2023/4/6总结

题解
Problem - A - Codeforces
1.这道题很简单,找出将当前数字放入字符串的最大值。
2.分情况讨论,有俩种情况,一种是大于等于数字d,那么这个数字d需要插入到最后字符串的位置。否则这个数字需要插入到第一次比它小的位置。
代码如下:
#include<stdio.h>
#include<string.h>
#define N 200100
char str[N];
char a[N],b[N];
int main()
{int t,n,d,i,j,min,flag;scanf("%d",&t);while(t--){scanf("%d%d",&n,&d);scanf("%s",str);min=99;flag=0;j=0;for(i=0;i<n;i++){if(min>str[i]) {min=str[i];}if(flag==0&&str[i]<d+'0'){flag=1;j=i;}}if(min>=d+'0') {printf("%s%c\\n",str,d+'0');}else{strcpy(a,str);a[j]=0;strcpy(b,str+j);printf("%s%c%s\\n",a,d+'0',b);}}return 0;
}P1656 炸铁路 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
1.这道题目时tarjan算法加桥的知识点。
可以看看我之前关于tarjan算法的一孔之见——2023/1/8总结_lxh0113的博客-CSDN博客
和桥——2023/1/12总结_lxh0113的博客-CSDN博客
tarjan算法是强连通算法,桥又叫割边,就是说去掉这条边,这条边对应的俩个顶点是否还有其他路径相连,如果没有,那么说这是桥。
2.在tarjan算法的基础上,有一个爷爷节点,父节点,儿子节点。桥的特点是,如果父节点的dfn值小于儿子节点的low值,说明儿子节点在这个图当中只能通过父节点。那么这个就是桥
3.会出现俩种情况,儿子节点访问过了,此时访问过了我们需要去刷新当前节点的low值,也就是出现的最早时间,如果儿子节点已经访问过了很有可能出现了强连通,它们在一个环里面。另外一个情况就是儿子节点没有被访问,此时,我们需要在这个儿子节点继续往下搜索(因为不确定儿子节点是否能回到父亲节点以上或者父亲节点)
4.然后就是排序啦,用的是c++的sort函数。
#include<stdio.h>
#include<algorithm>
#define Maxn 5100
#define N 160using namespace std;int mymap[N][N];
int dfn[N],low[N],time=1,n,m;
int len=0;
struct node
{int u,v;
}res[Maxn];
int minz(int a,int b)
{if(a>b) return b;return a;
}
bool cmp(node a,node b)
{if(a.u==b.u) return a.v<b.v;return a.u<b.u;
}
int dfs(int pre,int x)
{//桥,如果子节点的low值大于当前dfn值,说明没有别的路径//如果小于等于当前dfn值,说明还有别的路径//pre是父节点,x是当前节点,要找x的子节点dfn[x]=low[x]=time++;int i,y;for(i=1;i<=n;i++){if(mymap[x][i]){//如果有子节点,看孙子节点是否能到该节点y=i;if(dfn[y]&&y!=pre) low[x]=minz(low[x],dfn[y]);//如果儿子节点已经被访问过了//那么该点的low值需要刷新。if(dfn[y]==0){//如果该点没有访问过dfs(x,y);low[x]=minz(low[x],low[y]);if(low[y]>dfn[x]) {res[len].u=x;res[len].v=y;len++;}}}}return 0;
}
int main()
{int i,j,u,v;scanf("%d%d",&n,&m);for(i=1;i<=m;i++){scanf("%d%d",&u,&v);mymap[u][v]=1;mymap[v][u]=1;}for(i=1;i<=n;i++){if(dfn[i]==0){dfs(0,i);}}sort(res,res+len,cmp);for(i=0;i<len;i++){printf("%d %d\\n",res[i].u,res[i].v);}return 0;
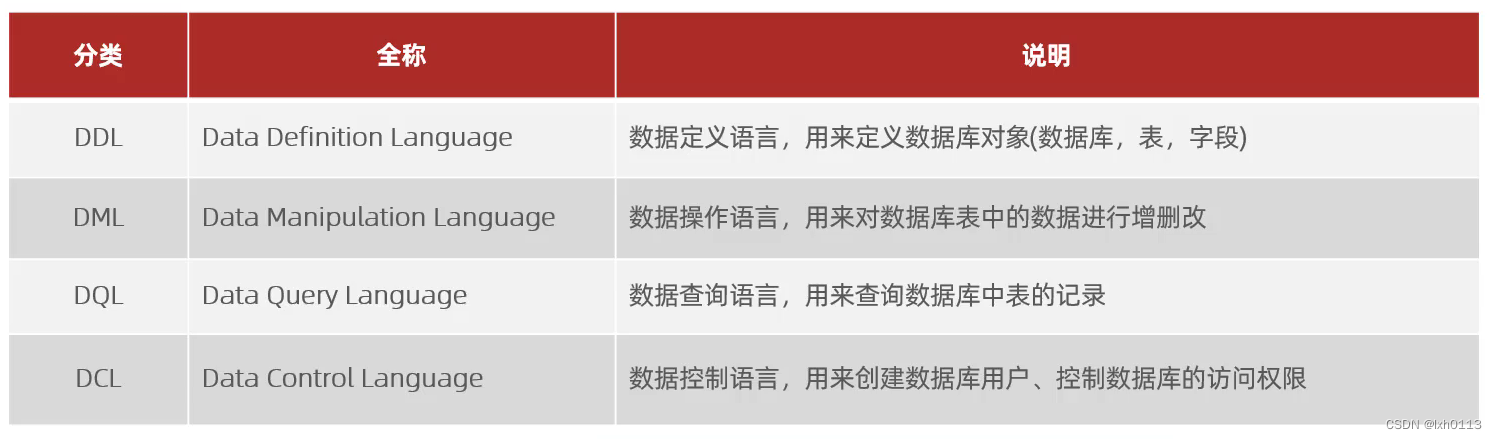
}主要学习了MySQL
MySQL注释
单行注释:--或#
多行注释 //
数据类型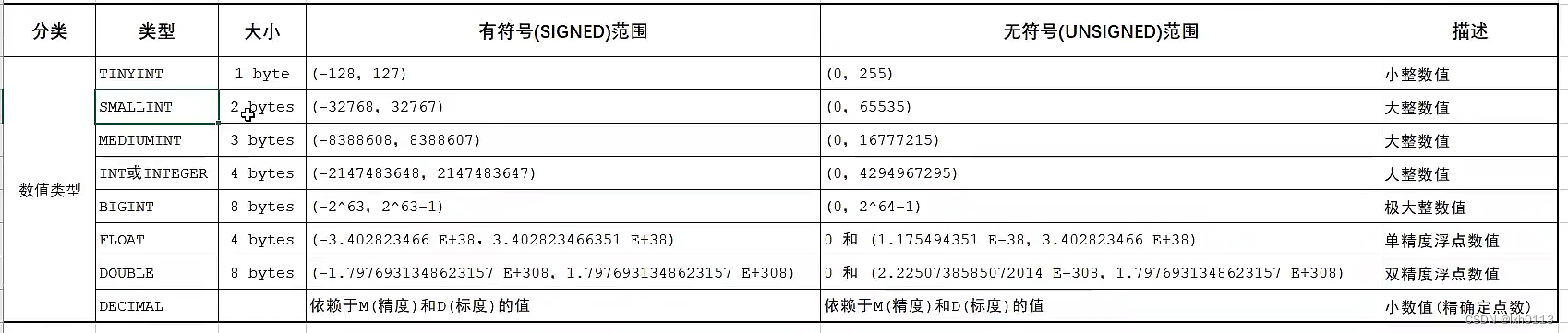


创建数据库:
creat database 名称;
在navicat中创建:
下面是创建一个数据库里面的表,表里面包含了这些元素。
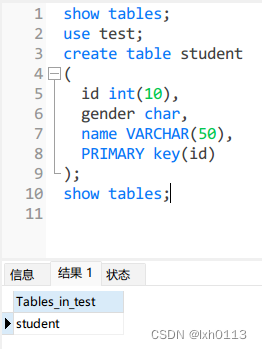
最后一行的primary key的意思是把id作为主键。
修改表
![]()
表示在student这个表里面添加score字段。
新建多个字段
![]()
修改字段类型:
![]()
修改字段名称(可以直接理解为修改字段)
![]()
删除字段
![]()
删除多个字段:
![]()
删除表
![]()
查看表结构
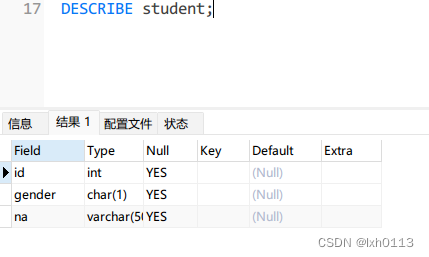
上面这些操作是可以在新建表当中搞:(如果想要修改,就点击你想要修改的表,右击选择设计表)
查询表中所有数据
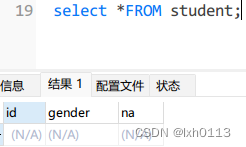
查询一列数据(指定的列)。
如果要查询多个指定的列,那么在from前面用逗号隔开即可。
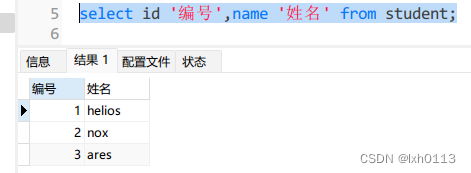
使用别名查询:(把字段变成别名,以便于查看)
concat语句,合并列字段
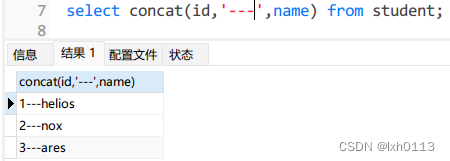
查询时可以进行加减乘除运算

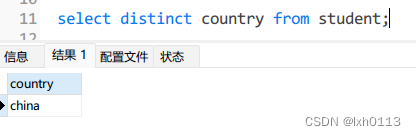
查询去重操作,用distinct语句即可。
条件查询,在后面加where语句,可以结合运算符使用。
比如:

插入单条数据:
![]()
如果想按照自己想要的字段顺序:
![]()
可以只插入自己想要的字段,但是必须插入主键的值,并且主键不能重复插入。主键值是整数并且是增长的,如果没有填写,就是默认自动增长。
如果要插入多组数据,那么需要在values后面加逗号批量插入。
下面这段代码表示,创建一个student1表格,主键是id,并且是默认自然增长的,name的初始值是666. 插入的时候如果不插入主键值,那么就会自然增长,不插入其他值,其他值就是我们所设的初始值。在navicat里面,字符串可以用单引号。这个自动增长永远是按照上一次的值来增长的,即使之前装满了数据,然后又清空了,自动增长还是会从上一次的开始,除非

修改所有行的字段数据 ,修改多个则添加逗号。
![]()
下面代表用where语句修改特定的数据,修改的是where语句后面id=2,修改的是id=2的数据的gender和name值
![]()
删除某行的数据,会删除where语句后面匹配的值。
![]()
删除整个表格,直接写delete from student;即可。
like语句
%代表像文件的通配符”*“,可以匹配多个字符,下面代表了,删除name以elios结尾的数据。
![]()