mybatis-源码

面试and redis mysql
1、流程
通过工厂模式创建sqlsession,
sqlsession=sqlSessionFactory.openSession();
根据不同需求,创建不同的sqlsession。
传递不同参数,获取sqlsession 不同状态。
1.1 解析对象
MappedStatement
//
/* 存放解析映射配置文件的内容* <select id="selectOne" resultType="com.itheima.pojo.User" parameterType="com.itheima.pojo.User">* select * from user where id = #{id} and username = #{username}* </select>*/
public class MappedStatement {// 1.唯一标识 (statementId namespace.id)private String statementId;// 2.返回结果类型private String resultType;// 3.参数类型private String parameterType;// 4.要执行的sql语句private String sql;// 5.mapper代理:sqlcommandTypeprivate String sqlcommandType;}
Configuration
/* 存放核心配置文件解析的内容*/
public class Configuration {// 数据源对象private DataSource dataSource;// map : key :statementId value : 封装好的MappedStatementprivate Map<String,MappedStatement> mappedStatementMap = new HashMap<>();
}
1.2 openSession()
创建sqlsession 的同时也创建了Executor对象
把configuration 和Executor对象传递进
class SqlsessionFactory@Overridepublic SqlSession openSession() {// 执行器创建出来Executor executor = new SimpleExecutor();DefaultSqlSession defaultSqlSession = new DefaultSqlSession(configuration,executor);return defaultSqlSession;}
1.3 sqlsession 里面的方法
// 执行sql 需要定位到sql,从而执行,需要statementId
// 还需要传递执行sql 语句时候的 条件参数 where name=xxx
Sqlsession 接口
E List<E> selectList(String statementId,Object param);DefaultSqlsession 实现类@Override // user.selectList 1 tom userpublic <E> List<E> selectList(String statementId, Object params) throws Exception {MappedStatement mappedStatement = configuration.getMappedStatementMap().get(statementId);// 将查询操作委派给底层的执行器// executor 是底层执行器 SimpleExecutor// 传递 configuration 获取datasourceList<E> list = executor.query(configuration,mappedStatement,params);return list;}1.4 SimpleExecutor
2. 整体架构设计
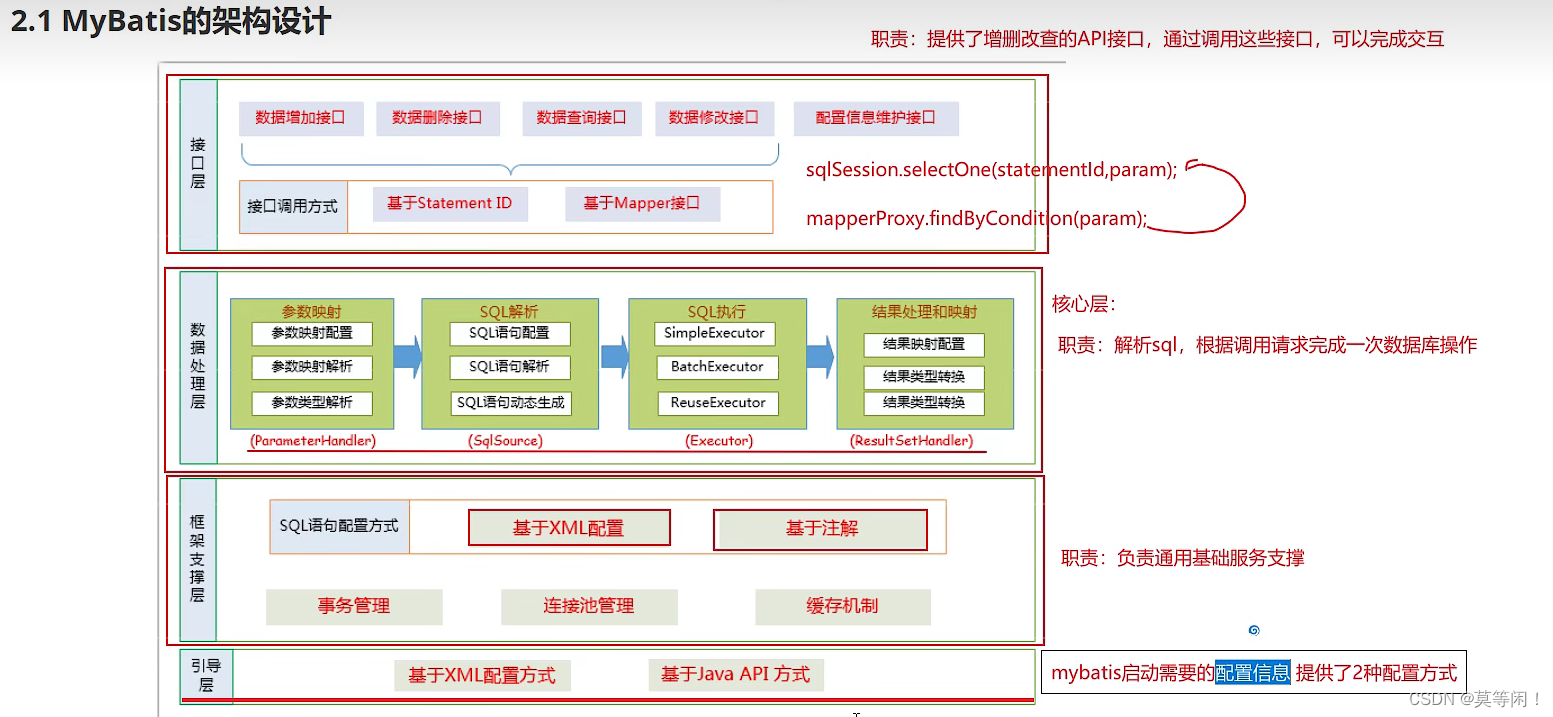
接口层、数据处理层、
2.1 组件调用关系
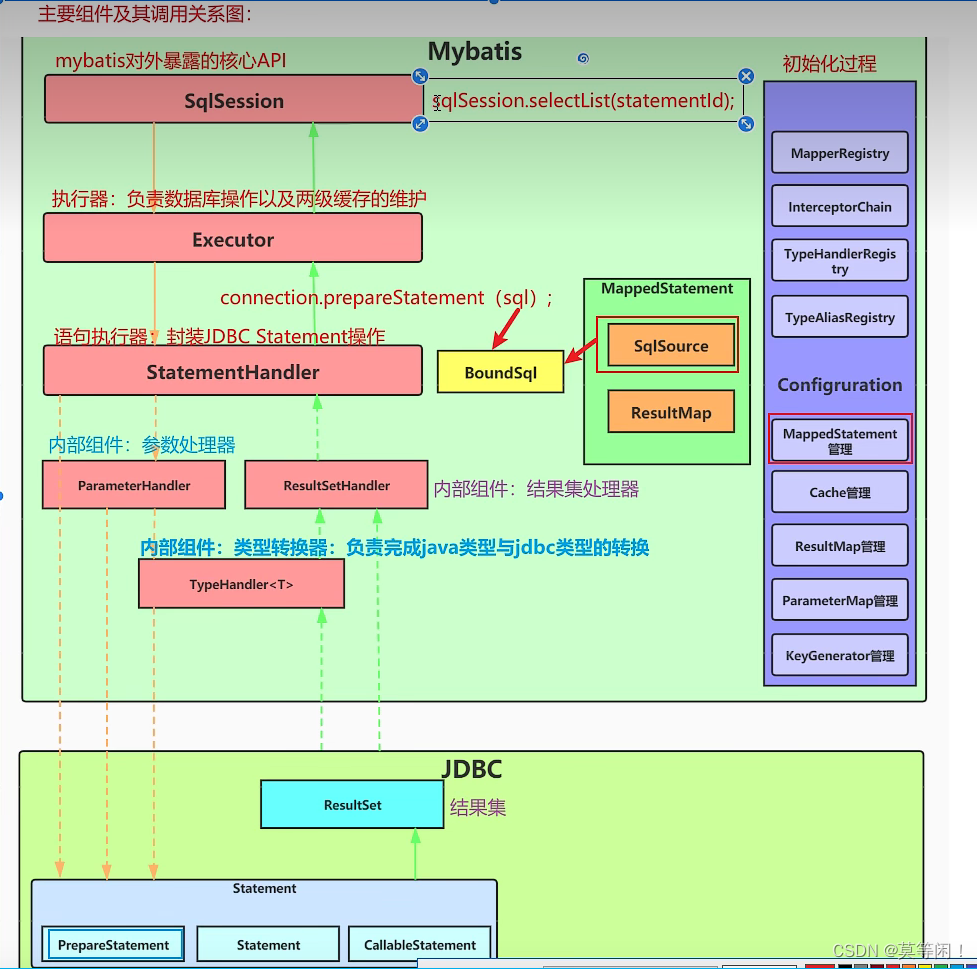
3 源码
3.1 加载配置文件
用classloadwrapper 而不是cloassload,为什么?
加载资源的时候,需要判断路径是否为空,加载的资源是否为空等。对判断进行封装,
3.2 build() 方法
- 解析配置文件封装configuration对象。
- 创建DefaultSqlsessionFactory对象
使用构建者模式 好处: 降低耦合,分离复杂对象创建
-
- 创建了XPathParser解析对象,根据inputstream解析成document对象,
-
- 创建了全局配置对象Configuration对象
// XMLConfigBuilder:用来解析XML配置文件// 使用构建者模式:好处:降低耦合、分离复杂对象的创建// 1.创建XPathParser解析器对象,//根据inputStream解析成了document对象 //2.创建全局配置对象Configuration对象XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);// parser.parse():使用XPATH解析XML配置文件,//将配置文件封装到Configuration对象// 返回DefaultSqlSessionFactory对象,//该对象拥有Configuration对象(封装配置文件信息)// parse():配置文件就解析完成了return build(parser.parse());
3.2.1 解析映射配置文件
XmlMapperBuilder 解析mapper.xml文件
- 映射配置文件的标签和属性如何被解析封装?
XmlMapperBuilder 解析mapper.xml文件,调用configurationElement()方法。从映射文件中的根标签开始解析,直到完整的解析完毕。
parseStatementNode(), 解析<insert><update><delete>子标签,通过构建者助手,创建MappedStatement对象
// 专门用来解析mapper映射文件XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());// 通过XMLMapperBuilder解析mapper映射文件mapperParser.parse();
//XmlMapperBuilder 类中的parse方法public void parse() {// mapper映射文件是否已经加载过if (!configuration.isResourceLoaded(resource)) {// 从映射文件中的<mapper>根标签开始解析,直到完整的解析完毕configurationElement(parser.evalNode("/mapper"));// 标记已经解析configuration.addLoadedResource(resource);// 为命名空间绑定映射bindMapperForNamespace();}
// configurationElement 方法解析标签private void configurationElement(XNode context) {// 解析<select>\\<insert>\\<update>\\<delete>子标签// 将cache对象封装到MappedStatement中buildStatementFromContext(context.evalNodes("select|insert|update|delete"));}buildStatementFromContext 解析标签,封装成mappedstatement对象。
parseStatementNode() 解析标签,封装称为mappedstatement对象。
/* 构建MappedStatement* @param list*/private void buildStatementFromContext(List<XNode> list) {if (configuration.getDatabaseId() != null) {buildStatementFromContext(list, configuration.getDatabaseId());}// 构建MappedStatementbuildStatementFromContext(list, null);}/* 2、专门用来解析MappedStatement* @param list* @param requiredDatabaseId*/private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) {for (XNode context : list) {// MappedStatement解析器final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);try {// // 解析select等4个标签,创建MappedStatement对象statementParser.parseStatementNode();} catch (IncompleteElementException e) {configuration.addIncompleteStatement(statementParser);}}}/* 解析<select>\\<insert>\\<update>\\<delete>子标签* // 通过构建者助手,创建MappedStatement对象*/public void parseStatementNode() {
// *创建SqlSource,解析SQL,封装SQL语句(未参数绑定)和入参信息// 问题:sql占位符如何进行的替换?动态sql如何进行的解析?SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);}
sql占位符如何替换?
动态sql如何解析?
封装到sqlsource对象,调用getBoundSql()方法,返回boundsql
public class BoundSql {private final String sql;private final List<ParameterMapping> parameterMappings;private final Object parameterObject;}
// *创建SqlSource,解析SQL,封装SQL语句(未参数绑定)和入参信息// 问题:sql占位符如何进行的替换?动态sql如何进行的解析?SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
3.2.2 sqlsource 占位符替换 boundsql 对象
sql占位符如何进行替换?
- 通过 ParameterMappingTokenHandler ,GenericTokenParser 工具类,将#{name} 替换成 ?,并将里面的值 封装到 parameterMappings 集合中 ,最终将解析后的sql语句 以及#{} 里面的值存到Sqlsource中,后续获取解析的sql,需要调用·
getBoundSql()方法
动态sql如何进行解析?
- 获取select标签里面的子标签,判断这个子标签是不是
元素节点,如果是,表示带有动态sql,那么会分别使用每一个动态标签的处理器
(nodeHandlerMap.get(nodeName) 动态sql标签名称),调用handlerNode()完成解析,把里面的内容,·封装成不同类型的sqlnode进行返回,返回的是dyamicSqlsource对象,调用getBoundSql方法时,重新完成sql的解析拼接工作。
/* 解析select\\insert\\ update\\delete标签中的SQL语句,最终将解析到的SqlNode封装到MixedSqlNode中的List集合中。 - 将带有${}号的SQL信息封装到TextSqlNode;* - 将带有#{}号的SQL信息封装到StaticTextSqlNode* - 将动态SQL标签中的SQL信息分别封装到不同的SqlNode中* @param node* @return*/protected MixedSqlNode parseDynamicTags(XNode node) {.....// 解析动态sqlString nodeName = child.getNode().getNodeName();// 动态SQL标签处理器NodeHandler handler = nodeHandlerMap.get(nodeName);if (handler == null) {throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");}handler.handleNode(child, contents);// 动态SQL标签是dynamic的isDynamic = true;.....}

// 初始化动态SQL中的节点处理器集合
private void initNodeHandlerMap() {nodeHandlerMap.put("trim", new TrimHandler());nodeHandlerMap.put("where", new WhereHandler());nodeHandlerMap.put("set", new SetHandler());nodeHandlerMap.put("foreach", new ForEachHandler());nodeHandlerMap.put("if", new IfHandler());nodeHandlerMap.put("choose", new ChooseHandler());nodeHandlerMap.put("when", new IfHandler());nodeHandlerMap.put("otherwise", new OtherwiseHandler());nodeHandlerMap.put("bind", new BindHandler());}
在createSqlSource()方法中
默认是XmlLanguageDriver
@Overridepublic SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) {// 初始化了动态SQL标签处理器XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);// 解析动态SQLreturn builder.parseScriptNode();}
parameterMappingTokenHandler 标记处理器 将#{} 转为?
GenericTokenParser 标记解析器
封装到sqlsource对象,调用getBoundSql()方法,返回boundsql
public SqlSource parse(String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters) {
// 标记处理器
ParameterMappingTokenHandler handler = new
ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);// 创建分词解析器 标记解析器GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);String sql;// 解析#{}sql = parser.parse(originalSql);// 将解析之后的SQL信息,封装到StaticSqlSource对象中// SQL字符串是带有?号的字符串,?相关的参数信息,封装到ParameterMapping集合中return new StaticSqlSource(configuration, sql, handler.getParameterMappings());}
// content #{name} 那么content就是 name@Overridepublic String handleToken(String content) {parameterMappings.add(buildParameterMapping(content));return "?";}
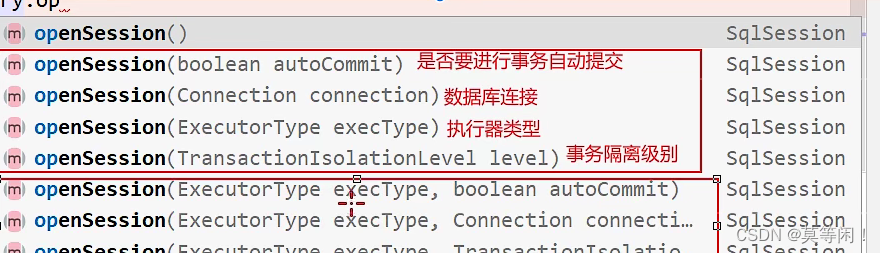
3.3 opsession() 方法
opensession()方法执行逻辑?
(1)创建事务对象
(2)创建了执行器对象cachingExecutor
(3)创建了DefaultSqlSession对象
sqlsessionfactory.opensession();
工厂模式,通过方法的重载创建不同的SQL session对象
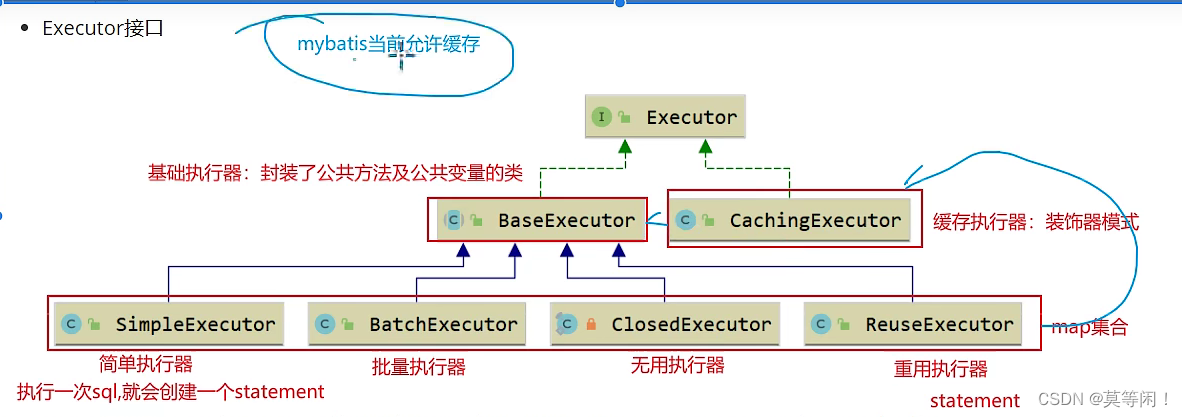
- BaseExecutor:基础执行器,封装了子类的公共方法,包括一级缓存、延迟加载、回滚、关闭等功能;
- SimpleExecutor:简单执行器,每执行一条 sql,都会打开一个 Statement,执行完成后关闭;
- ReuseExecutor:重用执行器,相较于 SimpleExecutor 多了 Statement 的缓存功能,其内部维护一个
Map<String, Statement>,每次编译完成的 Statement 都会进行缓存,不会关闭; - BatchExecutor:批量执行器,基于 JDBC 的
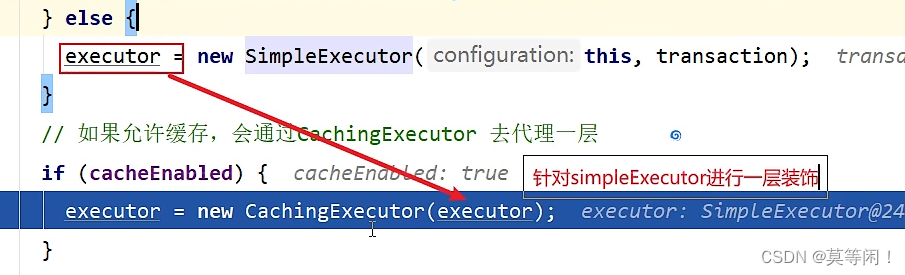
addBatch、executeBatch功能,并且在当前 sql 和上一条 sql 完全一样的时候,重用 Statement,在调用doFlushStatements的时候,将数据刷新到数据库; - CachingExecutor:缓存执行器,装饰器模式,在开启缓存的时候。会在上面三种执行器的外面包上 CachingExecutor;
构建执行器对象,进行装饰,返回缓存执行器。
3.4 sqlsession 执行流程
3.4.1 getBoundSql
//第一步@Overridepublic <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {// 获取绑定的SQL语句,比如 "SELECT * FROM user WHERE id = ? "BoundSql boundSql = ms.getBoundSql(parameterObject);// 生成缓存KeyCacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);}
- 根据传递的参数,获取boundsql,(0包括 sql语句,parametermappings,parameterobject)
- 生成cachekey
3.4.2cachekey 缓存

流程
- 生成cachekey
- 根据cachekey查询缓存中是否有数据
- 没有数据,查询数据库
- 将数据库查询结果存到缓存中。map.put(cachekey,查询结果)
问题
cachekey 对象有几部分构成?
cachekey hash值
statementId,sql语句,分页参数值, 参数值,enviromentID值 五部分
怎么完成cachekey的比较,保证cachekey的唯一性
比较cachekey的 hash值 和equals方法,通过hashcode保证唯一性
//statementIdcacheKey.update(ms.getId()); // statementId// 分页参数cacheKey.update(rowBounds.getOffset());//cacheKey.update(rowBounds.getLimit());//// sqlcacheKey.update(boundSql.getSql());// 参数的值cacheKey.update(value);// issue #176// 当前环境的值也会设置cacheKey.update(configuration.getEnvironment().getId());
。
3.4.3 缓存优先级
同时开启两级缓存,那么先查二级缓存,如果没有再一级缓存,在查db
3.4.4 statementhandler
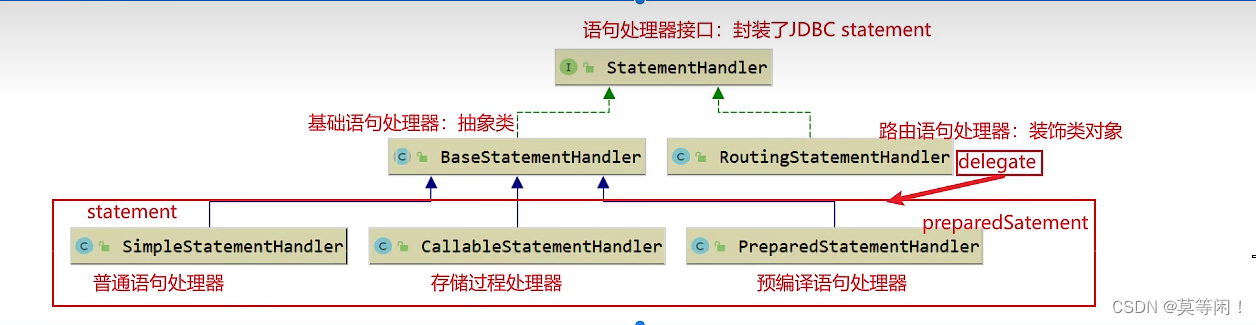
statementhandler:对jdbc statement的封装,语句处理器接口
通过statementHandler 创建statement 对象
statementHandler.prepare()创建statement对象,(可能是simplestatement,或者preparement对象)
@Overridepublic <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {Statement stmt = null;try {// 1. 获取配置实例Configuration configuration = ms.getConfiguration();// 2. new一个StatementHandler实例StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);// 3. 准备处理器,主要包括创建statement以及动态参数的设置stmt = prepareStatement(handler, ms.getStatementLog());// 4. 执行真正的数据库操作调用return handler.query(stmt, resultHandler);} finally {// 5. 关闭statementcloseStatement(stmt);}}private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {Statement stmt;// 1. 获取代理后(增加日志功能)的Connection对象Connection connection = getConnection(statementLog);// 2. 创建Statement对象(可能是一个SimpleStatement,一个PreparedStatement或CallableStatement)stmt = handler.prepare(connection, transaction.getTimeout());// 3. 参数化处理handler.parameterize(stmt);// 4. 返回执行前最后准备好的Statement对象return stmt;}SimpleExecutor.doquery()
3.4.5 parameterHandler 参数设置
动态参数设置
调用·TypeHandler 进行java 类型到jdbc类型转换,进行参数设置。
3.4.6 解析结果集
ResultSetHandler: 结果集处理器,完成对查询结果的处理。
- 获取resultser对象
- 获取映射关系 resulttype标签
- 根据映射关系封装实体
5.代理方式
问题1:<package name="com.itheima.mapper"/> 是如何进行解析的?
在解析name 属性,
–>根据包名,加载该包下所有的mapper接口。
---->将mapper接口以及mapper接口对应的代理工厂对象存储到 knowMappers map集合中。( Map<Class<?>, MapperProxyFactory<?>> knownMappers = new HashMap<>();)
---->根据mapper接口的路径 进行 · /替换,
----> 根据替换后的路径找到mapper.xml文件
-----> 调用XmlMapperBuilder.parse() 方法解析 同时 完成注解方式的解析。
MapperRegistry

CLASS MapperRegistryprivate final Map<Class<?>, MapperProxyFactory<?>> knownMappers =new HashMap<>();// 将包下所有的mapper接口以及它的代理工厂对象存储到一个Map集合中,//key为mapper接口类型,value为代理对象工厂configuration.addMappers(mapperPackage);// 将mapper接口以及它的代理对象存储到一个Map集合中,//key为mapper接口类型,value为代理对象工厂knownMappers.put(type, new MapperProxyFactory<>(type));
·为什么要同包同名 mapper.xml 和 mapper接口
根据mapper接口路径 把 点 替换成 斜杠 com.it.mapper.UserMapper
----- -> com/it/mapper/UserMapper.xml 再去找对应的mapper.xml 文件。
问题2:sqlSession.getMapper(UserMapper.class); 是如何生成的代理对象?
通过jdk 动态代理生成代理对象。
(T) Proxy.newProxyInstance(mapperInterface.getClassLoader(),new Class[] { mapperInterface }, mapperProxy);
问题3:mapperProxy.findByCondition(1); 是怎么完成的增删改查操作?
代理对象,调用接口方法,执行invoker 方法,
------->根据 SqlCommandType 值判断是 c r u d 的哪种操作
------->查询: 根据返回值判断调用 sqlsession.selectList() 还是selectOne
----> 增 删 改 : 执行sqlsession.update()
6.mybatis 插件机制
-
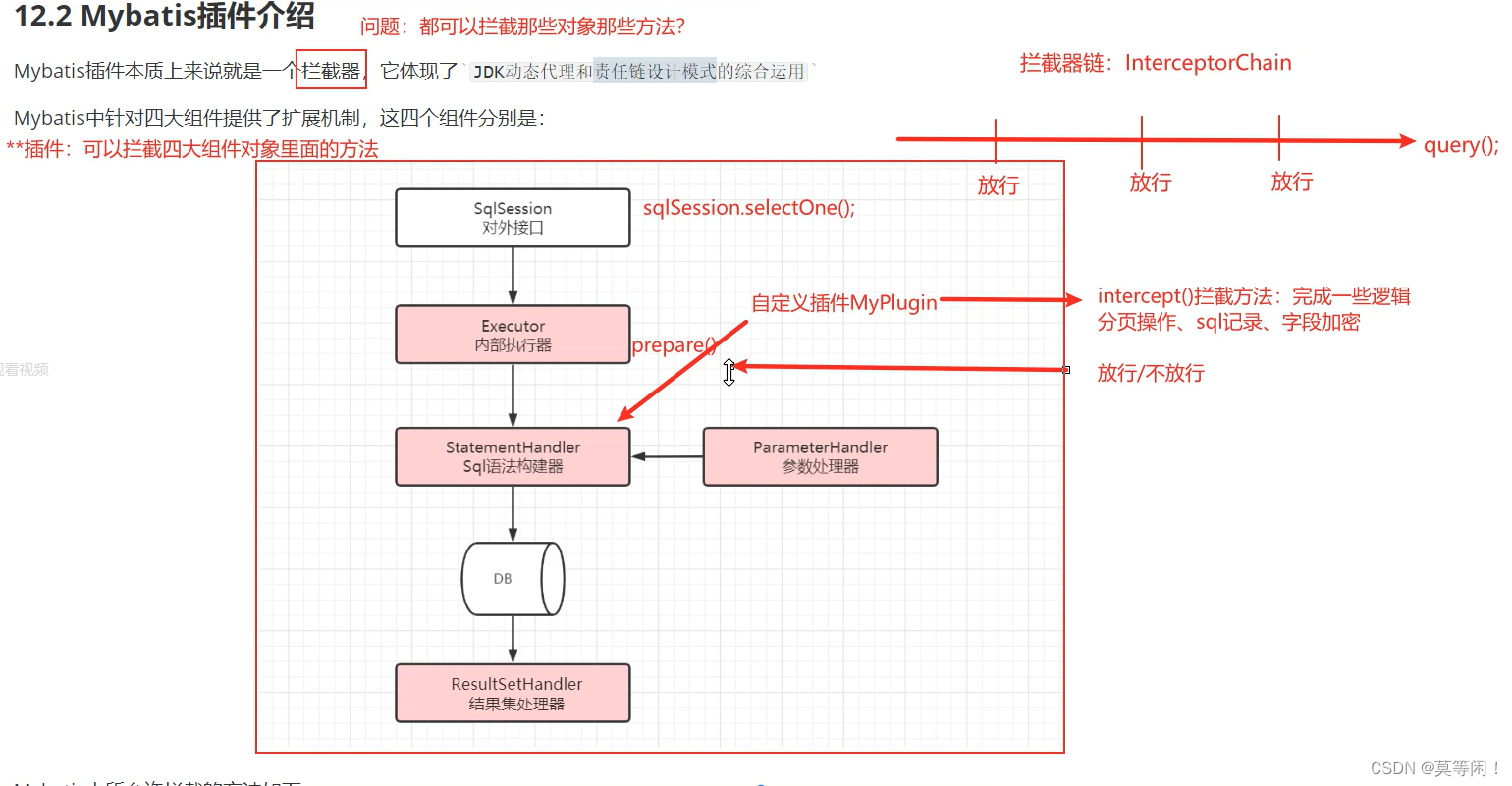
mybatis 插件 是 一种扩展机制,实现功能扩展。
-
本质 拦截器 -
体现了jdk 动态代理,和责任链模式。 -
Mybatis中所允许拦截的方法如下:
- Executor 【SQL执行器】【update,query,commit,rollback】
- StatementHandler 【Sql语法构建器对象】【prepare,parameterize,batch,update,query等】
- ParameterHandler 【参数处理器】【getParameterObject,setParameters等】
- ResultSetHandler 【结果集处理器】【handleResultSets,handleOuputParameters等】
6.1 插件相关类
@Interceptors
前面已经知道Mybatis插件是可以对Mybatis中四大组件对象的方法进行拦截,那拦截器拦截哪个类的哪个方法如何知道,就由下面这个注解提供拦截信息
指定 要拦截哪个对象里面的哪个方法
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Intercepts { //Signature[] value();
}
@Signature 详细配置要拦截哪些对象里面的哪些方法
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({})
public @interface Signature {// 拦截的类Class<?> type();// 拦截的方法String method();// 拦截方法的参数 Class<?>[] args();}
type= StatementHandler.Class
method=“prepare()”
args=Connection.Class
思考 拦截到目标方法后,要执行的逻辑写在哪里。
@Intercepts({@Signature(type = StatementHandler.class,method = "prepare",args = {Connection.class,Integer.class})
})
public interface Interceptor {/* 真正方法被拦截执行的逻辑 @param invocation 主要目的是将多个参数进行封装* :target 被拦截的对象 statementHandler* method 被拦截对象的方法 prepare* args prepare()方法的参数*/Object intercept(Invocation invocation) throws Throwable;// 生成目标对象的代理对象,添加到拦截器链中// tatget 目标对象default Object plugin(Object target) {// warp 将目标对象,基于jdk动态代理生成代理对象return Plugin.wrap(target, this);}// 可以拦截器设置一些属性// properties 插件初始化的时候,会设置的一些值的属性集合default void setProperties(Properties properties) {// NOP}
}public class Invocation {private final Object target;private final Method method;private final Object[] args;
}
6.2 自定义插件
需求:把Mybatis所有执行的sql都记录下来
步骤:① 创建Interceptor的实现类,重写方法
② 使用@Intercepts注解完成插件签名 说明插件的拦截四大对象之一的哪一个对象的哪一个方法
③ 将写好的插件注册到全局配置文件中
执行顺序
setProperties()---->plugin()----->intercept()
6.3 源码分析
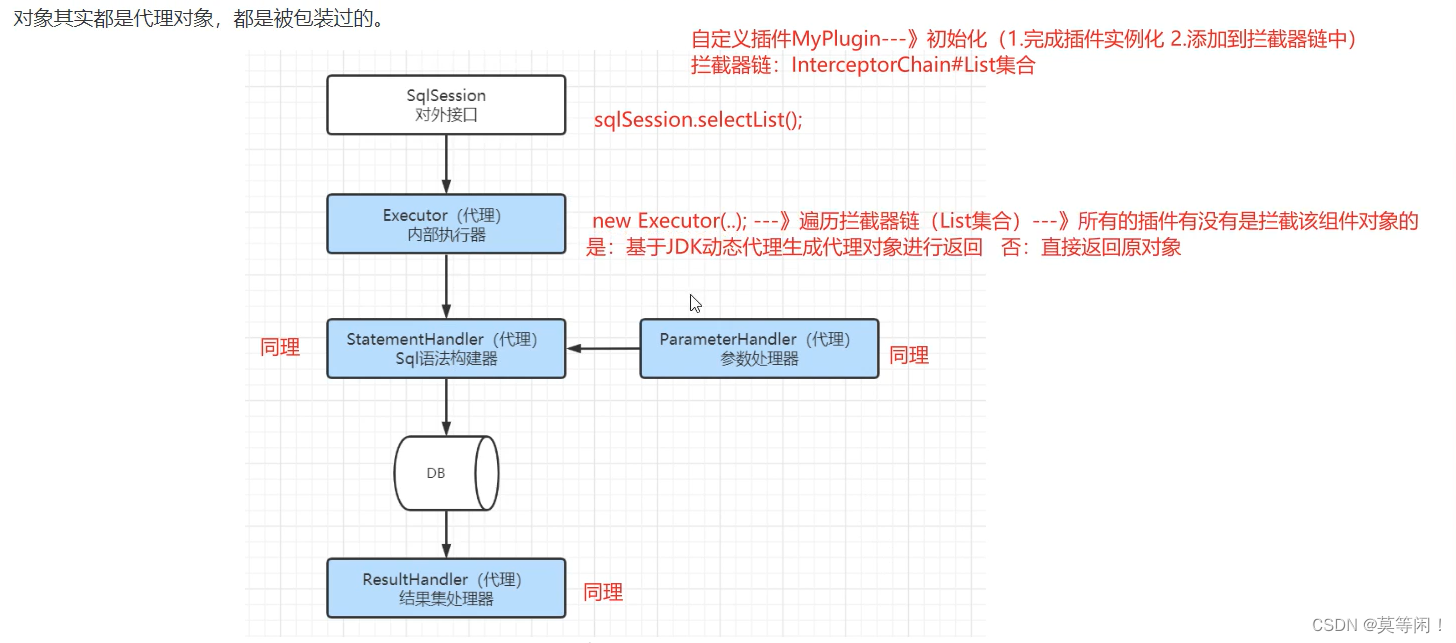
核心思想:
就是使用JDK动态代理的方式,对这四个对象进行包装增强。具体的做法是,创建一个类实现Mybatis的拦截器接口,并且加入到拦截器链中,在创建核心对象的时候,不直接返回,而是遍历拦截器链,把每一个拦截器都作用于核心对象中。这么一来,Mybatis创建的核心对象其实都是代理对象,都是被包装过的。
new Executor() 拦截器 构造方法中,遍历拦截器链
问题
插件对象是如何实例化的?
build方法时,解析全局配置文件,得到所配置的interceptor类的全路径,根据类全路径使用反射构建出实例对象,调用setproperties 方法设置属性的值。
插件实例化对象如何添加到拦截器中的?
添加到interceptors里面的list 集合中
组件对象的代理对象是如何产生的?
wrap方法中,构建组件对象时,判断组件对象是否有
拦截器对象拦截了该对象,
如果是,那么采用jdk动态代理产生该组件对象。
如果不是,返回原来的对象。
6.4 拦截逻辑
同一个组件对象的同一个方法,是否可以被多个拦截器进行拦截?
StatementHandler 里面的prepare()方法 被多个拦截器插件拦截
当然
所以我们配置在最前面的拦截器最先被代理,但是执行的时候却是最外层的先执行。
具体点:
假如依次定义了三个插件:插件1,插件2 和 插件3。
那么List中就会按顺序存储:插件1,插件2 和 插件3。
而解析的时候是遍历list,所以解析的时候也是按照:插件1 ,插件2,插件3的顺序。
但是执行的时候就要反过来了,执行的时候是按照:插件3,插件2和插件1的顺序进行执行。
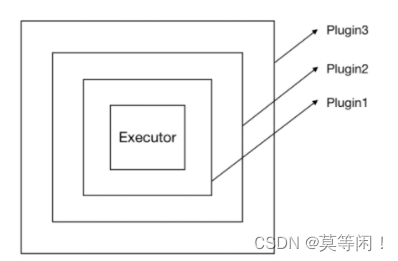
当 Executor 的某个方法被调用的时候,插件逻辑会先行执行。执行顺序由外而内,比如上图的执行顺序为 plugin3 → plugin2 → Plugin1 → Executor。
6.5 缓存策略
6.5.1 一级缓存 默认开启
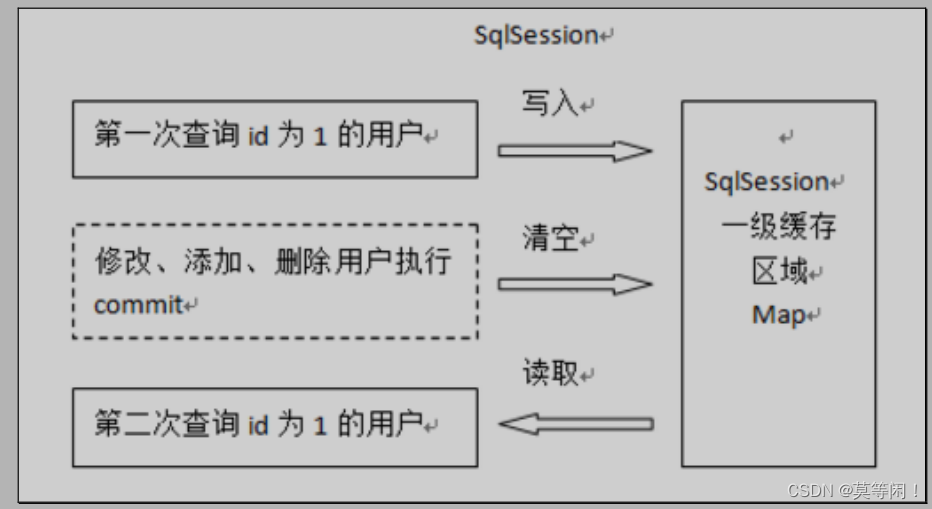
第一次发起查询用户 id 为 1 的用户信息,先去找缓存中是否有 id 为 1 的用户信息,如果没有,从数据库查询用户信息。
得到用户信息,将用户信息存储到一级缓存中。
如果 sqlSession 去执行 commit 操作(执行插入、更新、删除),清空 SqlSession 中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
第二次发起查询用户 id 为 1 的用户信息,先去找缓存中是否有 id 为 1 的用户信息,缓存中有,直接从缓存中获取用户信息。
6.5.2 一级缓存流程
底层数据结构是什么?
基于PerpetualCache类的 hashsmap的本地缓存
PerpetualCache
// 基于PerpetualCache类的 hashsmap的本地缓存
// key cachekey value db 查询数来的结果
private final Map<Object, Object> cache = new HashMap<>();cachekey hash值
statementId,sql语句,分页参数值, 参数值,enviromentID值 五部分
工作流程是什么?
- executor 查询local cache ,生成cachekey
- 根据cachekey查询缓存中是否有数据
- 没有数据,查询数据库
- 将数据库查询结果存到缓存中。map.put(cachekey,查询结果)
一级缓存源码分析结论:
- 一级缓存的数据结构是一个
HashMap<Object,Object>,它的value就是查询结果,它的key是CacheKey,CacheKey中有一个list属性,statementId,params,rowbounds,sql等参数都存入到了这个list中 - 先创建
CacheKey,会首先根据CacheKey查询缓存中有没有,如果有,就处理缓存中的参数,如果没有,就执行sql,执行sql后执行sql后把结果存入缓存
6.5.2 二级缓存
-
当我们在使用二级缓存时,·
所缓存的类一定要实现 java.io.Serializable 接口,这种就可以使用序列化方式来保存对象。 -
执行sqlsession方法中,必须调用 ·
commit() close() 方法,才能让二级缓存生效。 -
二级缓存 存储的是数据本身,而不是查询结果这个对象。
user1==user2 false -
sqlConfig 开启 enableEnabled=true 默认开启
-
在Mapper.xml 使用 需要开启
-
在 select 表情上 开启 useCache=true 默认开启
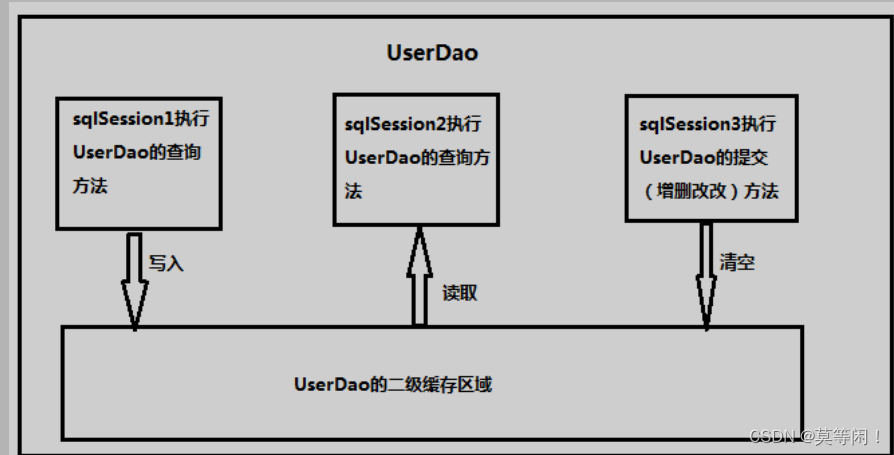
首先开启 mybatis 的二级缓存。
sqlSession1 去查询用户信息,查询到用户信息会将查询数据存储到二级缓存中。
如果 SqlSession3 去执行相同 mapper 映射下 sql,执行 commit 提交,将会清空该 mapper 映射下的二级缓存区域的数据。
sqlSession2 去查询与 sqlSession1 相同的用户信息,首先会去缓存中找是否存在数据,如果存在直接从缓存中取出数据。
原理
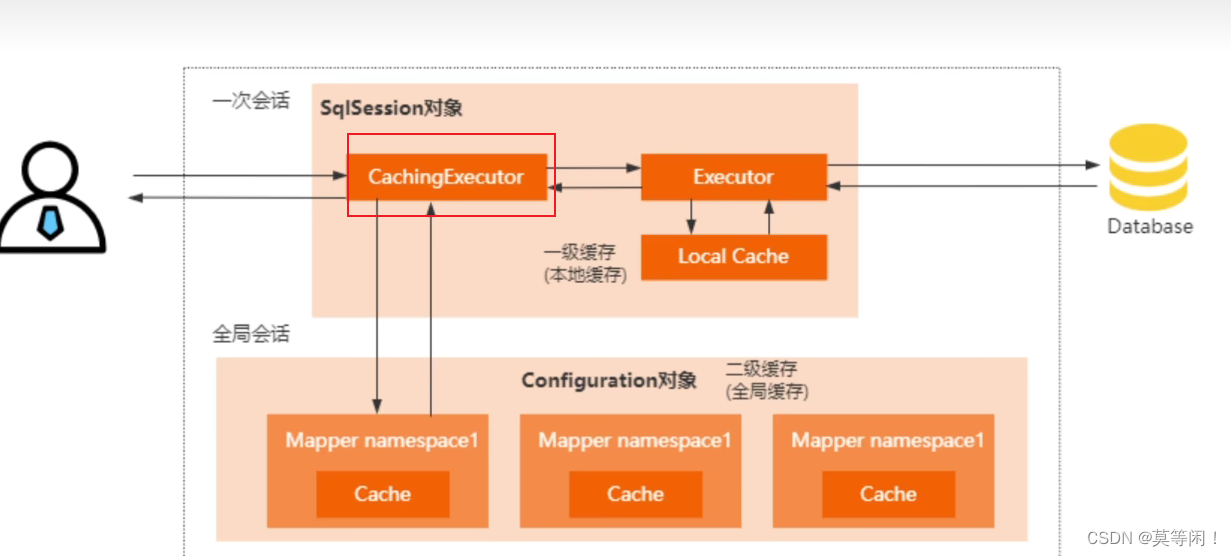
cache 标签

问题
① cache标签如何被解析的(二级缓存的底层数据结构是什么?)?
底层数据结构: 没配置type,默认是perpetualcache 也就是hashmap
解析cache 标签里面的属性,构建出cache对象。
存到configuration对象中。存到每个mappedStatement 对象中
② 同时开启一级缓存二级缓存,优先级?
③ 为什么只有执行sqlSession.commit或者sqlSession.close二级缓存才会生效

- 在db查询出来的时候,调用了事物缓存管理器
transactionalActionManagerputobject()方法,把数据存到了 TransactionalCache 中的entriesToAddOnCommit Map集合中
/* // 在事务被提交前,所有从数据库中查询的结果将缓存在此集合中*/private final Map<Object, Object> entriesToAddOnCommit;/
但是 取值 是从Cache delegate;(也就是perpetualCache map)中取的。
存合取不在同一个地方,所以没有生效。
- 所以在commit 或者close 中 ,会将entriesToAddOnCommit 中是数据
遍历转移到 cache中
存储二级缓存对象的时候是放到了TransactionalCache.entriesToAddOnCommit这个map中,但是每次查询的时候是直接从TransactionalCache.delegate中去查询的,所以这个二级缓存查询数据库后,设置缓存值是没有立刻生效的,主要是因为直接存到 delegate 会导致脏数据问题
④ 更新方法为什么不会清空二级缓存?
为什么一定要结合update() 和commit() 才清空
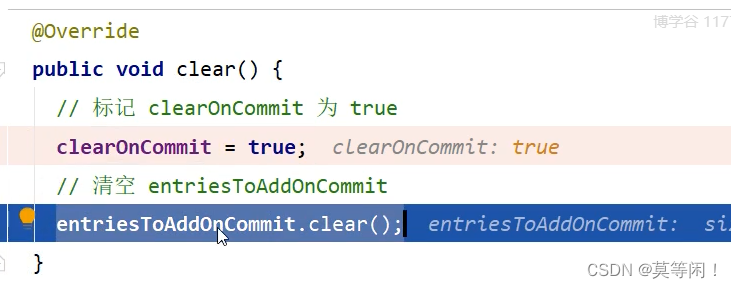
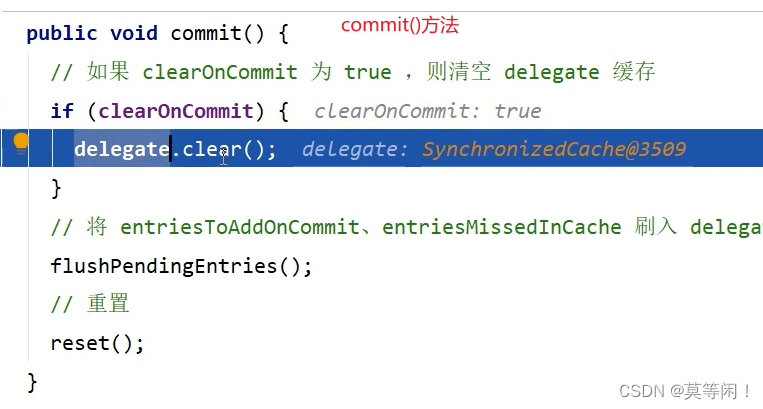
调用update 等方法时,会将clearOnCommit 标识设置为true。
在commit() 时,判断标识是否为true,就会清空cache里面的数据。
update()方法
commit 方法
总结
在二级缓存的设计上,MyBatis大量地运用了装饰者模式,如CachingExecutor, 以及各种Cache接口的装饰器。
- 二级缓存实现了Sqlsession之间的缓存数据共享,属于namespace级别
- 二级缓存具有丰富的缓存策略。
- 二级缓存可由多个装饰器,与基础缓存组合而成
- 二级缓存工作由 一个缓存装饰执行器CachingExecutor和
一个事务型预缓存TransactionalCache 完成
aaaaaa