Golang程序报错:fatal error: all goroutines are asleep - deadlock

文章目录
- 1.原始代码
- 2.错误原因分析
- 3. 解决方案
- 4. 经验总结
- 5. 练习
完整的报错信息如下:
fatal error: all goroutines are asleep - deadlock!goroutine 1 [chan receive]:
main.(*WorkerManager).KeepAlive(0xc000088f60)/root/go_workspace/studygoup/05.go:66 +0x59
main.(*WorkerManager).StartWorkPool(0xc000088f60)/root/go_workspace/studygoup/05.go:61 +0xef
main.main()/root/go_workspace/studygoup/05.go:88 +0x47goroutine 18 [chan receive]:
main.(*Worker).Work(0x0?, 0x0?, 0x0?)/root/go_workspace/studygoup/05.go:34 +0xfb
created by main.(*WorkerManager).StartWorkPool/root/go_workspace/studygoup/05.go:58 +0x27
当然这里的文件路径跟你不一样。主要就是fatal error: all goroutines are asleep - deadlock!以及其中的chan receive.
1.原始代码
我是在构建发送任务与任务处理搭配协程池的时候所遇到的。代码架构如下: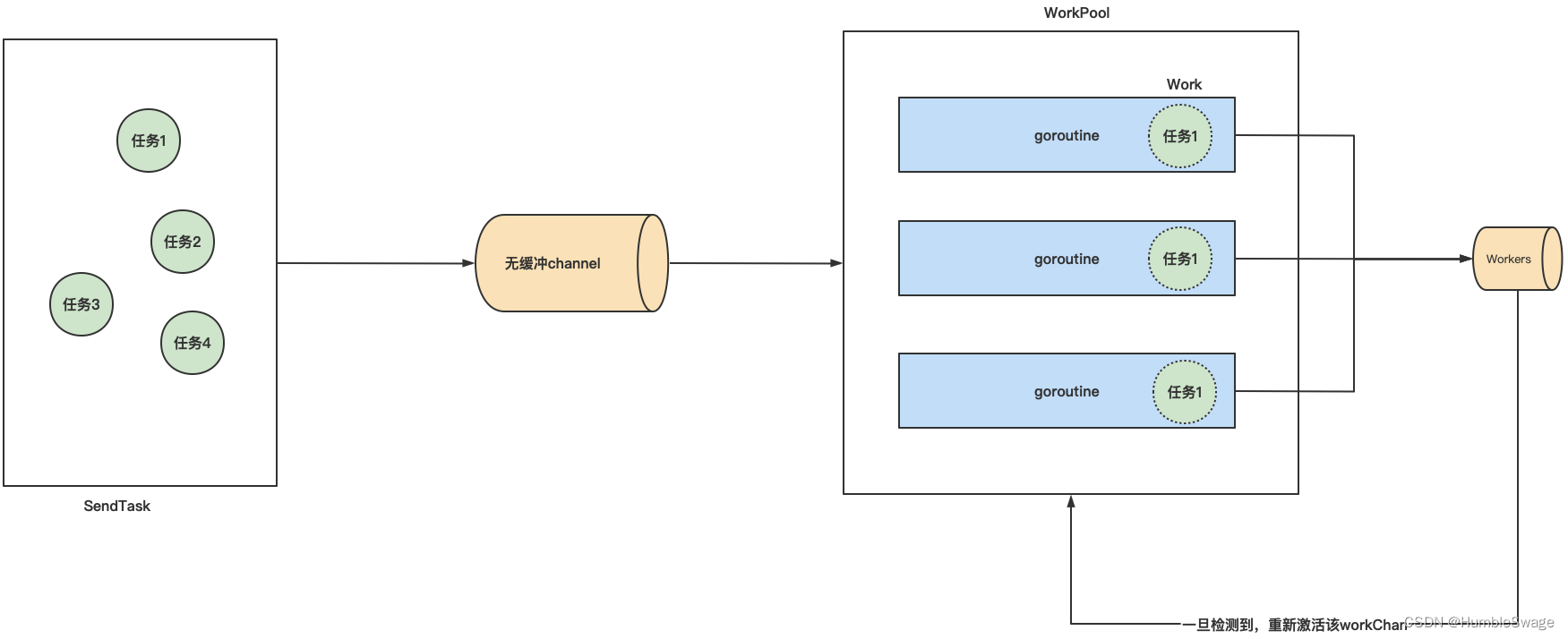
一开始就会生成这样一个workerPool,然后在执行任务的时候,goroutine挂掉了,就会被放进Wokers中,经过检查会被重新放回进WorkerPool中。
完整的代码逻辑如下:
package mainimport ("fmt""math""sync"
)// 创建一个无缓冲的channel
var workChan = make(chan int, 0)type Worker struct {id interr error
}func (w *Worker) Work(c chan int, workers chan *Worker) {defer func() {wg.Done()// 捕获错误if r := recover(); r != nil {// 将错误断言if err, ok := r.(error); ok {w.err = err} else {w.err = fmt.Errorf("panic happened with [%v]", r)}// 通知主goroutine,将死亡的chan加入workers <- w}}()// 模拟业务,这里应该也会阻塞for each := range c {fmt.Println("Task:", each)}
}type WorkerManager struct {Workers chan *WorkernWorkers int
}func NewWorkerManager(num int) *WorkerManager {return &WorkerManager{Workers: make(chan *Worker, num),nWorkers: num,}
}func (wm *WorkerManager) StartWorkPool() {// 开启指定数量的线程池for i := 0; i < wm.nWorkers; i++ {// 先创建一个worker对象wk := &Worker{id: i}go wk.Work(workChan, wm.Workers)}// 协程保活wm.KeepAlive()}func (wm *WorkerManager) KeepAlive() {// 这里会阻塞for wk := range wm.Workers {// log the errorfmt.Printf("Worker %d stopped with err: [%v] \\n", wk.id, wk.err)// reset errwk.err = nil// 当前这个wk已经死亡了,需要重新启动他的业务go wk.Work(workChan, wm.Workers)}
}// 保证所有资源的顺利执行
var wg = sync.WaitGroup{}func SendTask(c chan int, task int) {wg.Add(1)c <- task
}func main() {// 创建线程管理者wm := NewWorkerManager(10)// 开启指定数量的线程池wm.StartWorkPool()// 总的任务数TaskCnt := math.MaxInt64// 依次发送任务for i := 0; i < TaskCnt; i++ {SendTask(workChan, i)}// 等待完成wg.Wait()
}
一旦按照上面的代码执行,就会立即报错!报错信息如最上面的详细信息所示。
2.错误原因分析
- 在
main函数中执行wm.StartWorkPool(),注意在这里是串行执行,也就是说要等wm.StartWorkPool()执行完毕才执行下面一句TaskCnt := math.MaxInt64。 - 然后我们深入
wm.StartWorkPool()会发现,其中没有明显阻塞的地方,而是调用了一个wm.KeepAlive(),其中就是一直监视NewWorkerManager.Workers中是否有被添加worker,即wm.KeepAlive()中语句for wk := range wm.Workers {...,问题就是出现在这里,程序一直在这里阻塞,无法回到main中继续执行,要在后续的Work中才有可能发生向NewWorkerManager.Workers添加操作。因此直接造成了死锁。
3. 解决方案
因为是在wm.StartWorkPool()——> wm.KeepAlive()——>for wk := range wm.Workers {...,最终造成了阻塞,因此我们在这三个中任一个位置开启协程来处理。这里我直接在main函数中使用go wm.StartWorkPool()即可最终解决问题。
func main() {// 创建线程管理者wm := NewWorkerManager(10)// 开启指定数量的线程池go wm.StartWorkPool()// 总的任务数TaskCnt := math.MaxInt64// 依次发送任务for i := 0; i < TaskCnt; i++ {SendTask(workChan, i)}// 等待完成wg.Wait()
}
4. 经验总结
- 先分析可能发生阻塞的地方;【尤其是管道读取的地方】
- 从主函数入手,依次分析并理清阻塞处的逻辑执行顺序;
- 针对一块阻塞处,判断其写操作会不会在其后面,程序永远到不了;
- 理清调用链逻辑,确定协程开启的地方。【开启协程的地方不会阻塞,立即往下执行】
如果实在还无法执行,将你的代码post到评论区,让大家一起帮你解决!
5. 练习
查看下面哪个地方会发生deadlock。该程序使用协程完成1~30的各个数的阶层,并把各个结果放进map中。最后显示出来
package mainimport ("fmt""sync"
)var wg = sync.WaitGroup{}
var mapLock = sync.Mutex{}func Calculate(nums chan int, resMap map[int]uint64) {// 进来会直接阻塞等待for num := range nums {var res uint64 = 1for i := 1; i <= num; i++ {res = res * uint64(i)}// 加锁保证并发的安全mapLock.Lock()// map并发不安全resMap[num] = resmapLock.Unlock()}wg.Done()}func SendTask(c chan int, task int) {wg.Add(1)c <- task
}// 将发送任务与处理任务分开
func main() {// 创建一个无缓冲的管道numsChan := make(chan int)// 创建一个保存结果的mapresMap := make(map[int]uint64)// 开启指定数量的协程for i := 0; i < 3; i++ {go Calculate(numsChan, resMap)}// 循环把各个数据放进管道中for i := 1; i <= 30; i++ {SendTask(numsChan, i)}wg.Wait()fmt.Println(resMap)
}
答案放在评论区