TWIST阅读笔记

目录
TWIST: Two-Way Inter-label Self-Training for Semi-supervised 3D Instance Segmentation
摘要
利用无标签数据来提高模型性能,我们提出了一种新的双向标签间自我训练框架TWIST。它利用语义理解和场景实例信息之间的内在相关性。具体来说,考虑两种用于语义级和实例级监督的伪标签。我们的重点设计是提供对象级信息去噪伪标签,利用伪标签的相关性进行双向相互增强,从而迭代提升伪标签质量。
代码链接
本文的代码链接失效,所以找了团队代码主页
论文链接
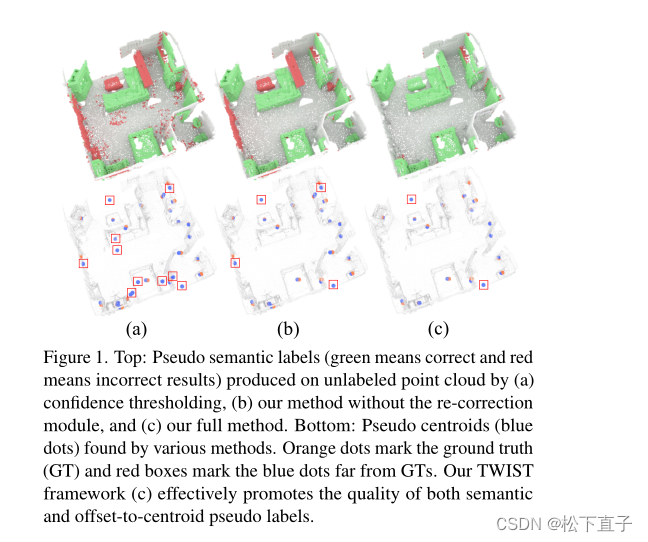
本文方法
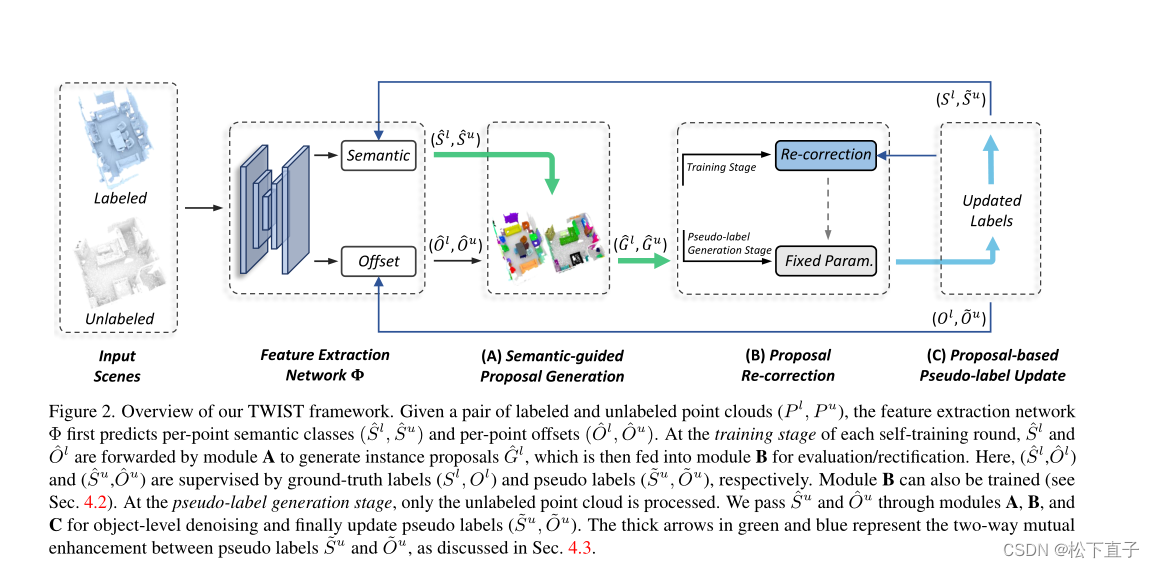
给定一对标记点云和一对未标记点云(P l, P u),特征提取网络Φ首先预测点语义类(Sl, Su)和点偏移量(Ol, Ou)
在每一轮自训练阶段,Sl和Ol前向传播经过A,生成实例建议Gl,然后传播到模块B进行评估/整改
在这里,(Sl, Ol)和(Su, Ou)分别由真实标签(Sl, Ol)和伪标签( ̄Su, ̄Ou)监督,模块B也可以被训练
在伪标签生成阶段,只对未标记的点云进行处理
通过模块A、B和C传递Su和Ou以进行对象级去噪,最后更新伪标签(≈Su,≈Ou)。绿色和蓝色的粗箭头表示伪标签~ Su和~ Ou之间的双向相互增强
将(Sl, Ol, Gl)和(Su, Ou, Gu)分别表示为在P l和Pu上预测的点语义类、点偏移量和实例建议,将Sl和Ol分别表示为P l的点真实语义标签和偏移量向量。
步骤1:
初始化阶段,在这个阶段我们训练模型Φ,在所有标记的点云上使用第3节中描述的模型,并在第0轮自我训练时使用θr0模型权重。每个P l的目标是

步骤2
伪标签生成阶段。在自我训练的第t轮,我们首先使用学习模型Φ对每个未标记点云Pu预测语义类Su和偏移向量Ou,然后对其进行细化,生成伪语义标签Su和伪偏移向量Ou
步骤3
是网络模型更新的训练阶段。此外,在自我训练的第t轮,我们使用pseudo标签~ Su和~ Ou来细化模型Φ(θrt−1)进入Φ( θrt)。
对于每个点云对(P l, P u),训练目标为
自训练在步骤2和3之间迭代,直到性能收敛。重要的是,伪语义标签~ Su提供类级监督,伪偏移向量~ Ou提供实例级监督,允许使用未标记的数据更新网络模型。
- 首先,语义引导建议生成模块将相同语义预测的点聚类到每个未标记点云P u中的候选实例提案Gu。
- 由于这些建议可能不准确,我们设计了提案重新修正模块,这是一个可学习的模型,通过对象级评估/细化来定位更可靠的实例建议
- 基于建议的伪标签更新模块从可靠的实例提案中生成pseudo标签~ Su和~ Ou,并帮助强制建议内的一致性
语义引导的实例提议生成
语义引导的实例建议生成模块使用聚类算法,以语义预测为指导,在输入点云Pl或Pu中生成实例建议
注意,我们在端到端网络训练(在Pl中输出Gl)和伪标签生成(在Pu中输出Gu)中都涉及到这一步。输出建议被馈送到重新校正模块进行建议级评估。
提议纠正
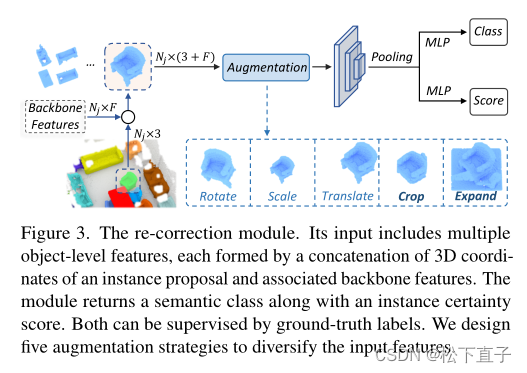
输入包括多个对象级特征,每个特征都是由实例建议的3D坐标和相关主干特征的连接形成的
该模块返回一个语义类以及实例确定性评分
两者都可以通过标签进行监督
设计了五种增强策略来丰富输入特征
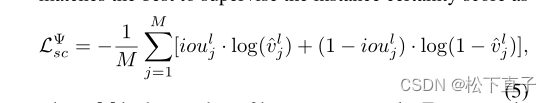
M是实例提议的数量
基于提议的伪标签更新
在每一轮自训练的伪标签生成阶段,对于一个未标记的点云P u,重新校正模块对P u预测的每个实例生成一个重新预测的语义类和实例确定性得分。得分高于0.5的实例提义被用于提议级伪标签更新
为了更新伪偏移向量,我们首先生成每个提案guj的伪实例中心。我们没有直接选择guj的质心,而是通过考虑guj中的所有点来采用mean-shift结果,利用预测的偏移向量
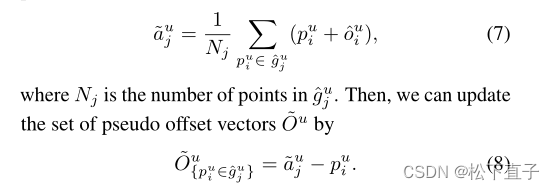
通过这种机制,我们在实例-提议级别更新了两种类型的伪标签,从而自然地保持了提议内伪标签的一致性
相互增强分析
TWIST的一个有趣的优点是,两个伪标签集的质量可以通过它们的双向交互而相互提高。
首先,更好的~ Su鼓励更好的语义预测,从而引导网络获得更好的实例建议(如图2中粗大的绿色箭头所示)。
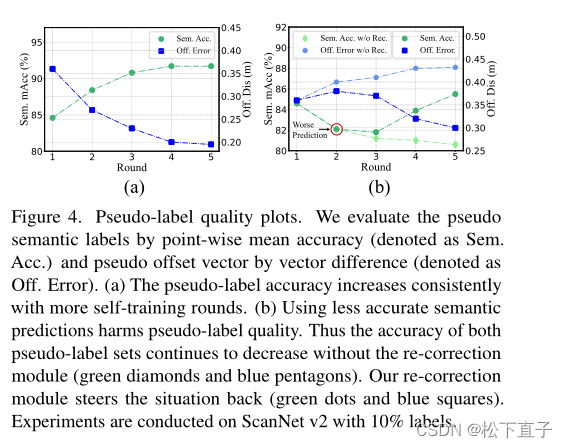
在一个提案中,点数更有可能来自同一对象,它们的mean-shift结果可以更可靠,从而提高~ Ou的质量。反过来,通过更好的~ Ou来训练更准确的偏移预测,更多更好的点集群可以生成用于更新伪语义标签的有效实例建议(由图2中粗大的蓝色箭头表示),其中可以生成更多~ Su并分配给高质量的点集。因此,在自我训练过程中,伪标签质量得到了共同的提高,如图4(a)所示。
此外,所设计的再校正模块可以有效地促使它们的相互作用向正方向收敛。如图4(b)所示,我们有意降低伪标签的质量,首先破坏10% GT标签的语义类进行模型训练,然后使用更新后的模型预测生成伪标签。当移除重新校正模块时,~ Su和~ Ou都受到精度降低的影响。幸运的是,当重新校正模块再次启用时,它们仍然可以恢复,甚至最终收敛到更好的状态。重新修正机制保证了模型的容错能力,促进了语义伪标签和偏移伪标签的相互促进作用。