初识机器学习

-
监督学习与无监督学习
supervised learning:监督学习,给出的训练集中有输入也有输出(标签)(也可以说既有特征又有目标),在此基础上让计算机进行学习。学习后通过测试集测试给相应的事物打上标签。
unsupervised learning:无监督学习,给出的训练集中只有特征没有目标(无标签)。不告诉计算机怎么做,而是让计算机学着自己去学习怎样做。只给定一组数据而没有数据的标签,让计算机自己来对数据进行学习从而达到聚类的效果。
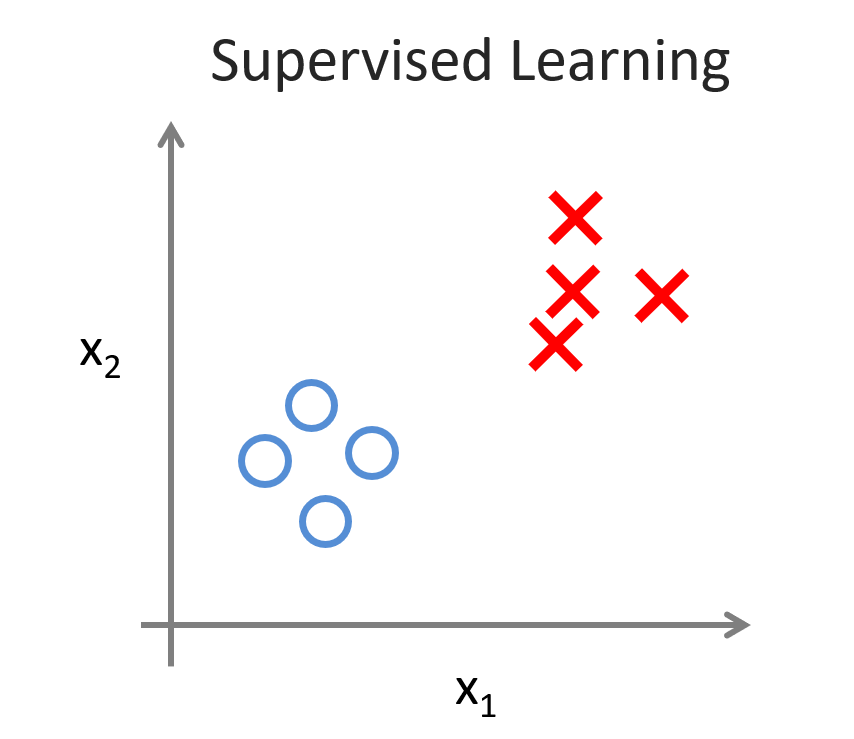
o和x是打上的标签,通过不同的类型对新数据进行分类
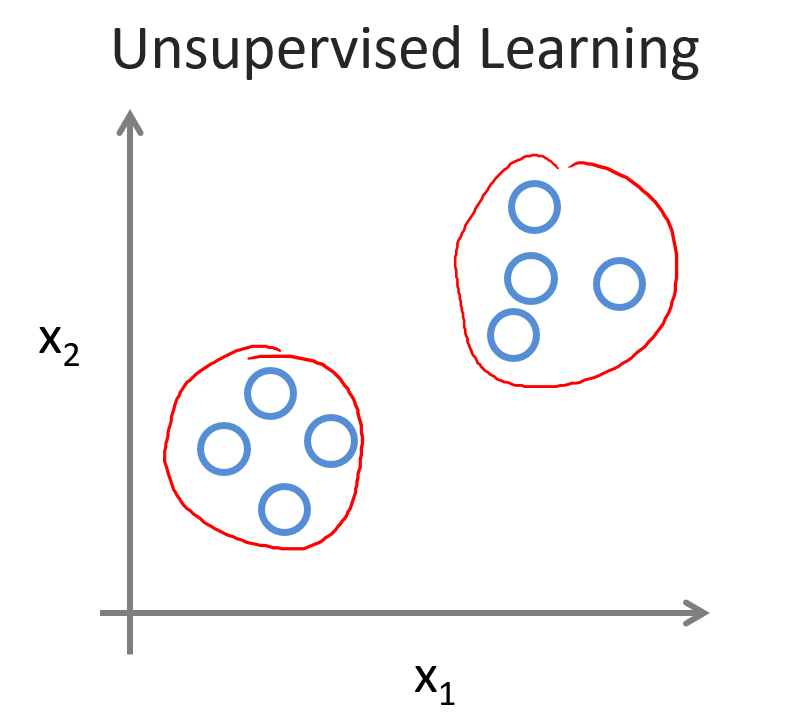
对于原始数据并没有贴上标签,而是让计算机通过自己学习数据特征(此例为相互距离)来进行区分,做到物以类聚
-
监督学习与无监督学习的主要类别
2.1 监督学习
分为分类问题(classification)和回归问题(regression)两大类。
分类:通过对训练集进行学习来对测试集进行分类,其结果是离散的。(yes or no,1 or 0,以及3种及三种以上类别)。如识别邮件是否是垃圾邮件
回归:通过对训练集进行学习来对测试集进行预测,其结果是连续的。如拟合房价与面积的关系,预测该面积的房子能卖多少钱。
2.2 无监督学习
分为聚类问题和降维问题两大类。
聚类:简单说就是一种自动分类的方法,在监督学习中,你很清楚每一个分类是什么,但是聚类则不是,你并不清楚聚类后的几个分类每个代表什么意思。计算机只是根据学习到的特征,将特征相似的分为一类。
降维:降维看上去很像压缩。这是为了在尽可能保存相关的结构的同时降低数据的复杂度。