Java - JsonProperty中首字母大小写对JSON反序列化的影响问题解决思路(不用Fastjson)

Java - JsonProperty中首字母大小写对JSON反序列化的影响问题解决思路(不用Fastjson)
- 前言
- 一. 简单的案例复现
- 二. Java端输出对应的字段映射关系
- 三. Node端进行大小写映射转换
前言
我先来说下我这遇到的问题背景:
- 我们平时调用的接口,可能来自于一个
Java服务端,也可能来自于一个NodeJs服务端。 - 如今我们有个小需求:希望在
Java服务端中调用NodeJs服务端的接口去做一层代理。 - 主要操作:
Java里面将Request封装成普通的JSON串给NodeJs,由NodeJs去做真实的请求。最终得到一个ResponseFromNode,然后我们再将ResponseFromNode进行JSON化,返回给Java服务端去反序列化。
这时候遇到问题了:
- 由于公司框架的某些原因。
ResponseFromNode里面的字段可能都以大写开头或者以小写开头。而Java里面的ResponseFromJava,每个字段一般都有@JsonProperty()进行标记。 - 那么这种就可能导致由于两端大小写不一致的情况,从而导致在
Java中,JSON反序列化的结果为null。
一. 简单的案例复现
我们这里给一个很简单的案例来说明这个问题。我们准备一个很简单的Pojo类:lombok和jackson的依赖我就不贴了。
@Data
@ToString
public class Model {@JsonProperty("Name")public String name;@JsonProperty("Age")public Integer age;@JsonProperty("BookList")public List<Book> books;
}@Data
public class Book {@JsonProperty("BookName")public String bookName;
}
写一个简单的Demo:这里主要用的是jackson的序列化。具体内容我就不写了,是内部封装的代码。
@org.junit.Test
public void test2() {Model model = new Model();model.setAge(1);model.setName("LJJ");ArrayList<Book> books = new ArrayList<>();Book book = new Book();book.setBookName("Hello");books.add(book);model.setBooks(books);System.out.println(JsonUtil.toJson(model));
}
拿到对应的JSON串:
{"Name":"LJJ","Age":1,"BookList":[{"BookName":"Hello"}]}
这个JSON串如果反序列化,是能够成功的。但是我们模拟一下NodeJs服务端请求返回,返回给Java一个JSON串如下:
{"name":"LJJ","Age":1,"books":[{"bookName":"Hello"}]}
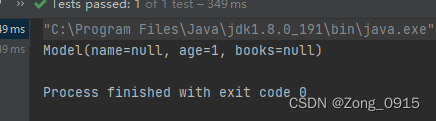
那么这个JSON串反序列化肯定是失败的:
@org.junit.Test
public void test3() {String json = "{\\"name\\":\\"LJJ\\",\\"Age\\":1,\\"books\\":[{\\"bookName\\":\\"Hello\\"}]}";Model model = JsonUtil.fromJson(Model.class, json);System.out.println(model);
}
如图:
那么这种情况改怎么保证NodeJs端返回的JSON串符合Java端对象属性定义的格式呢(@JsonProperty)?
我的思路如下:
Java端将需要反序列化对象的各个字段的大小写映射关系给到NodeJs服务。NodeJs服务进行真实请求后,将拿到的ResponseFromNode对象根据映射关系进行转换。最终再输出为JSON返回Java。- 这样
Java就能正确地进行反序列化了。
备注:如果觉得太麻烦或者没必要,直接用fastjson就能解决各种大小写和兼容问题(例如Calendar类型),就不必往下看啦。
二. Java端输出对应的字段映射关系
我们准备写一个FieldMappingUtil映射工具类,它的功能主要分为这么几个:
- 递归处理当前类的每一个字段。拿到对应
JsonProperty标记的值作为映射值。字段名则作为原始值。 - 能判断当前字段类型是否需要递归?例如八大基本数据类型就不需要判断。我们一般针对的都是自己封装的对象。
代码如下:
import com.fasterxml.jackson.annotation.JsonProperty;
import org.apache.commons.lang3.ClassUtils;import java.lang.reflect.Field;
import java.lang.reflect.ParameterizedType;
import java.lang.reflect.Type;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Set;/* @Date 2023/4/7 14:56* @Created by jj.lin*/
public class FieldMappingUtil {/* 除去 8大基本数据类型 及 对应包装类 的其他支持对象类型*/private static final String[] NORMAL_TYPE = new String[]{"String", "BigDecimal", "Calendar",};/* 需要排除校验的对象类型*/private static final String[] EXCLUDE_TYPE = new String[]{};/* 需要排除的字段名称*/private static final String[] EXCLUDE_FIELD = new String[]{};private static final Set<String> NORMAL_TYPE_SET = new HashSet<String>(Arrays.asList(NORMAL_TYPE));private static final Set<String> EXCLUDE_TYPE_SET = new HashSet<String>(Arrays.asList(EXCLUDE_TYPE));private static final Set<String> EXCLUDE_FIELD_SET = new HashSet<String>(Arrays.asList(EXCLUDE_FIELD));public static <T> HashMap<String, String> getMapping(Class<T> tClass) {HashMap<String, String> fieldMapping = new HashMap<>();getMapping(fieldMapping, tClass);return fieldMapping;}private static <T> boolean isNormalType(Class<T> tClass) {// 8 大基本数据类型和对应包装类的判断if (ClassUtils.isPrimitiveOrWrapper(tClass)) {return true;}// 其他类型的判断,这里就需要我们自定义了if (FieldMappingUtil.contain(tClass, NORMAL_TYPE_SET)) {return true;}return false;}private static <T> boolean contain(Class<T> tClass, Set<String> set) {return set.contains(tClass.getName()) || set.contains(tClass.getSimpleName());}private static <T> void getMapping(HashMap<String, String> fieldMapping, Class<T> tClass) {for (Field field : tClass.getDeclaredFields()) {// 如果是我们需要排除映射的类型,就跳过if (FieldMappingUtil.contain(tClass, EXCLUDE_TYPE_SET)) {continue;}String originName = field.getName();// 如果是我们不需要序列化的一些属性,跳过,例如序列化ID、静态成员变量if (EXCLUDE_FIELD_SET.contains(originName)) {continue;}Class<?> type = field.getType();// 如果是集合if (type == java.util.List.class) {// 取出对应的泛型类型Type genericType = field.getGenericType();if (genericType instanceof ParameterizedType) {ParameterizedType pt = (ParameterizedType) genericType;// 得到泛型里的class类型对象Class<?> genericClazz = (Class<?>) pt.getActualTypeArguments()[0];// 继续递归getMapping(fieldMapping, genericClazz);}// 加入当前集合名称的映射关系JsonProperty jsonProperty = field.getAnnotation(JsonProperty.class);if (jsonProperty != null) {fieldMapping.putIfAbsent(originName, jsonProperty.value());}continue;}// 如果不是常规对象类型,继续递归处理if (!FieldMappingUtil.isNormalType(type)) {getMapping(fieldMapping, type);continue;}// 增加当前的字段映射关系JsonProperty jsonProperty = field.getAnnotation(JsonProperty.class);if (jsonProperty != null) {fieldMapping.putIfAbsent(originName, jsonProperty.value());}}}
}
我们来测试一下这个工具:
@org.junit.Test
public void test4() {HashMap<String, String> mapping = FieldMappingUtil.getMapping(Model.class);System.out.println(JsonUtil.toJson(mapping));
}
结果如下:
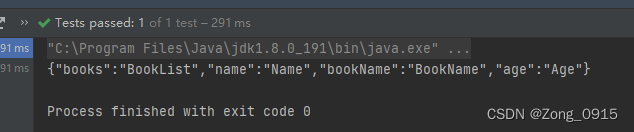
那么我们将这个映射Mapping关系,传给NodeJs,让NodeJs在返回真实Response之前,做一次转换即可。
三. Node端进行大小写映射转换
这里我同样进行Mock,我们看下一般的返回是怎样的:
const responseFromNode = {name: "LJJ",Age: 1,BookList: [{ bookName: "Hello" }]
}
// 这里就是要返回给Java的原始报文
console.log(responseFromNode)
那么现在,我们就要根据Mapping映射关系去做一次映射:
const responseFromNode = {name: "LJJ",Age: 1,books: [{ bookName: "Hello" }]
}
const fieldMapping = { "books": "BookList", "name": "Name", "bookName": "BookName", "age": "Age" };const transMapping = (jsonObj, mapping) => {// 数组则递归每一项if (jsonObj instanceof Array) {return jsonObj.map(item => transMapping(item));} else if (typeof (jsonObj) === 'object') {for (const key in jsonObj) {// 根据映射关系拿到新的Keyconst mappingNewKey = fieldMapping[key];if (!mappingNewKey) {continue;}// 递归处理该Key对应的ValuejsonObj[mappingNewKey] = transMapping(jsonObj[key]);// 记得删掉老的 K-Vif (mappingNewKey !== key) {delete jsonObj[key];}}return jsonObj;}return jsonObj;
};console.log('old:', responseFromNode)
console.log('new:', transMapping(responseFromNode, fieldMapping))
结果如下:

可以看到,Node端最后输出的对象属性大小写,已经完全吻合Java对象中的JSON定义了。这样一来,反序列化问题也就解决了。
最后再提一嘴:
- 如果大家遇到类似的情况,有更好的解决方案欢迎讨论交流。
- 如果使用
Fastjson,其实这些情况都不需要考虑的。默认下这个框架无视首字母大小写的。 - 其实这种通过原始
JSON来传递请求体和返回体,再进行序列化/反序列化的问题还是很多的。我这里举个例子,如果某个类型是Calendar,但是NodeJs端返回给Java的JSON对应字段的值是:/Date(1680844034150+0800)/,那么Jackson如果你不去设置一些东西,反序列化的时候会报错的。我这里暂时是在Node端进行格式化处理。
同一个问题的解决方案有很多,就看大家怎么选择啦。这里就当分享一下反射和递归在工作中的实际应用了~