NumPy 初学者指南中文第三版:6~10

原文:NumPy: Beginner’s Guide - Third Edition
协议:CC BY-NC-SA 4.0
译者:飞龙
六、深入探索 NumPy 模块
NumPy 具有许多从其前身 Numeric 继承的模块。 其中一些包具有 SciPy 对应版本,可能具有更完整的功能。 我们将在下一章中讨论 SciPy。
在本章中,我们将介绍以下主题:
linalg包fft包- 随机数
- 连续和离散分布
线性代数
线性代数是数学的重要分支。 numpy.linalg包包含线性代数函数。 使用此模块,您可以求矩阵求逆,计算特征值,求解线性方程式和确定行列式等。
实战时间 – 转换矩阵
线性代数中矩阵A的逆是矩阵A^(-1),当与原始矩阵相乘时,它等于单位矩阵I。 可以这样写:
A A^(-1) = I
numpy.linalg包中的inv()函数可以通过以下步骤反转示例矩阵:
-
使用前面章节中使用的
mat()函数创建示例矩阵:A = np.mat("0 1 2;1 0 3;4 -3 8") print("A\\n", A)A矩阵如下所示:A [[ 0 1 2][ 1 0 3][ 4 -3 8]] -
用
inv()函数将矩阵求逆:inverse = np.linalg.inv(A) print("inverse of A\\n", inverse)逆矩阵如下所示:
inverse of A [[-4.5 7\\. -1.5][-2\\. 4\\. -1\\. ][ 1.5 -2\\. 0.5]]提示
如果矩阵是奇异的,或者不是正方形,则引发
LinAlgError。 如果需要,可以用笔和纸手动检查结果。 这留给读者练习。 -
通过将原始矩阵乘以
inv()函数的结果来检查结果:print("Check\\n", A * inverse)结果是单位矩阵,如预期的那样:
Check [[ 1\\. 0\\. 0.][ 0\\. 1\\. 0.][ 0\\. 0\\. 1.]]
刚刚发生了什么?
我们用numpy.linalg包的inv()函数计算了矩阵的逆。 我们使用矩阵乘法检查了这是否确实是逆矩阵(请参见inversion.py):
from __future__ import print_function
import numpy as npA = np.mat("0 1 2;1 0 3;4 -3 8")
print("A\\n", A)inverse = np.linalg.inv(A)
print("inverse of A\\n", inverse)print("Check\\n", A * inverse)
小测验 - 创建矩阵
Q1. 哪个函数可以创建矩阵?
arraycreate_matrixmatvector
勇往直前 – 反转自己的矩阵
创建自己的矩阵并将其求逆。 逆仅针对方阵定义。 矩阵必须是正方形且可逆; 否则,将引发LinAlgError异常。
求解线性系统
矩阵以线性方式将向量转换为另一个向量。 该变换在数学上对应于线性方程组。 numpy.linalg函数solve()求解形式为Ax = b的线性方程组,其中A是矩阵,b可以是一维或二维数组,而x是未知数变量。 我们将看到dot()函数的使用。 此函数返回两个浮点数组的点积。
dot()函数计算点积。 对于矩阵A和向量b,点积等于以下总和:
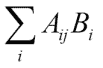
实战时间 – 解决线性系统
通过以下步骤解决线性系统的示例:
-
创建
A和b:A = np.mat("1 -2 1;0 2 -8;-4 5 9") print("A\\n", A) b = np.array([0, 8, -9]) print("b\\n", b)A和b出现如下:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P5lbDNFw-1681311708257)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_06_07.jpg)]
-
用
solve()函数求解线性系统:x = np.linalg.solve(A, b) print("Solution", x)线性系统的解如下:
Solution [ 29\\. 16\\. 3.] -
使用
dot()函数检查解决方案是否正确:print("Check\\n", np.dot(A , x))结果是预期的:
Check [[ 0\\. 8\\. -9.]]
刚刚发生了什么?
我们使用 NumPy linalg模块的solve()函数求解了线性系统,并使用dot()函数检查了解。 请参考本书代码捆绑中的solution.py文件:
from __future__ import print_function
import numpy as npA = np.mat("1 -2 1;0 2 -8;-4 5 9")
print("A\\n", A)b = np.array([0, 8, -9])
print("b\\n", b)x = np.linalg.solve(A, b)
print("Solution", x)print("Check\\n", np.dot(A , x))
查找特征值和特征向量
特征值是方程Ax = ax的标量解,其中A是二维矩阵,x是一维向量。特征向量是对应于特征值的向量。 numpy.linalg包中的eigvals()函数计算特征值。 eig()函数返回包含特征值和特征向量的元组。
实战时间 – 确定特征值和特征向量
让我们计算矩阵的特征值:
-
创建一个矩阵,如下所示:
A = np.mat("3 -2;1 0") print("A\\n", A)我们创建的矩阵如下所示:
A [[ 3 -2][ 1 0]] -
调用
eigvals()函数:print("Eigenvalues", np.linalg.eigvals(A))矩阵的特征值如下:
Eigenvalues [ 2\\. 1.] -
使用
eig()函数确定特征值和特征向量。 此函数返回一个元组,其中第一个元素包含特征值,第二个元素包含相应的特征向量,按列排列:eigenvalues, eigenvectors = np.linalg.eig(A) print("First tuple of eig", eigenvalues) print("Second tuple of eig\\n", eigenvectors)特征值和特征向量如下所示:
First tuple of eig [ 2\\. 1.] Second tuple of eig [[ 0.89442719 0.70710678][ 0.4472136 0.70710678]] -
通过计算特征值方程
Ax = ax的右侧和左侧,使用dot()函数检查结果:for i, eigenvalue in enumerate(eigenvalues):print("Left", np.dot(A, eigenvectors[:,i]))print("Right", eigenvalue * eigenvectors[:,i])print()输出如下:
Left [[ 1.78885438][ 0.89442719]] Right [[ 1.78885438][ 0.89442719]]
刚刚发生了什么?
我们发现了具有numpy.linalg模块的eigvals()和eig()函数的矩阵的特征值和特征向量。 我们使用dot()函数检查了结果(请参见eigenvalues.py):
from __future__ import print_function
import numpy as npA = np.mat("3 -2;1 0")
print("A\\n", A)print("Eigenvalues", np.linalg.eigvals(A) )eigenvalues, eigenvectors = np.linalg.eig(A)
print("First tuple of eig", eigenvalues)
print("Second tuple of eig\\n", eigenvectors)for i, eigenvalue in enumerate(eigenvalues):print("Left", np.dot(A, eigenvectors[:,i]))print("Right", eigenvalue * eigenvectors[:,i])print()
奇异值分解
奇异值分解(SVD)是一种分解因子,可以将矩阵分解为三个矩阵的乘积。 SVD 是先前讨论的特征值分解的概括。 SVD 对于像这样的伪逆算法非常有用,我们将在下一部分中进行讨论。 numpy.linalg包中的 svd()函数可以执行此分解。 此函数返回三个矩阵U,∑和V,使得U和V为一元且∑包含输入矩阵的奇异值:
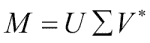
星号表示 Hermitian 共轭或共轭转置。复数的共轭改变复数虚部的符号,因此与实数无关。
注意
如果A*A = AA* = I(单位矩阵),则复方矩阵 A 是单位的。 我们可以将 SVD 解释为三个操作的序列-旋转,缩放和另一个旋转。
我们已经在本书中转置了矩阵。 转置翻转矩阵,将行变成列,然后将列变成行。
实战时间 – 分解矩阵
现在该使用以下步骤用 SVD 分解矩阵:
-
首先,创建如下所示的矩阵:
A = np.mat("4 11 14;8 7 -2") print("A\\n", A)我们创建的矩阵如下所示:
A [[ 4 11 14][ 8 7 -2]] -
用
svd()函数分解矩阵:U, Sigma, V = np.linalg.svd(A, full_matrices=False) print("U") print(U) print("Sigma") print(Sigma) print("V") print(V)由于
full_matrices=False规范,NumPy 执行了简化的 SVD 分解,计算速度更快。 结果是一个元组,在左侧和右侧分别包含两个单位矩阵U和V,以及中间矩阵的奇异值:U [[-0.9486833 -0.31622777][-0.31622777 0.9486833 ]] Sigma [ 18.97366596 9.48683298] V [[-0.33333333 -0.66666667 -0.66666667][ 0.66666667 0.33333333 -0.66666667]] -
实际上,我们没有中间矩阵,只有对角线值。 其他值均为 0。 用
diag()函数形成中间矩阵。 将三个矩阵相乘如下:print("Product\\n", U * np.diag(Sigma) * V)这三个矩阵的乘积等于我们在第一步中创建的矩阵:
Product [[ 4\\. 11\\. 14.][ 8\\. 7\\. -2.]]
刚刚发生了什么?
我们分解矩阵,并通过矩阵乘法检查结果。 我们使用了 NumPy linalg模块中的svd()函数(请参见decomposition.py):
from __future__ import print_function
import numpy as npA = np.mat("4 11 14;8 7 -2")
print("A\\n", A)U, Sigma, V = np.linalg.svd(A, full_matrices=False)print("U")
print(U)print("Sigma")
print(Sigma)print("V")
print(V)print("Product\\n", U * np.diag(Sigma) * V)
伪逆
矩阵的 Moore-Penrose 伪逆的计算公式为numpy.linalg模块的pinv()函数。 使用 SVD 计算伪逆(请参见前面的示例)。 inv()函数仅接受方阵; pinv()函数确实没有的限制,因此被认为是反函数的推广。
实战时间 – 计算矩阵的伪逆
让我们计算矩阵的伪逆:
-
首先,创建一个矩阵:
A = np.mat("4 11 14;8 7 -2") print("A\\n", A)我们创建的矩阵如下所示:
A [[ 4 11 14][ 8 7 -2]] -
用
pinv()函数计算伪逆矩阵:pseudoinv = np.linalg.pinv(A) print("Pseudo inverse\\n", pseudoinv)伪逆结果如下:
Pseudo inverse [[-0.00555556 0.07222222][ 0.02222222 0.04444444][ 0.05555556 -0.05555556]] -
将原始和伪逆矩阵相乘:
print("Check", A * pseudoinv)我们得到的不是一个恒等矩阵,但是很接近它:
Check [[ 1.00000000e+00 0.00000000e+00][ 8.32667268e-17 1.00000000e+00]]
刚刚发生了什么?
我们使用numpy.linalg模块的pinv()函数计算了矩阵的伪逆。 通过矩阵乘法检查得出的矩阵大约是单位矩阵(请参见pseudoinversion.py):
from __future__ import print_function
import numpy as npA = np.mat("4 11 14;8 7 -2")
print("A\\n", A)pseudoinv = np.linalg.pinv(A)
print("Pseudo inverse\\n", pseudoinv)print("Check", A * pseudoinv)
行列式
行列式是与方阵相关的值。 在整个数学中都使用它; 有关更多详细信息,请参见这里。 对于n x n实值矩阵,行列式对应于矩阵变换后 n 维体积所经历的缩放。 行列式的正号表示体积保留它的方向(顺时针或逆时针),而负号表示方向相反。 numpy.linalg模块具有det()函数,该函数返回矩阵的行列式。
实战时间 – 计算矩阵的行列式
要计算矩阵的行列式 ,请按照下列步骤操作:
-
创建矩阵:
A = np.mat("3 4;5 6") print("A\\n", A)我们创建的矩阵如下所示:
A [[ 3\\. 4.][ 5\\. 6.]] -
用
det()函数计算行列式:print("Determinant", np.linalg.det(A))行列式如下所示:
Determinant -2.0
刚刚发生了什么?
我们从numpy.linalg模块(请参见determinant.py)使用det()函数计算了矩阵的行列式:
from __future__ import print_function
import numpy as npA = np.mat("3 4;5 6")
print("A\\n", A)print("Determinant", np.linalg.det(A))
快速傅立叶变换
快速傅里叶变换(FFT)是一种用于计算离散傅立叶变换(DFT)的有效算法。
注意
傅立叶变换与傅立叶级数相关,在上一章中提到了第 5 章,“处理矩阵和函数”。 傅里叶级数将信号表示为正弦和余弦项之和。
FFT 在更多朴素算法上进行了改进,其阶数为O(N log N)。 DFT 在信号处理,图像处理,求解偏微分方程等方面具有应用。 NumPy 有一个名为fft的模块,该模块提供 FFT 函数。 该模块中的许多函数已配对。 对于那些函数,另一个函数执行逆运算。 例如,fft()和ifft()函数形成这样的一对。
实战时间 – 计算傅立叶变换
首先,我们将创建一个要转换的信号。 通过以下步骤计算傅立叶变换:
-
创建具有
30点的余弦波,如下所示:x = np.linspace(0, 2 * np.pi, 30) wave = np.cos(x) -
用
fft()函数变换余弦波:transformed = np.fft.fft(wave) -
使用
ifft()函数应用逆变换。 它应该大致返回原始信号。 检查以下行:print(np.all(np.abs(np.fft.ifft(transformed) - wave) < 10 -9))结果显示如下:
True -
使用 matplotlib 绘制转换后的信号:
plt.plot(transformed) plt.title('Transformed cosine') plt.xlabel('Frequency') plt.ylabel('Amplitude') plt.grid() plt.show()下图显示了 FFT 结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AiwtI8ps-1681311708257)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_06_01.jpg)]
刚刚发生了什么?
我们将fft()函数应用于余弦波。 应用ifft()函数后,我们得到了信号(请参阅fourier.py):
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as pltx = np.linspace(0, 2 * np.pi, 30)
wave = np.cos(x)
transformed = np.fft.fft(wave)
print(np.all(np.abs(np.fft.ifft(transformed) - wave) < 10 -9))plt.plot(transformed)
plt.title('Transformed cosine')
plt.xlabel('Frequency')
plt.ylabel('Amplitude')
plt.grid()
plt.show()
移位
numpy.linalg模块的fftshift()函数将零频率分量移到频谱中心。 零频率分量对应于信号的平均值 。 ifftshift()函数可逆转此操作。
实战时间 – 变换频率
我们将创建一个信号,对其进行转换,然后将其移位。 按以下步骤移动频率:
-
创建具有
30点的余弦波:x = np.linspace(0, 2 * np.pi, 30) wave = np.cos(x) -
使用
fft()函数变换余弦波:transformed = np.fft.fft(wave) -
使用
fftshift()函数移动信号:shifted = np.fft.fftshift(transformed) -
用
ifftshift()函数反转移位。 这应该撤消这种转变。 检查以下代码段:print(np.all((np.fft.ifftshift(shifted) - transformed) < 10 -9))The result appears as follows:
True -
绘制信号并使用 matplotlib 对其进行转换:
plt.plot(transformed, lw=2, label="Transformed") plt.plot(shifted, '--', lw=3, label="Shifted") plt.title('Shifted and transformed cosine wave') plt.xlabel('Frequency') plt.ylabel('Amplitude') plt.grid() plt.legend(loc='best') plt.show()下图显示了移位和 FFT 的效果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wnknUJuq-1681311708258)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_06_02.jpg)]
刚刚发生了什么?
我们将fftshift()函数应用于余弦波。 应用ifftshift()函数后,我们返回我们的信号(请参阅fouriershift.py):
import numpy as np
import matplotlib.pyplot as pltx = np.linspace(0, 2 * np.pi, 30)
wave = np.cos(x)
transformed = np.fft.fft(wave)
shifted = np.fft.fftshift(transformed)
print(np.all(np.abs(np.fft.ifftshift(shifted) - transformed) < 10 -9))plt.plot(transformed, lw=2, label="Transformed")
plt.plot(shifted, '--', lw=3, label="Shifted")
plt.title('Shifted and transformed cosine wave')
plt.xlabel('Frequency')
plt.ylabel('Amplitude')
plt.grid()
plt.legend(loc='best')
plt.show()
随机数
蒙特卡罗方法,随机演算等中使用了随机数。 真正的随机数很难生成,因此在实践中,我们使用伪随机数字,除了某些非常特殊的情况外,对于大多数意图和目的来说都是足够随机的。 这些数字似乎是随机的,但是如果您更仔细地分析它们,则将意识到它们遵循一定的模式。 与随机数相关的函数位于 NumPy 随机模块中。 核心随机数字生成器基于 Mersenne Twister 算法 – 一种标准且众所周知的算法。 我们可以从离散或连续分布中生成随机数。 分布函数具有一个可选的size参数,该参数告诉 NumPy 生成多少个数字。 您可以指定整数或元组作为大小。 这将导致数组中填充适当形状的随机数。 离散分布包括几何分布,超几何分布和二项分布。
实战时间 – 使用二项来赌博
二项分布模型是整数个独立试验中的成功的次数,其中每个实验中成功的概率是固定的数字。
想象一下一个 17 世纪的赌场,您可以在上面掷 8 个筹码。 九枚硬币被翻转。 如果少于五个,那么您将损失八分之一,否则将获胜。 让我们模拟一下,从拥有的 1,000 个硬币开始。 为此,可以使用随机模块中的binomial()函数。
要了解 binomial()函数,请查看以下部分:
-
将代表现金余额的数组初始化为零。 调用大小为 10000 的
binomial()函数。这表示在我们的赌场中有 10,000 次硬币翻转:cash = np.zeros(10000) cash[0] = 1000 outcome = np.random.binomial(9, 0.5, size=len(cash)) -
查看硬币翻转的结果并更新现金数组。 打印结果的最小值和最大值,只是为了确保我们没有任何奇怪的异常值:
for i in range(1, len(cash)):if outcome[i] < 5:cash[i] = cash[i - 1] - 1elif outcome[i] < 10:cash[i] = cash[i - 1] + 1else:raise AssertionError("Unexpected outcome " + outcome)print(outcome.min(), outcome.max())不出所料,该值在
0和9之间。 在下图中,您可以看到现金余额执行随机游走: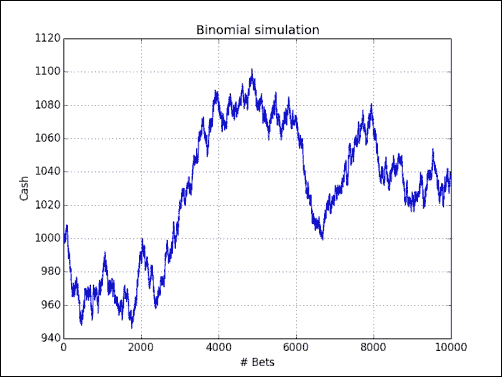
刚刚发生了什么?
我们使用 NumPy 随机模块中的binomial()函数进行了随机游走实验(请参见headortail.py):
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as pltcash = np.zeros(10000)
cash[0] = 1000
np.random.seed(73)
outcome = np.random.binomial(9, 0.5, size=len(cash))for i in range(1, len(cash)):if outcome[i] < 5:cash[i] = cash[i - 1] - 1elif outcome[i] < 10:cash[i] = cash[i - 1] + 1else:raise AssertionError("Unexpected outcome " + outcome)print(outcome.min(), outcome.max())plt.plot(np.arange(len(cash)), cash)
plt.title('Binomial simulation')
plt.xlabel('# Bets')
plt.ylabel('Cash')
plt.grid()
plt.show()
超几何分布
超几何分布对其中装有两种对象的罐进行建模。 该模型告诉我们,如果我们从罐子中取出指定数量的物品而不更换它们,可以得到一种类型的对象。 NumPy 随机模块具有模拟这种情况的hypergeometric()函数。
实战时间 – 模拟游戏节目
想象一下,游戏会显示出参赛者每次正确回答问题时,都会从罐子中拉出三个球,然后放回去。 现在,有一个陷阱,罐子里的一个球不好。 每次拔出时,参赛者将失去 6 分。 但是,如果他们设法摆脱 25 个普通球中的 3 个,则得到 1 分。 那么,如果我们总共有 100 个问题,将会发生什么? 查看以下部分以了解解决方案:
-
使用
hypergeometric()函数初始化游戏结果。 此函数的第一个参数是做出正确选择的方法数量,第二个参数是做出错误选择的方法数量,第三个参数是采样的项目数量:points = np.zeros(100) outcomes = np.random.hypergeometric(25, 1, 3, size=len(points)) -
根据上一步的结果设置评分:
for i in range(len(points)):if outcomes[i] == 3:points[i] = points[i - 1] + 1elif outcomes[i] == 2:points[i] = points[i - 1] - 6else:print(outcomes[i])下图显示了评分如何演变:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jICOl3xH-1681311708259)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_06_04.jpg)]
刚刚发生了什么?
我们使用 NumPy random模块中的 hypergeometric()函数模拟了游戏节目。 游戏得分取决于每次比赛参与者从罐子中抽出多少好球和坏球(请参阅urn.py):
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as pltpoints = np.zeros(100)
np.random.seed(16)
outcomes = np.random.hypergeometric(25, 1, 3, size=len(points))for i in range(len(points)):if outcomes[i] == 3:points[i] = points[i - 1] + 1elif outcomes[i] == 2:points[i] = points[i - 1] - 6else:print(outcomes[i])plt.plot(np.arange(len(points)), points)
plt.title('Game show simulation')
plt.xlabel('# Rounds')
plt.ylabel('Score')
plt.grid()
plt.show()
连续分布
我们通常使用概率密度函数(PDF)对连续分布进行建模。 值处于特定间隔的可能性由 PDF 的积分确定)。 NumPy random模块具有表示连续分布的函数-beta(),chisquare(),exponential(),f(),gamma(),gumbel(),laplace(),lognormal() ,logistic(),multivariate_normal(),noncentral_chisquare(),noncentral_f(),normal()等。
实战时间 – 绘制正态分布
我们可以从正态分布中生成随机数,并通过直方图可视化其分布)。 通过以下步骤绘制正态分布:
-
使用
randomNumPy 模块中的normal()函数,为给定的样本量生成随机的数字:N=10000 normal_values = np.random.normal(size=N) -
绘制直方图和理论 PDF,其中心值为 0,标准偏差为 1。 为此,请使用 matplotlib:
_, bins, _ = plt.hist(normal_values, np.sqrt(N), normed=True, lw=1) sigma = 1 mu = 0 plt.plot(bins, 1/(sigma * np.sqrt(2 * np.pi)) * np.exp( - (bins - mu)2 / (2 * sigma2) ),lw=2) plt.show()在下面的图表中,我们看到了熟悉的钟形曲线:
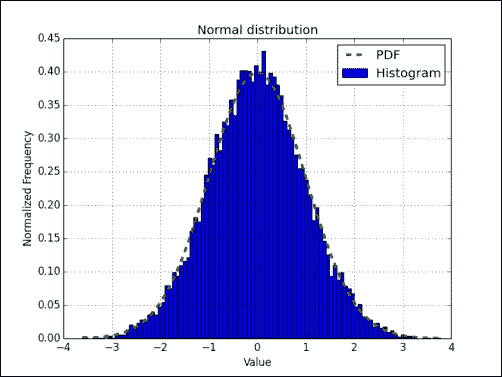
刚刚发生了什么?
我们使用来自随机 NumPy 模块的normal()函数可视化正态分布。 为此,我们绘制了钟形曲线和随机生成的值的直方图(请参见normaldist.py):
import numpy as np
import matplotlib.pyplot as pltN=10000np.random.seed(27)
normal_values = np.random.normal(size=N)
_, bins, _ = plt.hist(normal_values, np.sqrt(N), normed=True, lw=1, label="Histogram")
sigma = 1
mu = 0
plt.plot(bins, 1/(sigma * np.sqrt(2 * np.pi)) * np.exp( - (bins - mu)2 / (2 * sigma2) ), '--', lw=3, label="PDF")
plt.title('Normal distribution')
plt.xlabel('Value')
plt.ylabel('Normalized Frequency')
plt.grid()
plt.legend(loc='best')
plt.show()
对数正态分布
对数正态分布是自然对数呈正态分布的随机变量的分布。 随机 NumPy 模块的 lognormal()函数可对该分布进行建模。
实战时间 – 绘制对数正态分布
让我们用直方图可视化对数正态分布及其 PDF:
-
使用
randomNumPy 模块中的normal()函数生成随机数:N=10000 lognormal_values = np.random.lognormal(size=N) -
绘制直方图和理论 PDF,其中心值为 0,标准偏差为 1:
_, bins, _ = plt.hist(lognormal_values, np.sqrt(N), normed=True, lw=1) sigma = 1 mu = 0 x = np.linspace(min(bins), max(bins), len(bins)) pdf = np.exp(-(numpy.log(x) - mu)2 / (2 * sigma2))/ (x * sigma * np.sqrt(2 * np.pi)) plt.plot(x, pdf,lw=3) plt.show()直方图和理论 PDF 的拟合非常好,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n2ZjDB5H-1681311708259)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_06_06.jpg)]
刚刚发生了什么?
我们使用random NumPy 模块中的lognormal()函数可视化了对数正态分布。 我们通过绘制理论 PDF 曲线和随机生成的值的直方图(请参见lognormaldist.py)来做到这一点:
import numpy as np
import matplotlib.pyplot as pltN=10000
np.random.seed(34)
lognormal_values = np.random.lognormal(size=N)
_, bins, _ = plt.hist(lognormal_values, np.sqrt(N), normed=True, lw=1, label="Histogram")
sigma = 1
mu = 0
x = np.linspace(min(bins), max(bins), len(bins))
pdf = np.exp(-(np.log(x) - mu)2 / (2 * sigma2))/ (x * sigma * np.sqrt(2 * np.pi))
plt.xlim([0, 15])
plt.plot(x, pdf,'--', lw=3, label="PDF")
plt.title('Lognormal distribution')
plt.xlabel('Value')
plt.ylabel('Normalized frequency')
plt.grid()
plt.legend(loc='best')
plt.show()
统计量自举
自举是一种用于估计方差,准确性和其他样本估计量度的方法,例如算术平均值。 最简单的自举过程包括以下步骤:
- 从具有相同大小
N的原始数据样本中生成大量样本。 您可以将原始数据视为包含数字的罐子。 我们通过N次从瓶子中随机选择一个数字来创建新样本。 每次我们将数字返回到罐子中时,一个生成的样本中可能会多次出现一个数字。 - 对于新样本,我们为每个样本计算要调查的统计估计值(例如,算术平均值)。 这为我们提供了估计器可能值的样本。
实战时间 – 使用numpy.random.choice()进行采样
我们将使用numpy.random.choice()函数对执行自举。
-
启动 IPython 或 Python Shell 并导入 NumPy:
$ ipython In [1]: import numpy as np -
按照正态分布生成数据样本:
In [2]: N = 500In [3]: np.random.seed(52)In [4]: data = np.random.normal(size=N) -
计算数据的平均值:
In [5]: data.mean() Out[5]: 0.07253250605445645从原始数据生成
100样本并计算其平均值(当然,更多样本可能会导致更准确的结果):In [6]: bootstrapped = np.random.choice(data, size=(N, 100))In [7]: means = bootstrapped.mean(axis=0)In [8]: means.shape Out[8]: (100,) -
计算得到的算术平均值的均值,方差和标准偏差:
In [9]: means.mean() Out[9]: 0.067866373318115278In [10]: means.var() Out[10]: 0.001762807104774598In [11]: means.std() Out[11]: 0.041985796464692651如果我们假设均值的正态分布,则可能需要了解 z 得分,其定义如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mtCnunsa-1681311708260)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_06_10.jpg)]
In [12]: (data.mean() - means.mean())/means.std() Out[12]: 0.11113598238549766从 z 得分值,我们可以了解实际均值的可能性。
刚刚发生了什么?
我们通过生成样本并计算每个样本的平均值来自举数据样本。 然后,我们计算了均值,标准差,方差和均值的 z 得分。 我们使用numpy.random.choice()函数进行自举。
总结
您在本章中学到了很多有关 NumPy 模块的知识。 我们介绍了线性代数,快速傅立叶变换,连续和离散分布以及随机数。
在下一章中,我们将介绍专门的例程。 这些函数可能不经常使用,但是在需要时非常有用。
七、探索特殊例程
作为 NumPy 的用户,我们有时会发现自己有特殊需要,例如财务计算或信号处理。 幸运的是,NumPy 满足了我们的大多数需求。 本章介绍一些更专门的 NumPy 函数。
在本章中,我们将介绍以下主题:
- 排序和搜索
- 特殊函数
- 财务函数
- 窗口函数
排序
NumPy 具有几个数据排序例程:
sort()函数返回排序数组lexsort()函数使用键列表执行排序argsort()函数返回将对数组进行排序的索引ndarray类具有执行原地排序的sort()方法msort()函数沿第一轴对数组进行排序sort_complex()函数按复数的实部和虚部对它们进行排序
从此列表中,argsort()和sort()函数也可用作 NumPy 数组的方法。
实战时间 – 按词法排序
NumPy lexsort()函数返回输入数组元素的索引数组,这些索引对应于按词法对数组进行排序。 我们需要给函数一个数组或排序键元组:
-
让我们回到第 3 章,“熟悉常用函数”。 在该章中,我们使用了
AAPL的股价数据。 我们将加载收盘价和(总是复杂的)日期。 实际上,只为日期创建一个转换器函数:def datestr2num(s):return datetime.datetime.strptime(s, "%d-%m-%Y").toordinal() dates, closes=np.loadtxt('AAPL.csv', delimiter=',', usecols=(1, 6), converters={1:datestr2num}, unpack=True) -
使用
lexsort()函数按词法对名称进行排序。 数据已经按日期排序,但也按结束排序:indices = np.lexsort((dates, closes)) print("Indices", indices) print(["%s %s" % (datetime.date.fromordinal(dates[i]),closes[i]) for i in indices])该代码显示以下内容:
Indices [ 0 16 1 17 18 4 3 2 5 28 19 21 15 6 29 22 27 20 9 7 25 26 10 8 14 11 23 12 24 13] ['2011-01-28 336.1', '2011-02-22 338.61', '2011-01-31 339.32', '2011-02-23 342.62', '2011-02-24 342.88', '2011-02-03 343.44', '2011-02-02 344.32', '2011-02-01 345.03', '2011-02-04 346.5', '2011-03-10 346.67', '2011-02-25 348.16', '2011-03-01 349.31', '2011-02-18 350.56', '2011-02-07 351.88', '2011-03-11 351.99', '2011-03-02 352.12', '2011-03-09 352.47', '2011-02-28 353.21', '2011-02-10 354.54', '2011-02-08 355.2', '2011-03-07 355.36', '2011-03-08 355.76', '2011-02-11 356.85', '2011-02-09 358.16', '2011-02-17 358.3', '2011-02-14 359.18', '2011-03-03 359.56', '2011-02-15 359.9', '2011-03-04 360.0', '2011-02-16 363.13']
刚刚发生了什么?
我们使用 NumPy lexsort()函数按词法对AAPL的收盘价进行分类。 该函数返回与数组排序相对应的索引(请参见lex.py):
from __future__ import print_function
import numpy as np
import datetimedef datestr2num(s):return datetime.datetime.strptime(s, "%d-%m-%Y").toordinal()dates, closes=np.loadtxt('AAPL.csv', delimiter=',', usecols=(1, 6), converters={1:datestr2num}, unpack=True)
indices = np.lexsort((dates, closes))print("Indices", indices)
print(["%s %s" % (datetime.date.fromordinal(int(dates[i])), closes[i]) for i in indices])
勇往直前 – 尝试不同的排序顺序
我们使用日期和收盘价顺序进行了排序。 请尝试其他顺序。 使用我们在上一章中学习到的随机模块生成随机数,然后使用lexsort()对其进行排序。
实战时间 – 通过使用partition()函数选择快速中位数进行部分排序
partition()函数执行部分排序, 应该比完整排序更快,因为它的工作量较小。
注意
有关更多信息,请参考这里。 一个常见的用例是获取集合的前 10 个元素。 部分排序不能保证顶部元素组本身的正确顺序。
该函数的第一个参数是要部分排序的数组。 第二个参数是与数组元素索引相对应的整数或整数序列。 partition()函数对那些索引中的元素进行正确排序。 使用一个指定的索引,我们得到两个分区。 具有多个索引,我们得到多个分区。 排序算法确保分区中的元素(小于正确排序的元素)位于该元素之前。 否则,它们将放置在此元素后面。 让我们用一个例子来说明这个解释。 启动 Python 或 IPython Shell 并导入 NumPy:
$ ipython
In [1]: import numpy as np创建一个包含随机元素的数组以进行排序:
In [2]: np.random.seed(20)In [3]: a = np.random.random_integers(0, 9, 9)In [4]: a
Out[4]: array([3, 9, 4, 6, 7, 2, 0, 6, 8])通过将其分成两个大致相等的部分,对数组进行部分排序:
In [5]: np.partition(a, 4)
Out[5]: array([0, 2, 3, 4, 6, 6, 7, 9, 8])除了最后两个元素外,我们得到了几乎完美的排序。
刚刚发生了什么?
我们对 9 个元素的数组进行了部分排序。 排序仅保证索引 4 中间的一个元素位于正确的位置。 这对应于尝试获取数组的前五个元素而不关心前五个组中的顺序。 由于正确排序的元素位于中间,因此这也给出了数组的中位数。
复数
复数是具有实部和虚部的数字。 如您在前几章中所记得的那样,NumPy 具有特殊的复杂数据类型,这些数据类型通过两个浮点数表示复数。 可以使用 NumPy sort_complex()函数对这些数字进行排序。 此函数首先对实部进行排序,然后对虚部进行排序。
实战时间 – 对复数进行排序
我们将创建复数数组并将其排序:
-
为复数的实部生成五个随机数,为虚部生成五个数。 将随机生成器播种到
42:np.random.seed(42) complex_numbers = np.random.random(5) + 1j * np.random.random(5) print("Complex numbers\\n", complex_numbers) -
调用
sort_complex()函数对我们在上一步中生成的复数进行排序:print("Sorted\\n", np.sort_complex(complex_numbers))排序的数字将是:
Sorted [ 0.39342751+0.34955771j 0.40597665+0.77477433j 0.41516850+0.26221878j0.86631422+0.74612422j 0.92293095+0.81335691j]
刚刚发生了什么?
我们生成了随机复数,并使用sort_complex()函数对其进行了排序(请参见sortcomplex.py):
from __future__ import print_function
import numpy as npnp.random.seed(42)
complex_numbers = np.random.random(5) + 1j * np.random.random(5)
print("Complex numbers\\n", complex_numbers)print("Sorted\\n", np.sort_complex(complex_numbers))
小测验 - 生成随机数
Q1. 哪个 NumPy 模块处理随机数?
randnumrandomrandomutilrand
搜索
NumPy 具有几个可以搜索数组的函数:
-
argmax()函数提供数组最大值的索引 :>>> a = np.array([2, 4, 8]) >>> np.argmax(a) 2 -
nanargmax()函数的作用与上面相同,但忽略 NaN 值:>>> b = np.array([np.nan, 2, 4]) >>> np.nanargmax(b) 2 -
argmin()和nanargmin()函数提供相似的功能,但针对最小值。argmax()和nanargmax()函数也可用作ndarray类的方法。 -
argwhere()函数搜索非零值,并返回按元素分组的相应索引:>>> a = np.array([2, 4, 8]) >>> np.argwhere(a <= 4) array([[0],[1]]) -
searchsorted()函数告诉您数组中的索引,指定值所属的数组将保持排序顺序。 它使用二分搜索,即O(log n)算法。 我们很快就会看到此函数的作用。 -
extract()函数根据条件从数组中检索值。
实战时间 – 使用searchsorted
searchsorted()函数获取排序数组中值的索引。 一个例子应该清楚地说明这一点:
-
为了演示,使用
arange()创建一个数组,该数组当然被排序:a = np.arange(5) -
是时候调用
searchsorted()函数了:indices = np.searchsorted(a, [-2, 7]) print("Indices", indices)索引,应保持排序顺序:
Indices [0 5] -
用
insert()函数构造完整的数组:print("The full array", np.insert(a, indices, [-2, 7]))这给了我们完整的数组:
The full array [-2 0 1 2 3 4 7]
刚刚发生了什么?
searchsorted()函数为我们提供了7和-2的索引5和0。 使用这些索引,我们将数组设置为array [-2, 0, 1, 2, 3, 4, 7],因此数组保持排序状态(请参见sortedsearch.py):
from __future__ import print_function
import numpy as npa = np.arange(5)
indices = np.searchsorted(a, [-2, 7])
print("Indices", indices)print("The full array", np.insert(a, indices, [-2, 7]))
数组元素提取
NumPy extract()函数使我们可以根据条件从数组中提取项目。 此函数类似于第 3 章,“我们熟悉的函数”。 特殊的nonzero()函数选择非零元素。
实战时间 – 从数组中提取元素
让我们提取数组的偶数元素:
-
使用
arange()函数创建数组:a = np.arange(7) -
创建选择偶数元素的条件:
condition = (a % 2) == 0 -
使用我们的条件和
extract()函数提取偶数元素:print("Even numbers", np.extract(condition, a))这为我们提供了所需的偶数(
np.extract(condition, a)等于a[np.where(condition)[0]]):Even numbers [0 2 4 6] -
使用
nonzero()函数选择非零值:print("Non zero", np.nonzero(a))这将打印数组的所有非零值:
Non zero (array([1, 2, 3, 4, 5, 6]),)
刚刚发生了什么?
我们使用布尔值条件和 NumPy extract()函数从数组中提取了偶数元素(请参见extracted.py):
from __future__ import print_function
import numpy as npa = np.arange(7)
condition = (a % 2) == 0
print("Even numbers", np.extract(condition, a))
print("Non zero", np.nonzero(a))
财务函数
NumPy 具有多种财务函数:
fv()函数计算出所谓的未来值。 未来值基于某些假设,给出了金融产品在未来日期的价值。pv()函数计算当前值(请参阅这里)。 当前值是今天的资产价值。npv()函数返回净当前值。 净当前值定义为所有当前现金流的总和。pmt()函数计算借贷还款的本金加上利息。irr()函数计算的内部收益率。 内部收益率是实际利率, 未将通货膨胀考虑在内。mirr()函数计算修正的内部收益率。 修正的内部收益率是内部收益率的改进版本。nper()函数返回定期付款数值。rate()函数计算利率。
实战时间 – 确定未来值
未来值根据某些假设给出了金融产品在未来日期的价值。 终值取决于四个参数-利率,周期数,定期付款和当前值。
注意
在这个页面上关于未来值的东西。 具有复利的终值的公式如下:
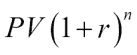
在上式中, PV是当前值,r是利率,n是周期数。
在本节中,让我们以3% 的利率,5年的季度10的季度付款以及1000的当前值。 用适当的值调用fv()函数(负值表示支出现金流):
print("Future value", np.fv(0.03/4, 5 * 4, -10, -1000))
终值如下:
Future value 1376.09633204如果我们改变保存和保持其他参数不变的年数,则会得到以下图表:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-grWeF5JH-1681311708261)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_07_01.jpg)]
刚刚发生了什么?
我们使用 NumPy fv()函数从1000的当前值,3的利率,5年和10的季度付款开始计算未来值。 。 我们绘制了各种保存期的未来值(请参见futurevalue.py):
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as pltprint("Future value", np.fv(0.03/4, 5 * 4, -10, -1000))fvals = []for i in xrange(1, 10):fvals.append(np.fv(.03/4, i * 4, -10, -1000))plt.plot(range(1, 10), fvals, 'bo')
plt.title('Future value, 3 % interest,\\n Quarterly payment of 10')
plt.xlabel('Saving periods in years')
plt.ylabel('Future value')
plt.grid()
plt.legend(loc='best')
plt.show()
当前值
当前值是今天的资产价值。 NumPy pv()函数可以计算当前值。 此函数与fv()函数类似,并且需要利率,期间数和定期还款,但是这里我们从终值开始。
了解有关当前值的更多信息。 如果需要,可以很容易地从将来值的公式中得出当前值的公式。
实战时间 – 获得当前值
让我们将“实战时间 – 确定未来值”中的数字反转:
插入“实战时间 – 确定未来值”部分:
print("Present value", np.pv(0.03/4, 5 * 4, -10, 1376.09633204))
除了微小的数值误差外,这给了我们1000预期的效果。 实际上,这不是错误,而是表示问题。 我们在这里处理现金流出,这就是负值的原因:
Present value -999.999999999刚刚发生了什么?
我们反转了“实战时间 – 确定将来值”部分,以从将来值中获得当前值。 这是通过 NumPy pv()函数完成的。
净当前值
净当前值定义为所有当前值现金流的总和。 NumPy npv()函数返回现金流的净当前值。 该函数需要两个参数:rate和代表现金流的数组。
阅读有关净当前值的更多信息,。 在净当前值的公式中, Rt是时间段的现金流,r是折现率,t是时间段的指数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vofFzxDY-1681311708261)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_07_10.jpg)]
实战时间 – 计算净当前值
我们将计算随机产生的现金流序列的净当前值:
-
为现金流量序列生成五个随机值。 插入 -100 作为起始值:
cashflows = np.random.randint(100, size=5) cashflows = np.insert(cashflows, 0, -100) print("Cashflows", cashflows)现金流如下:
Cashflows [-100 38 48 90 17 36] -
调用
npv()函数从上一步生成的现金流量序列中计算净当前值。 使用百分之三的比率:print("Net present value", np.npv(0.03, cashflows))净当前值:
Net present value 107.435682443
刚刚发生了什么?
我们使用 NumPy npv()函数(请参见netpresentvalue.py)从随机生成的现金流序列中计算出净当前值:
from __future__ import print_function
import numpy as npcashflows = np.random.randint(100, size=5)
cashflows = np.insert(cashflows, 0, -100)
print("Cashflows", cashflows)print("Net present value", np.npv(0.03, cashflows))
内部收益率
收益率的内部利率是有效利率,它没有考虑通货膨胀。 NumPy irr()函数返回给定现金流序列的内部收益率。
实战时间 – 确定内部收益率
让我们重用“实战时间 – 计算净当前值”部分的现金流序列。 在现金流序列上调用irr()函数:
print("Internal rate of return", np.irr([-100, 38, 48, 90, 17, 36]))
内部收益率:
Internal rate of return 0.373420226888刚刚发生了什么?
我们根据“实战时间 – 计算净当前值”部分的现金流系列计算内部收益率。 该值由 NumPy irr()函数给出。
定期付款
NumPy pmt()函数允许您基于利率和定期还款次数来计算贷款的定期还款。
实战时间 – 计算定期付款
假设您的贷款为 1000 万,利率为1%。 您有30年还清贷款。 您每个月要付多少钱? 让我们找出答案。
使用上述值调用pmt()函数:
print("Payment", np.pmt(0.01/12, 12 * 30, 10000000))
每月付款:
Payment -32163.9520447刚刚发生了什么?
我们以每年1% 的利率计算了 1000 万的贷款的每月付款。 鉴于我们有30年的还款期,pmt()函数告诉我们我们需要每月支付32163.95。
付款次数
NumPy nper()函数告诉我们要偿还贷款需要多少次定期付款。 必需的参数是贷款的利率,固定金额的定期还款以及当前值。
实战时间 – 确定定期付款的次数
考虑一笔9000的贷款,其利率为10% ,固定每月还款100。
使用 NumPy nper()函数找出需要多少笔付款:
print("Number of payments", np.nper(0.10/12, -100, 9000))
付款次数:
Number of payments 167.047511801刚刚发生了什么?
我们确定了还清利率为10的9000贷款和100每月还款所需的还款次数。 返回的付款数为167。
利率
NumPy rate()函数根据给定的定期付款次数, 付款金额,当前值和终值来计算利率。
实战时间 – 确定利率
让我们从“实战时间 – 确定定期付款的数量”部分的值,并从其他参数反向计算利率。
填写上一个“实战时间”部分中的数字:
print("Interest rate", 12 * np.rate(167, -100, 9000, 0))
预期的利率约为 10%:
Interest rate 0.0999756420664刚刚发生了什么?
我们使用 NumPy rate()函数和“实战时间 – 确定定期付款的数量”部分的值来计算贷款的利率。 忽略舍入错误,我们得到了最初的10百分比。
窗口函数
窗口函数是信号处理中常用的数学函数。 应用包括光谱分析和过滤器设计。 这些函数在指定域之外定义为 0。 NumPy 具有许多窗口函数:bartlett(),blackman(),hamming(),hanning()和kaiser()。 您可以在第 4 章,“便捷函数”和第 3 章,“熟悉常用函数”。
实战时间 – 绘制 Bartlett 窗口
Bartlett 窗口是三角形平滑窗口:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1ncnZOto-1681311708261)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_07_11.jpg)]
-
调用 NumPy
bartlett()函数:window = np.bartlett(42) -
使用 matplotlib 进行绘图很容易:
plt.plot(window) plt.show()如下所示,这是 Bartlett 窗口,该窗口是三角形的:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JQxDl3m5-1681311708261)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_07_02.jpg)]
刚刚发生了什么?
我们用 NumPy bartlett()函数绘制了 Bartlett 窗口。
布莱克曼窗口
布莱克曼窗口是以下余弦的和:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GmZxQ4K1-1681311708262)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_07_12.jpg)]
NumPy blackman()函数返回布莱克曼窗口。 唯一参数是输出窗口中M的点数。 如果该数字为0或小于0,则该函数返回一个空数组。
实战时间 – 使用布莱克曼窗口平滑股票价格
让我们从小型AAPL股价数据文件中平滑收盘价:
-
将数据加载到 NumPy 数组中。 调用 NumPy
blackman()函数形成一个窗口,然后使用该窗口平滑价格信号:closes=np.loadtxt('AAPL.csv', delimiter=',', usecols=(6,), converters={1:datestr2num}, unpack=True) N = 5 window = np.blackman(N) smoothed = np.convolve(window/window.sum(),closes, mode='same') -
使用 matplotlib 绘制平滑价格。 在此示例中,我们将省略前五个数据点和后五个数据点。 这样做的原因是存在强烈的边界效应:
plt.plot(smoothed[N:-N], lw=2, label="smoothed") plt.plot(closes[N:-N], label="closes") plt.legend(loc='best') plt.show()使用布莱克曼窗口平滑的
AAPL收盘价应如下所示: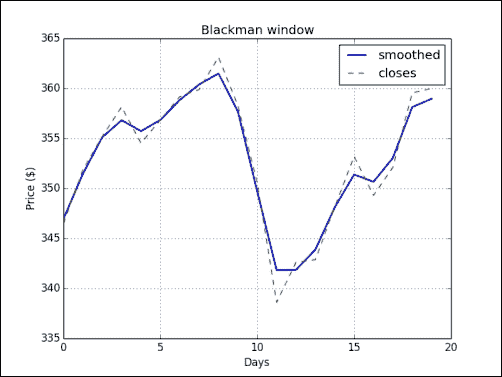
刚刚发生了什么?
我们从样本数据文件中绘制了AAPL的收盘价,该价格使用布莱克曼窗口和 NumPy blackman()函数进行了平滑处理(请参见plot_blackman.py):
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.dates import datestr2numcloses=np.loadtxt('AAPL.csv', delimiter=',', usecols=(6,), converters={1:datestr2num}, unpack=True)
N = 5
window = np.blackman(N)
smoothed = np.convolve(window/window.sum(), closes, mode='same')
plt.plot(smoothed[N:-N], lw=2, label="smoothed")
plt.plot(closes[N:-N], '--', label="closes")
plt.title('Blackman window')
plt.xlabel('Days')
plt.ylabel('Price ($)')
plt.grid()
plt.legend(loc='best')
plt.show()
汉明窗口
汉明窗由加权余弦形成。 计算公式如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0HWzpcFT-1681311708262)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_07_13.jpg)]
NumPy hamming()函数返回汉明窗口。 唯一的参数是输出窗口中点的数量M。 如果此数字为0或小于0,则返回一个空数组。
实战时间 – 绘制汉明窗口
让我们绘制汉明窗口:
-
调用 NumPy
hamming()函数:window = np.hamming(42) -
使用 matplotlib 绘制窗口:
plt.plot(window) plt.show()汉明窗图显示如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NudLWjCv-1681311708262)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_07_04.jpg)]
刚刚发生了什么?
我们使用 NumPy hamming()函数绘制了汉明窗口。
凯撒窗口
凯撒窗口由贝塞尔函数形成。
注意
贝塞尔函数是贝塞尔微分方程的解。
公式如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8k46tbbh-1681311708263)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_07_14.jpg)]
I0是零阶贝塞尔函数。 NumPy kaiser()函数返回凯撒窗口。 第一个参数是输出窗口中的点数。 如果此数字为0或小于0,则函数将返回一个空数组。 第二个参数是beta。
实战时间 – 绘制凯撒窗口
让我们绘制凯撒窗口:
-
调用 NumPy
kaiser()函数:window = np.kaiser(42, 14) -
使用 matplotlib 绘制窗口:
plt.plot(window) plt.show()凯撒窗口显示如下:
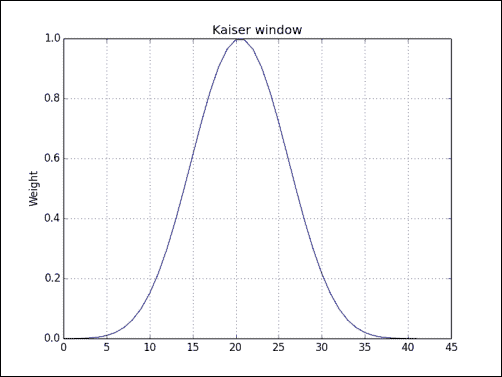
刚刚发生了什么?
我们使用 NumPy kaiser()函数绘制了凯撒窗口。
特殊数学函数
我们将以一些特殊的数学函数结束本章。 第一类 0 阶的修正的贝塞尔函数由i0()表示为 NumPy 中的 。 sinc函数在 NumPy 中由具有相同名称的函数表示, 也有此函数的二维版本。 sinc是三角函数; 有关更多详细信息,请参见这里。 sinc()函数具有两个定义。
NumPy sinc()函数符合以下定义:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gxosrlqi-1681311708263)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_07_15.jpg)]
实战时间 – 绘制修正的贝塞尔函数
让我们看看修正的第一种零阶贝塞尔函数是什么样的:
-
使用 NumPy
linspace()函数计算均匀间隔的值:x = np.linspace(0, 4, 100) -
调用 NumPy
i0()函数:vals = np.i0(x) -
使用 matplotlib 绘制修正的贝塞尔函数:
plt.plot(x, vals) plt.show()修正的贝塞尔函数将具有以下输出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OGtBrTZM-1681311708263)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_07_06.jpg)]
刚刚发生了什么?
我们用 NumPy i0()函数绘制了第一种零阶修正的贝塞尔函数。
sinc
sinc()函数广泛用于数学和信号处理中。 NumPy 具有相同名称的函数。 也存在二维函数。
实战时间 – 绘制sinc函数
我们将绘制sinc()函数:
-
使用 NumPy
linspace()函数计算均匀间隔的值:x = np.linspace(0, 4, 100) -
调用 NumPy
sinc()函数:vals = np.sinc(x) -
用 matplotlib 绘制
sinc()函数:plt.plot(x, vals) plt.show()sinc()函数将具有以下输出: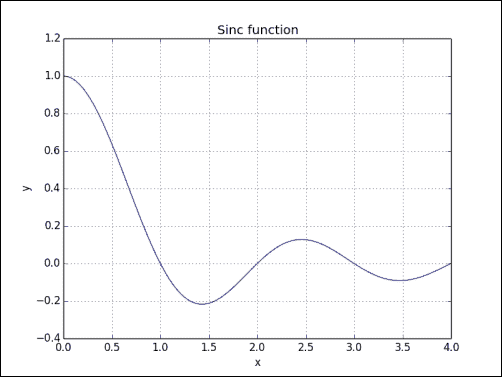
sinc2d()函数需要二维数组。 我们可以使用outer()函数创建它,从而得到该图(代码在以下部分中):[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W0Q8beJe-1681311708264)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_07_08.jpg)]
刚刚发生了什么?
我们用 NumPy sinc()函数(参见plot_sinc.py)绘制了众所周知的sinc函数:
import numpy as np
import matplotlib.pyplot as pltx = np.linspace(0, 4, 100)
vals = np.sinc(x)plt.plot(x, vals)
plt.title('Sinc function')
plt.xlabel('x')
plt.ylabel('y')
plt.grid()
plt.show()
我们在两个维度上都做了相同的操作(请参见sinc2d.py):
import numpy as np
import matplotlib.pyplot as pltx = np.linspace(0, 4, 100)
xx = np.outer(x, x)
vals = np.sinc(xx)plt.imshow(vals)
plt.title('Sinc 2D')
plt.xlabel('x')
plt.ylabel('y')
plt.grid()
plt.show()
总结
这是一章,涵盖了更多专门的 NumPy 主题。 我们介绍了排序和搜索,特殊函数,财务工具和窗口函数。
下一章是关于非常重要的测试主题的。
八、通过测试确保质量
一些程序员仅在生产中进行测试。 如果您不是其中之一,那么您可能熟悉单元测试的概念。 单元测试是程序员编写的用于测试其代码的自动测试。 例如,这些测试可以单独测试函数或函数的一部分。 每个测试仅覆盖一小部分代码。 这样做的好处是提高了对代码质量,可重复测试的信心,并附带了更清晰的代码。
Python 对单元测试有很好的支持。 此外,NumPy 将numpy.testing包添加到 NumPy 代码单元测试的包中。
测试驱动的开发(TDD)是最重要的事情之一发生在软件开发中。 TDD 将集中在自动化单元测试上。 目标是尽可能自动地测试代码。 下次更改代码时,我们可以运行测试并捕获潜在的回归。 换句话说,任何已经存在的函数仍然可以使用。
本章中的主题包括:
- 单元测试
- 断言
- 浮点精度
断言函数
单元测试通常使用函数,这些函数断言某些内容是测试的一部分。 在进行数值计算时,通常存在一个基本问题,即试图比较几乎相等的浮点数。 对于整数,比较是微不足道的操作,但对于浮点数则不是,因为计算机的表示不准确。 NumPy testing包具有许多工具函数,这些函数可以测试先决条件是否成立,同时考虑到浮点比较的问题。 下表显示了不同的工具函数:
| 函数 | 描述 |
|---|---|
assert_almost_equal() |
如果两个数字不等于指定的精度,则此函数引发异常 |
assert_approx_equal() |
如果两个数字在一定意义上不相等,则此函数引发异常 |
assert_array_almost_equal() |
如果两个数组的指定精度不相等,此函数将引发异常 |
assert_array_equal() |
如果两个数组不相等,此函数将引发异常。 |
assert_array_less() |
如果两个数组的形状不同,并且第一个数组的元素严格小于第二个数组的元素,则此函数引发异常 |
assert_equal() |
如果两个对象不相等,则此函数引发异常 |
assert_raises() |
如果使用定义的参数调用的可调用对象未引发指定的异常,则此函数失败 |
assert_warns() |
如果未抛出指定的警告,则此函数失败 |
assert_string_equal() |
此函数断言两个字符串相等 |
assert_allclose() |
如果两个对象不等于期望的公差,则此函数引发断言 |
实战时间 – 断言几乎相等
假设您有两个几乎相等的数字。 让我们使用assert_almost_equal()函数检查它们是否相等:
-
以较低精度调用函数(最多 7 个小数位):
print("Decimal 6", np.testing.assert_almost_equal(0.123456789, 0.123456780, decimal=7))请注意,不会引发异常,如以下结果所示:
Decimal 6 None -
以更高的精度调用该函数(最多 8 个小数位):
print("Decimal 7", np.testing.assert_almost_equal(0.123456789, 0.123456780, decimal=8))结果如下:
Decimal 7 Traceback (most recent call last):…raise AssertionError(msg) AssertionError: Arrays are not almost equalACTUAL: 0.123456789DESIRED: 0.12345678
刚刚发生了什么?
我们使用了 NumPy testing包中的assert_almost_equal()函数来检查0.123456789和0.123456780对于不同的十进制精度是否相等。
小测验 - 指定小数精度
Q1. assert_almost_equal()函数的哪个参数指定小数精度?
decimalprecisiontolerancesignificant
近似相等的数组
如果两个数字在一定数量的有效数字下不相等,则assert_approx_equal()函数会引发异常。 该函数引发由以下情况触发的异常:
abs(actual - expected) >= 10-(significant - 1)
实战时间 – 断言近似相等
让我们从上一个“实战”部分中选取数字,在它们上应用assert_approx_equal()函数:
-
以低重要性调用函数:
print("Significance 8", np.testing.assert_approx_equal (0.123456789, 0.123456780,significant=8))The result is as follows:
Significance 8 None -
以高重要性调用函数:
print("Significance 9", np.testing.assert_approx_equal (0.123456789, 0.123456780, significant=9))该函数引发一个
AssertionError:Significance 9 Traceback (most recent call last):...raise AssertionError(msg) AssertionError: Items are not equal to 9 significant digits:ACTUAL: 0.123456789DESIRED: 0.12345678
刚刚发生了什么?
我们使用了 NumPy testing包中的assert_approx_equal()函数来检查0.123456789和0.123456780对于不同的十进制精度是否相等。
几乎相等的数组
如果两个数组在指定的精度下不相等,则assert_array_almost_equal()函数会引发异常。 该函数检查两个数组的形状是否相同。 然后,将数组的值与以下元素进行逐元素比较:
|expected - actual| < 0.5 10-decimal
实战时间 – 断言数组几乎相等
通过向每个数组添加0,用上一个“实战时间”部分的值构成数组:
-
以较低的精度调用该函数:
print("Decimal 8", np.testing.assert_array_almost_equal([0, 0.123456789], [0, 0.123456780], decimal=8))The result is as follows:
Decimal 8 None -
以较高的精度调用该函数:
print("Decimal 9", np.testing.assert_array_almost_equal([0, 0.123456789], [0, 0.123456780], decimal=9))测试产生一个
AssertionError:Decimal 9 Traceback (most recent call last):…assert_array_compareraise AssertionError(msg) AssertionError: Arrays are not almost equal(mismatch 50.0%)x: array([ 0\\. , 0.12345679])y: array([ 0\\. , 0.12345678])
刚刚发生了什么?
我们将两个数组与 NumPy array_almost_equal()函数进行了比较。
勇往直前 – 比较不同形状的数组
使用 NumPy array_almost_equal()函数比较具有不同形状的两个数组。
相等的数组
如果两个数组不相等,assert_array_equal()函数将引发异常。 数组的形状必须相等,并且每个数组的元素必须相等。 数组中允许使用 NaN。 或者,可以将数组与array_allclose()函数进行比较。 此函数的参数为绝对公差(atol)和相对公差(rtol)。 对于两个数组a和b,这些参数满足以下方程式:
|a - b| <= (atol + rtol * |b|)
实战时间 – 比较数组
让我们将两个数组与刚才提到的函数进行比较。 我们将重复使用先前“实战”中的数组,并将它们加上 NaN:
-
调用
array_allclose()函数:print("Pass", np.testing.assert_allclose([0, 0.123456789, np.nan], [0, 0.123456780, np.nan], rtol=1e-7, atol=0))The result is as follows:
Pass None -
调用
array_equal()函数:print("Fail", np.testing.assert_array_equal([0, 0.123456789, np.nan], [0, 0.123456780, np.nan]))测试失败,并显示
AssertionError:Fail Traceback (most recent call last):… assert_array_compareraise AssertionError(msg) AssertionError: Arrays are not equal(mismatch 50.0%)x: array([ 0\\. , 0.12345679, nan])y: array([ 0\\. , 0.12345678, nan])
刚刚发生了什么?
我们将两个数组与array_allclose()函数和array_equal()函数进行了比较。
排序数组
如果两个数组不具有相同形状的,并且第一个数组的元素严格小于第二个数组的元素,则assert_array_less()函数会引发异常。
实战时间 – 检查数组顺序
让我们检查一个数组是否严格大于另一个数组:
-
用两个严格排序的数组调用
assert_array_less()函数:print("Pass", np.testing.assert_array_less([0, 0.123456789, np.nan], [1, 0.23456780, np.nan]))The result is as follows:
Pass None -
调用
assert_array_less()函数:print("Fail", np.testing.assert_array_less([0, 0.123456789, np.nan], [0, 0.123456780, np.nan]))该测试引发一个异常:
Fail Traceback (most recent call last):...raise AssertionError(msg) AssertionError: Arrays are not less-ordered(mismatch 100.0%)x: array([ 0\\. , 0.12345679, nan])y: array([ 0\\. , 0.12345678, nan])
刚刚发生了什么?
我们使用assert_array_less()函数检查了两个数组的顺序。
对象比较
如果两个对象不相等,则assert_equal()函数将引发异常。 对象不必是 NumPy 数组,它们也可以是列表,元组或字典。
实战时间 – 比较对象
假设您需要比较两个元组。 我们可以使用assert_equal()函数来做到这一点。
调用assert_equal()函数:
print("Equal?", np.testing.assert_equal((1, 2), (1, 3)))
该调用引发错误,因为项目不相等:
Equal?
Traceback (most recent call last):...raise AssertionError(msg)
AssertionError:
Items are not equal:
item=1ACTUAL: 2DESIRED: 3刚刚发生了什么?
我们将两个元组与assert_equal()函数进行了比较-由于元组彼此不相等,因此引发了一个例外。
字符串比较
assert_string_equal()函数断言两个字符串相等。 如果测试失败,该函数将引发异常,并显示字符串之间的差异。 字符串字符的大小写很重要。
实战时间 – 比较字符串
让我们比较一下字符串。 这两个字符串都是单词NumPy:
-
调用
assert_string_equal()函数将字符串与自身进行比较。 该测试当然应该通过:print("Pass", np.testing.assert_string_equal("NumPy", "NumPy"))测试通过:
Pass None -
调用
assert_string_equal()函数将一个字符串与另一个字母相同但大小写不同的字符串进行比较。 此测试应引发异常:print("Fail", np.testing.assert_string_equal("NumPy", "Numpy"))测试引发错误:
Fail Traceback (most recent call last):…raise AssertionError(msg) AssertionError: Differences in strings: - NumPy? ^ + Numpy? ^
刚刚发生了什么?
我们将两个字符串与assert_string_equal()函数进行了比较。 当外壳不匹配时,该测试引发了异常。
浮点比较
计算机中浮点数的表示形式不准确。 比较浮点数时,这会导致问题。 assert_array_almost_equal_nulp()和assert_array_max_ulp() NumPy 函数提供一致的浮点比较。浮点数的最低精度的单位(ULP),根据 IEEE 754 规范,是基本算术运算所需的半精度。 您可以将此与标尺进行比较。 公制标尺通常具有毫米的刻度,但超过该刻度则只能估计半毫米。
机器ε是浮点算术中最大的相对舍入误差。 机器ε等于 ULP 相对于 1。NumPy finfo()函数使我们能够确定机器ε。 Python 标准库还可以为您提供机器的ε值。 该值应与 NumPy 给出的值相同。
实战时间 – 使用assert_array_almost_equal_nulp来比较
让我们看到assert_array_almost_equal_nulp()函数的作用:
-
使用
finfo()函数确定机器epsilon:eps = np.finfo(float).eps print("EPS", eps)ε将如下所示:EPS 2.22044604925e-16 -
使用
assert_almost_equal_nulp()函数将1.0与1 + epsilon进行比较。 对1 + 2 * epsilon执行相同的操作:print("1", np.testing.assert_array_almost_equal_nulp(1.0, 1.0 + eps)) print("2", np.testing.assert_array_almost_equal_nulp(1.0, 1.0 + 2 * eps))The result is as follows:
1 None 2 Traceback (most recent call last):…assert_array_almost_equal_nulpraise AssertionError(msg) AssertionError: X and Y are not equal to 1 ULP (max is 2)
刚刚发生了什么?
我们通过finfo()函数确定了机器ε。 然后,我们将1.0与1 + epsilon与assert_almost_equal_nulp()函数进行了比较。 但是,该测试通过了,添加另一个ε导致异常。
更多使用 ULP 的浮点比较
assert_array_max_ulp()函数允许您指定允许的 ULP 数量的上限。 maxulp参数接受整数作为限制。 默认情况下,此参数的值为 1。
实战时间 – 使用最大值 2 的比较
让我们进行与先前“实战”部分相同的事情,但在必要时, 指定maxulp为2:
-
使用
finfo()函数确定机器epsilon:eps = np.finfo(float).eps print("EPS", eps)The epsilon would be as follows:
EPS 2.22044604925e-16 -
按照前面的“实战时间”部分中进行的比较,但是将
assert_array_max_ulp()函数与相应的maxulp值一起使用:print("1", np.testing.assert_array_max_ulp(1.0, 1.0 + eps)) print("2", np.testing.assert_array_max_ulp(1.0, 1 + 2 * eps, maxulp=2))输出为 ,如下所示:
1 1.0 2 2.0
刚刚发生了什么?
我们比较了与之前“实战”部分相同的值,但在第二次比较中指定了2的maxulp。 通过将assert_array_max_ulp()函数与适当的maxulp值一起使用,这些测试通过了 ULP 数量返回值。
单元测试
单元测试是自动化测试,它测试一小段代码,通常是函数或方法。 Python 具有用于单元测试的PyUnit API。 作为 NumPy 的用户,我们可以利用之前在操作中看到的assert函数。
实战时间 – 编写单元测试
我们将为一个简单的阶乘函数编写测试 。 测试将检查所谓的快乐路径和异常状况。
-
首先编写阶乘函数:
import numpy as np import unittestdef factorial(n):if n == 0:return 1if n < 0:raise ValueError, "Unexpected negative value"return np.arange(1, n+1).cumprod()该代码使用
arange()和cumprod()函数创建数组并计算累积乘积,但是我们添加了一些边界条件检查。 -
现在我们将编写单元测试。 让我们写一个包含单元测试的类。 它从标准测试 Pytho 的
unittest模块扩展了TestCase类。 测试具有以下三个属性的阶乘函数的调用:-
正数,正确的方式
-
边界条件 0
-
负数,这将导致错误
class FactorialTest(unittest.TestCase):def test_factorial(self):#Test for the factorial of 3 that should pass.self.assertEqual(6, factorial(3)[-1])np.testing.assert_equal(np.array([1, 2, 6]), factorial(3))def test_zero(self):#Test for the factorial of 0 that should pass.self.assertEqual(1, factorial(0))def test_negative(self):#Test for the factorial of negative numbers that should fail.# It should throw a ValueError, but we expect IndexErrorself.assertRaises(IndexError, factorial(-10))如以下输出所示,我们将其中一项测试失败了:
$ python unit_test.py .E. ====================================================================== ERROR: test_negative (__main__.FactorialTest) ---------------------------------------------------------------------- Traceback (most recent call last):File "unit_test.py", line 26, in test_negativeself.assertRaises(IndexError, factorial(-10))File "unit_test.py", line 9, in factorialraise ValueError, "Unexpected negative value" ValueError: Unexpected negative value---------------------------------------------------------------------- Ran 3 tests in 0.003sFAILED (errors=1)
-
刚刚发生了什么?
我们对阶乘函数代码进行了一些满意的路径测试。 我们让边界条件测试故意失败(请参阅unit_test.py):
import numpy as np
import unittestdef factorial(n):if n == 0:return 1if n < 0:raise ValueError, "Unexpected negative value"return np.arange(1, n+1).cumprod()class FactorialTest(unittest.TestCase):def test_factorial(self):#Test for the factorial of 3 that should pass.self.assertEqual(6, factorial(3)[-1])np.testing.assert_equal(np.array([1, 2, 6]), factorial(3))def test_zero(self):#Test for the factorial of 0 that should pass.self.assertEqual(1, factorial(0))def test_negative(self):#Test for the factorial of negative numbers that should fail.# It should throw a ValueError, but we expect IndexErrorself.assertRaises(IndexError, factorial(-10))if __name__ == '__main__':unittest.main()
Nose测试装饰器
鼻子是嘴巴上方的器官,人类和动物用来呼吸和闻味。 它也是一个 Python 框架 ,使(单元)测试变得更加容易。 Nose可帮助您组织测试。 根据nose文档:
“将收集与
testMatch正则表达式(默认值:(?:^|[b_.-])[Tt]est)匹配的任何 python 源文件,目录或包作为测试。”
Nose大量使用装饰器。 Python 装饰器是指示有关方法或函数的注释。 numpy.testing模块具有许多装饰器。 下表显示了numpy.testing模块中的不同装饰器:
| 装饰器 | 描述 |
|---|---|
numpy.testing.decorators.deprecated |
运行测试时,此函数过滤弃用警告 |
numpy.testing.decorators.knownfailureif |
此函数基于条件引发KnownFailureTest异常 |
numpy.testing.decorators.setastest |
此装饰器标记测试函数或未测试函数 |
numpy.testing.decorators.skipif |
此函数根据条件引发一个SkipTest异常 |
numpy.testing.decorators.slow |
此函数将测试函数或方法标记为缓慢 |
另外,我们可以调用decorate_methods()函数将修饰符应用于与正则表达式或字符串匹配的类的方法。
实战时间 – 装饰测试函数
我们将直接将@setastest装饰器应用于测试函数。 然后,我们将相同的装饰器应用于方法以将其禁用。 另外,我们将跳过其中一项测试,并通过另一项测试。 首先,安装nose以防万一。
-
用
setuptools安装nose:$ [sudo] easy_install nose或点子:
$ [sudo] pip install nose -
将一个函数当作测试,将另一个函数当作不是测试:
@setastest(False) def test_false():pass@setastest(True) def test_true():pass -
使用
@skipif装饰器跳过测试。 让我们使用一个总是导致测试被跳过的条件:@skipif(True) def test_skip():pass -
添加一个始终通过的测试函数。 然后,使用
@knownfailureif装饰器对其进行装饰,以使测试始终失败:@knownfailureif(True) def test_alwaysfail():pass -
使用通常应由
nose执行的方法定义一些test类:class TestClass():def test_true2(self):passclass TestClass2():def test_false2(self):pass -
让我们从上一步中禁用第二个测试方法:
decorate_methods(TestClass2, setastest(False), 'test_false2') -
使用以下命令运行测试:
$ nosetests -v decorator_setastest.py decorator_setastest.TestClass.test_true2 ... ok decorator_setastest.test_true ... ok decorator_test.test_skip ... SKIP: Skipping test: test_skipTest skipped due to test condition decorator_test.test_alwaysfail ... ERROR====================================================================== ERROR: decorator_test.test_alwaysfail ---------------------------------------------------------------------- Traceback (most recent call last):File "…/nose/case.py", line 197, in runTestself.test(*self.arg)File …/numpy/testing/decorators.py", line 213, in knownfailerraise KnownFailureTest(msg) KnownFailureTest: Test skipped due to known failure---------------------------------------------------------------------- Ran 4 tests in 0.001sFAILED (SKIP=1, errors=1)
刚刚发生了什么?
我们将某些函数和方法修饰为非测试形式,以便它们被鼻子忽略。 我们跳过了一项测试,也没有通过另一项测试。 我们通过直接使用装饰器并使用decorate_methods()函数(请参见decorator_test.py)来完成此操作:
from numpy.testing.decorators import setastest
from numpy.testing.decorators import skipif
from numpy.testing.decorators import knownfailureif
from numpy.testing import decorate_methods@setastest(False)
def test_false():pass@setastest(True)
def test_true():pass@skipif(True)
def test_skip():pass@knownfailureif(True)
def test_alwaysfail():passclass TestClass():def test_true2(self):passclass TestClass2():def test_false2(self):passdecorate_methods(TestClass2, setastest(False), 'test_false2')
文档字符串
Doctests 是嵌入在 Python 代码中的字符串,类似于交互式会话。 这些字符串可用于测试某些假设或仅提供示例。 numpy.testing模块具有运行这些测试的函数。
实战时间 – 执行文档测试
让我们写一个简单示例,该示例应该计算众所周知的阶乘,但并不涵盖所有可能的边界条件。 换句话说,某些测试将失败。
-
docstring看起来像您在 Python Shell 中看到的文本(包括提示)。 吊装其中一项测试失败,只是为了看看会发生什么:""" Test for the factorial of 3 that should pass. >>> factorial(3) 6 Test for the factorial of 0 that should fail. >>> factorial(0) 1 """ -
编写以下 NumPy 代码行:
return np.arange(1, n+1).cumprod()[-1]我们希望此代码不时出于演示目的而失败。
-
例如,通过在 Python Shell 中调用
numpy.testing模块的rundocs()函数来运行doctest:>>> from numpy.testing import rundocs >>> rundocs('docstringtest.py') Traceback (most recent call last):File "<stdin>", line 1, in <module>File "…/numpy/testing/utils.py", line 998, in rundocsraise AssertionError("Some doctests failed:\\n%s" % "\\n".join(msg)) AssertionError: Some doctests failed: File "docstringtest.py", line 10, in docstringtest.factorial Failed example:factorial(0) Exception raised:Traceback (most recent call last):File "…/doctest.py", line 1254, in __runcompileflags, 1) in test.globsFile "<doctest docstringtest.factorial[1]>", line 1, in <module>factorial(0)File "docstringtest.py", line 13, in factorialreturn np.arange(1, n+1).cumprod()[-1]IndexError: index -1 is out of bounds for axis 0 with size 0
刚刚发生了什么?
我们编写了文档字符串测试,该测试未考虑0和负数。 我们使用numpy.testing模块中的rundocs()函数运行了测试,结果得到了索引错误(请参见docstringtest.py):
import numpy as npdef factorial(n):"""Test for the factorial of 3 that should pass.>>> factorial(3)6Test for the factorial of 0 that should fail.>>> factorial(0)1"""return np.arange(1, n+1).cumprod()[-1]
总结
您在本章中了解了测试和 NumPy 测试工具。 我们介绍了单元测试,文档字符串测试,断言函数和浮点精度。 大多数 NumPy 断言函数都会处理浮点数的复杂性。 我们展示了可以被鼻子使用的 NumPy 装饰器。 装饰器使测试更加容易,并记录了开发人员的意图。
下一章的主题是 matplotlib – Python 科学的可视化和图形化开源库。
九、matplotlib 绘图
matplotlib是一个非常有用的 Python 绘图库。 它与 NumPy 很好地集成在一起,但是是一个单独的开源项目。 您可以在这个页面上找到漂亮的示例。
matplotlib也具有工具函数,可以从 Yahoo Finance 下载和操纵数据。 我们将看到几个股票图表示例。
本章涵盖以下主题:
- 简单图
- 子图
- 直方图
- 绘图自定义
- 三维图
- 等高线图
- 动画
- 对数图
简单绘图
matplotlib.pyplot包包含用于简单绘图的函数。 重要的是要记住,每个后续函数调用都会更改当前图的状态。 最终,我们想要将图保存在文件中,或使用 show()函数显示。 但是,如果我们在 Qt 或 Wx 后端上运行的 IPython 中,则该图将交互更新,而无需等待show()函数。 这与即时输出文本输出的方式相当。
实战时间 – 绘制多项式函数
为了说明绘图的工作原理,让我们显示一些多项式图。 我们将使用 NumPy 多项式函数poly1d()创建一个多项式。
-
将标准输入值作为多项式系数。 使用 NumPy
poly1d()函数创建多项式:func = np.poly1d(np.array([1, 2, 3, 4]).astype(float)) -
使用 NumPy 和
linspace()函数创建x值。 使用-10到10范围,并创建30等距值:x = np.linspace(-10, 10, 30) -
使用我们在第一步中创建的多项式来计算多项式值:
y = func(x) -
调用
plot()函数; 这样不会立即显示图形:plt.plot(x, y) -
使用
xlabel()函数在x轴上添加标签:plt.xlabel('x') -
使用
ylabel()函数在y轴上添加标签:plt.ylabel('y(x)') -
调用
show()函数显示图形:plt.show()以下是具有多项式系数 1、2、3 和 4 的图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Erc0So9V-1681311708264)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_09_01.jpg)]
刚刚发生了什么?
我们在屏幕上显示了多项式的图。 我们在x和y轴上添加了标签(请参见polyplot.py):
import numpy as np
import matplotlib.pyplot as pltfunc = np.poly1d(np.array([1, 2, 3, 4]).astype(float))
x = np.linspace(-10, 10, 30)
y = func(x)plt.plot(x, y)
plt.xlabel('x')
plt.ylabel('y(x)')
plt.show()
小测验 – plot()函数
Q1. plot()函数有什么作用?
- 它在屏幕上显示二维图。
- 它将二维图的图像保存在文件中。
- 它同时执行(1)和(2)。
- 它不执行(1),(2)或(3)。
绘图的格式字符串
plot()函数接受无限数量的参数。 在上一节中,我们给了它两个数组作为参数。 我们也可以通过可选的格式字符串指定线条颜色和样式。 默认情况下,它是蓝色实线,表示为b-,但是您可以指定其他颜色和样式,例如红色破折号。
实战时间 – 绘制多项式及其导数
让我们使用deriv()函数和m作为1绘制多项式及其一阶导数。 我们已经在前面的“实战时间”部分中做了第一部分。 我们希望使用两种不同的线型来识别什么是什么。
-
创建并微分多项式:
func = np.poly1d(np.array([1, 2, 3, 4]).astype(float)) func1 = func.deriv(m=1) x = np.linspace(-10, 10, 30) y = func(x) y1 = func1(x) -
用两种样式绘制多项式及其导数:红色圆圈和绿色虚线。 您无法在本书的印刷版本中看到颜色,因此您将不得不亲自尝试以下代码:
plt.plot(x, y, 'ro', x, y1, 'g--') plt.xlabel('x') plt.ylabel('y') plt.show()具有多项式系数
1,2,3和4的图如下:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aIuUPPeo-1681311708264)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_09_02.jpg)]
刚刚发生了什么?
我们使用两种不同的线型和一次调用plot()函数(请参见polyplot2.py)来绘制多项式及其导数:
import numpy as np
import matplotlib.pyplot as pltfunc = np.poly1d(np.array([1, 2, 3, 4]).astype(float))
func1 = func.deriv(m=1)
x = np.linspace(-10, 10, 30)
y = func(x)
y1 = func1(x)plt.plot(x, y, 'ro', x, y1, 'g--')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
子图
在某一时刻,一个绘图中将有太多的线。 但是,您仍然希望将所有内容组合在一起。 我们可以通过 subplot()函数执行此操作。 此函数在网格中创建多个图。
实战时间 – 绘制多项式及其导数
让我们绘制一个多项式及其一阶和二阶导数。 为了清楚起见,我们将进行三个子图绘制:
-
使用以下代码创建多项式及其导数:
func = np.poly1d(np.array([1, 2, 3, 4]).astype(float)) x = np.linspace(-10, 10, 30) y = func(x) func1 = func.deriv(m=1) y1 = func1(x) func2 = func.deriv(m=2) y2 = func2(x) -
使用
subplot()函数创建多项式的第一个子图。 此函数的第一个参数是行数,第二个参数是列数,第三个参数是以 1 开头的索引号。或者,将这三个参数合并为一个数字,例如311。 子图将组织成三行一列。 为子图命名为Polynomial。 画一条红色实线:plt.subplot(311) plt.plot(x, y, 'r-') plt.title("Polynomial") -
使用
subplot()函数创建一阶导数的第三子图。 为子图命名为First Derivativ。 使用一行蓝色三角形:plt.subplot(312) plt.plot(x, y1, 'b^') plt.title("First Derivative") -
使用
subplot()函数创建第二个导数的第二个子图。 给子图标题为"Second Derivative"。 使用一行绿色圆圈:plt.subplot(313) plt.plot(x, y2, 'go') plt.title("Second Derivative") plt.xlabel('x') plt.ylabel('y') plt.show()多项式系数为 1、2、3 和 4 的三个子图如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sz1xvOYq-1681311708265)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_09_03.jpg)]
刚刚发生了什么?
我们在三行一列中使用三种不同的线型和三个子图绘制了多项式及其一阶和二阶导数(请参见polyplot3.py):
import numpy as np
import matplotlib.pyplot as pltfunc = np.poly1d(np.array([1, 2, 3, 4]).astype(float))
x = np.linspace(-10, 10, 30)
y = func(x)
func1 = func.deriv(m=1)
y1 = func1(x)
func2 = func.deriv(m=2)
y2 = func2(x)plt.subplot(311)
plt.plot(x, y, 'r-')
plt.title("Polynomial")
plt.subplot(312)
plt.plot(x, y1, 'b^')
plt.title("First Derivative")
plt.subplot(313)
plt.plot(x, y2, 'go')
plt.title("Second Derivative")
plt.xlabel('x')
plt.ylabel('y')
plt.show()
财务
matplotlib可以帮助监视我们的股票投资。 matplotlib.finance包具有工具,我们可以使用这些工具从 Yahoo Finance 网站下载股票报价。 然后,我们可以将数据绘制为烛台。
实战时间 – 绘制一年的股票报价
我们可以使用matplotlib.finance包绘制一年的股票报价数据。 这需要连接到 Yahoo Finance,这是数据源。
-
通过从今天减去一年来确定开始日期:
from matplotlib.dates import DateFormatter from matplotlib.dates import DayLocator from matplotlib.dates import MonthLocator from matplotlib.finance import quotes_historical_yahoo from matplotlib.finance import candlestick import sys from datetime import date import matplotlib.pyplot as plt today = date.today() start = (today.year - 1, today.month, today.day) -
我们需要创建所谓的定位器。 来自
matplotlib.dates包的这些对象在x轴上定位了几个月和几天:alldays = DayLocator() months = MonthLocator() -
创建一个日期格式化程序以格式化
x轴上的日期。 此格式化程序创建一个字符串,其中包含月份和年份的简称:month_formatter = DateFormatter("%b %Y") -
使用以下代码从 Yahoo Finance 下载股票报价数据:
quotes = quotes_historical_yahoo(symbol, start, today) -
创建一个
matplotlib Figure对象-这是绘图组件的顶级容器:fig = plt.figure() -
在该图中添加子图:
ax = fig.add_subplot(111) -
将
x轴上的主定位器设置为月份定位器。 此定位器负责x轴上的大刻度:ax.xaxis.set_major_locator(months) -
将
x轴上的次要定位器设置为天定位器。 此定位器负责x轴上的小滴答声:ax.xaxis.set_minor_locator(alldays) -
将
x轴上的主要格式器设置为月份格式器。 此格式化程序负责x轴上大刻度的标签:ax.xaxis.set_major_formatter(month_formatter) -
matplotlib.finance包中的函数使我们可以显示烛台。 使用报价数据创建烛台。 可以指定烛台的宽度。 现在,使用默认值:
```py
candlestick(ax, quotes)
```
- 将
x轴上的标签格式化为日期。 这将旋转标签在x轴上,以使其更适合:
```py
fig.autofmt_xdate()
plt.show()
````DISH`(磁盘网络)的烛台图显示如下: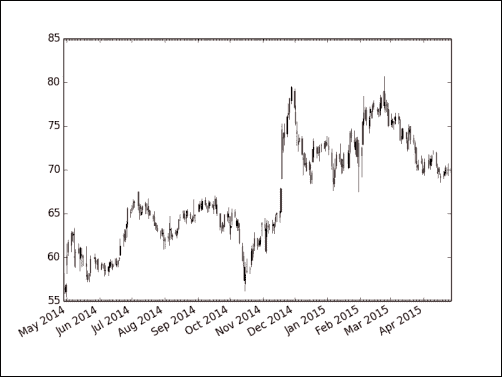
刚刚发生了什么?
我们从 Yahoo Finance 下载了年的数据。 我们使用烛台绘制了这些数据的图表(请参见candlesticks.py):
from matplotlib.dates import DateFormatter
from matplotlib.dates import DayLocator
from matplotlib.dates import MonthLocator
from matplotlib.finance import quotes_historical_yahoo
from matplotlib.finance import candlestick
import sys
from datetime import date
import matplotlib.pyplot as plttoday = date.today()
start = (today.year - 1, today.month, today.day)alldays = DayLocator()
months = MonthLocator()
month_formatter = DateFormatter("%b %Y")symbol = 'DISH'if len(sys.argv) == 2:symbol = sys.argv[1]quotes = quotes_historical_yahoo(symbol, start, today)fig = plt.figure()
ax = fig.add_subplot(111)
ax.xaxis.set_major_locator(months)
ax.xaxis.set_minor_locator(alldays)
ax.xaxis.set_major_formatter(month_formatter)candlestick(ax, quotes)
fig.autofmt_xdate()
plt.show()
直方图
直方图可视化数值数据的分布。 matplotlib具有方便的hist()函数 ,可绘制直方图。 hist()函数有两个主要参数-包含数据和条数的数组。
实战时间 – 绘制股价分布图
让我们绘制 Yahoo Finance 的股票价格 , 的分布图。
-
下载一年前的数据:
today = date.today() start = (today.year - 1, today.month, today.day)quotes = quotes_historical_yahoo(symbol, start, today) -
上一步中的报价数据存储在 Python 列表中。 将其转换为 NumPy 数组并提取收盘价:
quotes = np.array(quotes) close = quotes.T[4] -
用合理数量的条形图绘制直方图:
plt.hist(close, np.sqrt(len(close))) plt.show()DISH 的直方图如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xAqDLUlO-1681311708265)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_09_05.jpg)]
刚刚发生了什么?
我们将 DISH 的股价分布绘制为直方图 (请参见stockhistogram.py):
from matplotlib.finance import quotes_historical_yahoo
import sys
from datetime import date
import matplotlib.pyplot as plt
import numpy as nptoday = date.today()
start = (today.year - 1, today.month, today.day)symbol = 'DISH'if len(sys.argv) == 2:symbol = sys.argv[1]quotes = quotes_historical_yahoo(symbol, start, today)
quotes = np.array(quotes)
close = quotes.T[4]plt.hist(close, np.sqrt(len(close)))
plt.show()
勇往直前 - 画钟形曲线
使用平均价格和标准差覆盖钟形曲线(与高斯或正态分布有关)。 当然只是练习。
对数图
当数据具有较宽范围的值时,对数图很有用。 matplotlib具有函数semilogx()(对数x轴),semilogy()(对数y轴)和loglog()(x和y轴为对数)。
实战时间 – 绘制股票交易量
股票交易量变化很大,因此让我们以对数标度进行绘制。 首先,我们需要从 Yahoo Finance 下载历史数据,提取日期和交易量,创建定位符和日期格式化程序,然后创建图形并将其添加到子图中。 我们已经在上一个“实战时间”部分中完成了这些步骤,因此我们将在此处跳过 。
使用对数刻度绘制体积:
plt.semilogy(dates, volume)
现在,设置定位器并将x轴格式化为日期。 这些步骤的说明也可以在前面的“实战时间”部分中找到。
使用对数刻度的 DISH 的股票交易量显示如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IcdyRtzY-1681311708265)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_09_06.jpg)]
刚刚发生了什么?
我们使用对数比例(参见logy.py)绘制了股票交易量 :
from matplotlib.finance import quotes_historical_yahoo
from matplotlib.dates import DateFormatter
from matplotlib.dates import DayLocator
from matplotlib.dates import MonthLocator
import sys
from datetime import date
import matplotlib.pyplot as plt
import numpy as nptoday = date.today()
start = (today.year - 1, today.month, today.day)symbol = 'DISH'if len(sys.argv) == 2:symbol = sys.argv[1]quotes = quotes_historical_yahoo(symbol, start, today)
quotes = np.array(quotes)
dates = quotes.T[0]
volume = quotes.T[5]alldays = DayLocator()
months = MonthLocator()
month_formatter = DateFormatter("%b %Y")fig = plt.figure()
ax = fig.add_subplot(111)
plt.semilogy(dates, volume)
ax.xaxis.set_major_locator(months)
ax.xaxis.set_minor_locator(alldays)
ax.xaxis.set_major_formatter(month_formatter)
fig.autofmt_xdate()
plt.show()
散点图
散点图在同一数据集中显示两个数值变量的值。 matplotlib scatter()函数创建散点图。 (可选)我们可以在图中指定数据点的颜色和大小以及 alpha 透明度。
实战时间 – 用散点图绘制价格和数量回报
我们可以轻松地绘制股票价格和交易量回报的散点图。 同样,从 Yahoo Finance 下载必要的数据。
-
上一步中的报价数据存储在 Python 列表中。 将此转换为 NumPy 数组并提取关闭和体积值:
dates = quotes.T[4] volume = quotes.T[5] -
计算收盘价和批量收益:
ret = np.diff(close)/close[:-1] volchange = np.diff(volume)/volume[:-1] -
创建一个 matplotlib 图形对象:
fig = plt.figure() -
在该图中添加子图:
ax = fig.add_subplot(111) -
创建散点图,将数据点的颜色链接到收盘价,将大小链接到体积变化:
ax.scatter(ret, volchange, c=ret * 100, s=volchange * 100, alpha=0.5) -
设置图的标题并在其上放置网格:
ax.set_title('Close and volume returns') ax.grid(True)plt.show()DISH 的散点图如下所示:
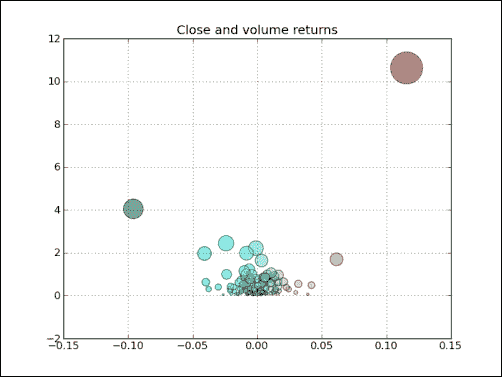
刚刚发生了什么?
我们绘制了 DISH 收盘价和成交量回报的散点图 (请参见scatterprice.py):
from matplotlib.finance import quotes_historical_yahoo
import sys
from datetime import date
import matplotlib.pyplot as plt
import numpy as nptoday = date.today()
start = (today.year - 1, today.month, today.day)symbol = 'DISH'if len(sys.argv) == 2:symbol = sys.argv[1]quotes = quotes_historical_yahoo(symbol, start, today)
quotes = np.array(quotes)
close = quotes.T[4]
volume = quotes.T[5]
ret = np.diff(close)/close[:-1]
volchange = np.diff(volume)/volume[:-1]fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(ret, volchange, c=ret * 100, s=volchange * 100, alpha=0.5)
ax.set_title('Close and volume returns')
ax.grid(True)plt.show()
填充区域
fill_between()函数用指定的颜色填充绘图区域。 我们可以选择一个可选的 Alpha 通道值。 该函数还具有where参数,以便我们可以根据条件对区域进行着色。
实战时间 – 根据条件遮蔽绘图区域
假设您要在股票图表的某个区域遮蔽,该区域的收盘价低于平均水平,而其颜色高于高于均值的颜色。 fill_between()函数是工作的最佳选择。 我们将再次省略以下步骤:下载一年前的历史数据,提取日期和收盘价以及创建定位器和日期格式化程序。
-
创建一个 matplotlib
Figure对象:fig = plt.figure() -
在该图中添加子图:
ax = fig.add_subplot(111) -
绘制收盘价:
ax.plot(dates, close) -
根据值是低于平均价格还是高于平均价格,使用不同的颜色对低于收盘价的地块区域进行阴影处理:
plt.fill_between(dates, close.min(), close, where=close>close.mean(), facecolor="green", alpha=0.4) plt.fill_between(dates, close.min(), close, where=close<close.mean(), facecolor="red", alpha=0.4)现在,我们可以通过设置定位器并将
x轴值格式化为日期来完成绘制,如图所示。 使用 DISH 的条件阴影的股票价格如下:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zdEee7oR-1681311708266)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_09_08.jpg)]
刚刚发生了什么?
我们用与高于均值(请参见fillbetween.py)不同的颜色,来着色股票图表中收盘价低于平均水平的区域:
from matplotlib.finance import quotes_historical_yahoo
from matplotlib.dates import DateFormatter
from matplotlib.dates import DayLocator
from matplotlib.dates import MonthLocator
import sys
from datetime import date
import matplotlib.pyplot as plt
import numpy as nptoday = date.today()
start = (today.year - 1, today.month, today.day)symbol = 'DISH'if len(sys.argv) == 2:symbol = sys.argv[1]quotes = quotes_historical_yahoo(symbol, start, today)
quotes = np.array(quotes)
dates = quotes.T[0]
close = quotes.T[4]alldays = DayLocator()
months = MonthLocator()
month_formatter = DateFormatter("%b %Y")fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(dates, close)
plt.fill_between(dates, close.min(), close, where=close>close.mean(), facecolor="green", alpha=0.4)
plt.fill_between(dates, close.min(), close, where=close<close.mean(), facecolor="red", alpha=0.4)
ax.xaxis.set_major_locator(months)
ax.xaxis.set_minor_locator(alldays)
ax.xaxis.set_major_formatter(month_formatter)
ax.grid(True)
fig.autofmt_xdate()
plt.show()
图例和标注
图例和标注对于良好的绘图至关重要。 我们可以使用legend()函数创建透明的图例,然后让matplotlib找出放置它们的位置。 同样,通过annotate()函数,我们可以准确地在图形上进行标注。 有大量的标注和箭头样式。
实战时间 – 使用图例和标注
在第 3 章,“熟悉常用函数”中,我们学习了如何计算股票价格的 EMA。 我们将绘制股票的收盘价及其三只 EMA 的收盘价。 为了阐明绘图,我们将添加一个图例。 我们还将用标注指示两个平均值的交叉。 为了避免重复,再次省略了某些步骤。
-
返回第 3 章“熟悉常用函数”,如果需要,并查看 EMA 算法。 计算并绘制 9,12 和 15 周期的 EMA:
emas = []for i in range(9, 18, 3):weights = np.exp(np.linspace(-1., 0., i))weights /= weights.sum()ema = np.convolve(weights, close)[i-1:-i+1]idx = (i - 6)/3ax.plot(dates[i-1:], ema, lw=idx, label="EMA(%s)" % (i))data = np.column_stack((dates[i-1:], ema))emas.append(np.rec.fromrecords(data, names=["dates", "ema"]))请注意,
plot()函数调用需要图例标签。 我们将移动平均值存储在记录数组中,以进行下一步。 -
让我们找到前两个移动均线的交叉点:
first = emas[0]["ema"].flatten() second = emas[1]["ema"].flatten() bools = np.abs(first[-len(second):] - second)/second < 0.0001 xpoints = np.compress(bools, emas[1]) -
现在我们有了交叉点,用箭头标注它们。 确保标注文本稍微偏离交叉点:
for xpoint in xpoints:ax.annotate('x', xy=xpoint, textcoords='offset points',xytext=(-50, 30),arrowprops=dict(arrowstyle="->")) -
添加图例,然后让
matplotlib决定将其放置在何处:leg = ax.legend(loc='best', fancybox=True)) -
通过设置 Alpha 通道值使图例透明:
leg.get_frame().set_alpha(0.5)带有图例和标注的股票价格和移动均线如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xa5korC8-1681311708266)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_09_09.jpg)]
刚刚发生了什么?
我们绘制了股票的收盘价及其三个 EMA。 我们在剧情中添加了图例。 我们用标注标注了前两个平均值的交叉点(请参见emalegend.py):
from matplotlib.finance import quotes_historical_yahoo
from matplotlib.dates import DateFormatter
from matplotlib.dates import DayLocator
from matplotlib.dates import MonthLocator
import sys
from datetime import date
import matplotlib.pyplot as plt
import numpy as nptoday = date.today()
start = (today.year - 1, today.month, today.day)symbol = 'DISH'if len(sys.argv) == 2:symbol = sys.argv[1]quotes = quotes_historical_yahoo(symbol, start, today)
quotes = np.array(quotes)
dates = quotes.T[0]
close = quotes.T[4]fig = plt.figure()
ax = fig.add_subplot(111)emas = []
for i in range(9, 18, 3):weights = np.exp(np.linspace(-1., 0., i))weights /= weights.sum()ema = np.convolve(weights, close)[i-1:-i+1]idx = (i - 6)/3ax.plot(dates[i-1:], ema, lw=idx, label="EMA(%s)" % (i))data = np.column_stack((dates[i-1:], ema))emas.append(np.rec.fromrecords(data, names=["dates", "ema"]))first = emas[0]["ema"].flatten()
second = emas[1]["ema"].flatten()
bools = np.abs(first[-len(second):] - second)/second < 0.0001
xpoints = np.compress(bools, emas[1])for xpoint in xpoints:ax.annotate('x', xy=xpoint, textcoords='offset points',xytext=(-50, 30),arrowprops=dict(arrowstyle="->"))leg = ax.legend(loc='best', fancybox=True)
leg.get_frame().set_alpha(0.5)alldays = DayLocator()
months = MonthLocator()
month_formatter = DateFormatter("%b %Y")
ax.plot(dates, close, lw=1.0, label="Close")
ax.xaxis.set_major_locator(months)
ax.xaxis.set_minor_locator(alldays)
ax.xaxis.set_major_formatter(month_formatter)
ax.grid(True)
fig.autofmt_xdate()
plt.show()
三维绘图
三维图非常壮观,因此我们也必须在此处进行介绍。 对于三维图,我们需要一个与3D投影关联的Axes3D对象。
实战时间 – 三维绘图
我们将绘制一个简单的三维函数:
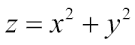
-
使用 3D 关键字为绘图指定三维投影:
ax = fig.add_subplot(111, projection='3d') -
要创建方形二维网格,请使用
meshgrid()函数初始化x和y值:u = np.linspace(-1, 1, 100)x, y = np.meshgrid(u, u) -
我们将为表面图指定行跨度,列跨度和颜色图。 步幅决定了表面砖的尺寸。 颜色图的选择取决于风格:
ax.plot_surface(x, y, z, rstride=4, cstride=4, cmap=cm.YlGnBu_r)结果是以下三维图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x2PgqKeG-1681311708266)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_09_11.jpg)]
刚刚发生了什么?
我们创建了一个三维函数的绘图(请参见three_d.py):
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import cmfig = plt.figure()
ax = fig.add_subplot(111, projection='3d')u = np.linspace(-1, 1, 100)x, y = np.meshgrid(u, u)
z = x 2 + y 2
ax.plot_surface(x, y, z, rstride=4, cstride=4, cmap=cm.YlGnBu_r)plt.show()
等高线图
matplotlib等高线三维图有两种样式-填充的和未填充的。 等高线图使用所谓的等高线。 您可能熟悉地理地图上的等高线。 在此类地图中,等高线连接了海拔相同高度的点。 我们可以使用contour()函数创建法线等高线图。 对于填充的等高线图,我们使用contourf()函数。
实战时间 – 绘制填充的等高线图
我们将在前面的“实战时间”部分中绘制三维数学函数的填充等高线图 。 代码也非常相似。 一个主要区别是我们不再需要3D投影参数。 要绘制填充的等高线图,请使用以下代码行:
ax.contourf(x, y, z)
这为我们提供了以下填充等高线图:
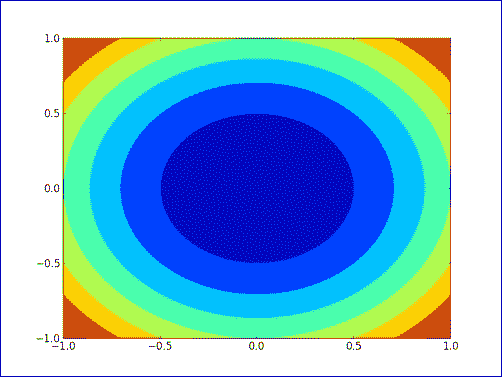
刚刚发生了什么?
我们创建了三维数学函数的填充等高线图(请参见contour.py):
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import cmfig = plt.figure()
ax = fig.add_subplot(111)u = np.linspace(-1, 1, 100)x, y = np.meshgrid(u, u)
z = x 2 + y 2
ax.contourf(x, y, z)plt.show()
动画
matplotlib通过特殊的动画模块提供精美的动画函数。 我们需要定义一个用于定期更新屏幕的回调函数。 我们还需要一个函数来生成要绘制的数据。
实战时间 – 动画绘图
我们将绘制三个随机数据集 ,并将它们显示为圆形,点和三角形。 但是,我们将仅使用随机值更新其中两个数据集。
-
以不同的颜色绘制三个随机数据集,如圆形,点和三角形:
circles, triangles, dots = ax.plot(x, 'ro', y, 'g^', z, 'b.') -
调用此函数可以定期更新屏幕。 使用新的
y值更新两个图:def update(data):circles.set_ydata(data[0])triangles.set_ydata(data[1])return circles, triangles -
使用 NumPy 生成随机数据:
def generate():while True: yield np.random.rand(2, N)以下是运行中的动画的快照:
刚刚发生了什么?
我们创建了一个随机数据点的动画 (请参见animation.py):
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animationfig = plt.figure()
ax = fig.add_subplot(111)
N = 10
x = np.random.rand(N)
y = np.random.rand(N)
z = np.random.rand(N)
circles, triangles, dots = ax.plot(x, 'ro', y, 'g^', z, 'b.')
ax.set_ylim(0, 1)
plt.axis('off')def update(data):circles.set_ydata(data[0])triangles.set_ydata(data[1])return circles, trianglesdef generate():while True: yield np.random.rand(2, N)anim = animation.FuncAnimation(fig, update, generate, interval=150)
plt.show()
总结
本章是关于matplotlib的-Python 绘图库。 我们涵盖了简单图,直方图,图自定义,子图,三维图,等高线图和对数图。 您还看到了一些显示股票走势图的示例。 显然,我们只是刮擦了表面,只是看到了冰山的一角。 matplotlib的功能非常丰富,因此我们没有足够的空间来覆盖 Latex 支持,极坐标支持和其他功能。
matplotlib的作者 John Hunter 于 2012 年 8 月去世。该书的一位技术评论家建议提及John Hunter 纪念基金。 NumFocus 基金会设立的纪念基金为我们(约翰·亨特的工作迷)提供了一个“回馈”的机会。 同样,有关更多详细信息,请查看前面的 NumFocus 网站链接。
下一章将介绍 SciPy,这是一个基于 NumPy 构建的科学 Python 框架。
十、当 NumPy 不够用时 - SciPy 及更多
SciPy 是建立在 NumPy 之上的世界著名的 Python 开源科学计算库。 它增加了一些功能,例如数值积分,优化,统计和特殊函数。
在本章中,我们将介绍以下主题:
- 文件 I/O
- 统计
- 信号处理
- 优化
- 插值
- 图像和音频处理
MATLAB 和 Octave
MATLAB 及其开源替代品 Octave 是流行的数学程序。 scipy.io包具有一些函数,可让您加载 MATLAB 或 Octave 矩阵,以及数字或 Python 程序中的字符串,反之亦然。 loadmat()函数加载.mat文件。 savemat()函数将名称和数组的字典保存到.mat文件中。
实战时间 – 保存并加载.mat文件
如果我们从 NumPy 数组开始并决定在 MATLAB 或 Octave 环境中使用所述数组,那么最简单的方法就是创建一个.mat文件。 然后,我们可以在 MATLAB 或 Octave 中加载文件。 让我们完成必要的步骤:
-
创建一个 NumPy 数组,然后调用
savemat()函数来创建.mat文件。 该函数有两个参数:文件名和包含变量名和值的字典:a = np.arange(7)io.savemat("a.mat", {"array": a}) -
在 MATLAB 或 Octave 环境中,加载
.mat文件并检查存储的数组:octave-3.4.0:7> load a.mat octave-3.4.0:8> aoctave-3.4.0:8> array array =0123456
刚刚发生了什么?
我们从 NumPy 代码创建了一个.mat文件,并将其加载到 Octave 中。 我们检查了创建的 NumPy 数组(请参见scipyio.py):
import numpy as np
from scipy import ioa = np.arange(7)io.savemat("a.mat", {"array": a})
小测验 - 加载.mat文件
Q1. 哪个函数加载.mat文件?
Loadmatlabloadmatloadoctfrommat
统计
SciPy 统计模块为 ,称为scipy.stats。 一类实现连续分布 ,一类实现离散分布。 同样,在此模块中,可以找到执行大量统计检验的函数。
实战时间 – 分析随机值
我们将生成模拟正态分布的随机值,并使用scipy.stats包中的统计函数分析生成的数据。
-
使用
scipy.stats包从正态分布生成随机值:generated = stats.norm.rvs(size=900) -
将生成的值拟合为正态分布。 这基本上给出了数据集的平均值和标准偏差:
print("Mean", "Std", stats.norm.fit(generated))平均值和标准差如下所示:
Mean Std (0.0071293257063200707, 0.95537708218972528) -
偏度告诉我们概率分布有多偏斜(不对称)。执行偏度检验。 该检验返回两个值。 第二个值是 p 值 – 数据集的偏斜度不符合正态分布的概率。
注意
一般而言,p 值是结果与给定零假设所期望的结果不同的概率,在这种情况下,偏度与正态分布(由于对称而为 0)不同的概率。
P 值的范围是
0至1:print("Skewtest", "pvalue", stats.skewtest(generated))偏度检验的结果如下所示:
Skewtest pvalue (-0.62120640688766893, 0.5344638245033837)因此,我们不处理正态分布的可能性为
53% 。 观察如果我们生成更多的点会发生什么,这很有启发性,因为如果我们生成更多的点,我们应该具有更正态的分布。 对于 900,000 点,我们得到0.16的 p 值。 对于 20 个生成的值,p 值为0.50。 -
峰度告诉我们概率分布的弯曲程度。 执行峰度检验。 此检验的设置与偏度检验类似,但当然适用于峰度:
print("Kurtosistest", "pvalue", stats.kurtosistest(generated))峰度检验的结果显示如下:
Kurtosistest pvalue (1.3065381019536981, 0.19136963054975586)900,000 个值的 p 值为
0.028。 对于 20 个生成的值,p 值为0.88。 -
正态检验告诉我们数据集符合正态分布的可能性。 执行正态性检验。 此检验还返回两个值,其中第二个是p值:
print("Normaltest", "pvalue", stats.normaltest(generated))正态性检验的结果如下所示:
Normaltest pvalue (2.09293921181506, 0.35117535059841687)900,000 个生成值的 p 值为
0.035。 对于 20 个生成的值,p 值为0.79。 -
我们可以使用 SciPy 轻松找到某个百分比的值:
print("95 percentile", stats.scoreatpercentile(generated, 95))95th百分位的值显示如下:95 percentile 1.54048860252 -
进行与上一步相反的操作,以找到 1 处的百分位数:
print("Percentile at 1", stats.percentileofscore(generated, 1))1处的百分位数显示如下:Percentile at 1 85.5555555556 -
使用
matplotlib在直方图中绘制生成的值(有关matplotlib的更多信息,请参见前面的第 9 章,
“Matplotlib 绘图”:plt.hist(generated)生成的随机值的直方图如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fcvVXA0f-1681311708267)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_10_01.jpg)]
刚刚发生了什么?
我们从正态分布创建了一个数据集,并使用scipy.stats模块对其进行了分析(请参见statistics.py):
from __future__ import print_function
from scipy import stats
import matplotlib.pyplot as pltgenerated = stats.norm.rvs(size=900)
print("Mean", "Std", stats.norm.fit(generated))
print("Skewtest", "pvalue", stats.skewtest(generated))
print("Kurtosistest", "pvalue", stats.kurtosistest(generated))
print("Normaltest", "pvalue", stats.normaltest(generated))
print("95 percentile", stats.scoreatpercentile(generated, 95))
print("Percentile at 1", stats.percentileofscore(generated, 1))
plt.title('Histogram of 900 random normally distributed values')
plt.hist(generated)
plt.grid()
plt.show()
勇往直前 - 改善数据生成
从前面的“实战时间”部分中的直方图来看,在生成数据方面还有改进的余地。 尝试使用 NumPy 或scipy.stats.norm.rvs()函数的其他参数。
SciKits 样本比较
通常,我们有两个数据样本,可能来自不同的实验,它们之间存在某种关联。 存在可以比较样本的统计检验。 其中一些是在scipy.stats模块中实现的。
我喜欢的另一个统计检验是scikits.statsmodels.stattools的 Jarque-Bera 正态性检验。 SciKit 是小型实验 Python 软件工具箱。 它们不属于 SciPy。 还有 Pandas,这是scikits.statsmodels的分支。 可以在这个页面上找到 SciKit 的列表。 您可以使用安装工具通过以下工具安装statsmodels:
$ [sudo] easy_install statsmodels实战时间 – 比较股票对数收益
我们将使用matplotlib下载两个追踪器的去年股票报价。 如先前的第 9 章,“matplotlib 绘图”,我们可以从 Yahoo Finance 检索报价。 我们将比较DIA和SPY的收盘价的对数回报(DIA 跟踪道琼斯指数; SPY 跟踪 S&P 500 指数)。 我们还将对返回值的差异执行 Jarque–Bera 检验。
-
编写一个可以返回指定股票的收盘价的函数:
def get_close(symbol):today = date.today()start = (today.year - 1, today.month, today.day)quotes = quotes_historical_yahoo(symbol, start, today)quotes = np.array(quotes)return quotes.T[4] -
计算 DIA 和 SPY 的对数返回。 通过采用收盘价的自然对数,然后采用连续值的差来计算对数收益:
spy = np.diff(np.log(get_close("SPY"))) dia = np.diff(np.log(get_close("DIA"))) -
均值比较测试检查两个不同的样本是否可以具有相同的平均值。 返回两个值,第二个是从 0 到 1 的 p 值:
print("Means comparison", stats.ttest_ind(spy, dia))均值比较检验的结果如下所示:
Means comparison (-0.017995865641886155, 0.98564930169871368)因此,这两个样本有大约 98% 的机会具有相同的平均对数回报。 实际上,该文档的内容如下:
注意
如果我们观察到较大的 p 值(例如,大于 0.05 或 0.1),那么我们将无法拒绝具有相同平均分数的原假设。 如果 p 值小于阈值,例如 1% ,5% 或 10% ,则我们拒绝均值的零假设。
-
Kolmogorov–Smirnov 双样本检验告诉我们从同一分布中抽取两个样本的可能性:
print("Kolmogorov smirnov test", stats.ks_2samp(spy, dia))再次返回两个值,其中第二个值为 p 值:
Kolmogorov smirnov test (0.063492063492063516, 0.67615647616238039) -
对对数返回值的差异进行 Jarque–Bera 正态性检验:
print("Jarque Bera test", jarque_bera(spy – dia)[1])Jarque-Bera 正态性检验的 p 值显示如下:
Jarque Bera test 0.596125711042 -
用
matplotlib绘制对数收益的直方图及其差值:plt.hist(spy, histtype="step", lw=1, label="SPY") plt.hist(dia, histtype="step", lw=2, label="DIA") plt.hist(spy - dia, histtype="step", lw=3, label="Delta") plt.legend() plt.show()对数收益和差异的直方图如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-82mE5ncc-1681311708267)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_10_02.jpg)]
刚刚发生了什么?
我们比较了 DIA 和 SPY 的对数回报样本。 另外,我们对对数返回值的差进行了 Jarque-Bera 检验(请参见pair.py):
from __future__ import print_function
from matplotlib.finance import quotes_historical_yahoo
from datetime import date
import numpy as np
from scipy import stats
from statsmodels.stats.stattools import jarque_bera
import matplotlib.pyplot as pltdef get_close(symbol):today = date.today()start = (today.year - 1, today.month, today.day)quotes = quotes_historical_yahoo(symbol, start, today)quotes = np.array(quotes)return quotes.T[4]spy = np.diff(np.log(get_close("SPY")))
dia = np.diff(np.log(get_close("DIA")))print("Means comparison", stats.ttest_ind(spy, dia))
print("Kolmogorov smirnov test", stats.ks_2samp(spy, dia))print("Jarque Bera test", jarque_bera(spy - dia)[1])plt.title('Log returns of SPY and DIA')
plt.hist(spy, histtype="step", lw=1, label="SPY")
plt.hist(dia, histtype="step", lw=2, label="DIA")
plt.hist(spy - dia, histtype="step", lw=3, label="Delta")
plt.xlabel('Log returns')
plt.ylabel('Counts')
plt.grid()
plt.legend(loc='best')
plt.show()
信号处理
scipy.signal模块包含过滤函数和 B 样条插值算法。
注意
样条插值使用称为样条的多项式进行插值 )。 然后,插值尝试将样条线粘合在一起以拟合数据。 B 样条是样条的一种。
SciPy 信号定义为数字数组。 过滤器的一个示例是detrend()函数。 此函数接收信号并对其进行线性拟合。 然后从原始输入数据中减去该趋势。
实战时间 – 检测QQQ趋势
通常对数据样本的趋势比对其去趋势更感兴趣。 在下降趋势之后,我们仍然可以轻松地恢复趋势。 让我们以QQQ的年价格数据为例。
-
编写获取
QQQ收盘价和相应日期的代码:today = date.today() start = (today.year - 1, today.month, today.day)quotes = quotes_historical_yahoo("QQQ", start, today) quotes = np.array(quotes)dates = quotes.T[0] qqq = quotes.T[4] -
消除趋势:
y = signal.detrend(qqq) -
为日期创建月和日定位器:
alldays = DayLocator() months = MonthLocator() -
创建一个日期格式化器,该日期格式化器创建月份名称和年份的字符串:
month_formatter = DateFormatter("%b %Y") -
创建图形和子图:
fig = plt.figure() ax = fig.add_subplot(111) -
通过减去去趋势信号绘制数据和潜在趋势:
plt.plot(dates, qqq, 'o', dates, qqq - y, '-') -
设置定位器和格式化器:
ax.xaxis.set_minor_locator(alldays) ax.xaxis.set_major_locator(months) ax.xaxis.set_major_formatter(month_formatter) -
将 x 轴标签的格式设置为日期:
fig.autofmt_xdate() plt.show()下图显示了带有趋势线的 QQQ 价格:
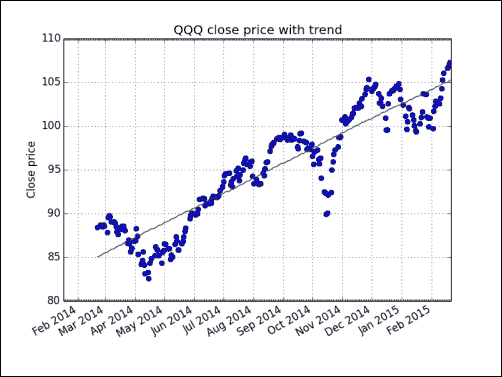
刚刚发生了什么?
我们用趋势线绘制了 QQQ 的收盘价(请参见trend.py):
from matplotlib.finance import quotes_historical_yahoo
from datetime import date
import numpy as np
from scipy import signal
import matplotlib.pyplot as plt
from matplotlib.dates import DateFormatter
from matplotlib.dates import DayLocator
from matplotlib.dates import MonthLocatortoday = date.today()
start = (today.year - 1, today.month, today.day)quotes = quotes_historical_yahoo("QQQ", start, today)
quotes = np.array(quotes)dates = quotes.T[0]
qqq = quotes.T[4]y = signal.detrend(qqq)alldays = DayLocator()
months = MonthLocator()
month_formatter = DateFormatter("%b %Y")fig = plt.figure()
ax = fig.add_subplot(111)plt.title('QQQ close price with trend')
plt.ylabel('Close price')
plt.plot(dates, qqq, 'o', dates, qqq - y, '-')
ax.xaxis.set_minor_locator(alldays)
ax.xaxis.set_major_locator(months)
ax.xaxis.set_major_formatter(month_formatter)
fig.autofmt_xdate()
plt.grid()
plt.show()
傅立叶分析
现实世界中的信号通常具有周期性。 处理这些信号的常用工具是离散傅里叶变换。 离散傅立叶变换是从时域到频域的变换,即将周期信号线性分解为各种频率的正弦和余弦函数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GhTX4VVu-1681311708268)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_10_09.jpg)]
可以在scipy.fftpack模块中找到傅里叶变换的函数(NumPy 也有自己的傅里叶包numpy.fft)。 该包中包括快速傅立叶变换,微分和伪微分运算符,以及一些辅助函数。 MATLAB 用户将很高兴地知道scipy.fftpack模块中的许多函数与 MATLAB 的对应函数具有相同的名称,并且与 MATLAB 的等效函数具有相似的功能。
实战时间 – 过滤去趋势的信号
在前面的“实战时间”部分中,我们学习了如何使信号逆趋势。 该去趋势的信号可以具有循环分量。 让我们尝试将其可视化。 其中一些步骤是前面“实战时间”部分中的步骤的重复,例如下载数据和设置matplotlib对象。 这些步骤在此省略。
-
应用傅立叶变换,得到频谱:
amps = np.abs(fftpack.fftshift(fftpack.rfft(y))) -
滤除噪音。 假设,如果频率分量的幅度低于最强分量的
10% ,则将其丢弃:amps[amps < 0.1 * amps.max()] = 0 -
将过滤后的信号转换回原始域,并将其与去趋势的信号一起绘制:
plt.plot(dates, y, 'o', label="detrended") plt.plot(dates, -fftpack.irfft(fftpack.ifftshift(amps)), label="filtered") -
将 x 轴标签格式化为日期,并添加具有超大尺寸的图例:
fig.autofmt_xdate() plt.legend(prop={'size':'x-large'}) -
添加第二个子图并在过滤后绘制频谱图:
ax2 = fig.add_subplot(212) N = len(qqq) plt.plot(np.linspace(-N/2, N/2, N), amps, label="transformed") -
显示图例和图解:
plt.legend(prop={'size':'x-large'})plt.show()下图是信号和频谱的图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZRtzIWKf-1681311708268)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_10_04.jpg)]
刚刚发生了什么?
我们对信号进行了去趋势处理,然后使用scipy.fftpack模块在其上应用了一个简单的过滤器(请参阅frequencies.py):
from matplotlib.finance import quotes_historical_yahoo
from datetime import date
import numpy as np
from scipy import signal
import matplotlib.pyplot as plt
from scipy import fftpack
from matplotlib.dates import DateFormatter
from matplotlib.dates import DayLocator
from matplotlib.dates import MonthLocatortoday = date.today()
start = (today.year - 1, today.month, today.day)quotes = quotes_historical_yahoo("QQQ", start, today)
quotes = np.array(quotes)dates = quotes.T[0]
qqq = quotes.T[4]y = signal.detrend(qqq)alldays = DayLocator()
months = MonthLocator()
month_formatter = DateFormatter("%b %Y")fig = plt.figure()
fig.subplots_adjust(hspace=.3)
ax = fig.add_subplot(211)ax.xaxis.set_minor_locator(alldays)
ax.xaxis.set_major_locator(months)
ax.xaxis.set_major_formatter(month_formatter)## make font size bigger
ax.tick_params(axis='both', which='major', labelsize='x-large')amps = np.abs(fftpack.fftshift(fftpack.rfft(y)))
amps[amps < 0.1 * amps.max()] = 0plt.title('Detrended and filtered signal')
plt.plot(dates, y, 'o', label="detrended")
plt.plot(dates, -fftpack.irfft(fftpack.ifftshift(amps)), label="filtered")
fig.autofmt_xdate()
plt.legend(prop={'size':'x-large'})
plt.grid()ax2 = fig.add_subplot(212)
plt.title('Transformed signal')
ax2.tick_params(axis='both', which='major', labelsize='x-large')
N = len(qqq)
plt.plot(np.linspace(-N/2, N/2, N), amps, label="transformed")plt.legend(prop={'size':'x-large'})
plt.grid()
plt.tight_layout()
plt.show()
数学优化
优化算法试图找到问题的最佳解决方案,例如,找到函数的最大值或最小值。 该函数可以是线性的或非线性的。 该解决方案也可能具有特殊的约束。 例如,可能不允许解决方案具有负值。 scipy.optimize模块提供了几种优化算法。 算法之一是最小二乘拟合函数leastsq()。 调用此函数时,我们提供了残差(错误项)函数。 此函数可将残差平方和最小化。 它对应于我们的解决方案数学模型。 还必须给算法一个起点。 这应该是一个最佳猜测-尽可能接近真实的解决方案。 否则,将在大约100 * (N+1)次迭代后停止执行,其中 N 是要优化的参数数量。
实战时间 – 正弦拟合
在前面的“实战时间”部分中,我们为脱趋势数据创建了一个简单的过滤器。 现在,让我们使用限制性更强的过滤器,该过滤器将只剩下主要频率分量。 我们将为其拟合正弦波模式并绘制结果。 该模型具有四个参数-幅度,频率,相位和垂直偏移。
-
根据正弦波模型定义残差函数:
def residuals(p, y, x):A,k,theta,b = perr = y-A * np.sin(2* np.pi* k * x + theta) + breturn err -
将过滤后的信号转换回原始域:
filtered = -fftpack.irfft(fftpack.ifftshift(amps)) -
猜猜我们试图估计的从时域到频域的转换的参数值:
N = len(qqq) f = np.linspace(-N/2, N/2, N) p0 = [filtered.max(), f[amps.argmax()]/(2*N), 0, 0] print("P0", p0)初始值如下所示:
P0 [2.6679532410065212, 0.00099598469163686377, 0, 0] -
调用
leastsq()函数:plsq = optimize.leastsq(residuals, p0, args=(filtered, dates)) p = plsq[0] print("P", p)最终参数值如下:
P [ 2.67678014e+00 2.73033206e-03 -8.00007036e+03 -5.01260321e-03] -
用去趋势数据,过滤后的数据和过滤后的数据拟合完成第一个子图。 将日期格式用于水平轴并添加图例:
plt.plot(dates, y, 'o', label="detrended") plt.plot(dates, filtered, label="filtered") plt.plot(dates, p[0] * np.sin(2 * np.pi * dates * p[1] + p[2]) + p[3], '^', label="fit") fig.autofmt_xdate() plt.legend(prop={'size':'x-large'}) -
添加第二个子图,其中包含频谱主要成分的图例:
ax2 = fig.add_subplot(212) plt.plot(f, amps, label="transformed")以下是结果图表:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ucZDBzY0-1681311708268)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_10_05.jpg)]
刚刚发生了什么?
我们降低了 QQQ 一年价格数据的趋势。 然后对该信号进行过滤,直到仅剩下频谱的主要成分。 我们使用scipy.optimize模块(请参见optfit.py)将正弦拟合到过滤后的信号:
from __future__ import print_function
from matplotlib.finance import quotes_historical_yahoo
import numpy as np
import matplotlib.pyplot as plt
from scipy import fftpack
from scipy import signal
from matplotlib.dates import DateFormatter
from matplotlib.dates import DayLocator
from matplotlib.dates import MonthLocator
from scipy import optimizestart = (2010, 7, 25)
end = (2011, 7, 25)quotes = quotes_historical_yahoo("QQQ", start, end)
quotes = np.array(quotes)dates = quotes.T[0]
qqq = quotes.T[4]y = signal.detrend(qqq)alldays = DayLocator()
months = MonthLocator()
month_formatter = DateFormatter("%b %Y")fig = plt.figure()
fig.subplots_adjust(hspace=.3)
ax = fig.add_subplot(211)ax.xaxis.set_minor_locator(alldays)
ax.xaxis.set_major_locator(months)
ax.xaxis.set_major_formatter(month_formatter)
ax.tick_params(axis='both', which='major', labelsize='x-large')amps = np.abs(fftpack.fftshift(fftpack.rfft(y)))
amps[amps < amps.max()] = 0def residuals(p, y, x):A,k,theta,b = perr = y-A * np.sin(2* np.pi* k * x + theta) + breturn errfiltered = -fftpack.irfft(fftpack.ifftshift(amps))
N = len(qqq)
f = np.linspace(-N/2, N/2, N)
p0 = [filtered.max(), f[amps.argmax()]/(2*N), 0, 0]
print("P0", p0)plsq = optimize.leastsq(residuals, p0, args=(filtered, dates))
p = plsq[0]
print("P", p)
plt.title('Detrended and filtered signal')
plt.plot(dates, y, 'o', label="detrended")
plt.plot(dates, filtered, label="filtered")
plt.plot(dates, p[0] * np.sin(2 * np.pi * dates * p[1] + p[2]) + p[3], '^', label="fit")
fig.autofmt_xdate()
plt.legend(prop={'size':'x-large'})
plt.grid()ax2 = fig.add_subplot(212)
plt.title('Tranformed signal')
ax2.tick_params(axis='both', which='major', labelsize='x-large')
plt.plot(f, amps, label="transformed")plt.legend(prop={'size':'x-large'})
plt.grid()
plt.tight_layout()
plt.show()
数值积分
SciPy 具有数值积分包scipy.integrate,在 NumPy 中没有等效项。 quad()函数可以在两个点之间整合一个单变量函数。 这些点可以是无穷大。 该函数使用最简单的数值积分方法:梯形法则。
实战时间 – 计算高斯积分
高斯积分是error()函数相关(在数学上也称为erf),但没有限制。 计算结果为pi的平方根。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JRR1d78K-1681311708269)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_10_10.jpg)]
让我们用quad()函数计算积分(对于导入,请检查代码包中的文件):
print("Gaussian integral", np.sqrt(np.pi),integrate.quad(lambda x: np.exp(-x2), -np.inf, np.inf))
返回值是结果,其错误如下:
Gaussian integral 1.77245385091 (1.7724538509055159, 1.4202636780944923e-08)刚刚发生了什么?
我们使用quad()函数计算了高斯积分。
勇往直前 – 更多实验
试用同一包中的其他集成函数。 只需替换一个函数调用即可。 我们应该得到相同的结果,因此您可能还需要阅读文档以了解更多信息。
插值
插值填充数据集中已知数据点之间的空白。 scipy.interpolate()函数根据实验数据对函数进行插值。 interp1d类可以创建线性或三次插值函数。 默认情况下,会创建线性插值函数,但是如果设置了kind参数,则会创建三次插值函数。 interp2d类的工作方式相同,但是是 2D 的。
实战时间 – 一维内插
我们将使用 sinc()函数创建数据点,并向其中添加一些随机噪声。 之后,我们将进行线性和三次插值并绘制结果。
-
创建数据点并为其添加噪声:
x = np.linspace(-18, 18, 36) noise = 0.1 * np.random.random(len(x)) signal = np.sinc(x) + noise -
创建一个线性插值函数,并将其应用于具有五倍数据点的输入数组:
interpreted = interpolate.interp1d(x, signal) x2 = np.linspace(-18, 18, 180) y = interpreted(x2) -
执行与上一步相同的操作,但使用三次插值:
cubic = interpolate.interp1d(x, signal, kind="cubic") y2 = cubic(x2) -
用
matplotlib绘制结果:plt.plot(x, signal, 'o', label="data") plt.plot(x2, y, '-', label="linear") plt.plot(x2, y2, '-', lw=2, label="cubic") plt.legend() plt.show()下图是数据,线性和三次插值的图形:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ceBSjYe2-1681311708269)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_10_06.jpg)]
刚刚发生了什么?
我们通过sinc()函数创建了一个数据集,并添加了噪声。 然后,我们使用scipy.interpolate模块的interp1d类(请参见sincinterp.py)进行了线性和三次插值 :
import numpy as np
from scipy import interpolate
import matplotlib.pyplot as pltx = np.linspace(-18, 18, 36)
noise = 0.1 * np.random.random(len(x))
signal = np.sinc(x) + noiseinterpreted = interpolate.interp1d(x, signal)
x2 = np.linspace(-18, 18, 180)
y = interpreted(x2)cubic = interpolate.interp1d(x, signal, kind="cubic")
y2 = cubic(x2)plt.plot(x, signal, 'o', label="data")
plt.plot(x2, y, '-', label="linear")
plt.plot(x2, y2, '-', lw=2, label="cubic")plt.title('Interpolated signal')
plt.xlabel('x')
plt.ylabel('y')
plt.grid()
plt.legend(loc='best')
plt.show()
图像处理
使用 SciPy,我们可以使用scipy.ndimage包进行图像处理。 该模块包含各种图像过滤器和工具。
实战时间 - 操纵 Lena
scipy.misc模块是一个加载“Lena”图像的工具。 这是 Lena Soderberg 的图像,传统上用于图像处理示例。 我们将对该图像应用一些过滤器并旋转它。 执行以下步骤以执行 :
-
加载 Lena 图像并将其显示在带有灰度色图的子图中:
image = misc.lena().astype(np.float32) plt.subplot(221) plt.title("Original Image") img = plt.imshow(image, cmap=plt.cm.gray)请注意,我们正在处理
float32数组。 -
中值过滤器扫描图像,并用相邻数据点的中值替换每个项目。 对图像应用中值过滤器,然后在第二个子图中显示它:
plt.subplot(222) plt.title("Median Filter") filtered = ndimage.median_filter(image, size=(42,42)) plt.imshow(filtered, cmap=plt.cm.gray) -
旋转图像并将其显示在第三个子图中:
plt.subplot(223) plt.title("Rotated") rotated = ndimage.rotate(image, 90) plt.imshow(rotated, cmap=plt.cm.gray) -
Prewitt 过滤器基于计算图像强度的梯度。 将 Prewitt 过滤器应用于图像,并在第四个子图中显示它:
plt.subplot(224) plt.title("Prewitt Filter") filtered = ndimage.prewitt(image) plt.imshow(filtered, cmap=plt.cm.gray) plt.show()以下是生成的图像:

刚刚发生了什么?
我们使用 Lena 的图像:
from scipy import misc
import numpy as np
import matplotlib.pyplot as plt
from scipy import ndimageimage = misc.lena().astype(np.float32)plt.subplot(221)
plt.title("Original Image")
img = plt.imshow(image, cmap=plt.cm.gray)
plt.axis("off")plt.subplot(222)
plt.title("Median Filter")
filtered = ndimage.median_filter(image, size=(42,42))
plt.imshow(filtered, cmap=plt.cm.gray)
plt.axis("off")plt.subplot(223)
plt.title("Rotated")
rotated = ndimage.rotate(image, 90)
plt.imshow(rotated, cmap=plt.cm.gray)
plt.axis("off")plt.subplot(224)
plt.title("Prewitt Filter")
filtered = ndimage.prewitt(image)
plt.imshow(filtered, cmap=plt.cm.gray)
plt.axis("off")
plt.show()
音频处理
既然我们已经完成了一些图像处理,那么您也可以使用 WAV 文件来完成令人兴奋的事情,您可能不会感到惊讶。 让我们下载一个 WAV 文件并重播几次。 我们将跳过下载部分的解释,该部分只是常规的 Python。
实战时间 – 重放音频片段
我们将下载 Austin Powers 的 WAV 文件,称为“Smashing baby”。 可以使用scipy.io.wavfile模块中的 read()函数将此文件转换为 NumPy 数组。 相同包中的 write()函数将在本节末尾用于创建新的 WAV 文件。 我们将进一步使用 tile()函数重播音频剪辑几次。
-
使用
read()函数读取文件:sample_rate, data = wavfile.read(WAV_FILE)这给了我们两项–采样率和音频数据。 对于本节,我们仅对音频数据感兴趣。
-
应用
tile()函数:repeated = np.tile(data, 4) -
使用
write()函数编写一个新文件:wavfile.write("repeated_yababy.wav", sample_rate, repeated)下图显示了四次重复的原始音频数据和音频剪辑:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mY4HUYNi-1681311708269)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/numpy-beginners-guide-3e/img/4154_10_08.jpg)]
刚刚发生了什么?
我们读取一个音频剪辑,将其重复四次,然后使用新数组(请参见repeat_audio.py)创建一个新的 WAV 文件:
from __future__ import print_function
from scipy.io import wavfile
import matplotlib.pyplot as plt
import urllib.request
import numpy as npresponse = urllib.request.urlopen('http://www.thesoundarchive.com/austinpowers/smashingbaby.wav')
print(response.info())
WAV_FILE = 'smashingbaby.wav'
filehandle = open(WAV_FILE, 'wb')
filehandle.write(response.read())
filehandle.close()
sample_rate, data = wavfile.read(WAV_FILE)
print("Data type", data.dtype, "Shape", data.shape)plt.subplot(2, 1, 1)
plt.title("Original audio signal")
plt.plot(data)
plt.grid()plt.subplot(2, 1, 2)## Repeat the audio fragment
repeated = np.tile(data, 4)## Plot the audio data
plt.title("Repeated 4 times")
plt.plot(repeated)
wavfile.write("repeated_yababy.wav",sample_rate, repeated)
plt.grid()
plt.tight_layout()
plt.show()
总结
在本章中,我们仅介绍了 SciPy 和 SciKits 可以实现的功能。 尽管如此,我们还是学到了一些有关文件 I/O,统计量,信号处理,优化,插值,音频和图像处理的知识。
在下一章中,我们将使用 Pygame(开源 Python 游戏库)创建一些简单而有趣的游戏。 在此过程中,我们将学习 NumPy 与 Pygame,Scikit 机器学习库,以及其他的集成。