Caffe

目录
1、简述
2、项目起源
3、架构设计
4、极智AI相关内容
1、简述
Caffe(全称Convolutional Architecture for Fast Feature Embedding)是一个兼具表达性、速度和思维模块化的深度学习框架,由伯克利人工智能研究小组和伯克利视觉和学习中心开发。虽然其内核是用C++编写的,但Caffe有Python和Matlab相关接口。
2、项目起源
Caffe是一个深度学习框架,最初开发于加利福尼亚大学伯克利分校。Caffe在BSD许可下开源,使用C++编写,带有Python接口。是贾扬清在加州大学伯克利分校攻读博士期间创建了Caffe项目。项目托管于GitHub,拥有众多贡献者。Caffe应用于学术研究项目、初创原型甚至视觉、语音和多媒体领域的大规模工业应用。雅虎还将Caffe与Apache Spark集成在一起,创建了一个分布式深度学习框架CaffeOnSpark。2017年4月,Facebook发布Caffe2,加入了递归神经网络等新功能。2018年3月底,Caffe2并入PyTorch。
3、架构设计
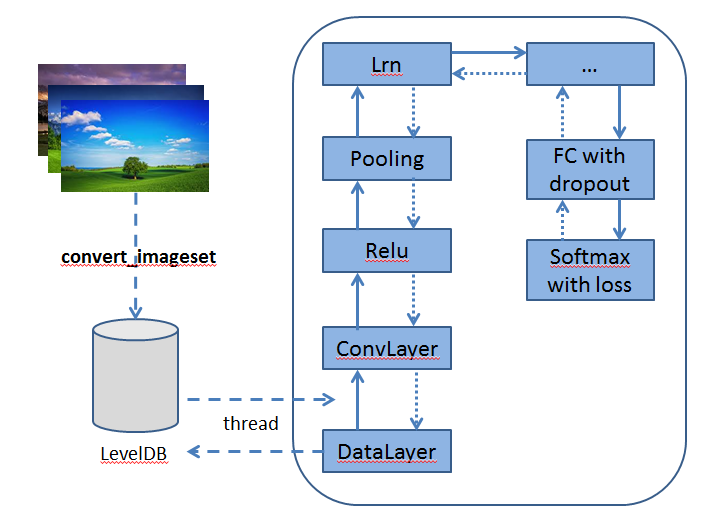
Caffe 完全开源,并且在有多个活跃社区沟通解答问题,同时提供了一个用于训练、测试等完整工具包,可以帮助使用者快速上手。此外 Caffe 还具有以下特点:
模块性:Caffe 以模块化原则设计,实现了对新的数据格式,网络层和损失函数轻松扩展。
表示和实现分离:Caffe 已经用谷歌的 Protocl Buffer定义模型文件。使用特殊的文本文件 prototxt 表示网络结构,以有向非循环图形式的网络构建。
Python和MATLAB结合: Caffe 提供了 Python 和 MATLAB 接口,供使用者选择熟悉的语言调用部署算法应用。
GPU 加速:利用了 MKL、Open BLAS、cu BLAS 等计算库,利用GPU实现计算加速。
简单来讲,Caffe 中的数据结构是以 Blobs-layers-Net 形式存在。其中,Blobs 是通过 4 维向量形式(num,channel,height,width)存储网络中所有权重,激活值以及正向反向的数据。作为 Caffe 的标准数据格式,Blob 提供了统一内存接口。Layers 表示的是神经网络中具体层,例如卷积层等,是 Caffe 模型的本质内容和执行计算的基本单元。layer 层接收底层输入的 Blobs,向高层输出 Blobs。在每层会实现前向传播,后向传播。Net 是由多个层连接在一起,组成的有向无环图。一个网络将最初的 data 数据层加载数据开始到最后的 loss 层组合为整体。
4、极智AI相关内容
caffe 是一个 古老而又优秀的深度学习训练框架,用过 caffe 的大部分都是从业 AI 三四年以上的开发者了。caffe 现在听起来更像 AI 训练框架的上古神兽,现在很多的训练中都不太会用 caffe 了,但它与现在主流的 AI 训练框架却紧密结合 (2017 年 4 月,Facebook 发布 Caffe2,加入了递归神经网络等新功能。2018 年 3 月底,Caffe2 并入了 PyTorch);另外有些场景还是会用到:某些特定硬件部署 (如海思、国产硬件 或 其他一些低算力硬件),这些 "自研推理框架" 大多会 优先 支持 caffe 模型的导入。理由可能也比较简单:(1) 具备规划推理框架的 "大佬", 可能最开始就是用 caffe 的,对此会比较熟悉;(2) caffe 算子定义清晰,使用 google protobuf,具有编译校验功能;(3) caffe 算子粒度大,对推理支持起来比较友好... (当然可能还会有更多原因)。
大家知道,caffe 的作者是大名鼎鼎的 贾扬清,其同样也是著名框架 tensorflow 的核心开发者,目前是阿里副总裁、阿里达摩院系统AI实验室负责人。
但是,相信很多用过 caffe 的同学,也都会吐槽:caffe 的安装真的是吐血。没错,搭建深度学习环境中有两个堪称麻烦:(1) opencv 源码编译;(2) caffe 的编译安装。关于 caffe 的安装,由于 caffe 推出的时间比较早,且早就不再更新维护了,所以对于一些更新的系统环境上编译 caffe,就可能会遇到各种问题,如在 cudnn8 上编译原生的 caffe,你就会发现编译过不了。但一旦你把 caffe 安装好了,到了使用阶段,你就会发现 caffe 用起来特别方便,甚至都不要求你有编码能力,直接改一些 prototxt 就可以轻松上手训练可用的深度学习模型,而且 caffe 出来的模型,对于模型部署是最友好的。
我本身对于 caffe 也有浓厚的感情,也属于那一批刚学深度学习时用的还是 caffe 的同学。所以我之前也写了挺多关于 caffe 的一些文章,涉及 caffe 的编译安装 (包括适配 cudnn8)、一些 caffe 的算子实现解读等,这里整理了一下:
- 极智AI | ubuntu cudnn8 源码编译caffe:https://blog.csdn.net/weixin_42405819/article/details/118114026
- 极智AI | 让 caffe-cudnn8 支持 yolov3:https://blog.csdn.net/weixin_42405819/article/details/118193046
- 极智AI | 一文看懂 caffe 生成 VOC0712 lmdb 数据集:https://blog.csdn.net/weixin_42405819/article/details/118878863
- 极智AI | 谈谈 caffe 的 bn 和 scale 算子:https://blog.csdn.net/weixin_42405819/article/details/120418688
- 极智AI | 谈谈 caffe 的 conv 算子:https://blog.csdn.net/weixin_42405819/article/details/120618607
- 极智AI | caffe proto 校验模型结构 prototxt 讲解:https://blog.csdn.net/weixin_42