90、Neural Residual Radiance Fields for Streamably Free-Viewpoint Videos

简介
主页:https://aoliao12138.github.io/ReRF/
前提知识:DeVRF:https://jia-wei-liu.github.io/DeVRF/
先利用多台固定相机拍摄动态场景,在第一帧利用DVGO重建好半显示场景,后续则是通过预测体素x,y,z三个方向的运动来进行体素移动,从而得到一个快速渲染的动态NeRF

显式地对时空特征空间中相邻时间戳之间的剩余信息建模,使用基于全局坐标的微型MLP作为特征解码器,采用了一个紧凑的运动网格和一个剩余特征网格来利用帧间的特征相似性,不牺牲质量的情况下处理大型运动,序列训练方案,以保持运动/残差网格的平滑性和稀疏性。提出一个特殊的FVV编解码器,实现了三个数量级的压缩率,并提供了一个配套的ReRF播放器来支持长时间动态场景FVV的在线流媒体
实现流程
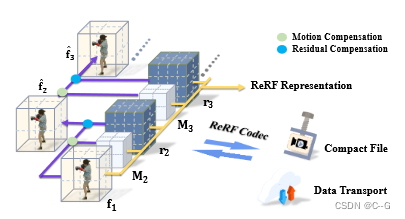
第一帧训练好一个初始半显示场景 f1f_1f1
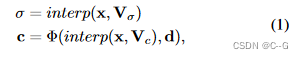
再用 f1f_1f1 和 第二帧的图像训练紧凑的运动网格 M2M_2M2 和一个剩余特征网格 r2r_2r2,从而得到当前场景体素表示 f2f_2f2。(下面公式用 ftf_tft表示当前场景,ft−1f_{t-1}ft−1表示上一场景 )

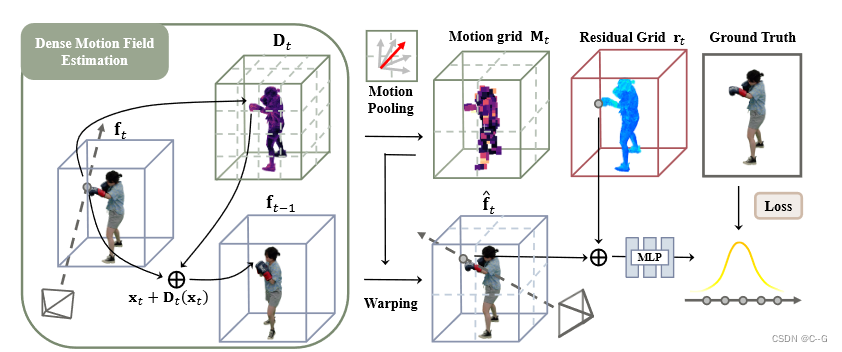
为当前 帧t 引入一个紧凑运动网格 MtM_tMt 和一个剩余特征网格 rtr_trt。低分辨率运动网格 MtM_tMt 表示体素偏移,以表示当前帧中的体素在上一帧中对应的体素索引。剩余网格 rtr_trt 表示对当前帧中相邻扭曲误差和新观测区域的稀疏补偿,对于第一帧,采用完整的显式特征网格表示 f1f_1f1 和全局 MLP Φ。ReRF用公式表示为 Φ ,f1f_1f1,{Mt,rt}t=1N\\{M_t,r_t\\}^N_{t=1}{Mt,rt}t=1N
将 MtM_tMt 应用于 ft−1f_{t−1}ft−1 来提取帧间冗余,并获得当前帧的基本特征网格 ftf_tft
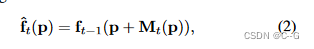
添加残差补偿来恢复整个特征网格: ft=f^t+rtf_t = \\hat{f}_t + r_tft=f^t+rt
Motion Grid Estimation
两阶段和顺序的训练方案,以从长时间RGB视频输入中获得包括 Φ, f1f_1f1和{Mt,rt}t=1N\\{M_t, r_t\\}^N_{t=1}{Mt,rt}t=1N 的ReRF表示,这加强了剩余网格和运动网格的紧凑性
和DeVRF一样,获得第一帧的完整显式特征网格 f1f_1f1,并使用全局MLP Φ 作为特征解码器,给定前一帧的特征网格 ft−1f_{t−1}ft−1和当前帧的输入图像,生成运动网格 MtM_tMt 和残差网格 rtr_trt
遵循DEVRF到一个密集运动场 DtD_tDt
引入了一个运动池化策略,体素 ptp_tpt 中的运动向量可以指向前一帧中的不同体素 pt−1p_{t−1}pt−1,这类似于标准的平均池化操作
首先将 DtD_tDt 分割为立方体,其中每个立方体包含连续的8 × 8 × 8体素,对于每个立方体,在8 × 8 × 8的核上对 DtD_tDt 应用平均池化,以确保每个立方体共享相同的运动向量,对其进行采样以生成低分辨率的运动网格 MtM_tMt,大小比原始的密集网格小512倍
可以通过运动场跟踪前一帧的一些特征立方体,从而进一步降低剩余体素的熵,生成一个低分辨率 MtM_tMt,紧凑地表示跨帧的平滑运动
Residual Grid Optimization
将之前的特征网格 ft−1f_{t−1}ft−1 扭曲为当前的基网格 ftf_tft,粗略地补偿了帧间运动引起的特征差异
优化残差网格的过程中,固定 ftf_tft 和 Φ,并将梯度反向传播到残差网格 rtr_trt,以仅更新 rtr_trt
使用L1损失来正则化 rtr_trt,以增强其稀疏性以提高紧凑性,强制 rtr_trt 仅补偿帧间残差或新观测区域的稀疏信息
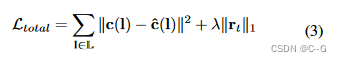
其中λ=0.01\\lambda=0.01λ=0.01
得到 Mt,rtM_t,r_tMt,rt,利用公式2,恢复当前帧的显式特征网格 ftf_tft,然后进行下一帧的连续训练
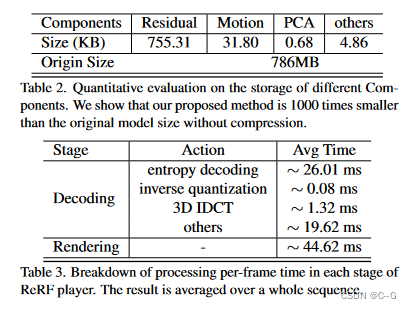
MtM_tMt 和 rtr_trt 的设计和生成机制使它们压缩友好,因为它们的紧凑表示和稀疏属性,支持以下ReRF编解码器和流
Feature-level Residual Compression.
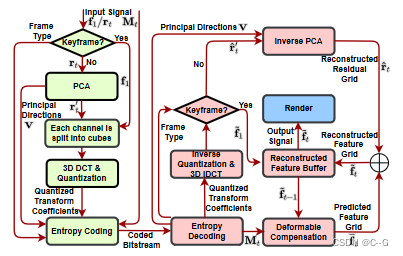
基于ReRF的编解码器和配套的FVV播放器,用于长时间动态场景的在线流媒体
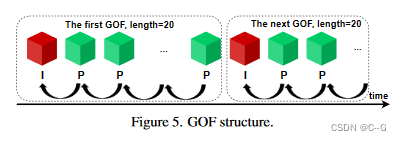
将特征网格序列划分为几组连续的特征网格(GOF), GOF是一个连续网格的集合
GOF 由 I-feature 网格 (关键帧)和 P-feature 网格组成,每个GOF都从一个独立于所有其他特征网格编码的 I-feature 网格开始,P-feature网格 包含一个相对于前一个特征网格的可变形补偿残差网格
GOF 表示为 {f1,r2,⋯,rt−1,rt,⋯}\\{f_1,r_2,\\cdots,r_{t-1},r_t,\\cdots\\}{f1,r2,⋯,rt−1,rt,⋯},f1f_1f1 是 feature网格,rtr_trt 是residual网格
首先将 f1f_1f1 和 rtr_trt 重塑为 f1(m,n)f_1(m, n)f1(m,n) 和 rt(m,n)r_t(m, n)rt(m,n),一个 m × n的特征矩阵,其中m和n分别为非空特征体素和特征通道的数量。然后,对 rt(m,n)r_t(m, n)rt(m,n) 进行线性主成分分析(PCA),得到主方向 v。最后,通过 rt′=rt⋅Vr'_t = r_t·Vrt′=rt⋅V 将 rtr_trt 投影到主方向上,将网格 f1f_1f1 和 rt′r'_trt′ 的每个通道分割成8 × 8 × 8体素的立方体,并使用三维DCT对每个立方体分别进行变换。然后,利用量化矩阵对变换系数进行量化。
对量化后的变换系数进行熵编码,并与运动场 MtM_tMt、帧类型等辅助信息一起传输。具体来说,使用差分脉冲编码调制(DPCM)方法对直流系数进行编码。
AC系数编码涉及以“3D之字形”顺序排列量化的DCT系数,采用运行长度编码(RLE)算法将相似频率分组在一起,插入长度编码零。最后,使用Huffman编码进一步压缩 DPCM-code DC 系数和 RLE-coded AC 系数。压缩方法的一个优点是能够通过调整量化参数来实现可变比特率,从而根据可用带宽实现动态自适应的ReRF流。
Network Streaming ReRF Player
实现了一个伴ReRF播放器,用于长序列的在线流动态辐射场,具有广泛的控制功能。接收到比特流后,首先对量化后的变换系数进行逆量化和反变换,重构 I-feature 网格 fˉ1\\bar{f}_1fˉ1。
I-feature网格重构完成后,将对随后接收到的 p-feature 网格进行重构。对量化后的变换系数进行逆量化和逆变换,生成初始重构残差网格。然后,r^‘t\\hat{r}`_tr^‘t向后投影到原点空间 r^t=r^t′⋅VT\\hat{r}_t = \\hat{r}'_t \\cdot V^Tr^t=r^t′⋅VT。另外,已知解码后的运动场 MtM_tMt 和之前重构的特征网格 fˉt−1\\bar{f}_{t-1}fˉt−1,可以通过变形得到预测的特征网格 fˉt\\bar{f}_tfˉt。最后,加入f t和rt,得到最终重构的特征网格 fˉt\\bar{f}_tfˉt。fˉt\\bar{f}_tfˉt输出到渲染器,生成动态场景的照片逼真的FVV。
受益于GOF结构的设计,ReRF播放器允许快速寻找到一个新的位置播放播放期间。因为在压缩比特流中遇到一个新的GOF意味着解码器可以解码一个压缩的特征网格,而不需要重建任何先前的特征网格。通过ReRF播放器,用户首次可以像观看2D视频一样,暂停、播放、快进/后退、寻找动态亮度场,带来前所未有的高品质自由视点观看体验。
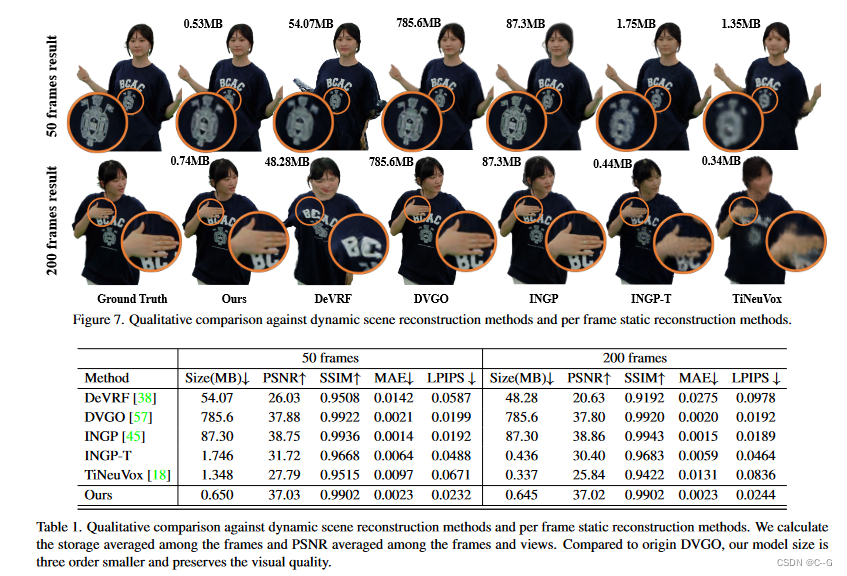
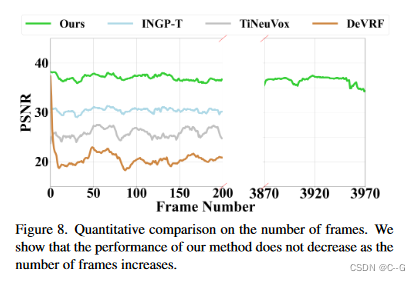
实验
动态数据集包含大约74个视图,分辨率为1920×1080,帧率为25帧