OpenPrompt使用记录

一、Prompt提示学习
Prompt是继预训练-精调范式(Pre-train,Fine-tune) 后的第四范式。
- 🔥 Fine-tuning中:是预训练语言模型“迁就“各种下游任务。具体体现就是通过引入各种辅助任务loss,将其添加到预训练模型中,然后继续pre-training,以便让其更加适配下游任务。总之,这个过程中,预训练语言模型做出了更多的牺牲。
- 🔥 Prompting中,是各种下游任务“迁就“预训练语言模型。我们需要对不同任务进行重构,使得它达到适配预训练语言模型的效果。总之,这个过程中,是下游任务做出了更多的牺牲。
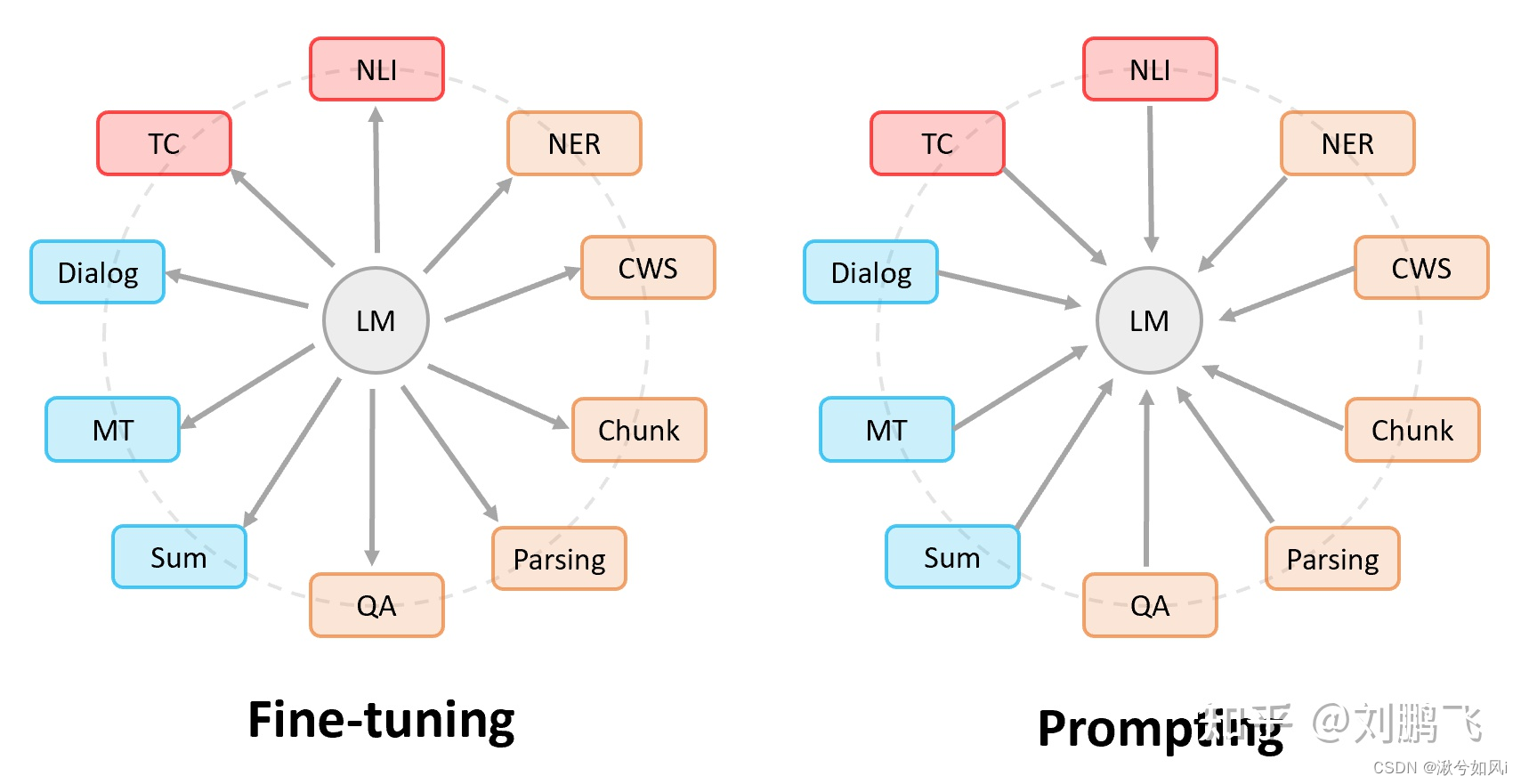
以BERT为例(可以将BERT理解为一名“完形填空满分选手”),我们可以把许多下游任务改造成它擅长的形式。
例1:
任务输入:这个餐厅的服务真不错
任务输出:任务标签{正向,负向}
改造:
Prompt任务输入:____满意,这个餐厅的服务真不错
Prompt任务输出:任务标签{正向,负向}
我们可以通过限制BERT的输出为 “很”或“不” 这两个词,“很”满意对应正向情感;“不”满意对应负向情感。多分类任务、匹配任务等如上。
Prompt最大的优点:少/零样本,因为Prompt的思想是重构下游任务来适配预训练语言模型,不需要对预训练语言模型进行任何fine-tune。 但在有条件的情况下,也可以即重构下游任务,又对预处理模型进行fine-tune,尝试是否能获得更好的效果。
二、OpenPrompt安装
-
新建一个虚拟环境
conda create -n OpenPrompt python=3.8 -
激活虚拟环境
conda activate OpenPrompt -
顺序执行以下命令
git clone https://github.com/thunlp/OpenPrompt.git cd OpenPrompt pip install -r requirements.txt python setup.py install -
上述步骤运行成功后,会在根目录下生成文件夹“OpenPrompt”,即整个项目结构。直接在此文件夹中创建一个新文件
samplt.py来测试是否安装成功。代码如下:# step1: import torch from openprompt.data_utils import InputExample classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive"negative","positive" ] dataset = [ # For simplicity, there's only two examples# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.InputExample(guid = 0,text_a = "Albert Einstein was one of the greatest intellects of his time.",),InputExample(guid = 1,text_a = "The film was badly made.",), ] # step 2 from openprompt.plms import load_plm plm, tokenizer, model_config, WrapperClass = load_plm("bert", "bert-base-cased") #step3 from openprompt.prompts import ManualTemplate promptTemplate = ManualTemplate(text = '{"placeholder":"text_a"} It was {"mask"}',tokenizer = tokenizer, ) #step4 from openprompt.prompts import ManualVerbalizer promptVerbalizer = ManualVerbalizer(classes = classes,label_words = {"negative": ["bad"],"positive": ["good", "wonderful", "great"],},tokenizer = tokenizer, ) #step 5 from openprompt import PromptForClassification promptModel = PromptForClassification(template = promptTemplate,plm = plm,verbalizer = promptVerbalizer, ) #step 6 from openprompt import PromptDataLoaderdata_loader = PromptDataLoader(dataset=dataset,tokenizer=tokenizer,template=promptTemplate,tokenizer_wrapper_class=WrapperClass, ) # step 7 # making zero-shot inference using pretrained MLM with prompt promptModel.eval() with torch.no_grad():for batch in data_loader:logits = promptModel(batch)preds = torch.argmax(logits, dim=-1)print(classes[preds]) # predictions would be 1, 0 for classes 'positive', 'negative' -
看报错,缺什么install什么,比较麻烦。。。(例如新环境torch还没安装等等)
三、代码实战
论文Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification源码尝试
- 安装OpenPrompt(如上已经安装)
- 下载数据集(即进入OpenPrompt项目结构datasets文件夹执行bash命令)
cd OpenPrompt/datasets bash download_text_classification.sh - 克隆源码
git clone git@github.com:thunlp/KnowledgeablePromptTuning.git - 运行scripts例如
bash scripts/run_fewshot.sh执行few-shot场景代码 - 上一步报错了?说明
run_fewshot.sh文件配置的不对。我这里需要修改三个地方,第一是将原来的模型路径改为了模型名字,因为我已经在.cache中预先缓存了roberta-large预训练模型。第二是将OpenPrompt项目结构路径改为本地正确的相对路径。第三是改服务器显卡的序号(源码为7,但实验室服务器只有四块显卡所以报错找不到CUDA)。
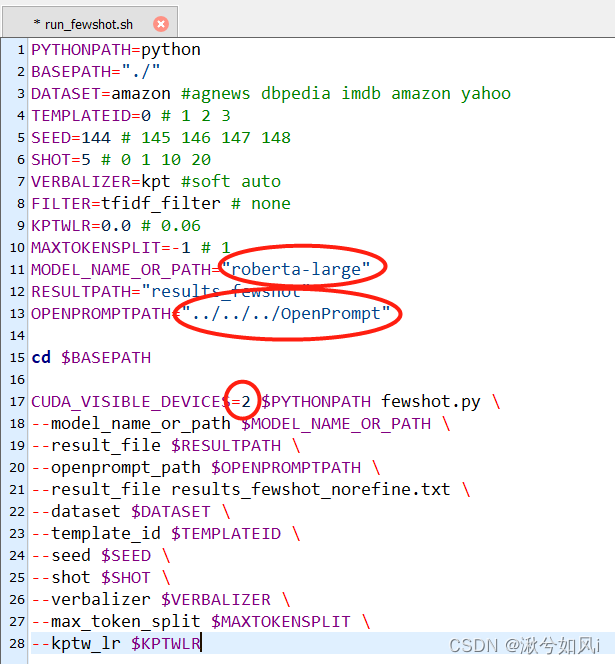
- 成功运行!但报错
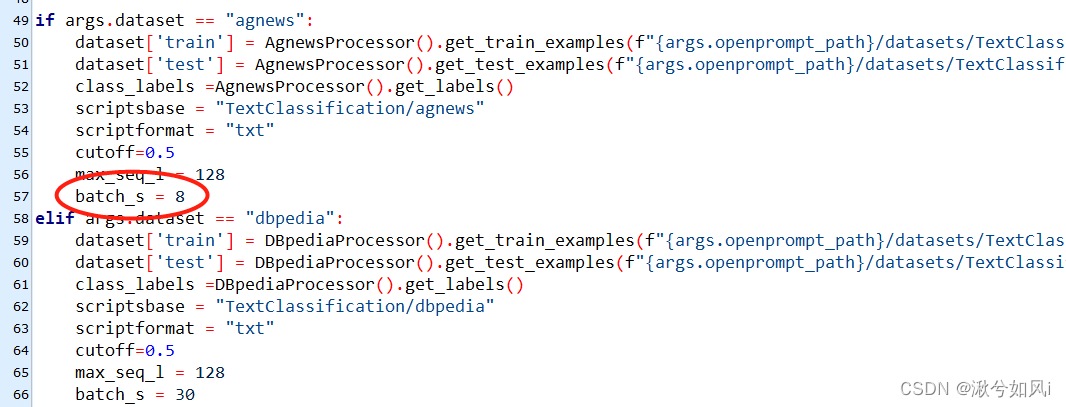
CUDA out of memory。。。估计是实验室显卡显存不够?一块显卡的显存只有10.75GB,可能还需要修改其他配置。失败!(已解决,把数据集的batch_size改小即可,默认为30)
- 还有个小报错,需要指定保存最佳模型参数的文件夹(源码中设置为ckpts文件夹),所以需要在项目路径下创建ckpts文件夹最终才能运行成功。
运行结果如图:
