java基础学习-5

Java基础学习-5
- 快乐算法
-
- 二分查找
-
- 小总结
- 分块查找
- 冒泡
- 选择
- 插入排序
- 递归算法
- 快速排序
-
- 小总结
- Arrays
- Lambda表达式
-
- 小总结
- Lambda表达式的省略写法
-
- 小练习
177-200
快乐算法
七大查找算法:
查找是在大量的信息中寻找一个特定的信息元素,在计算机应用中,查找是常用的基本运算,例如编译程序中符号表的查找。文本简单概括性的介绍了常见的其中查找算法,说是七种,其实是二分查找、插值查找以及斐波那契查找都可以归为一类–插值查找。插值查找和斐波那契查找是在二分查找的基础上的优化查找算法,树表查找和哈希查找。
顺序查找-----略
二分查找
前提条件:数组中的数据必须是有序的
升序或者降序排列
核心逻辑:每次排除一半的查找范围
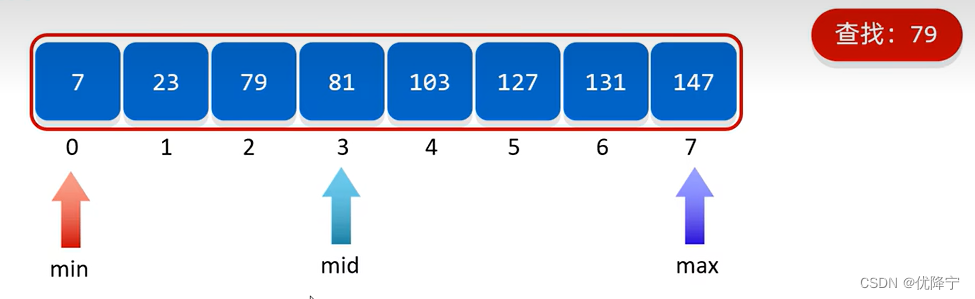
1、min和max表示当前要查找的范围
2、mid是在min和max中间的
3、如果要查找的元素在mid的左边,缩小范围时,min不变,max等于mid减1
4、如果要查找的元素在mid的右边,缩小范围,max不变,min等于mid加1
//定义两个变量记录要查找的范围
int min = 0;
int max = arr.length-1;
//利用循环不断地取找要查找的数据
while(true){if(min>max){return -1;}//找到min和max的中间位置int mid = (min+max)/2;//拿着mid指向的元素跟要查找的元素进行比较//number在mid的右边//number跟mid指向的元素一样if(arr[mid]>number){//number在mid的左边//min不变,max=mid-1;max=mid-1;}else if(arr[mid]<number){//number在mid的右边//max不变,min=mid+1;min=mid+1;}else{//number跟mid指向的元素一样return mid;}
}
小总结
1、二分查找的优势?
提高查找效率
2、二分查找的前提条件?
数据必须是有序的
如果数据是乱的,先排序再用二分查找得到的索引没有实际意义,只能确定当前数字在数组中是否存在,因为排序之后数字的位置就可能发生变化了
3、二分查找的过程
min和max表示当前要查找的范围
mid是在min和max中间的
如果要查找的元素在mid的左边,缩小范围时,min不变,max等于mid-1
如果要查找的元素在mid的右边,缩小范围时,max不变,min等于mid+1
4、二分查找、插值查找、斐波那契查询各自的特点
相同点:
都是通过不断缩小范围来查找对应的数据的
不同点:
计算mid的方式不一样
二分查找:mid每次都是指向范围的中间位置
插值查找:mid尽可能地靠近要查找的数据,但是要求数据尽可能地分布均匀
斐波那契查找:根据黄金分割点来计算mid指向的位置
分块查找
分块的原则1:前一块中的最大数据,小于后一块中的所有数据(块内无序,块间有序)
分块的原则2:块数数量一般等于数字的个数开根号。比如:16个数字一般分为4个块左右
核心思路:先确定要查找的元素在哪一个块,然后在块中挨个查找
冒泡
冒泡排序:相邻的数据两两比较,小的放前面,大的放后面
1、相邻的元素两两比较,大的放右边,小的放左边
2、第一轮循环结束,最大值已经找到,,在数组的最右边
3、第二轮循环只要在剩余的元素找最大值就可以了
4、每二轮循环结束,次大值已经确定,第三轮循环继续在剩余数据中循环
1、相邻的元素两两比较,大的放右边,小的放左边
2、第一轮比较完毕之后,最大值就已经确定,第二轮可以少循环一次,后面以此类推
3、如果数组中有n个数据,总共我们只要执行n-1轮的代码就可以
选择
选择排序:从0索引开始,拿着每一个索引上的元素跟后面的元素依次比较,小的放前面,大的放后面,以此类推。
1、从0索引开始,跟后面的元素一一作比较
2、小的放前面,大的放后面
3、第一轮循环结束后,最小的数据已经确定
4、第二轮循环从1索引开始以此类推
5、第三轮循环从2索引开始以此类推
6、第四轮循环从3索引开始以此类推
插入排序
将0索引的元素到N索引的元素看作是有序的,把N+1索引的元素到最后一个当成是无序的。遍历无序的数据,将遍历到的元素插入有序序列中适当的位置,如遇到相同的数据,插入在后面
//1、找到无序的那一组数组是从哪个索引开始的
int startIndex=-1;
for(int i=0;i<arr.length;i++){if(arr[i]>arr[i+1]){startIndex=i+1;break;}
}
//2、遍历从startIndex开始到最后一个元素,依次得到无序的那一组数据中的每一个元素
for(int i=startIndex;i<arr.length;i++){//问题:如何把遍历到的数据,插入到前面有序的这一组当中//记录当前要插入数据的索引int j=i;while(j>0&&arr[j]<arr[j-1]){//交换位置int temp=arr[j];arr[j]=arr[j-1];arr[j-1]=temp;j--;}printArr(arr);
}
递归算法
递归指的是方法中调用方法本身的现象
递归的注意点:递归一定要有出口,否则就会出现内存溢出
把一个复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解
递归策略只需少量的程序就可描述除解题过程所需要的多次重复计算
写递归的两个核心:
找出口:什么时候不再调用方法
找规则:如何把大问题变成规模较小的问题
方法内部再次调用方法的时候,参数必须要更加的靠近出口
public static int getFactorialRecursion(int number){if(number==1){return 1;}return number*getFactorialRecursion(number:number-1);
}
快速排序
第一轮:把0索引的数字作为基准数,确定基准数在数组中正确的位置
比基准数小的全部在左边,比基准数大的全部在右边
public static void quickSort(int[] arr,int i,int j){//定义两个变量记录要查找的范围int start = i;int end = j;if(start>end){return;}//记录基准数int baseNumber = arr[i];while(start!=end){//利用end,从后往前开始找,找比基准数小的数字while(true){if(end<=start||arr[end]<baseNumber){break;}end--;}//利用start,从前往后找,找比基准数大的数字while(true){if(end<=start||arr[start]>baseNumber){break;}start--;}//把end和start指向的元素进行交换int temp = arr[start];arr[start]=arr[end];arr[end]=temp;}//当start和end指向了同一个元素的时候,那么上面的循环就会结束//表示已经找到了基准数在数组中应存入的位置//基准数归位//就是拿着这个范围中的第一个数字,跟start指向的元素进行交换int temp = arr[i];arr[i] = arr[start];arr[start]=temp;quickSort(arr,i,j:start-1);quickSor(arr,i:start+1,j);
}
小总结
1、冒泡排序
相邻的元素两两比较,小的放前面,大的放后面
2、选择排序:
从0索引开始,拿着每一个索引上的元素跟后面的元素依次比较
小的放前面,大的放后面,依次类推
3、插入排序
将数组分为有序和无序两组,遍历无序数组,将元素插入有序序列中即可。
4、快速排序
将排序范围中的第一个数字作为基准数字,再定义两个变量start、end
start从前往后找比基准数大的,end从后往前找比基准数小的
找到之后交换start和end指向的元素,并循环这一过程,直到start和end处于同一个位置,该位置是基准数在数组中应存入的位置,再让基准数归位
归为后的效果:基准数左边的,比基准数小。基准数右边的,比基准数大
Arrays
操作数组的工具类
public static Stirng toString(数组)----把数组拼接成一个字符串
public static int binarySearch(数组,查找的元素)----二分查找法查找元素
public static int[] copyOf(原数组,新数组长度)----拷贝数组
public static int[] copyOfRange(原数组,起始索引,结束索引)----拷贝数组(指定范围)
public static void fill(数组,元素)----填充数组
public static void sort(数组)----按照默认方式进行数组排序
public static void sort(数组,排序规则)----按照指定的规则排序
binarySearch:二分查找法查找元素
细节1:二分查找的前提:数组中的元素必须是有序,数组中的元素必须是升序的
细节2:如果要查找的元素是存在的,那么返回的是真实的索引
但是,如果要查找的元素是不存在的,返回的是-插入点-1
疑问:为什么要减1呢?
解释:如果此时,我现在要查找数字0,那么如果返回的值是-插入点,就会出现问题了
如果要查找数字0,此时0是不存在的,但是按照上面的规则-插入点,应该就是-0
为了避免这样的情况,Java在这个基础上又减一。
copyOf:拷贝数组
参数一:老数组
参数二:新数组的长度
方法的底层会根据第二个参数来创建新的数组
如果新数组的长度是小于老数组的长度,会部分拷贝
如果新数组的长度是等于老数组的长度,会完全拷贝
如果新数组的长度是大于老数组的长度,会补上默认初始值
copyOfRange:拷贝数组(指定范围)
细节:包头不包尾,包左不包右
sort:排序,默认情况下,给基本数据类型进行升序排列,底层使用的是快速排序
sort(数组,排序规则)按照指定的规则排序
参数一:要排序的数组
参数二:排序的规则
细节:只能给引用数据类型的数组进行排序
如果数组是基本数据类型的,需要变成其对于的包装类
第二个参数是一个接口,所以我们在调用方法的时候,需要传递这个接口的实现类对象,作为排序的规则。
但是这个实现类,我只要使用依次,所以就没有必要单独的去写一个类,直接采取匿名内部类的方式就可以了
底层原理
利用插入排序+二分查找的方式进行排序
默认把0索引的数据当作是有序的序列,索引到最后认为是无序的序列
遍历无需的序列得到里面的每一个元素,假设当前遍历得到的元素是A元素
把A往有序序列中进行插入,在插入的时候,是利用二分查找确定A元素的插入点
拿着A元素,跟插入点的元素进行比较,比较的规则就是compare方法的方法体
如果方法的返回值是负数,拿着A继续跟前面的数据进行比较
如果方法的返回值是正数,拿着A继续跟后面的数据进行比较
如果方法的返回值是0,也拿着A跟后面的数据进行比较
直到能确定A的最终位置为止
compare方法的形式参数:
参数 o1:表示在无序序列中,遍历得到的每一个元素
参数o2:有序序列中的元素
返回值:
负数:表示当前要插入的元素是小的,放在前面
正数:表示当前要插入的元素是大的,放在后面
0:表示当前要插入的元素跟现在的元素比是一样的我们也会放在后面。
简单理解
o1-o2:升序排列
o2-o1:降序排列
Lambda表达式
函数式编程
函数式编程是一种思想特点
面向对象:先找对象,让对象做事情
函数式编程思想,忽略面向对象的复杂语法,强调做什么,而不是谁去做
而我们要学习的Lambda表达式就是函数式思想的体现
Lambda表达式是JDK8开始后的一种新语法形式
()->{
}
()对应着方法的形参
->固定格式
{}对应着方法的方法体
Lambda表达式可以用来简化匿名内部类的书写
Lambda表达式只能简化函数式接口的匿名内部类的写法
函数式接口:有且仅有一个抽象方法的接口叫做函数式接口,接口上方可以加@FunctionalInterface注解
小总结
1、Lambda表达式的基本作用?
简化函数式接口的匿名内部类的写法
2、Lambda表达式有什么使用前提?
必须是接口的匿名内部类,接口中只能有一个抽象方法
3、Lambda的好处?
Lambda是一个匿名函数,我们可以把Lambda表达式理解为是一段可以传递的代码,它可以写出更简洁、更灵活的代码,作为一种更紧凑的代码风格,使Java语言表达能力得到了提升
Lambda表达式的省略写法
省略核心:可推导,可省略
省略规则:
1、参数类型可以省略不写
2、如果只有一个参数,参数类型可以省略,同时()也可以省略
3、如果Lambda表达式的方法体只有一行,大括号,分号,return可以省略不写,需要同时省略
小练习
Lambda表达式简化Comparator接口的匿名形式
定义数组并存储一些字符串,利用Arrays中的sort方法进行排序
要求:
按照字符串的长度进行排序,短的在前面,长的在后面
(暂时不比较字符串里面的内容)
String[] arr = {"a","aaaa","aaa","aa"};
Arrays.sort(arr,(String o1,String o2)->{return o1.length()-o2.length();}
}
String[] arr = {"a","aaaa","aaa","aa"};
Arrays.sort(arr,(o1,o2)->o1.length()-o2.length());