【工具】Js敏感信息扫描器

文章目录
- 前言
- 一、JsScan扫描器介绍
- 二、使用步骤及后期优化
-
- 1.源码:
- 2.依赖安装
- 3. 使用
- 注意事项
- 后期优化
- 总结
前言
在做JS漏洞挖掘的时候,发现很多工具不是太好用,在信息收集的时间花费很多,自己就像写一个JS信息收集的工具,使用python开发了一个简单的收集工具,其中仿照JSFinder工具的功能,做了信息针对性优化,先做了一个测试版的工具,此工具带有GUI的界面,欢迎交流。
一、JsScan扫描器介绍
在开发时采用tkinter开发的GUI界面,可以探测网站上的 JavaScript 文件,并检查它们是否包含敏感信息。该应用程序使用 requests、threading、tkinter、BeautifulSoup 和 selenium 等库实现。
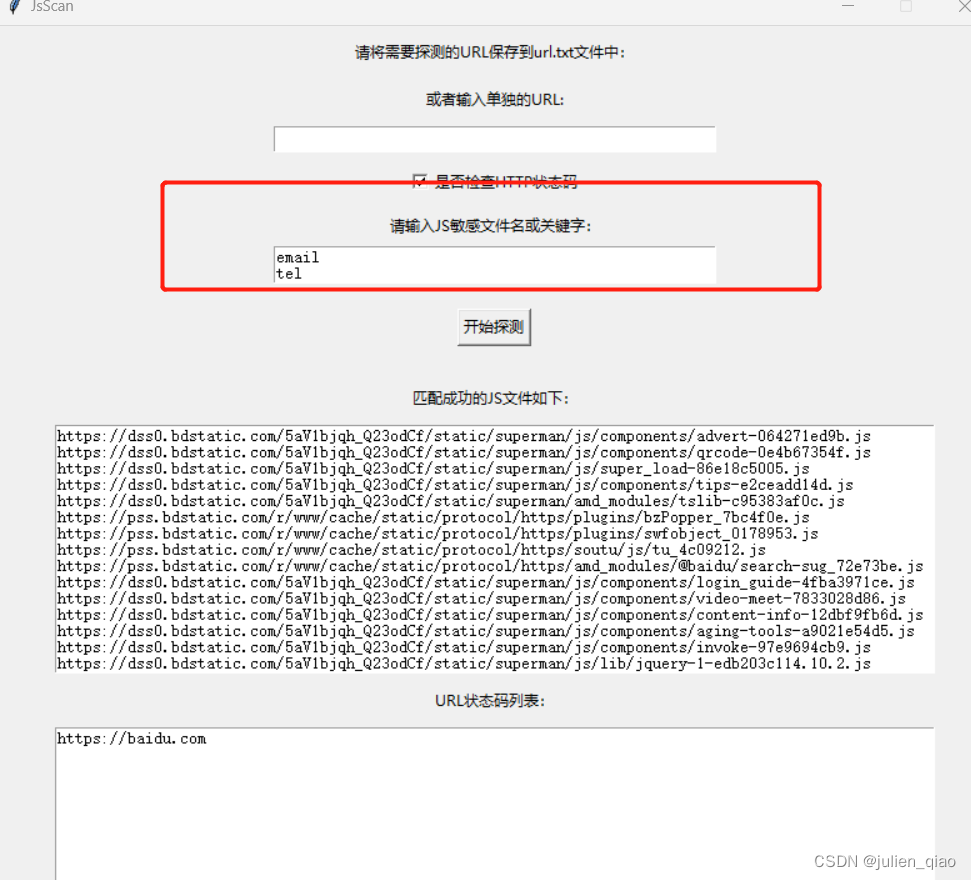
1.用户可以将需要探测的 URL 保存到 url.txt 文件中,也可以在应用程序中输入单独的 URL。
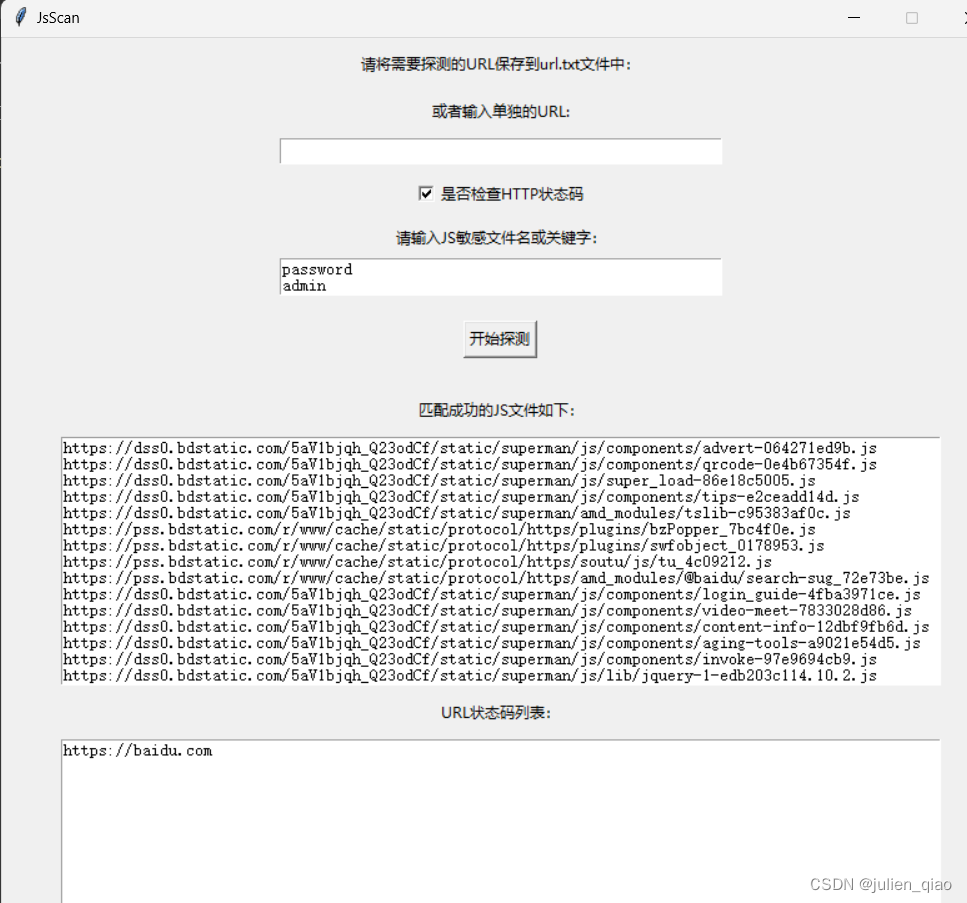
2.用户可以选择是否检查 HTTP 状态码。
3.用户可以输入 JS 敏感文件名或关键字。程序将搜索 JavaScript 文件并匹配用户输入中指定的敏感信息。
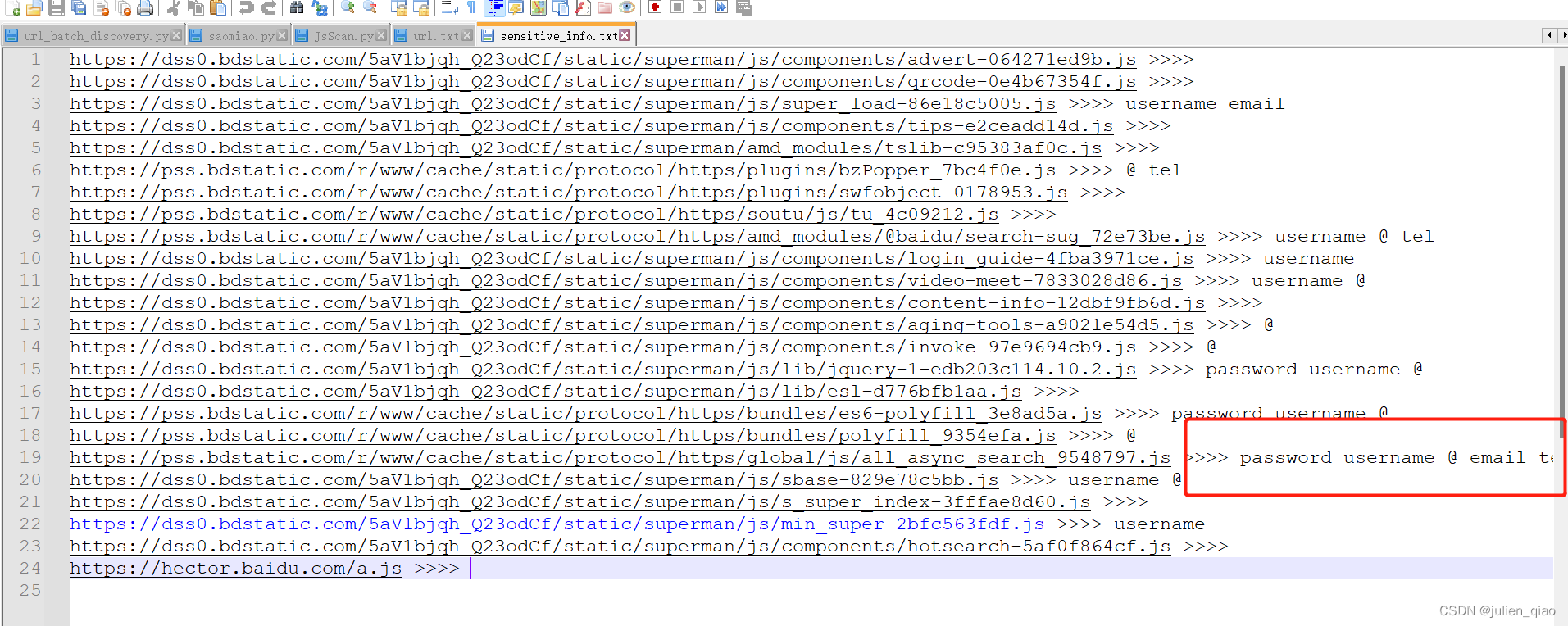
4.程序将输出匹配成功的 JS 文件列表、状态码列表和敏感信息列表,并将它们分别保存到 js_result.txt、url_result.txt 和 sensitive_info.txt 文件中。
二、使用步骤及后期优化
1.源码:
代码如下:
import requests
import threading
import tkinter as tk
from bs4 import BeautifulSoup
from selenium import webdriver
import reclass Application(tk.Tk):def __init__(self):super().__init__()self.title("JsScan")self.geometry("800x700")self.resizable(False, False)self.url_label = tk.Label(self, text="请将需要探测的URL保存到url.txt文件中:")self.url_label.pack(pady=10)self.url_entry_label = tk.Label(self, text="或者输入单独的URL:")self.url_entry_label.pack(pady=5)self.url_entry = tk.Entry(self, width=50)self.url_entry.pack(pady=5)self.check_status_var = tk.BooleanVar()self.check_status_var.set(False)self.check_status_cb = tk.Checkbutton(self, text="是否检查HTTP状态码", variable=self.check_status_var)self.check_status_cb.pack(pady=5)self.js_sensitive_label = tk.Label(self, text="请输入JS敏感文件名或关键字:")self.js_sensitive_label.pack(pady=5)self.js_sensitive_text = tk.Text(self, width=50, height=2)self.js_sensitive_text.pack()# 默认给出一些JS敏感信息匹配示例self.js_sensitive_text.insert(tk.END, "password\\nadmin\\n测试账户\\n测试\\nusername\\n@\\nemail\\ntel")self.start_button = tk.Button(self, text="开始探测", command=self.start_check)self.start_button.pack(pady=20)self.js_result_label = tk.Label(self, text="匹配成功的JS文件如下:")self.js_result_label.pack(pady=10)self.js_result_text = tk.Text(self, width=100, height=15)self.js_result_text.pack()self.url_result_label = tk.Label(self, text="URL状态码列表:")self.url_result_label.pack(pady=10)self.url_result_text = tk.Text(self, width=100, height=15)self.url_result_text.pack()self.sensitive_info_label = tk.Label(self, text="敏感信息列表:")self.sensitive_info_label.pack(pady=10)self.sensitive_info_text = tk.Text(self, width=100, height=15)self.sensitive_info_text.pack()self.clear_button = tk.Button(self, text="清空敏感信息", command=self.clear_sensitive_info)self.clear_button.pack(pady=10)def start_check(self):urls = []if self.url_entry.get().strip():urls.append(self.url_entry.get())try:with open("url.txt", "r") as f:urls += [line.strip() for line in f.readlines()]for url in urls:if not url.startswith("http://") and not url.startswith("https://"):message = f"{url.strip()} URL必须以http或https开头!\\n"self.js_result_text.insert(tk.END, message)self.url_result_text.insert(tk.END, message)continuet = threading.Thread(target=self.check_url, args=(url.strip(),))t.start()except Exception as e:message = f"读取文件失败,{e}\\n"self.js_result_text.insert(tk.END, message)self.url_result_text.insert(tk.END, message)def check_url(self, url):try:options = webdriver.ChromeOptions()options.add_argument('--headless') # 隐藏Chrome浏览器窗口driver = webdriver.Chrome(options=options)driver.get(url)js_urls = self.get_js_urls(driver.page_source)js_results = []sensitive_info = []js_sensitive = [line.strip() for line in self.js_sensitive_text.get(1.0, tk.END).split('\\n')]for js_url in js_urls:response = requests.get(js_url, timeout=5)if response.status_code == 200:js_content = str(response.content)matched_keywords = [word for word in js_sensitive if re.search(word, js_content)]if matched_keywords:matched_str = "{} >>>>".format(js_url)for keyword in matched_keywords:matched_str += " {}".format(keyword)sensitive_info.append(matched_str)js_results.append(js_url)message = f"{js_url}\\n"self.js_result_text.insert(tk.END, message)else:message = f"{js_url} 探测失败,状态码为 {response.status_code}\\n"self.js_result_text.insert(tk.END, message)if self.check_status_var.get():response = requests.get(url, timeout=5)status_code = response.status_codeif status_code == 200:message = f"{url}\\n"self.url_result_text.insert(tk.END, message)else:message = f"{url} 探测失败,状态码为 {status_code}\\n"self.url_result_text.insert(tk.END, message)js_result_file = "js_result.txt"with open(js_result_file, "w") as f:f.write("")with open(js_result_file, "a", encoding="utf-8") as f:for js_url in js_results:f.write(js_url + "\\n")if self.check_status_var.get():url_result_file = "url_result.txt"with open(url_result_file, "w") as f:f.write("")with open(url_result_file, "a", encoding="utf-8") as f:if status_code == 200:f.write(url + "\\n")sensitive_info_file = "sensitive_info.txt"with open(sensitive_info_file, "a", encoding="utf-8") as f:for info in sensitive_info:f.write(info + "\\n")if sensitive_info:message = "\\n".join(sensitive_info) + "\\n"self.sensitive_info_text.insert(tk.END, message)except Exception as e:message = f"{url} 探测失败,{e}\\n"self.js_result_text.insert(tk.END, message)self.url_result_text.insert(tk.END, message)finally:driver.quit()def get_js_urls(self, html):soup = BeautifulSoup(html, "html.parser")js_urls = []for script in soup.find_all("script"):src = script.get("src")if src and src.startswith("http"):js_urls.append(src)return js_urlsdef clear_sensitive_info(self):# 清空敏感信息并提示sensitive_info_file = "sensitive_info.txt"with open(sensitive_info_file, "w") as f:f.write("")message = "已清空敏感信息列表!\\n"self.sensitive_info_text.delete(1.0, tk.END)self.sensitive_info_text.insert(tk.END, message)if __name__ == "__main__":app = Application()app.mainloop()2.依赖安装
pip install requests
pip install beautifulsoup4
pip install selenium
3. 使用
将需要扫描的URL放入url.txt文件内
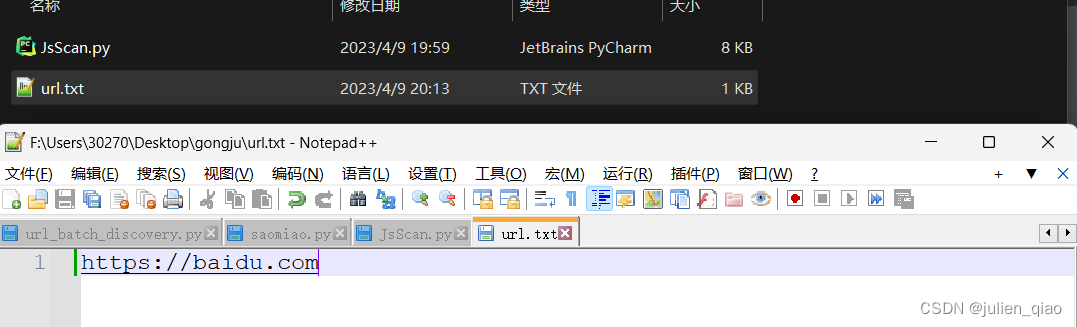
启动:python JsScan.py
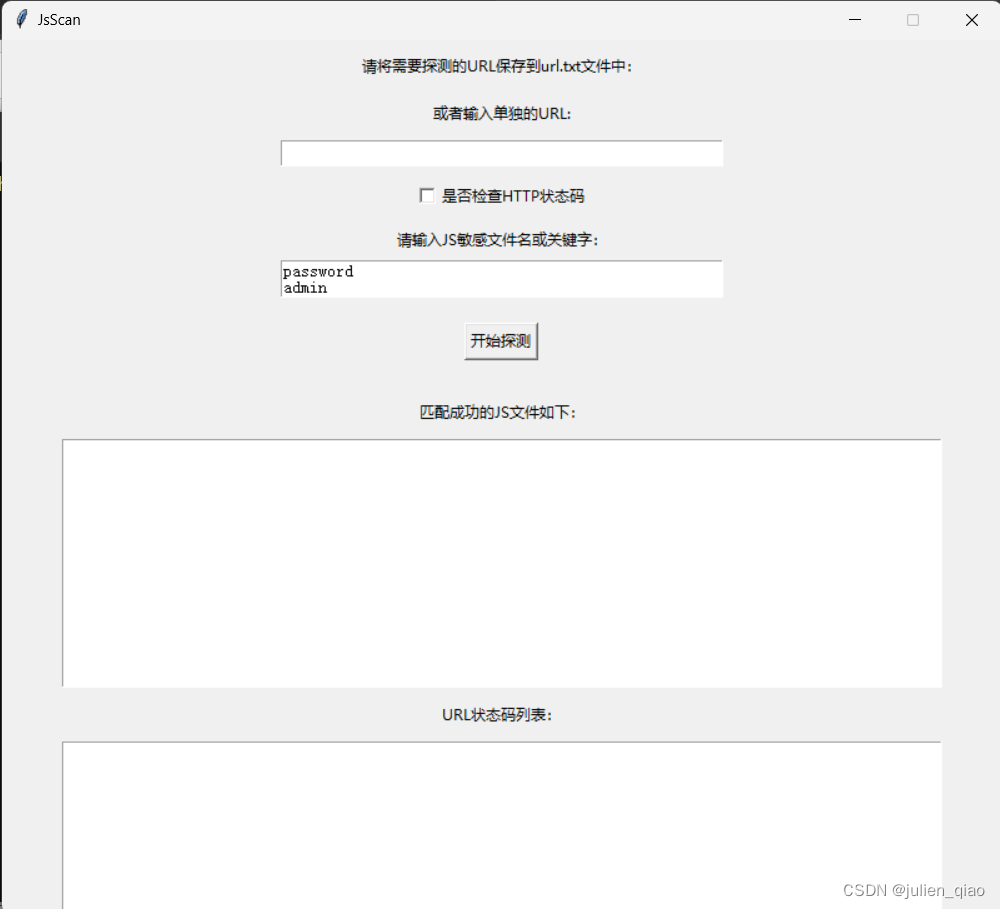
启动
文件夹会生成一下文件:
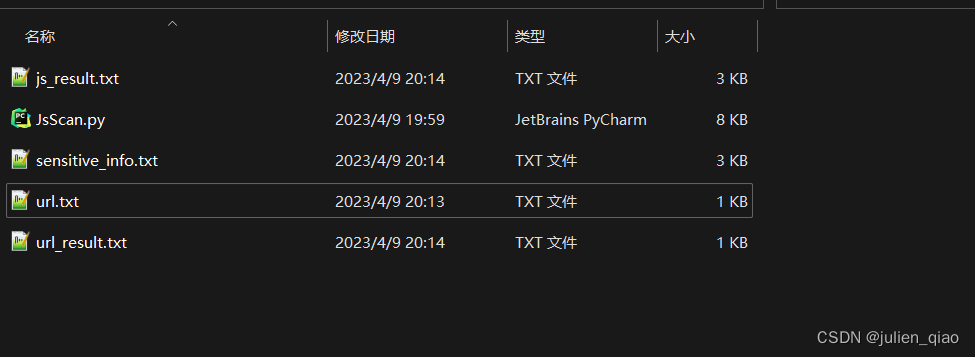
js_result.txt #JS URL路径
sensitive_info.txt 敏感信息关键字匹配的js url
url_result.txt #存放访问成功的url
注意事项
敏感信息关键字可以自定义,默认只有几个可以自己添加,以上工具不可用于恶意破坏,产生一切后果与我无关。
后期优化
后期可能添加代理池和高并发,现在效率比较低可以自己修改,此工具开源。
总结
开发了几天,虽然写的一般,但是对我来说实现的效果还是不错。