起训练和更新。
- 一种类型是全局图,它表示所有数据的公共模式。
- 另一种类型是单独的图形,它表示每个数据的唯一模式。
这两种类型的图都针对不同的层进行了单独优化,可以更好地拟合模型的层次结构。这种数据驱动的方法增加了模型构造图的灵活性,并带来了更多的通用性,以适应各种数据样本。
ST-GCN 中另一个值得注意的问题是,附着在每个顶点上的特征向量仅包含关节的二维或三维坐标,可视为骨架数据的一阶信息。然而,代表两个关节之间的骨骼特征的二阶信息并没有被利用。
通常情况下,骨骼的长度和方向对动作识别来说自然更有信息量和分辨力。为了利用骨骼数据的二阶信息,将骨骼的长度和方向表示为一个从源关节指向目标关节的向量。与第一存储器信息类似,该向量被输入自适应图卷积网络来预测动作标签。此外,提出了一阶和二阶信息融合的双流框架,进一步提高了性能。
我们工作的主要贡献在于三个方面:
- 提出了一种自适应图卷积网络,以端到端的方式自适应学习不同 GCN 层和骨架样本的图拓扑,能够更好地适应动作识别任务和 GCN 的层次结构。
- 采用双流框架将骨架数据的二阶信息显式表述并与一阶信息相结合,显著提高了识别性能。
- 在基于骨骼的动作识别的两个大规模数据集上,提出的 2s-AGCN 大大超过了目前的技术水平。
图卷积网络
1. 图结构
图的结构遵循 ST-GCN,使用一个时空图沿着空间和时间维度来建模这些关节之间的结构化信息。如下图所示,关节表示为顶点,它们在人体中的自然连接表示为空间边(橙线)。在时间维度上,相邻两帧之间的对应节点用时间边连接(蓝线)。将每个关节的坐标向量设置为对应顶点的属性。
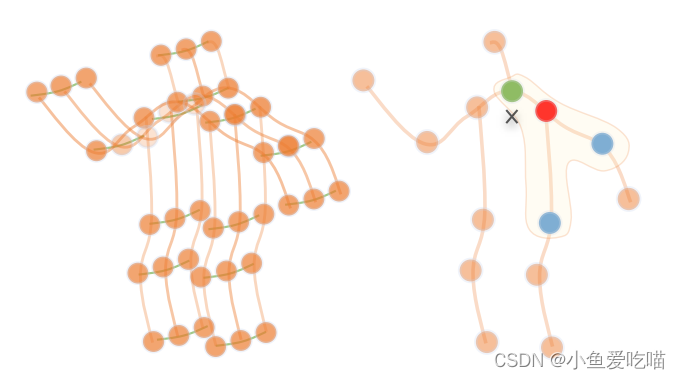
左图为在 ST-GCN 中使用的时空图说明,右图是分区策略的说明,不同的颜色表示不同的子集。
2. 图卷积
对于上述定义的图,在图上应用多层时空图卷积运算来提取高层特征。然后使用全局平均池化层和 softmaxsoftmaxsoftmax 分类器根据提取的特征预测动作类别。在空间维度上,顶点 viv_ivi 上的图卷积运算公式为:fout(vi)=∑vj∈Bi1Zijfin(vj)⋅w(li(vj))(1)f_{out}(v_i) = \\sum_{v_j \\in \\mathcal B_i} \\frac{1}{Z_{ij}} f_{in}(v_j) ·w(l_i (v_j) ) \\tag{1}fout(vi)=vj∈Bi∑Zij1fin(vj)⋅w(li(vj))(1)其中 fff 表示特征映射,vvv 表示图形的顶点。Bi\\mathcal B_iBi 表示 viv_ivi 卷积的采样面积,定义为目标顶点(viv_ivi)的1距离邻居顶点(vjv_jvj)集。www 是类似于原始卷积操作的加权函数,它基于给定的输入提供了一个权重向量。
注意,卷积的权向量数量是固定的,而 Bi\\mathcal B_iBi 中的顶点数量是变化的。在 ST-GCN 中专门设计了一个映射函数 lil_ili,用唯一的权向量映射每个顶点。参见上图分区策略的说明,其中×表示骨架的重心,Bi\\mathcal B_iBi 是曲线围成的面积。具体来说,该策略根据经验将核大小设置为3,并将 Bi\\mathcal B_iBi 自然划分为3个子集:
- Si1\\mathcal S_{i1}Si1 是顶点本身(红色圆圈);
- Si2\\mathcal S_{i2}Si2 是向心子集,它包含了更接近重心的相邻顶点(绿色圆圈);
- Si3\\mathcal S_{i3}Si3 是离心子集,它包含了离重心更远的相邻顶点(蓝色圆圈)。
ZijZ_{ij}Zij 表示包含 vjv_jvj 的 Sik\\mathcal S_{ik}Sik 的基数。它的目的是平衡每个子集的贡献。
3. 实现
图卷积在空间维度上的实现并不简单。具体来说,网络的特征图实际上是一个 C×T×NC × T × NC×T×N 张量,其中 NNN 表示顶点的数量,TTT 表示时间长度,CCC 表示通道的数量。为了实现 ST-GCN,将式(1)转化为:fout∑kKvWk(finAk)⊙Mk(2)\\mathbf f_{out} \\sum_k^{K_v} \\mathbf W_k (\\mathbf f_{in} \\mathbf A_k) \\odot \\mathbf M_k\\tag{2}foutk∑KvWk(finAk)⊙Mk(2)其中 KvK_vKv 为空间维的核大小。根据上面设计的分区策略,KvK_vKv 设为3。Ak=Λk−12AˉkΛk−12\\mathbf A_k = \\mathbf Λ^{−\\frac{1}{2} }_k \\mathbf {\\bar A}_k \\mathbf Λ^{−\\frac{1}{2}}_kAk=Λk−21AˉkΛk−21,其中 Aˉk\\mathbf {\\bar A}_kAˉk 类似于 N×NN × NN×N 邻接矩阵,其元素 Aˉkij\\mathbf {\\bar A}_k^{ij}Aˉkij 表示顶点 vjv_jvj 是否在顶点 viv_ivi 的子集 Sik\\mathcal S_{ik}Sik 中。它用于从 finf_{in}fin 中提取特定子集中的连通顶点,以获得相应的权值向量。Λkii=∑j(Aˉkij)+α\\mathbf Λ^{ii}_k = \\sum_j (\\mathbf {\\bar A}_k^{ij}) + αΛkii=∑j(Aˉkij)+α 是标准化对角矩阵。ααα 被设置为0.001以避免空行。Wk\\mathbf W_kWk 为 1×11 × 11×1 卷积运算的 Cout×Cin×1×1C_{out} × C_{in} × 1 × 1Cout×Cin×1×1 权向量,表示公式1中的权函数 www。MkM_kMk 是一个 N×NN × NN×N 的注意力图,表示每个顶点的重要性。⊙\\odot⊙ 表示点积。
对于时间维度,由于每个顶点的邻居数固定为2(两个连续帧中的对应关节),因此执行类似经典卷积操作的图卷积是很简单的。具体来说,我们对上面计算的输出特征图进行 Kt×1K_t × 1Kt×1 卷积,其中 KtK_tKt 为时间维的核大小。
在说本篇论文的创新前,先说明一下 ST-GCN 的缺点。
一是 ST-GCN 的注意力机制灵活性不够,掩码 MkM_kMk 是与邻接矩阵直接相乘,这里说的相乘是按元素相乘,并不是矩阵相乘。这就造成一个现象,就是如果邻接矩阵 AkA_kAk 里面部分元素为0,那么无论 MkM_kMk 对应元素为何值,最后结果都是0。换句话说就是不会创造不存在的连接,比如对于“行走”动作,手和腿的联系很大,但是手和腿没有直接相连,所以效果不好。
二是没有利用骨骼数据的第二特征,这里第一特征就是关节坐标,第二特征就是骨骼的长度和方向。直觉上,第二特征也包含了丰富的行为信息。
双流自适应图卷积网络
详细介绍我们提出的双流自适应图卷积网络(2s-AGCN)的组成部分。
1. 自适应图卷积层
我们提出的自适应图卷积层以端到端学习的方式使图的拓扑结构与网络的其他参数一起优化。图对于不同的层和样本是唯一的,这大大增加了模型的灵活性。同时将其设计为残差分支,保证了原模型的稳定性。
具体地,由公式(2)可知,图的拓扑实际上是由邻接矩阵和掩码决定的,分别为 AkA_kAk 和 MkM_kMk。AkA_kAk 决定了两个顶点之间是否有连接,MkM_kMk 决定了连接的强度。为了使图结构自适应,我们将公式(2)改为如下形式:fout=∑kKvWkfin(Ak+Bk+Ck)(3)\\mathbf f_{out} = \\sum^{K_v}_k \\mathbf W_k \\mathbf f_{in}(\\mathbf A_k + \\mathbf B_k + \\mathbf C_k)\\tag{3}fout=k∑KvWkfin(Ak+Bk+Ck)(3)主要区别在于图的邻接矩阵,它分为三部分:AkA_kAk,BkB_kBk 和 CkC_kCk。
这是针对 ST-GCN 的第一个缺点进行的改进,对邻接矩阵进行了改进。
第一部分 (Ak)(A_k)(Ak) 与公式(2)中原归一化 N×NN × NN×N 邻接矩阵 AkA_kAk 相同,它代表人体的物理结构。(另外一篇论文的 DGNN 结构对此进行了改进)
第二部分 (Bk)(B_k)(Bk) 也是一个 N×NN × NN×N 邻接矩阵。与 AkA_kAk 相比,BkB_kBk 的元素在训练过程中与其他参数一起参数化和优化。BkB_kBk 的值没有约束,这意味着图完全是根据训练数据学习的。通过这种数据驱动的方式,模型可以学习完全针对识别任务的图形,并且对于不同层中包含的不同信息更加个性化。注意,矩阵中的元素可以是任意值。它不仅表明两个关节之间是否存在连接,而且还表明连接的强度。它可以起到与公式(2)中 MkM_kMk 所起到的注意机制相同的作用。但是,原来的注意力矩阵 MkM_kMk 是点乘 AkA_kAk,也就是说,如果 AkA_kAk 中有一个元素为0,那么无论 MkM_kMk 的值是多少,它都是0。因此,它不能生成原来物理图中不存在的新的连接。从这个角度来看,BkB_kBk 比 MkM_kMk 更灵活。
第二部分 BkB_kBk 和第一部分类似,也是一个 N×NN×NN×N 的邻接矩阵,这里有所不同的是,BkB_kBk 是一个可训练的权重,而且没有对其进行如归一化等任何约束条件,也就是 BkB_kBk 完全是从数据学习过来的参数。他不仅能表示两个节点是否存在联系,而且能表示联系的强弱。乍一看 BkB_kBk 似乎和之前提到的掩码 MkM_kMk 没什么区别,这里与 ST-GCN 不同的是融合方式。ST-GCN 是相乘,这里是相加,相加就可以产生不存在的联系(0 * 任意数 = 0,0 + 任意数 = 任意数)。
第三部分 (Ck)(C_k)(Ck) 是一个依赖于数据的图,它为每个样本学习一个唯一的图。为了确定两个顶点之间是否存在连接以及连接的强度,我们应用归一化嵌入高斯函数来计算两个顶点的相似度:
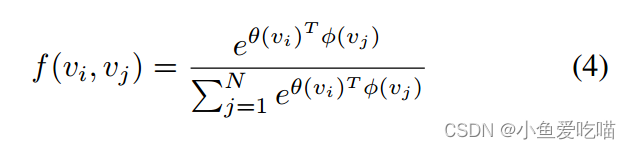
其中 NNN 是顶点的总数。我们使用点积来测量嵌入空间中两个顶点的相似性。
具体来说,给定大小为 Cin×T×NC_{in}×T ×NCin×T×N 的输入特征图 fin\\mathbf f_{in}fin,我们首先用两个嵌入函数 θ\\thetaθ 和 ϕ\\phiϕ 将其嵌入到 Ce×T×NC_e×T ×NCe×T×N 中。通过大量的实验,我们选择一个 1×11 × 11×1 的卷积层作为嵌入函数。两个嵌入的特征图被重新排列和重塑为 N×CeTN×C_eTN×CeT 矩阵和 CeT×NC_eT × NCeT×N 矩阵。然后将它们相乘,得到 N×NN ×NN×N 相似度矩阵 CkC_kCk,其中元素 CkijC^{ij}_kCkij 表示顶点 viv_ivi 和顶点 vjv_jvj 的相似度。将矩阵的值归一化为 0−10 - 10−1,作为两个顶点的软边。由于归一化高斯函数具有 softmaxsoftmaxsoftmax 运算,我们可以根据公式(4)像下面这样计算 CkC_kCk:Ck=softmax(finTWθkTWφkfin)(5)\\mathbf C_k = softmax(\\mathbf f_{in}^T \\mathbf W^T_{θk} \\mathbf W_{φk} \\mathbf f_{in}) \\tag{5}Ck=softmax(finTWθkTWφkfin)(5)其中 Wθ\\mathbf W_{\\theta}Wθ 和 Wϕ\\mathbf W_{\\phi}Wϕ 分别是嵌入函数 θ\\thetaθ 和 ϕ\\phiϕ 的参数。
第三部分 CkC_kCk 是对每个样本学习一个独有的图。它用的是非常经典的高斯嵌入函数,功能就是捕捉关节之间的相似性。他的功能其实和 BkB_kBk 有点类似,就是确定两个顶点是否存在连接和连接的强弱。说实话我是不太懂他们在功能上的差别在哪,我能理解的就是 BkB_kBk 中的元素没有进行归一化等处理,功能就是注意力机制。而 CkC_kCk 中的元素是0-1的概率,是通过 softmax 层处理过的。
其实关于 CkC_kCk,我还有点话想说,生成 CkC_kCk 的方式叫做高斯嵌入函数,也就是 θ\\thetaθ 分支和 ϕ\\phiϕ 分支相乘得到 CkC_kCk。这个 ⊗⊗⊗ 是 pytorch 里面的 torch.matmul()函数,这个函数的工作方式大家可以自行百度,这里的维度并不是图上提到的 N×CeTN×C_eTN×CeT ,其实前面还有批次乘以 MMM(表示最大人数,一般是2)。还有一点,就是下图的第二个相乘,也就是 Cin×N⊗N×NC_{in}×N ⊗ N×NCin×N⊗N×N,他后面其实还有个 softmax 层,这部分因为是调参做的一些改进,文章并没有写到原理上。关于 softmax 的维度等参数,大家可以看看原论文的代码。
我们不是直接用 BkB_kBk 或 CkC_kCk 取代原来的 AkA_kAk,而是把它们加进去。BkB_kBk 的值和参数 θ\\thetaθ、ϕ\\phiϕ 初始化为0。这样既可以增强模型的灵活性,又不会降低原有的性能。
下图是其整体图,从图上可以看到输入数据的形状是 Cin×T×NC_{in}×T×NCin×T×N ,编码成 Ce×T×NC_e×T×NCe×T×N ,这里的 CeC_eCe 论文上没有明确说是什么,我是看了代码才看懂,这里的 CeC_eCe 是输出通道除以4。输出通道和输入通道一般有两种关系,要么是输出通道和输入通道相等,要么输出通道是输入通道的一半。除以4的目的是因为最后的结果是 N×NN×NN×N 的,不包含通道维度,所以这样做可以减少计算量,只要控制 1×11×11×1 卷积层的输出通道就行了。因为其实 1×11×11×1 的卷积的参数量挺大的。原本 2s-AGCN 的参数量就比 ST-GCN 多很多。
自适应图卷积层的总体结构如下图所示:
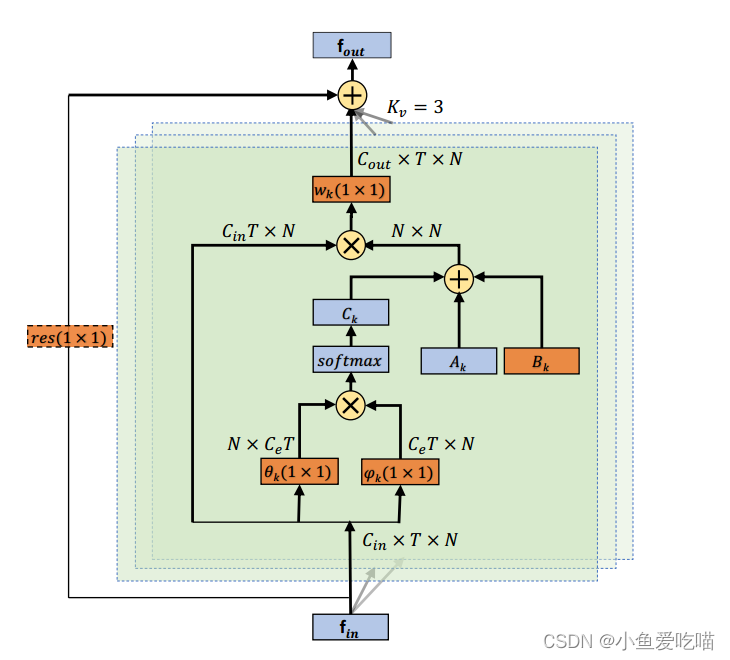
每一层共有三种类型的图,分别是 AkA_kAk,BkB_kBk 和 CkC_kCk。橙色框表示该参数是可学习的。(1×1)(1 × 1)(1×1) 为卷积核的大小,KvK_vKv 表示子集的数量。⊕⊕⊕ 表示按元素求和,⊗⊗⊗ 表示矩阵乘法。残差框(虚线)仅在 CinC_{in}Cin 与 CoutC_{out}Cout 不相同时才需要。
除前面介绍的 AkA_kAk,BkB_kBk,CkC_kCk 外,卷积的核大小(KvK_vKv)设置与之前相同,即3。wkw_kwk 为公式(1)中引入的权重函数,其参数为公式(3)中的 Wk\\mathbf W_kWk。为每一层添加一个类似于[10]的残差连接,这允许将该层插入任何现有模型而不破坏其初始行为。如果输入通道数与输出通道数不同,则在残差路径中插入 1×11 × 11×1 卷积(图2中橙色虚线框),将输入转换为与输出在通道维度上匹配。
2. 自适应图卷积块
时间维的卷积与 ST-GCN 相同,即对 C×T×NC×T × NC×T×N 特征图进行 Kt×1K_t × 1Kt×1 卷积。空间 GCN 和时间 GCN 后面都有一个批归一化(BN)层和一个 ReLU 层。如下图所示,一个基本块是一个空间 GCN (Convs),一个时间 GCN (Convt)和一个额外的 dropout 层的组合,droprate 设置为0.5。为了稳定训练,为每个块添加一个残差连接。
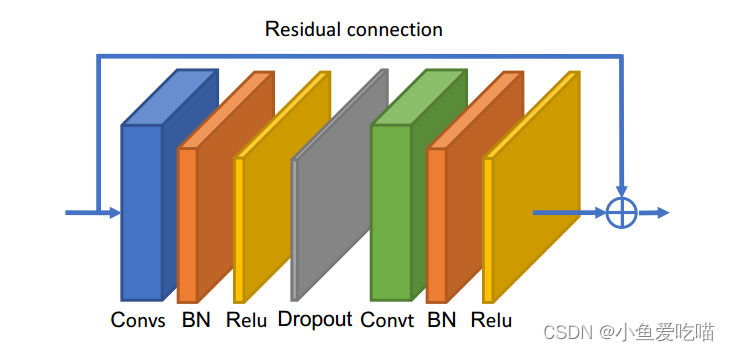
上图为自适应图卷积块的说明,Convs 表示空间 GCN,Convt 表示时间 GCN,后面都有 BN 层和 ReLU 层。此外,为每个块添加一个残差连接。
3. 自适应图卷积网络
自适应图卷积网络(AGCN)就是这些基本块的堆栈,如下图所示,总共有9个块(B1−B9B1-B9B1−B9)。每个块的输出通道数为64、64、64、128、128、256、256和256。在开始时添加数据 BN 层以规范化输入数据。最后进行全局平均池化层,将不同样本的特征图池到相同大小。最终输出被发送到 softmaxsoftmaxsoftmax 分类器以获得预测结果。
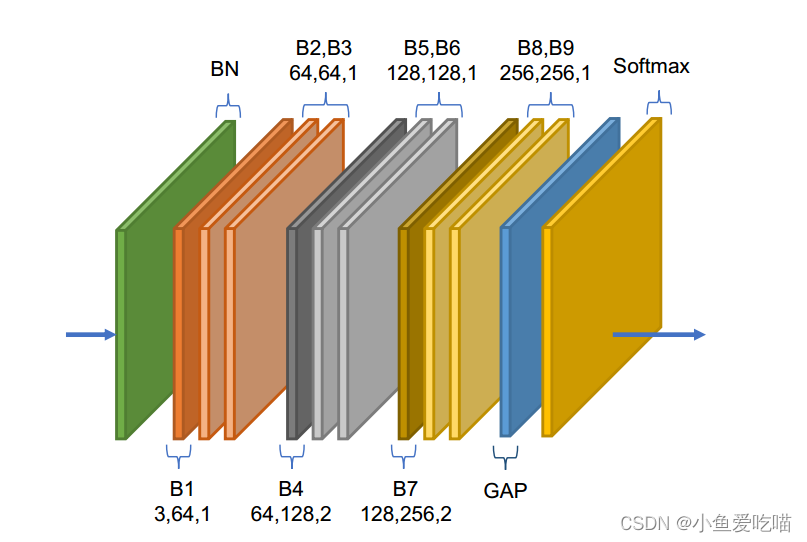
图中,每个块的三个数字分别表示输入通道数、输出通道数和步幅。GAP 表示全局平均池化层。
4. 双流网络
二阶信息,即骨骼信息,对于基于骨骼的动作识别也很重要,但在之前的工作中被忽略了。在本文中,我们提出了显式建模的二阶信息,即骨骼信息,用一个双流框架来增强识别。
特别地,由于每根骨骼都被两个关节固定,我们定义离骨架重心较近的关节为源关节,离重心较远的关节为目标关节。每根骨骼都表示为一个从源关节指向目标关节的向量,其中不仅包含长度信息,还包含方向信息。例如,给定一根源关节 v1=(x1,y1,z1)\\mathbf v_1 = (x_1, y_1, z_1)v1=(x1,y1,z1),目标关节 v2=(x2,y2,z2)\\mathbf v_2 = (x_2, y_2, z_2)v2=(x2,y2,z2) 的骨,则该根骨骼的向量计算为 ev1,v2=(x2−x1,y2−y1,z2−z1)\\mathbf e_{v_1,v_2} = (x_2−x_1, y_2−y_1, z_2−z_1)ev1,v2=(x2−x1,y2−y1,z2−z1)。
长度和方向看起来比关节坐标要复杂,其实很简单。首先寻找一个人体骨骼的重心,就是人胸腔部分作为中心点,因为每个骨骼都有两个点,把靠近中心点的关节看做源关节,远离中心点的关节看做目标关节。所以说关节就是点,骨骼就是从一个点指向另外一个点的向量,向量的长度就是骨骼的长度,向量的方向就是骨骼的方向。
由于骨架数据图没有循环,每一块骨骼都可以被分配一个唯一的目标关节。目标关节的数量比骨头的数量多1,因为中心关节没有分配给任何骨头。为了简化网络的设计,我们在中心关节中添加了一个值为0的空骨。通过这种方式,骨骼的图形和网络都可以像关节一样设计,因为每个骨骼都可以绑定一个唯一的目标关节。
因为骨骼是两个关节组成一个骨骼,而且没有环状的图,所以关节数比骨骼数多1个。这里添加一个值为0的空关节,这样关节数与骨骼数就相同,网络也相同。
我们使用 J-stream 和 B-stream 分别表示关节和骨骼的网络。整体架构(2s-AGCN)如下图所示。
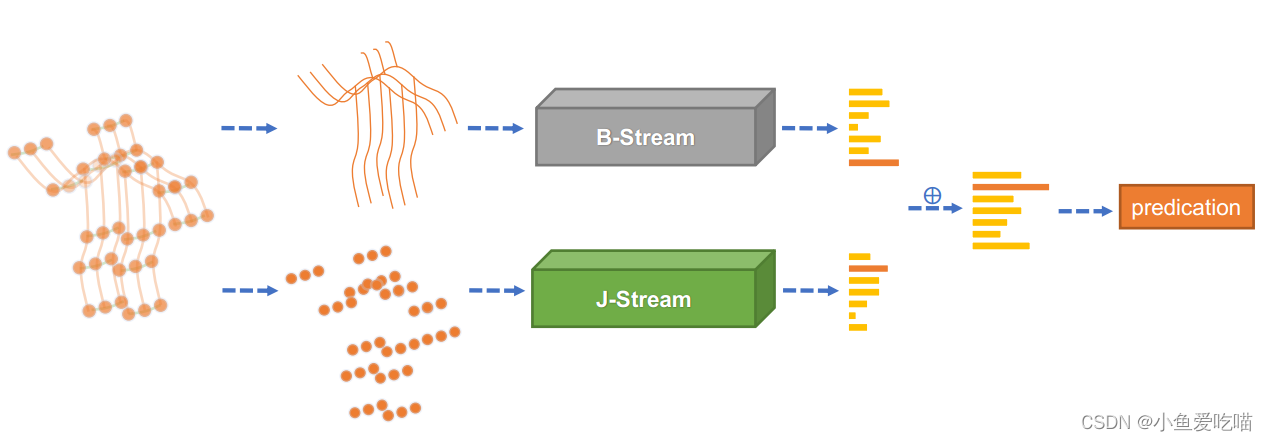
给定一个样本,我们首先根据关节数据计算骨骼数据。然后将关节数据和骨骼数据分别输入 J-stream 和 B-stream。最后,将两个流的 softmaxsoftmaxsoftmax 分数相加,得到融合分数并预测动作标签。
实验
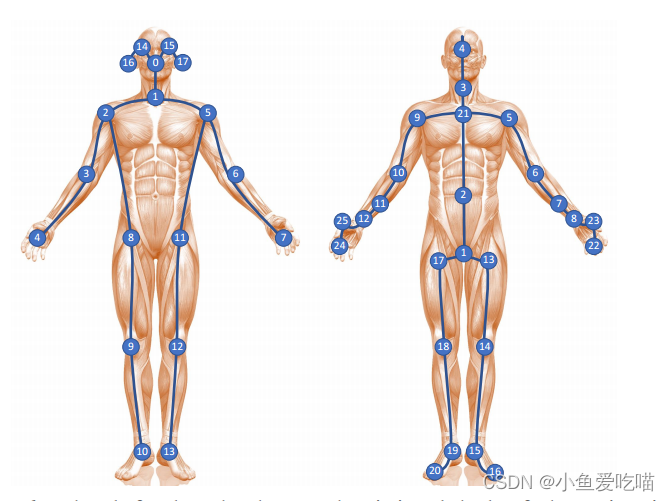
左图显示了 Kinetics-Skeleton 数据集的关节标签,右图显示了 NTU-RGBD 数据集的关节标签。
训练细节
所有实验均在 PyTorch 深度学习框架上进行。采用 Nesterov 动量为0.9的随机梯度下降(SGD)作为优化策略,批大小为64,选择交叉熵作为梯度反向传播的损失函数,权重衰减设置为0.0001。
对于 NTU-RGBD 数据集,数据集的每个样本中最多有两个人。如果样本中主体的数量小于2,我们用0填充第二个主体。每个样本的最大帧数为300,对于小于300帧的样本,我们重复样本直到达到300帧。学习率设置为0.1,在第30和第40 epoch 分别除以10。训练过程在第50个 epoch 结束。
对于 Kinetics-Skeleton 数据集,输入张量的大小设置同上,包含150帧,每帧2个主体。我们相同的数据增强方法,具体而言,我们从输入骨架序列中随机选择150帧,并通过随机选择的旋转和平移略微干扰关节坐标。学习率也设置为0.1,并在第45 epoch和第55 epoch除以10。训练过程在第65 epoch 结束。
双流框架
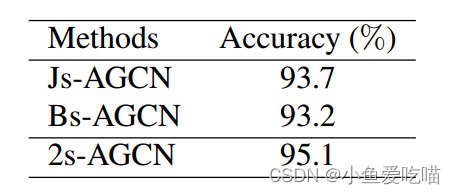
另一个重要的改进是对二阶信息的利用。在这里,我们比较了单独使用每种输入数据的性能,如表中的 Js-AGCN 和 Bs-AGCN,以及将它们组合使用时的性能,如表中的 2s-AGCN。显然,双流方法优于基于单流的方法。
Conclusion
在这项工作中,我们提出了一种新的自适应图卷积神经网络(2s-AGCN)用于基于骨骼的动作识别。将骨架数据的图结构参数化,嵌入到网络中,与模型共同学习更新。这种数据驱动的方法增加了图卷积网络的灵活性,更适合于动作识别任务。
此外,传统方法往往忽略或低估了骨骼数据中的二阶信息,即骨骼信息的重要性。在这项工作中,我们提出了一个双流框架来显式地使用这种类型的信息,这进一步提高了性能。最终模型在 NTU-RGBD 和 Kinetics 两个大规模动作识别数据集上进行了评估,并在这两个数据集上都达到了最先进的性能。
总的来说这篇论文比较好理解,思路也比较明确,针对 ST-GCN 的两个缺点进行改进,提出两个创新点。作者提到的用相加取代相乘的注意力机制是一种很好的创新,另外就是利用骨骼的长度和方向也是最近两年开始使用的。
论文理解
参考:博客园
参考:【骨骼行为识别】2s-AGCN论文理解
代码解读
参考文章:解读 2s-AGCN 代码