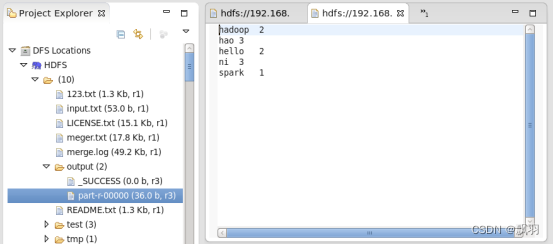
WordCount 在 MapReduce上运行详细步骤

注意:前提条件hadoop已经安装成功,并且正常启动。
1.准备好eclipse安装包,eclipse-jee-juno-linux-gtk-x86_64.tar.gz,使用SSH Secure File Transfer Client工具把安装包上传于Hadoop集群的名称节点。
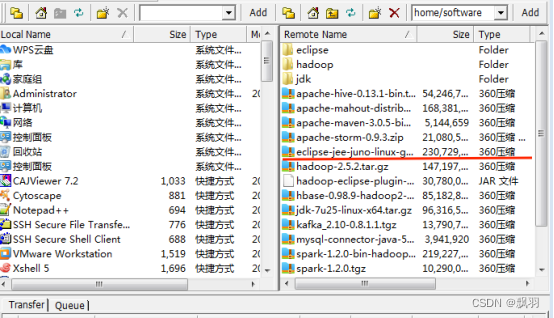
2.上传Hadoop在eclipse上运行插件:haoop-eclipse-plugin-2.6.0.jar
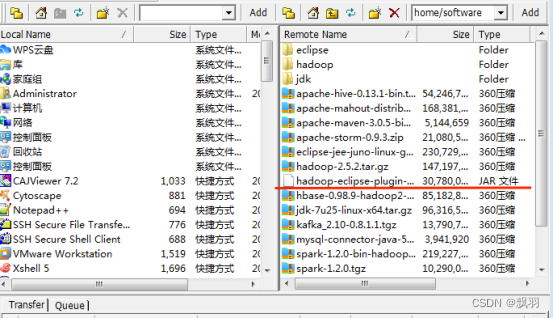
3.更改eclipse-jee-juno-linux-gtk-x86_64.tar.gz权限
![]()
4.解压缩eclipse
![]()
解压后会出现eclipse文件夹,

![]()
并且进行查看是否拷贝成功:
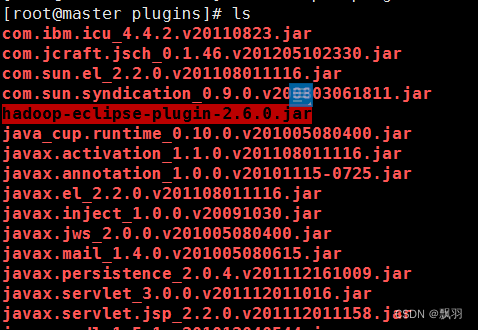
6.切换到eclipse安装目录,并且打开eclipse(启动eclipse需要在虚拟机中启动)

出现以下界面表示启动成功:

7.配置eclipse插件
点击导航栏window-->show View-->other,选中MapReduce Tools中的Map/Reduce Locations,并点击“ok”按钮。
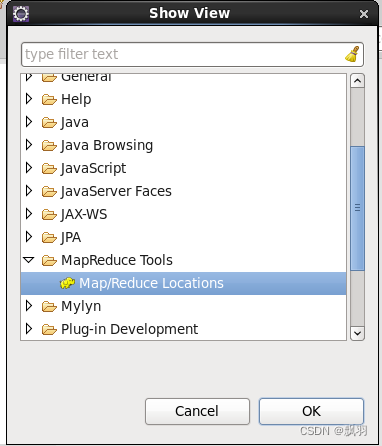
8.eclipse下面会出现Map/Reduce Locations窗口,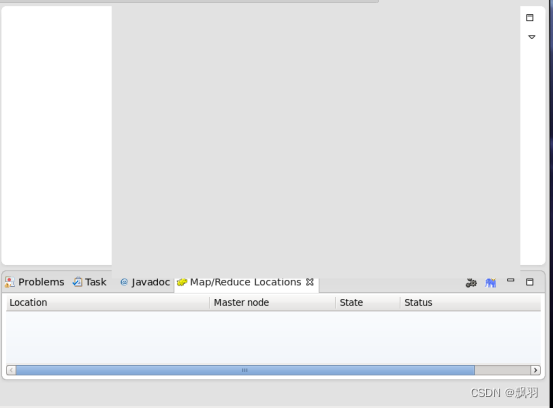
9.创建HDFS本地连接。
在Map/Reduce Locations窗口的空白处右键,

选择New Hadoop location,会弹出对话框;

填写配置信息:

点击finish,后在eclipse界面左上角就会出现HDFS本地连接,以及可以看到HDFS上的文件结构目录。
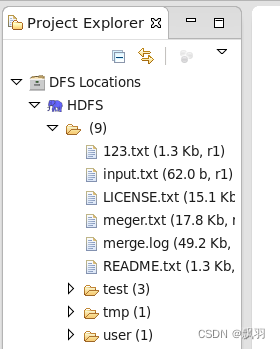
10.创建Hadoop项目,
在eclipse中点击File--->new--->other,会弹出对话框:
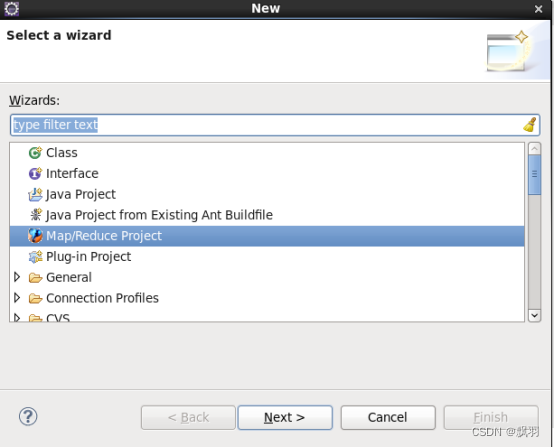
然后找到,Map/Reduce文件夹,然后选择Map/Reduce Project。
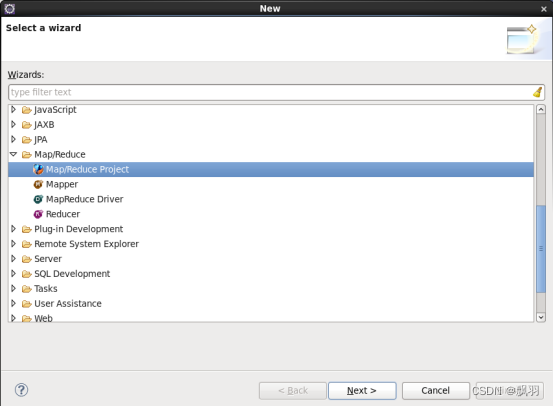
点击下一步,然后输入WordCount,并点击完成。
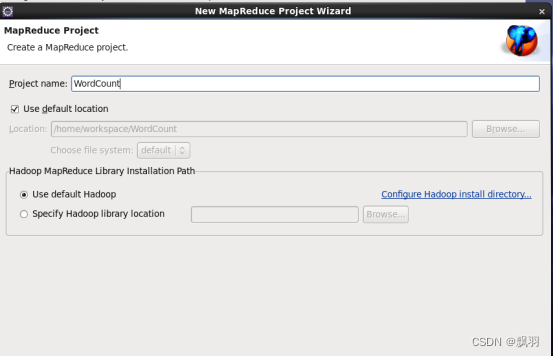
在eclipse工程列表中会出现WordCount项目,
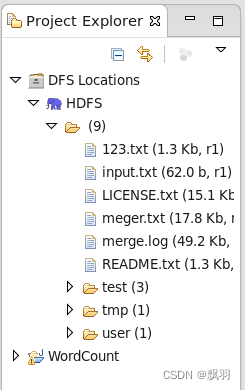
创建类,
打开WordCount目录,右键点击src文件夹,选择new--->Class
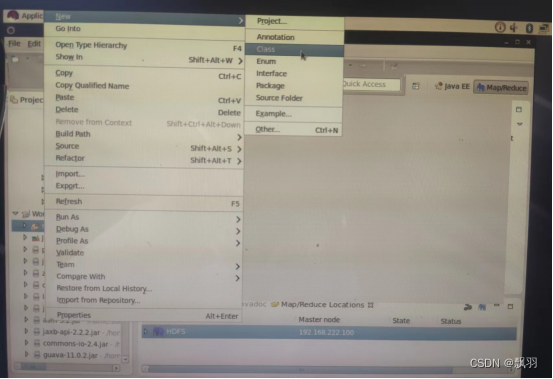
填写类名:WordCount,点击finish。

工程目录下会出现WordCount的java文件。
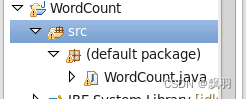
双击WordCount.java文件,把代码拷贝进去。
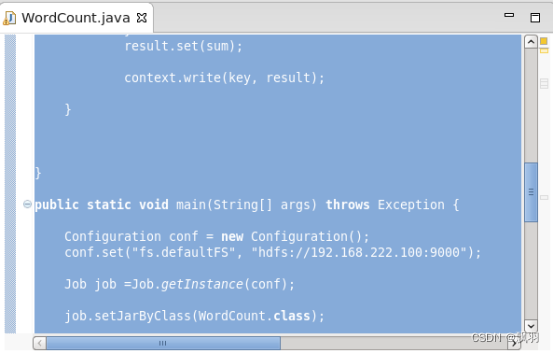
import java.io.IOException;
public class WordCount {
public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String line=value.toString();
String [] words=line.split(" ");
for(String w:words){
context.write(new Text(w), new IntWritable(1));
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.222.100:9000");
Job job =Job.getInstance(conf);
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("/input.txt"));
Path output=new Path("/output");
FileSystem fs=FileSystem.get(conf);
if(fs.exists(output)){
fs.delete(output,true);
}
FileOutputFormat.setOutputPath(job, output);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
创建数据文件,

在文件中输入内容并保存退出:
# vi input.txt

上传数据文件
![]()
刷新目录会发现文件上传成功:
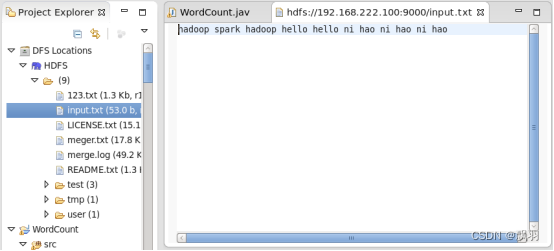
运行程序:右键程序Run as--->Run on Hadoop,运行完毕后,刷新目录如下图,