【CLIP速度篇】Contrastive Language-Image Pretraining

【CLIP速度篇】Contrastive Language-Image Pretraining
- 0、前言
- Abstract
- 1. Introduction and Motivating Work
- 2. Approach
-
- 2.1. Natural Language Supervision
- 2.2. Creating a Sufficiently Large Dataset
- 2.3. Selecting an Efficient Pre-Training Method
- 2.4. Choosing and Scaling a Model
- 2.5. Training
- 3. Experiments
-
- 3.1. Zero-Shot Transfer
-
- 3.1.1 Motivation
- 3.1.2 Using CLIP for zero-shot transfer
- 3.1.3 Initial comparison to visual N-Grams
- 3.1.4 Prompt engineering and ensembling
- 3.1.5 Analysis of zero-shot clip preformance
- 3.2. Representation Learning
- 5. Data Overlap Analysis
- 6. Limitations
- 9. Conclusion
- Reference
论文地址&论文标题:Learning Transferable Visual Models From Natural Language Supervision(通过自然语言处理来的一些监督信号,可以去训练一个迁移效果很好的视觉模型)
项目地址:https://github.com/openai/CLIP
本篇博客主要将详细介绍CLIP的实现原理。
本文参考了很多论文和博客,不过相对于原文的48页而言也算是简明扼要一些,方便提升学习效率。(部分目录顺序沿用论文的)
0、前言
一言以蔽之:
CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image。
CLIP(对比语言-图像预训练)是一种在各种(图像、文本)对上训练的神经网络。可以用自然语言指示它在给定图像的情况下预测最相关的文本片段,而无需直接针对任务进行优化,类似于 GPT-2 和 3 的零样本功能。作者发现在不使用任何原始 1.28M 标记示例的情况下,CLIP 与原始 ResNet50 的性能相匹配,在 ImageNet 上“零样本”,克服了计算机视觉中的几个主要挑战。
Abstract
- 提出问题:现在的compute vision systems是训练模型来预测一组固定的、提前定义好的目标类别(比如ImageNet就是1000个类,COCO就是80个类),这种监督方式比较受限,因为需要额外的标记数据,限制了泛化性,如果有新的类别就要再去收集数据。
- 提出解决方案:直接从图像有关的原始文本中学习是一种很有前途的替代方案,它利用了更广泛的监督来源。给一些文本描述和一些图像,预测哪个标题和哪个图像搭配,这个预训练任务是一种有效且可扩展的方式,在从互联网收集的4亿(图像、文本)对的数据集上从头开始学习,能学到SOTA的image representations。
- 效果:预训练之后,natural language is used to reference learned visual concepts(or describe new ones) enabling zero-shot transfer of the model to 下游任务(自然语言引导模型去做物体的分类,分类不局限于已经学到的视觉概念,还能扩展到新的类别,从而现在学到的这个模型是能够直接在下游任务上做zero-shot的推理)。
- 实验:对超过30多个数据集进行测试来评估性能,涵盖OCR,视频中的动作识别、geo-localization和许多细粒度的分类,能轻松地转移到大多数任务,并且能达到和有监督的baseline方法差不多的性能,而无需任何数据集特定的训练。在ImageNet上,不使用那1.28 million训练样本,就能得到和有监督的ResNet-50差不多的结果。
1. Introduction and Motivating Work
之前的一些弱监督方法效果不好的原因主要在scale(规模),即数据集的规模和模型的规模。
论文的作者团队收集了一个超级大的图像文本配对的数据集,有400 million个图片文本的配对, 模型最大最好的是ViT-Large(ViT-L/14@336px),提出了CLIP(Contrastive Language-Image Pre-training),是一种从自然语言监督中学习的有效方法,在模型上一共尝试了8个模型(5个ResNets和3个Vision Transformers),从resnet到ViT,最小模型和最大模型之间的计算量相差约100倍,迁移学习的效果基本和模型大小成正相关。
对于ViT-L/14,还在更高的336像素分辨率下进行了额外一个时期的预训练,以提高性能最后称为(ViT-L/14@336px)
尝试了30个数据集,都能和之前的有监督的模型效果差不多甚至更好。
2. Approach

- CLIP是如何进行预训练的?
模型的输入是图片和文字的配对,图片输入到图片的encoder得到一些特征,文本输入到文本的encoder得到一些特征,每个traning batch里有n个图片-文本对,就能得到n个图片的特征和n个文本的特征,然后在这些特征上做对比学习,对比学习非常灵活,就需要正样本和负样本的定义,其它都是正常套路(不懂对比学习),配对的图片-文本对就是正样本,描述的是同一个东西,特征矩阵里对角线上的都是正样本,矩阵中非对角线上的元素都是负样本,n个正样本,n2-n个负样本,有了正负样本,模型就可以通过对比学习的方式去训练了,不需要任何手工标注。这种无监督的训练方式,是需要大量的训练数据的。 - CLIP是如何做zero-shot的推理的?
预训练之后只能得到文本和图片的特征,是没有分类头的,作者提出一种利用自然语言的方法,prompt template。比如对于ImageNet的类别,首先把它变成"A photo of a {object}" 这样一个句子,ImageNet有1000个类,就生成1000个句子,然后这1000个句子通过之前预训练好的文本的encoder能得到1000个文本特征。直接用类别单词去抽取文本特征也可以,但是模型预训练的时候和图片配对的都是句子,推理的时候用单词效果会下降。把需要分类的图片送入图片的encoder得到特征,拿图片的特征和1000个文本特征算余弦相似性,选最相似的那个文本特征对应的句子,从而完成了分类任务。不局限于这1000个类别,任何类别都可以。彻底摆脱了categorical label的限制,训练和推理的时候都不需要提前定义好的标签列表了。
2.1. Natural Language Supervision
方法的核心是the idea of learning perception from supervision contained in natural language.
相比其它的训练方法,从自然语言的监督信号来学习,有几个好处。首先就是it’s much easier to scale,不需要再去标注数据,比如用传统方法做分类,需要先确定类别,然后去下载图片再清洗,再标注,现在只需要去下载图片和文本的配对,数据集很容易就做大了,现在的监督对象是文本,而不是N选1的标签了。
其次,it doesn’t “just” learn a representation but also connects that representation to language which enables flexible zero-shot transfer. 训练的时候把图片和文本绑在了一起,学到的特征不再单是视觉特征了,而是多模态的特征,和语言连在一起以后,就很容易做zero-shot的迁移学习了。
2.2. Creating a Sufficiently Large Dataset
a major motivation for natural language supervision是互联网上公开提供了这种形式的大量数据。
现有的数据集不能充分反应这种可能性,因此仅考虑在这些数据集上的结果会低估这一研究方向的潜力。(也就是说现有数据集要么还不够大,要么质量不高)
为了解决这个问题,作者团队构建了400 million的图像文本对,这个数据集称作WIT(WebImage Text)。(i.e.因为最终数据集的总字数与用于训练GPT-2的WebText数据集相似。)
2.3. Selecting an Efficient Pre-Training Method
作者团队最初尝试的方法,类似VirTex,图像用CNN,文本用transformer,从头开始训练,预测图片的caption,这是一个预测型的任务,然而在efficiently scaling this method的时候遇到了困难。
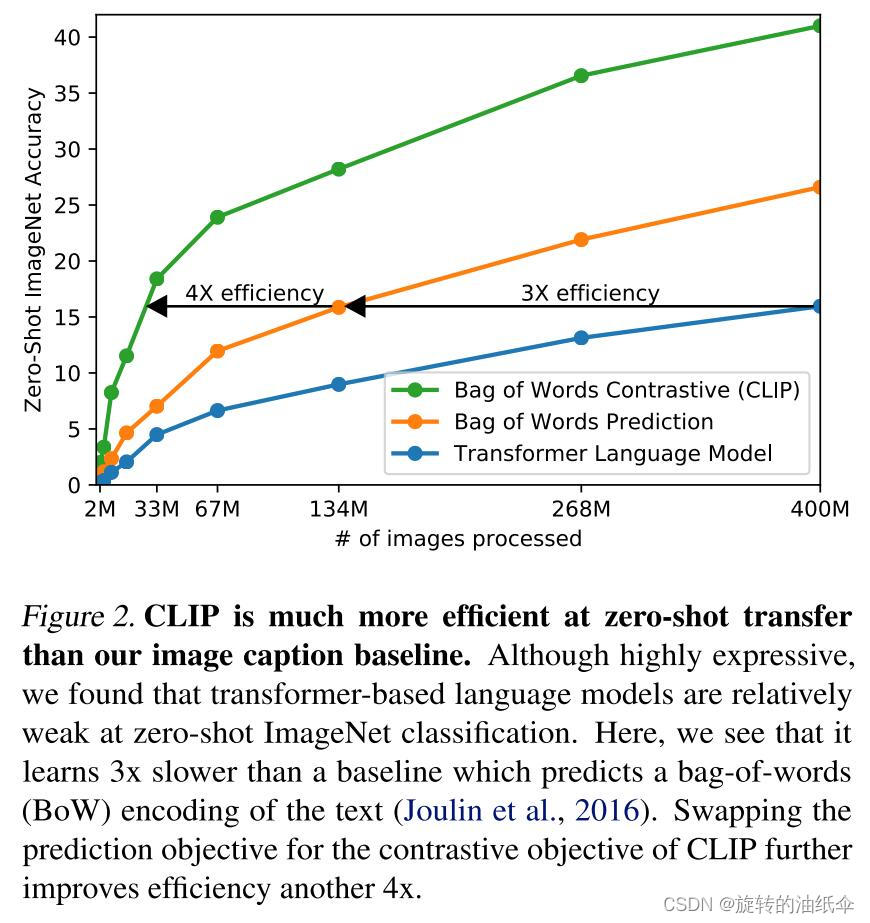
作者实验发现一个具有63 million参数的transformer language model,已经使用了ResNet-50 image encoder两倍的算力,但是学习识别ImageNet类比预测相同文本的bag-of-words编码的更简单的基线慢三倍。learns to recognize ImageNet classes three times slower than a much simpler baseline that predicts a bag-of-words encoding of the same text.
这个任务在试图预测每张图片所附文本的确切单词(给定一张图片,去预测对应文本,要逐字逐句去预测文本的),这是个困难的任务,因为与图像同时出现的描述、评论和相关文本种类繁多。
最近在图像对比学习方面的工作发现,对比目标比其等价的预测目标能够学习更好的表征contrastive objectives can learn better representations than their equivalent predictive objective.
其他一些研究发现,尽管图像的生成模型能够学习高质量的image representations,但它们的计算量比相同性能的对比模型要多一个数量级。
基于这些发现,本文探索训练了一个系统来解决潜在的更容易的代理任务,即只预测哪个文本作为一个整体和哪个图像配对,而不是预测该文本的确切单词(predict only which text as a whole is paired with which image and not the exact words of that text),效率提高了4倍。
也就是说:Bag of Words Prediction于Transformer Language Model而言效率提高了3倍
Bag of Words Contrastive (CLIP) 于Bag of Words Prediction而言又提高了4倍。
也就是说Bag of Words Contrastive (CLIP) 比Transformer Language Model提高了12倍。
如图:
给定一批N个(图像,文本)对,CLIP被训练来预测一批中N ×N个可能的(图像,文本)配对中的哪一个实际发生。
要做到这一点,CLIP通过联合训练图像编码器和文本编码器来学习多模态嵌入空间,以最大化批次中N个真实配对的real pairs图像和文本嵌入的余弦相似性,同时最小化N2-N个不正确配对的incorrect pairings嵌入的余弦相似性。我们优化这些相似性分数的对称交叉熵损失symmetric cross entropy loss。
下图是CLIP核心实现的伪代码pseudocode:

有两个输入,一个是图片,一个是文本,图片的维度是[n,h,w,c],文本的维度是[n,l],l是指序列长度,n是一个minibatch的大小。
然后送入到各自的encoder提取特征,image encoder可以是ResNet也可以是Vision Transformer,text encoder可以是CBOW,也可以是Text Transformer.
得到对应的特征之后,再经过一个投射层(即W_i和W_t),投射层的意义是学习如何从单模态变成多模态,投射完之后再做l2 norm,就得到了最终的用来对比的特征I_e和T_e。现在有n个图像的特征,和n个文本的特征,接下来就是算consine similarity,算的相似度就是最后要分类的logits,最后logits和ground truth做交叉熵loss,正样本是对角线上的元素,logits的维度是[n,n],ground truth label是np.arange(n)。(这里不懂为什么是np.arange(n)这样的ground truth)
最后是算两个loss,一个是image的,一个是text的,最后把两个loss加起来就平均。这个操作在对比学习中是很常见的,都是用的这种对称式的目标函数。
数据集很大很大,over-fitting不是主要问题,相对而言训练CLIP的细节也比较简单。
从头开始训练,文本和图片的encoder都不使用预训练的weights,between the representation and the constastive embedding space也没有使用非线性的投射(projection),相反仅使用线性投影来从每个编码器的表示映射到多模态嵌入空间。(use only a linear projection to map from each encoder’s representation to the multi-modal embedding space.)
在之前对比学习的一些文章中提到过,非线性投射层比线性投射层能够带来将近10个点的性能提升,但是在CLIP中,作者发现线性还是非线性关系不大,他们怀疑非线性的投射层是用来适配纯图片的单模态学习的。
作者还删除了Zhang et al.(2020)中的文本转换函数tut_utu,该函数从文本中统一采样单个句子,因为CLIP预训练数据集中的许多(图像,文本)对只是一个句子。还简化了图像变换函数tvt_vtv。
唯一用的数据增强是随机裁剪(a random square crop from resized images)。
模型与数据集都实在是太大了,也不太好做调参的工作,在之前的对比学习中起到很重要作用的一个参数 temperature即τ\\tauτ(controls the range of the logits in the softmax),作者把它设置成了可学习的标量,直接在模型训练过程中优化,不需要调参。
2.4. Choosing and Scaling a Model
主要就将image encoder选了ResNet和ViT两种结构,text encoder只用了transformer
image encoder考虑了2种不同的结构。
For the first, 用ResNet-50作为base architecture,然后又对原始版本做了一些改动,利用attention pooling mechanism代替了global average pooling,the attention pooling is implemented as a single layer of “transformer-style” multi-head QKV attention where the query is conditioned on the global average-pooled representation of the image. 注意池被实现为单层“transformer-style”多头 QKV 注意力,其中查询以图像的全局平均池表示为条件。
For the second, 使用的Vision Transformer(ViT),只做了一点很小的修改,add an additional layer normalization to the combined patch and position embeddings before the transformer 并且使用了一个略微不同的初始化方案。
Text encoder是一个transformer,使用一个63M-parameter 12-layer 512-wide model with 8 attention heads作为base size,the transformer operates on a lower-cased byte pair encoding (BPE) representation of the text with a 49,152 vocab size(Transformer对文本的低位字节对编码 (BPE)表示进行操作,其单词大小为49,152 )。
为了计算高效,序列长度最大被限制为76. 在文本序列中加入[SOS]和[EOS]标记,并将[EOS]标记处transformer 最高层的激活作为文本的特征表示,对文本进行层归一化,然后线性投影到多模态嵌入空间。
在文本编码器中使用了掩蔽的自注意力masked self-attention,以保持用预先训练的语言模型初始化或添加语言模型作为辅助目标的能力,尽管这方面的探索有待于未来的工作。
2.5. Training
图片这边共训练了8个模型,5个ResNet和3个transformer,5个ResNet包括ResNet-50,ResNet-101,另外三个是根据efficientNet的方式对ResNet-50的宽度、深度、输入大小进行scaling,分别大约对应原始ResNet50 4倍,16倍,64倍的计算量,它们分别表示为RN50x4、RN50x16和RN50x64。 3个Vision Transformers包括ViT-B/32,ViT-B/16 和ViT-L/14。
所有的模型都训练了32个epochs,用的Adam Optimizer将解耦的权值衰减正则化应用于所有不是增益或偏差gains or biases的权值,并使用余弦调度cosine schedule来衰减学习速率。
初始超参数设置使用的grid searches,random search和manual tuning的组合在基线模型Resnet50上,训练了1个epoch。 由于计算的限制,超参数被启发式地heuristically适应于较大的模型。
可学习温度参数τ\\tauτ从(Wu et al.,2018)中初始化为等效的0.07,并进行裁剪,以防止将logits缩放超过100,我们发现这对于防止训练不稳定性是必要的。
使用的是32,768的非常大的MiniBatch大小。 混合精度Mixed-precision被用于加速训练和节省存储空间。
为了节省额外的内存,使用了gradient checkpointing、half-precision Adam statistics和half-precision stochastically rounded text encoder weights。
最大的那个ResNet(RN50x64)在592个V100的GPU上训练了18天,最大的ViT在256个V100 GPU上只花了12天。对预训练好的ViT-L/14,又在这个数据集上fine-tune了一个epoch,用的是更大分辨率336*336,这个模型称作ViT-L/14@336px,论文后面提到的CLIP除非特别说明,均指ViT-L/14@336px。
3. Experiments
3.1. Zero-Shot Transfer
3.1.1 Motivation
在计算机视觉中,zero-shot学习主要指 the study of generalizing to unseen object categories in image classification. 本文在更广的意义上使用这个术语,并研究对unseen datasets的泛化。
其中Visual N-grams对现有图像分类数据集的zero-shot transfer对CLIP的影响最大。然后GPT(Generative Pre-trained Transformer)化。
之前的那些自监督和无监督的方法,主要研究的是特征学习的能力,目标就是学一种泛化性比较好的特征,但即使学到了很好的特征,想应用到下游任务,还是需要有标签的数据做微调,所以有限制,比如下游任务数据不好收集,可能有distribution shift的问题。
怎么做到只训练一个模型,后面不再需要微调了呢,这就是作者研究zero-shot迁移的研究动机。借助文本训练了一个又大又好的模型之后,就可以借助这个文本作为引导,很灵活的做zero-shot的迁移学习。
3.1.2 Using CLIP for zero-shot transfer
参考Figure 1
在clip预训练好之后,就有2个编码器,一个是图像编码器,一个是文本编码器,推理时给定一张图片,通过编码器就能得到一个图片的特征,文本那边的输入就是感兴趣的标签有哪些,比如plane,car,dog等,这些词会通过prompt engineering得到对应的句子,比如‘A photo of a plane’,‘A photo of a dog’,有了这些句子以后,送入到文本编码器,就能得到对应的文本特征,这里假设是plane,car,dog这3个,然后拿这3个文本的特征去和那张图片的特征做余弦相似度,计算得到相似度以后再用温度参数τ缩放,之后通过一个softmax得到概率分布,概率最大的那个句子就是在描述这张照片。
3.1.3 Initial comparison to visual N-Grams

结果:
visual N-Grams在ImageNet上只有11.5%的准确率,而CLIP已经达到了76.2%,和ResNet50精度差不多,完全没有用1.28 million的训练图片,直接zero-shot迁移就能得到76.2%。
当然作者也指出了这种对比不公平,CLIP的数据集是之前的10倍,而且视觉上的模型比之前要多100倍的计算,加起来可能使用超过1000倍的训练计算。
另外CLIP用的是transformer,2017年visual N-Grams发表的时候transformer还没出现。(Attention Is All You Need即transformer是2017年6月发表的。)
3.1.4 Prompt engineering and ensembling
prompt是在做微调或者直接做推理时的一种方法,起到的是一个提示的作用,也就是文本的引导作用。
为什么要用Prompt engineering和Prompt ensembling呢?
第一:原因是polysemy,多义性,即一个单词可能同时有很多含义,如果在做文本和图片匹配的时候,每次只用一个单词,也就是标签对应的那个单词,去做文本的特征抽取,就有可能遇到问题,因为缺乏上下文信息,模型无法区分是哪个词义,比如在ImageNet里面同时包含两个类,construction cranes和cranes,在不同的语境下,这两个crane对应的意义是不一样的,在建筑工地环境下,construction cranes指的是起重机,作为动物,cranes指的是鹤,这就有歧义了。在Oxfort-IIIT Pet数据集中,有一类是boxer,根据上下文可知道它指的是一种狗,但对于缺乏上下文的文本编码器来说,极有可能把它当成拳击运动员。只用一个单词去做prompt,会经常出现歧义性的问题。
第二:另一个问题是,在预训练的时候,匹配的文本一般都是一个句子,很少出现一个单词的情况,如果推理的时候,每次进来的是一个单词,可能就存在distribution gap的问题,抽出来的特征可能就不好。
基于这两个问题,作者就提出了一种方式去做prompt template,利用这个模板“A photo of a {label}.” 把单词变成一个句子,把单词改成句子了,就不太会出现distribution gap的问题了,而且它的意思是“这是一张xxx的图片”,这个标签一般代表的都是名词,能一定程度上解决歧义性的问题。比如remote这个单词,就指的是遥控器,而不是遥远的。用上了提示模板之后,准确度提升了1.3%。
通过为每个任务自定义提示文本可以显著提高zero shot的能力。We found on several fine-grained image classification datasets that it helped to specify the category. 例如做Oxford-IIIT Pets这个数据集,它里面的类别肯定都是动物,给出的提示可以是这样的,“A photo of a {label}, a type of pet.” 这样就缩小了解空间,同样地在Food101数据集上可以指定“a type of food”,在FGVC Aircraft数据集上可以指定“a type of aircraft”,对于OCR数据集,作者发现在要识别的文本或数字旁加上引号可以提高性能。对卫星图像数据集,使用“a satellite photo of a {label}”这样的提示。
作者还尝试集成多个zero shot classifiers,即prompt ensembling ,作为提高性能的另一种方式。这些分类器是在不同的上下文提示下得到的,比如“A photo of a big {label}" 和”A photo of a small {label}"。我们在嵌入空间而不是概率空间上构建集成。这允许我们缓存一组平均文本嵌入,以便在分摊到许多预测时,集成的计算成本与使用单个分类器相同。We construct the ensemble over the embedding space instead of probability space. This allows us to cache a single set of averaged text embeddings so that the compute cost of the ensemble is the same as using a single classifier when amortized over many predictions. 在ImageNet上,共集成了80个不同的context prompts,这比单个的default prompt 提高了3.5%的性能。
作者在 Prompt_Engineering_for_ImageNet.ipynb列出了使用的这80个context prompts,比如有"a photo of many {}"适合包含多个物体的情况,"a photo of the hard to see {}"可能适合一些小目标或比较难辨认的目标。
 ▲部分截图\\blacktriangle部分截图▲部分截图
▲部分截图\\blacktriangle部分截图▲部分截图
3.1.5 Analysis of zero-shot clip preformance

Zero-shot CLIP在完全监督的baseline下是有竞争力的。 在27个数据集eval suite中,Zero-shot CLIP分类器的性能优于基于Resnet-50的特征的全 监督线性分类器,包括ImageNet在内的16个数据集。
我们看到Zero-shot CLIP 在卫星图像分类(EuroSAT 和 RESISC45)、淋巴结肿瘤检测(PatchCamelyon)、合成场景中的物体计数(CLEVRCounts)、自动驾驶等几个专门的、复杂的或抽象的任务上相当薄弱相关任务如德国交通标志识别(GTSRB),识别到最近汽车的距离(KITTI Distance)。这些结果凸显了Zero-shot CLIP 在更复杂任务上的较差能力。对于其中的一些困难的任务,没有先验知识很难有一个很好的表现。对于这种特别难的任务如果只做 zero-shot 不太合理,更适合去做 few-shot 的迁移,对于这种需要特定领域知识的任务(如肿瘤分类等)即是对于人类来说没有先验知识也是很难得。

Figure 6 横坐标是数据集中每一个类别里用了多少训练样本,0 的话就是 zero-shot 了,其他方法因为没有和自然语言的结合无法做 zero-shot,最低也得从 one-shot 开始。
纵坐标是平均准确度,是在 20 个数据集上取的平均(来源于 Figure 5 中的27 个数据集,其中有 7 个数据集的部分类别训练样本不足 16 个,无法满足横坐标要求,因此舍弃了)。
BiT(Big Transfer)主要为迁移学习量身定做,是 few-shot 迁移学习表现最好的工作之一。而 zero-shot CLIP 直接就和最好的 BiT 持平。如图紫色曲线,当每个类别仅仅用1、2、4个训练样本时还不如 zero-shot 的效果,这也证明了用文本来引导多模态学习是多么的强大。随着训练样本的增多, few-shot CLIP 的效果是最好的,不仅超越了之前的方法,也超越了 zero-shot CLIP。
3.2. Representation Learning
这里作者讨论了下游任务用全部数据,CLIP 的效果会如何。特征学习一般都是先预训练一个模型,然后在下游任务上用全部的数据做微调。这里在下游任务上用全部数据就可以和之前的特征学习方法做公平对比了。
衡量模型的性能最常见的两种方式就是通过 linear probe 或 fine-tune 后衡量其在各种数据集上的性能。linear probe 就是把预训练好的模型参数冻结,然后在上面训练一个分类头;fine-tune 就是把整个网络参数都放开,直接去做 end-to-end 的学习。fine-tune 一般是更灵活的,而且在下游数据集比较大时,fine-tune往往比 linear probe 的效果要好很多。
但本文作者选用了 linear probe,因为 CLIP 的工作就是用来研究这种跟数据集无关的预训练方式,如果下游数据集足够大,整个网络都放开再在数据集上做 fine-tune 的话,就无法分别预训练的模型到底好不好了(有可能预训练的模型并不好,但是在 fine-tune 的过程中经过不断的优化,导致最后的效果也很好)。而 linear probe 这种用线性分类头的方式,就不太灵活,整个网络大部分都是冻住的,只有最后一层 FC 层是可以训练的,可学习的空间比较小,如果预训练的模型不太好的话,即使在下游任务上训练很久,也很难优化到特别好的结果,所以更能反映出预训练模型的好坏。此外,作者选用 linear probe 的另一个原因就是不怎么需要调参,CLIP 调参的话太耗费资源了,如果做 fine-tune 就有太多可做的调参和设计方案了。

如 Figure 10 右图所示,是在先前提到的那 27 个数据集进行比较,横坐标是计算量,纵坐标是评价分数。显然是越靠近左上角的模型越好。其中CLIP(实心、空心红色五角星)比所有的其他模型都要好,不光是上文中讲过的 zero-shot 和 few-shot,现在用全部的数据去做训练时 CLIP 依然比其他模型强得多。
如 Figure 10 左图所示,之前有工作提出了这 12 个数据集的集合,很多人都是在这些数据集上做的比较,CLIP-ViT 的效果是很好的,但是 CLIP-ResNet 就要比别的方法差了。但是这 12 个数据集的集合和 ImageNet 的关系很大,如果模型之前在 ImageNet 做过有监督的预训练,那么效果肯定是更好的,因此 CLIP-ResNet 并没有那么好也是可以理解的。

随后作者又将 CLIP 与 之前在 ImageNet 上表现最好的模型 EfficientNet L2 NS(最大的 EfficientNet 并使用为标签的方式训练)进行对比。在 27 个数据集中,CLIP 在其中 21 个数据集都超过了 EfficientNet,而且很多数据集都是大比分超过,少部分数据集也仅仅是比 EfficientNet 稍低一点点。
Zero-shot CLIP比标准ImageNet模型对分布偏移更鲁棒。

5. Data Overlap Analysis
为了分析是否是因为本文使用的数据集与其他的数据集之间有重叠而导致模型的性能比较好,作者在这部分做了一些去重的实验,最后的结论还是 CLIP 本身的泛化性能比较好。
6. Limitations
(1) CLIP 在很多数据集上平均来看都能和普通的 baseline 模型(即在 ImageNet 训练的 ResNet50)打成平手,但是在大多数数据集上,ResNet50 并不是 SOTA,与最好的模型比还是有所差距的,CLIP 很强,但又不是特别强。实验表明,如果加大数据集,也加大模型的话,CLIP 的性能还能继续提高,但如果想把各个数据集上的 SOTA 的差距弥补上的话,作者预估还需要在现在训练 CLIP 的计算量的基础上的 1000 倍,这个硬件条件很难满足。如果想要 CLIP 在各个数据集上都达到 SOTA 的效果,必须要有新的方法在计算和数据的效率上有进一步的提高。
(2) zero-shot CLIP 在某些数据集上表现也并不好,在一些细分类任务上,CLIP 的性能低于 ResNet50。同时 CLIP 也无法处理抽象的概念,也无法做一些更难的任务(如统计某个物体的个数)。作者认为还有很多很多任务,CLIP 的 zero-shot 表现接近于瞎猜。
(3) CLIP 虽然泛化能力强,在许多自然图像上还是很稳健的,但是如果在做推理时,这个数据与训练的数据差别非常大,即 out-of-distribution,那么 CLIP 的泛化能力也很差。比如,CLIP 在 MNIST 的手写数字上只达到88%的准确率,一个简单的逻辑回归的 baseline 都能超过 zero-shot CLIP。 语义检索和近重复最近邻检索都验证了在我们的预训练数据集中几乎没有与MNIST数字相似的图像。 这表明CLIP在解决深度学习模型的脆弱泛化这一潜在问题上做得很少。 相反,CLIP 试图回避这个问题,并希望通过在如此庞大和多样的数据集上进行训练,使所有数据都能有效地分布在分布中。
(4) 虽然 CLIP 可以做 zero-shot 的分类任务,但它还是在你给定的这些类别中去做选择。这是一个很大的限制,与一个真正灵活的方法,如 image captioning,直接生成图像的标题,这样的话一切都是模型在处理。 不幸的是,作者发现 image captioning 的 baseline 的计算效率比 CLIP 低得多。一个值得尝试的简单想法是将对比目标函数和生成目标函数联合训练,希望将 CLIP 的高效性和 caption 模型的灵活性结合起来。
(5) CLIP 对数据的利用还不是很高效,如果能够减少数据用量是极好的。将CLIP与自监督(Data-Efficient Image Recognition with Contrastive Predictive Coding;Big Self-Supervised Models are Strong Semi-Supervised Learners)和自训练(Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Network;Self-training with Noisy Student improves ImageNet classification)方法相结合是一个有希望的方向,因为它们证明了比标准监督学习更能提高数据效率。
(6) 在研发 CLIP 的过程中为了做公平的比较,并得到一些回馈,往往是在整个测试的数据集上做测试,尝试了很多变体,调整了很多超参,才定下了这套网络结构和超参数。而在研发中,每次都是用 ImageNet 做指导,这已经无形之中带入了偏见,且不是真正的 zero-shot 的情况,此外也是不断用那 27 个数据集做测试。创建一个新的任务基准,明确用于评估广泛的 zero-shot 迁移能力,而不是重复使用现有的有监督的数据集,将有助于解决这些问题。
(7) 因为数据集都是从网上爬的,这些图片-文本对儿基本是没有经过清洗的,所以最后训练出的 CLIP 就很可能带有社会上的偏见,比如性别、肤色、宗教等等。
(8) 虽然我们一直强调,通过自然语言引导图像分类器是一种灵活和通用的接口,但它有自己的局限性。 许多复杂的任务和视觉概念可能很难仅仅通过文本来指导,即使用语言也无法描述。不可否认,实际的训练示例是有用的,但 CLIP 并没有直接优化 few-shot 的性能。 在作者的工作中,我们回到在CLIP特征上拟合线性分类器。 当从 zero-shot 转换到设置 few-shot 时,当 one-shot、two-shot、four-shot 时反而不如 zero-shot,不提供训练样本时反而比提供少量训练样本时查了,这与人类的表现明显不同,人类的表现显示了从 zero-shot 到 one-shot 大幅增加。今后需要开展工作,让 CLIP 既在 zero-shot 表现很好,也能在 few-shot 表现很好。
9. Conclusion
作者的研究动机就是在 NLP 领域利用大规模数据去预训练模型,而且用这种跟下游任务无关的训练方式,NLP 那边取得了非常革命性的成功,比如 GPT-3。作者希望把 NLP 中的这种成功应用到其他领域,如视觉领域。作者发现在视觉中用了这一套思路之后确实效果也不错,并讨论了这一研究路线的社会影响力。在预训练时 CLIP 使用了对比学习,利用文本的提示去做 zero-shot 迁移学习。在大规模数据集和大模型的双向加持下,CLIP 的性能可以与特定任务的有监督训练出来的模型竞争,同时也有很大的改进空间。
推荐博客:
How to Train Really Large Models on Many GPUs?如何利用多GPU训练大模型 这个博主干货很多 openai的员工。其最有名的What are Diffusion Models?是学习扩散模型必看的一篇博客。
其它好玩的应用:
StyleCLIP:根据输入的文本进行人脸编辑
CLIPDraw:根据输入的文本生成画
CLIPS:根据输入的文本从视频中检索到相关物体
Reference
【1】:CLIP 论文逐段精读【论文精读】_哔哩哔哩_bilibili
【2】:https://zhuanlan.zhihu.com/p/511460120
【3】:https://blog.csdn.net/Friedrichor/article/details/127272167?ops_request_misc=&request_id=&biz_id=102&utm_term=CLIP&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-1-127272167.nonecase&spm=1018.2226.3001.4187