6.S081——虚拟内存部分——xv6源码完全解析系列(3)

0.briefly speaking
没想到vm.c这份代码文件还没有读完,不过剩下的也就只剩下copyin、copyout、copyinstr这三个函数了。这篇博客就将整个虚拟内存部分的代码收个尾,然后再去扒一扒exec.c的实现逻辑。
1.kernel/memorylayout.h
2.kernel/vm.c (434 rows) <-----------(这篇博客要阅读的代码)
3.kernel/kalloc.c
4.kernel/exec.c (154 rows) <-----------(这篇博客要阅读的代码)
5.kernel/riscv.h
点此回看本系列博客的上一篇
1.kernel/vm.c
1.17 copyin函数
这个函数负责从给定的用户页表pagetable的虚拟地址srcva处拷贝长度为len字节的数据到地址dst处。在阅读这段代码时,思考一个问题:为什么内核目的地址dst使用指针来表示,而用户态的地址却使用uint64 srcva来代替?
这其实还是因为,copyin代码会运行在内核态下,所以在copyin代码中凡是引用指针变量的地方(如dst)都会通过MMU硬件单元查询内核页表翻译为对应的物理地址,因此对于内核来说这种对应关系是正确的。
而对于用户态下的虚拟地址,我们就没法使用MMU来翻译了,因为在内核态下地址空间是内核地址空间而非用户地址空间。我们只能够用软件来模拟MMU的查找过程,这也就是在copyin代码中调用walkaddr的原因,它本质上是用软件逻辑实现了硬件MMU的地址翻译过程。
// Copy from user to kernel.
// Copy len bytes to dst from virtual address srcva in a given page table.
// Return 0 on success, -1 on error.
// 译:从用户空间向内核空间拷贝数据
// 从页表pagetable的虚拟地址srcva中拷贝len长度的数据到dst
// 成功时返回0,出错时返回-1
int
copyin(pagetable_t pagetable, char *dst, uint64 srcva, uint64 len)
{uint64 n, va0, pa0;// 总共要复制len个字符之后再跳出循环while(len > 0){// 使用PGROUNDDOWN宏来找到srcva对应页的起始虚拟地址va0 = PGROUNDDOWN(srcva);// 找到va0对应的实际物理地址pa0 = walkaddr(pagetable, va0);// pa0 == 0表示walkaddr函数出错,返回-1if(pa0 == 0)return -1;// 注意:这里的n是在本次迭代中要复制的字节数// 考虑两种非对齐的情形:// 1.srcva起始地址如果不是页对齐的,n的大小恰好等于第一个页面要复制的剩余的字节数量// 在复制完第一个页面之后,页面会强制对齐,假设剩余len > PGSIZE// 那么此时会有n = PGSIZE - (srcva - va0) = PGSIZE,这会复制一整个页面n = PGSIZE - (srcva - va0);// 这是为了收尾处理,防止复制多余数据// 2.此时if(n > len)的判断可以保证不复制多余的数据if(n > len)n = len;// 调用memmove完成本次复制memmove(dst, (void *)(pa0 + (srcva - va0)), n);// 更新len、dst、srcvalen -= n;dst += n;// 注意这里的对srcva的更新,无论一开始srcva是否是页对齐的// 经过这里的更新后一定会是页对齐的,因为va是圆整后的页面起始地址,细细品味一下...srcva = va0 + PGSIZE;}return 0;
}
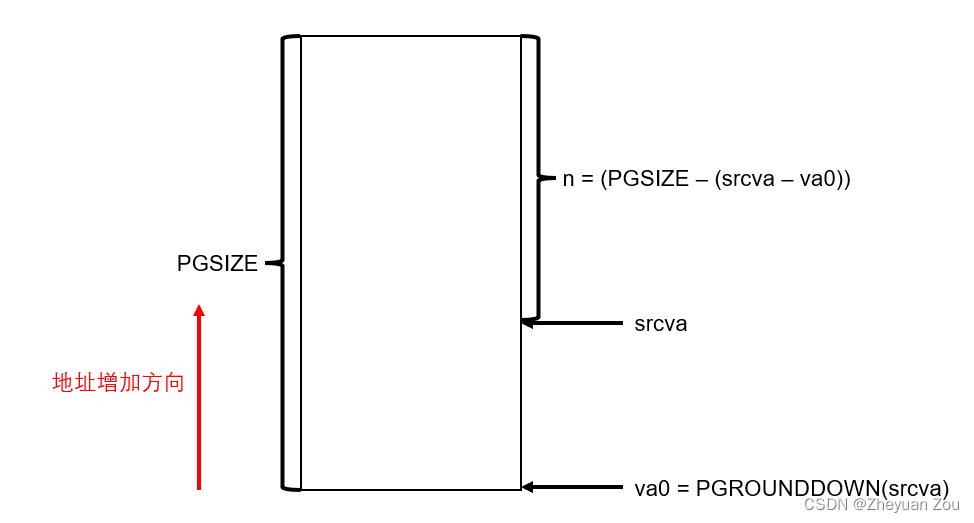
上面这段代码中为了处理复制过程中的非页对齐,还是有些晦涩的逻辑在的。这里简单找一种情况展开说说:
假设srcva的开始地址不是页对齐的,那么它就会像下图一样,位于某一个页面的中间。那么n此时正好等于这个页面中要复制的数据长度,memmove正好复制了这个页面中该复制的那一部分数据。
然后在更新时有:srcva = va0 + PGSIZE,正好会将srcva强制对齐到下一个页面的开始位置,避免srcva不对齐的情况再次发生,所以这里的代码写的是非常巧妙的,正确高效地处理了地址不对齐的情况。
1.18 copyinstr函数
趁热打铁,看完了copyin函数的实现,现在就可以紧跟着看看copyinstr是怎么实现的,以及它和copyin有哪些不同。与copyin不同的地方在于,因为copyinstr复制的对象是字符串,所以复制结束的标志是遇到空字符(null-terminated)。
这里为了防止缓冲区的溢出,还特地设置了最大可复制的字符数量上限max,如果超过这个数字仍未遇到空字符,则要退出复制过程并返回-1表示出错了。代码注释如下:
// Copy a null-terminated string from user to kernel.
// Copy bytes to dst from virtual address srcva in a given page table,
// until a '\\0', or max.
// Return 0 on success, -1 on error.
// 译:从用户空间拷贝一个以空字符结尾的字符串到内核空间
// 从页表pagetable的srcva地址处以字节为单位拷贝数据到dst
// 直到遇见空字符或达到最大数量
// 成功时返回0,失败时返回-1
int
copyinstr(pagetable_t pagetable, char *dst, uint64 srcva, uint64 max)
{uint64 n, va0, pa0;// 是否遇到空字符的标志位,为0表示没有遇到int got_null = 0;// 如果没有遇到空字符或尚未达到最大字符限制while(got_null == 0 && max > 0){// 找出srcva对应页的起始物理地址va0 = PGROUNDDOWN(srcva);pa0 = walkaddr(pagetable, va0);// 如果查询的物理地址为0,表示出错,返回-1if(pa0 == 0)return -1;// 这里的逻辑和copyin一样,不再赘述// n表示的是本次迭代要复制的字节数n = PGSIZE - (srcva - va0);if(n > max)n = max;// 得到本次复制源字符串起始的物理地址char *p = (char *) (pa0 + (srcva - va0));// 完成n个字节的复制while(n > 0){// 如果已经遇到了空字符if(*p == '\\0'){// 则给dst处也放置一个空字符// got_null标志位置为1,表示已经遇到空字符,并跳出循环 *dst = '\\0';got_null = 1;break;// 如果没有遇到空字符,则拷贝当前字符} else {*dst = *p;}// 更新循环变量--n;--max;p++;dst++;}// 强制对齐srcva到下一个页面开始位置srcva = va0 + PGSIZE;}// 如果是因为遇到空字符而结束复制,则返回0表示正常// 如果是因为超过了最大允许复制的字节数量,则返回-1表示出错if(got_null){return 0;} else {return -1;}
}1.19 copyout函数
终于要到了收官阶段了,既然有copyin和copyinstr函数负责从用户空间向内核空间拷贝数据,那么也一定会有反过来的操作。和上面一样,src地址是指针,而用户空间的地址是uint64类型。直接来看下面的代码逻辑:
// Copy from kernel to user.
// Copy len bytes from src to virtual address dstva in a given page table.
// Return 0 on success, -1 on error.
// 译:从内核空间向用户空间拷贝数据
// 从src拷贝len长度的字节到pagetable页表的dstva位置处
// 成功时返回0,错误时返回-1
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{uint64 n, va0, pa0;// 当字符还没有复制完毕时while(len > 0){// 找到对应当前虚拟地址dstva的物理地址pa0va0 = PGROUNDDOWN(dstva);pa0 = walkaddr(pagetable, va0);// 如果pa0为0,表示查找过程出错,返回-1if(pa0 == 0)return -1;// 这里的逻辑和copyin一样,处理非对齐的情况和防止复制超出范围// n表示的是当前循环可以复制的字节数量n = PGSIZE - (dstva - va0);if(n > len)n = len;memmove((void *)(pa0 + (dstva - va0)), src, n);// 更新循环变量// 强制对齐dstva,和copyin对齐srcva的做法一致,不再赘述len -= n;src += n;dstva = va0 + PGSIZE;}return 0;
}
哇,可真不容易啊,总算是将xv6中用于虚拟内存管理的主要函数都仔细研究了一遍。现在算是对xv6的虚拟内存管理部分有了更加深入的认识,vm.c文件共包含3个全局变量,18个函数,至此都一一研究过了。这下不仅更加深刻地理解了多级页表机制,还更加深入地理解了xv6的虚拟内存管理机制!
下面准备进入第二个文件kernel/exec.c,去详细看看exec系统调用是怎么实现的:
2. kernel/exec.c
exec系统调用会创建一个地址空间的用户部分(creates the user part of an address space),注意这里xv6 book里的措辞。一个用户进程的地址空间除了用户部分之外,还需要有内核栈等位于内核的部分。所以这里的措辞很严谨,exec只负责初始化地址空间的用户部分。
用什么来初始化所谓地址空间的用户部分呢?——存储在文件系统里的ELF格式的文件
有关ELF格式文件可以阅读其他资料,这里的是维基百科上的介绍,ELF文件的一般格式如下:
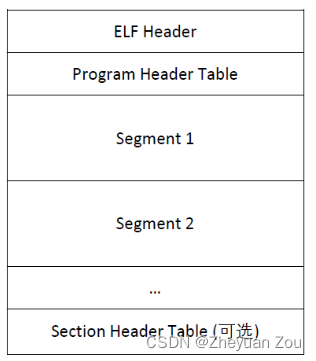
一般来说ELF文件会有多个program header,它们每一个指向必须读入内存的一个程序段,但是xv6中为了简单起见,只有一个program header,有关ELF格式的定义全部在kernel/elf.h中,为了阅读代码方便,最好打开一份ELF格式文件参照表,这样才可以知道每一个字段的含义。
下面开始阅读代码了:)
2.1 loadseg函数
先从loadseg函数开始,因为exec函数会调用它,这个函数负责将一个程序段载入某个页表的虚拟地址中。
// Load a program segment into pagetable at virtual address va.
// va must be page-aligned
// and the pages from va to va+sz must already be mapped.
// Returns 0 on success, -1 on failure.
// 译:将一个程序段读入页表pagetable的虚拟地址va处
// va必须是页对齐的,va到va + sz范围内的页必须已经被映射好
// 返回0表示成功,-1表示失败
static int
loadseg(pagetable_t pagetable, uint64 va, struct inode *ip, uint offset, uint sz)
{uint i, n;uint64 pa;// 迭代地复制程序段,每次复制一个页面for(i = 0; i < sz; i += PGSIZE){// 使用walkaddr找到对应的物理地址 pa = walkaddr(pagetable, va + i);// pa返回0表示walkaddr调用失败,对应的虚拟地址可能:// 1.PTE不存在// 2.没有建立映射关系// 3.用户无权访问if(pa == 0)panic("loadseg: address should exist");// 这里是防止最后一页要复制的字节不满一页而导致的复制溢出if(sz - i < PGSIZE)n = sz - i;elsen = PGSIZE;// readi系统调用是从索引节点对应的文件数据缓冲区中读取数据的函数// 下面的调用从索引节点ip指向的文件的off偏移处读取n个字节放入物理地址pa// 第二个参数为0表示处于内核地址空间// 再次地,我们用到了内核地址空间的直接映射(direct-mapping)// 就算pa是某个用户页表翻译出来的物理地址,在内核地址空间中也会被译为同等的地址if(readi(ip, 0, (uint64)pa, offset+i, n) != n)return -1;}return 0;
}2.2 exec函数
exec函数的实现过程相对复杂,在这个过程中会涉及到很多后面的代码内容,所以这里对exec代码实现的阅读只关注大致的流程,比如文件系统的相关操作、锁的使用这里只给出简单的注解,具体的代码实现细节还需要研究到对应部分的源码才可以全部解释清楚,如果这里的解释有谬误请多包涵,我在研究完所有代码后会回来修改。
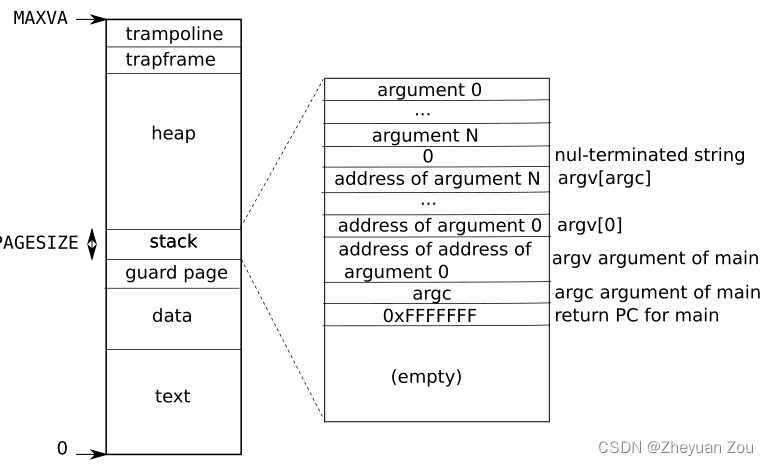
阅读下面的源代码时,一定要来回头看看这个用户栈地址空间的格式,它非常重要。
int
exec(char *path, char **argv)
{// 一系列需要使用的变量声明char *s, *last;int i, off;uint64 argc, sz = 0, sp, ustack[MAXARG], stackbase;struct elfhdr elf;struct inode *ip;struct proghdr ph;pagetable_t pagetable = 0, oldpagetable;struct proc *p = myproc(); // 获取当前进程// begin_op是开启文件系统的日志功能// 每当进行一个与文件系统相关的系统调用时都要记录begin_op();// namei同样是一个文件系统操作,它返回对应路径文件的索引节点(index node)的内存拷贝// 索引节点中记录着文件的一些元数据(meta data)// 如果出错就使用end_op结束当前调用的日志功能if((ip = namei(path)) == 0){end_op();return -1;}// 给索引节点加锁,防止访问冲突ilock(ip);// Check ELF header// 读取ELF文件头,查看文件头部的魔数(MAGIC NUMBER)是否符合要求,这在xv6中有详细说明// 如果不符合就跳转到错误处理程序if(readi(ip, 0, (uint64)&elf, 0, sizeof(elf)) != sizeof(elf))goto bad;if(elf.magic != ELF_MAGIC)goto bad;// 创建一个用户页表,将trampoline页面和trapframe页面映射进去// 保持用户内存部分留白if((pagetable = proc_pagetable(p)) == 0)goto bad;// Load program into memory.// 译:将程序加载到内存中去// elf.phoff字段指向program header的开始地址,program header通常紧随elf header之后// elf.phnum字段表示program header的个数,在xv6中只有一条program headerfor(i=0, off=elf.phoff; i<elf.phnum; i++, off+=sizeof(ph)){// 读取对应的program header, 出错则转入错误处理程序if(readi(ip, 0, (uint64)&ph, off, sizeof(ph)) != sizeof(ph))goto bad;// 如果不是LOAD段,则读取下一段,xv6中只定义了LOAD这一种类型的program header(kernel/elf.h)// LOAD意为可载入内存的程序段if(ph.type != ELF_PROG_LOAD)continue;// memsz:在内存中的段大小(以字节计)// filesz:文件镜像大小// 一般来说,filesz <= memsz,中间的差值使用0来填充// memsz < filesz就是一种异常的情况,会跳转到错误处理程序if(ph.memsz < ph.filesz)goto bad;// 安全检测,防止当前程序段载入之后地址溢出 if(ph.vaddr + ph.memsz < ph.vaddr)goto bad;// 尝试为当前程序段分配地址空间并建立映射关系// 这里正好满足了loadseg要求的映射关系建立的要求 // uvmalloc函数见完全解析系列博客(2)uint64 sz1;if((sz1 = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz)) == 0)goto bad;// 更新sz大小,sz记录着当前已复制的地址空间的大小sz = sz1;// 如果ph.vaddr不是页对齐的,则跳转到出错程序// 这也是为了呼应loadseg函数va必须对齐的要求if((ph.vaddr % PGSIZE) != 0)goto bad;// 调用loadseg函数将程序段读入前面已经分配好的页面// 如读取不成功则跳转到错误处理程序if(loadseg(pagetable, ph.vaddr, ip, ph.off, ph.filesz) < 0)goto bad;} // 持续循环直到读完所有程序段// iunlockput函数实际上将iunlock和iput函数结合了起来// iunlock是释放ip的锁,和前面的ilock对应// iput是在索引节点引用减少时尝试回收节点的函数iunlockput(ip);// 结束日志操作,和前面的begin_op对应end_op();// 将索引节点置为空指针ip = 0;// 获取当前进程并读取出原先进程占用内存大小// myproc这个函数定义在kernel/proc.c中// 有关进程也是一个很大的话题,需要仔细研究p = myproc();uint64 oldsz = p->sz;// Allocate two pages at the next page boundary.// Use the second as the user stack.// 译:在当前页之后再分配两页内存// 并使用第二页作为用户栈// 这和xv6 book中展示的用户地址空间是完全一致的,可以参考一下// 在text、data段之后是一页guard page,然后是user stacksz = PGROUNDUP(sz);uint64 sz1;if((sz1 = uvmalloc(pagetable, sz, sz + 2*PGSIZE)) == 0)goto bad;sz = sz1;// 清除守护页的用户权限 uvmclear(pagetable, sz-2*PGSIZE);// sz当前的位置就是栈指针stack pointer的位置,即栈顶// stackbase是栈底位置,即栈顶位置减去一个页面sp = sz;stackbase = sp - PGSIZE;// Push argument strings, prepare rest of stack in ustack.// 在用户栈中压入参数字符串// 准备剩下的栈空间在ustack变量中// 读取exec函数传递进来的参数列表,直至遇到结束符for(argc = 0; argv[argc]; argc++) {// 传入的参数超过上限,则转入错误处理程序if(argc >= MAXARG)goto bad;// 栈顶指针下移,给存放的参数留下足够空间// 多下移一个字节是为了存放结束符sp -= strlen(argv[argc]) + 1;sp -= sp % 16; // riscv sp must be 16-byte aligned,对齐sp指针// 如果超过了栈底指针,表示栈溢出了if(sp < stackbase)goto bad;// 使用copyout函数将参数从内核态拷贝到用户页表的对应位置if(copyout(pagetable, sp, argv[argc], strlen(argv[argc]) + 1) < 0)goto bad;// 将参数的地址放置在ustack变量的对应位置// 注意:ustack数组存放的是函数参数的地址(虚拟地址)ustack[argc] = sp;}// 在ustack数组的结尾存放一个空字符串,表示结束ustack[argc] = 0;// push the array of argv[] pointers.// 将参数的地址数组放入用户栈中,即将ustack数组拷贝到用户地址空间中// argc个参数加一个空字符串,一共是argc + 1个参数// 对齐指针到16字节并检测是否越界sp -= (argc+1) * sizeof(uint64);sp -= sp % 16;if(sp < stackbase)goto bad;// 从内核态拷贝ustack到用户地址空间的对应位置if(copyout(pagetable, sp, (char *)ustack, (argc+1)*sizeof(uint64)) < 0)goto bad;// arguments to user main(argc, argv)// argc is returned via the system call return// value, which goes in a0.// 译:用户main程序的参数// argc作为返回值返回,存放在a0中,稍后我们就会看到这个调用的返回值就是argc// sp作为argv,即指向参数0的指针的指针,存放在a1中返回// < 疑问:按照xv6 book所述,这里的栈里应该还有argv和argc的存放 >// < 这个地方留个坑,等研究完系统调用和陷阱的全流程之后再来解释 >p->trapframe->a1 = sp;// Save program name for debugging.// 译:保留程序名,方便debug// 将程序名截取下来放到进程p的name中去for(last=s=path; *s; s++)if(*s == '/')last = s+1;safestrcpy(p->name, last, sizeof(p->name));// Commit to the user image.// 译:提交用户镜像// 在此,首先将用户的原始地址空间保存下来,以备后面释放// 然后将新的地址空间全部设置好// epc设置为elf.entry,elf.entry这个地址里存放的是进程的开始执行地址// sp设置为当前栈顶位置spoldpagetable = p->pagetable;p->pagetable = pagetable;p->sz = sz;p->trapframe->epc = elf.entry; // initial program counter = mainp->trapframe->sp = sp; // initial stack pointerproc_freepagetable(oldpagetable, oldsz);return argc; // this ends up in a0, the first argument to main(argc, argv)// 错误处理程序所做的事:// 释放已经分配的新进程的空间// 解锁索引节点并结束日志记录,返回-1表示出错bad:if(pagetable)proc_freepagetable(pagetable, sz);if(ip){iunlockput(ip);end_op();}return -1;
}
啊哈,算是大概看了一下exec调用的实现,这个函数的实现还是非常复杂的,足足写了上百行代码。在阅读过的代码部分中,我有一个地方不是很明白,那就是以下代码(kernel/exec.c:103):
p->trapframe->a1 = sp;
为什么要将sp设置到trapframe的a1寄存器中?sp指向是当前的栈顶位置,它本身的值也是程序参数argv的值。这个值在返回之后何时被放入到用户栈中,或者何时被调用,可能在理解了整个系统调用过程之后才可以被解释清楚,这个问题留待我们在完成实验4之后回过头来看。
这篇文章暂且写到这里吧!
点击跳转到下一篇博客