【数据结构】HashMap和HashSet

目录
1、HashMap
1.1 HashMap的简介
1.2 HashMap 部分源码
1.2.1 HashMap 属性
1.2.2 哈希表的构造方法
1.2.3 HashMap 方法
2、HashSet
1、HashMap
1.1 HashMap的简介
- HashMap 的底层就是一个哈希桶,也就是数组加链表的结构,当数组长度达到 64 且链表长度达到 8,则会转换成红黑树
- 因为 HashMap 的底层是一个哈希桶,所以它的插入/删除/查找时间复杂度为 O(1)
- HashMap 不关于 key 有序
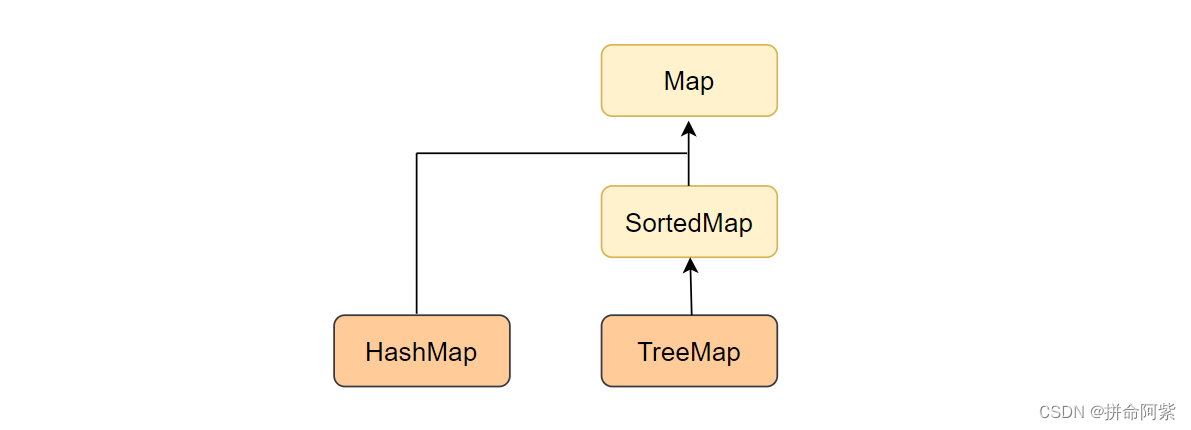
HashMap 并没有继承 SortedMap 接口,所以 key 并不需要重新 CompareTO 方法,因此 HashMap 不关于 key 有序
- 通过哈希函数计算哈希地址
HashMap 并没有继承 SortedMap 接口,所以 key 并不需要重新 CompareTO 方法,key 都不能进行比较了,那如何通过哈希函数计算哈希地址呢?
答:可以通过 hashCode 方法获取到哈希值,从而通过哈希函数计算出哈希地址
- 当 HashMap 中的 key为自定义类型时,自定义类型需要重写 equals 和 hashCode 方法
自定义类型为什么要重写 equals?
答:因为 key 无法进行比较,HashMap 中的 key 必须是唯一的,所以重写 equals 判断是否与 HashMap 中的其它 key 相同
自定义类型为什么要重写 hashCode?
假设我们现在有如下代码:
public class Student {private String name;public Student(String name) {this.name = name;}
}
class Demo {public static void main(String[] args) {Student student1 = new Student("张三");Student student2 = new Student("张三");System.out.println(student1.hashCode());System.out.println(student2.hashCode());}
} 打印结果: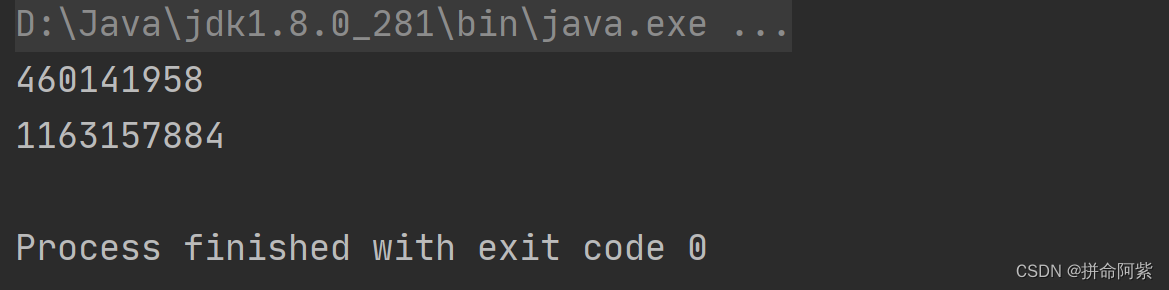
答:明明姓名一样却通过 hashCode 方法得到的哈希值不一样,那么通过哈希函数获取到的位置也就不同了,既然位置都不同了那还如何在同一个链表中判断是否有相同的 key 了咧
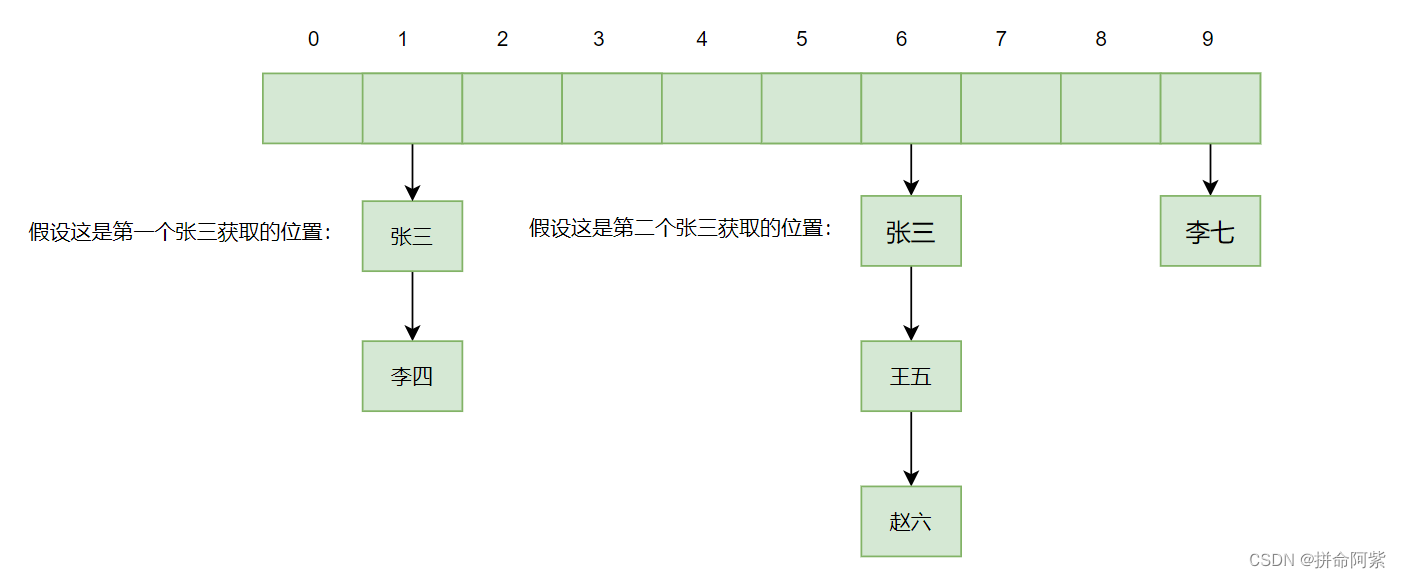
如果像上图这样就无法确定 key 的唯一性
重写 hashCode 的代码:
import java.util.Objects;public class Student {private String name;public Student(String name) {this.name = name;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(name);}
}class Demo {public static void main(String[] args) {Student student1 = new Student("张三");Student student2 = new Student("张三");System.out.println(student1.hashCode());System.out.println(student2.hashCode());}
} 运行结果: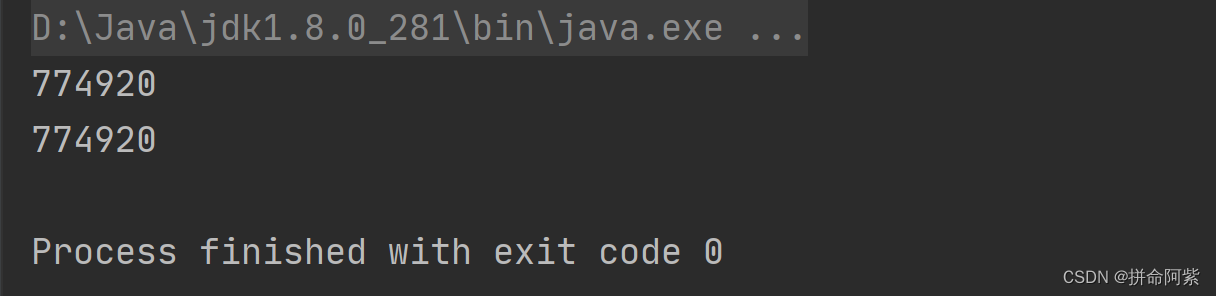
只有获取的 hashCode 值相同才能确定位置相同,那么才能判断是否有相同的 key
那么现在有这样两个问题:
问题一:hashCode相同,equals 就一定相同嘛?
答:不一定,因为 hashCode 只是确定在同一个位置,但是同一个位置中存储的是一个链表,链表中有很多节点,节点中的 key 也是不同的,那么就无法保证 equals 就一定相同
问题二:equals 相同,hashCode 一定相同嘛?
答:一定,因为 equals 相同说明就是一样的 key ,那么 hashCode 获得的位置也就是同一个
1.2 HashMap 部分源码
1.2.1 HashMap 属性
默认初始容量:
最大容量: 
默认的负载因子: 
树化的前提条件:

当链表长度为8时并且数组长度为64时,则会转化成红黑树
解树化(红黑树转链表):
HashMap 的主要存储结构是一个 Node<K,V> 类型的数组:
数组的每个存储单元下存储的都是一个链表
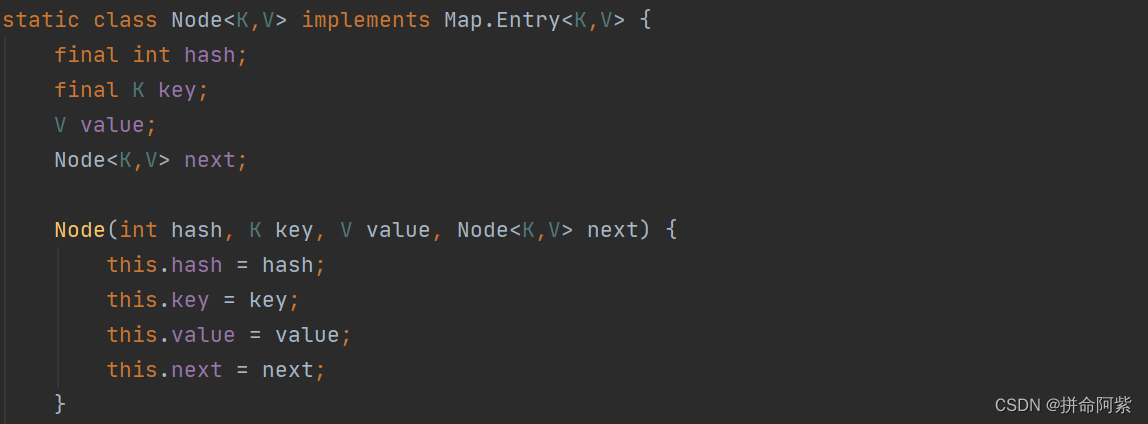
Node是链表的节点结构
记录 HashMap 中的元素个数:
记录当前哈希表的负载因子:
通过当前哈希表的负载因子值与默认负载因子值比较,判断是否需要扩容
1.2.2 哈希表的构造方法
1.无参构造

第一个构造方法无参构造方法,直接将默认负载因子赋值给了当前负载因子
2.构造方法

第二个构造方法是有参构造方法, 将默认负载因子赋值给了当前负载因子,在根据传入的 Map 构造出一个新的 Map
3.构造方法
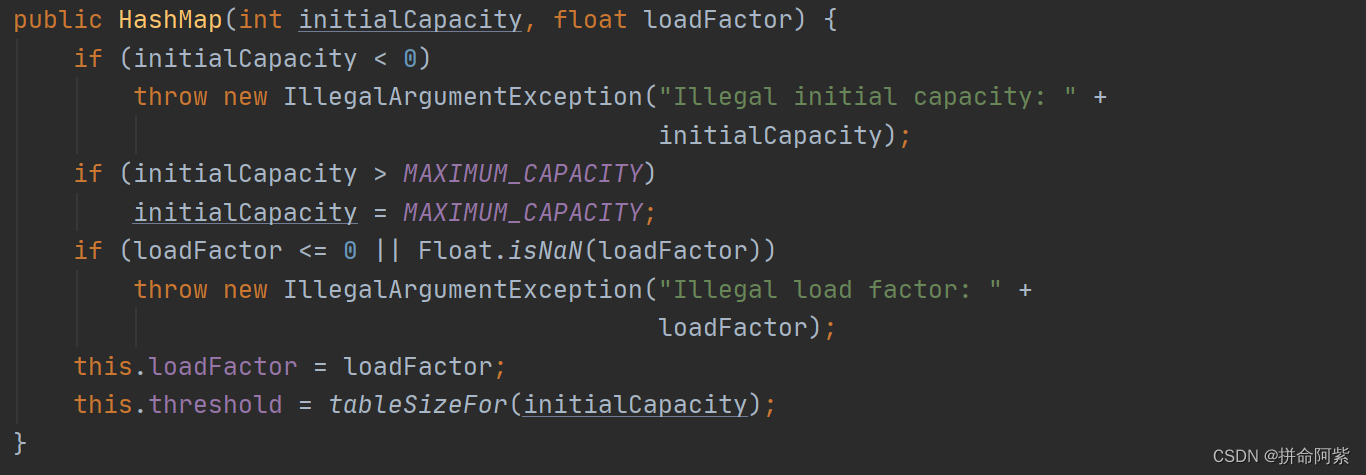
第三个构造方法是有参构造方法,指定容量和自定义负载因子
4.构造方法

第四个构造方法是有参构造方法,它会通过 this 调用第三个构造方法,传入指定容量和默认的负载因子
1.2.3 HashMap 方法
当我们使用不指定容量的构造方法时,也能够成功构造一个 HashMap。当时我们并没有指定容量那么数组容量就为空
但是当我们插入元素的时候也是能够插入成功的,这是为什么呢?
答:既然构造的时候没有开辟容量,那么能够插入元素成功肯定跟 put 方法有关了,那么接下来我们就来从 put 方法中找寻答案
put 方法:

进入 put 方法中,可以发现 put 方法调用了 putValue 方法 ,调用 putValue 方法的时候第一个参数调用了 hash 方法并把我们要插入的 key 传入进去。那么接下来我们先来了解 hash 方法是干嘛的,再看 putValue 方法
hash 方法:

hash方法中判断了,key 是否会 null,如果为 null 则返回 0,否则调用 key 的哈希方法得到的哈希值赋值给 h(如果 key 是自定义类型一定要重写 hashCode 方法,否则就会调用 Object 的hashCode 方法),然后将 h 和 h >>> 16 得到得值进行异或运算得到得结果进行返回
为什么要将 h 和 h >>> 16 得到得值进行异或运算?
答:因为能够将 h 的低16 位和高16 位都参与运算,这样得到的结果更均匀
putValue方法:
putValue 方法比较复杂我们分段来分析

首先定义了 Node<K,V> 类型的数组 tab,Node<K,V> 类型的变量 p,int 类型的变量 n 和 i 。将 table 赋值给 tab ,判断 tab 是否为空或者 tab 数组的长度是否为 0,如果满足则会调用 resize 方法,初始化数组。初始哈希表的长度是 16,临界阈值为 16 * 0.75 = 12,也就是数组元素达到 12个即会扩容
当 HashMap 扩容时,需要注意什么?
答:将里面的元素重新哈希地址
那咱们接着往下看 putValue 方法中的内容

计算插入节点在数组中的插入位置的下标放入 i 中,如果为空则直接插入
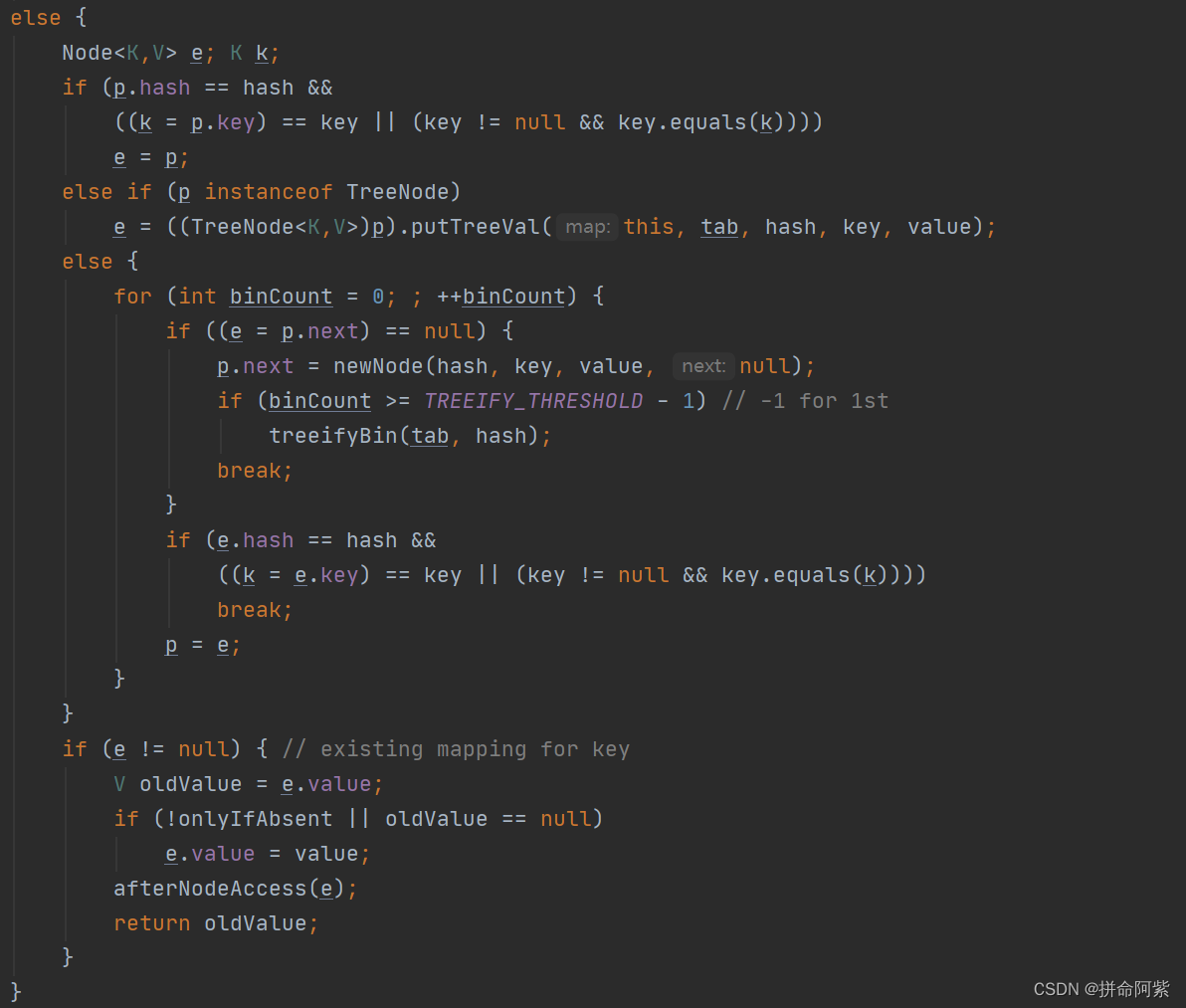
否则说明这个位置不为空,判断当前下标元素的 hash 值是否与我们要插入元素的 hash 值相同,如果相同则判断节点 key 是否存在,如果存在则覆盖当前元素 。如果节点 key 不存在,就会判断下标 i 的位置是不是一棵红黑树节点,如果是则采用红黑树的方式插入元素。如果下标 i 的位置是一个链表,则采用尾插的方式插入节点,在插入的时候会判断是否要转化为红黑树
红黑树里面的元素是可比较的,那么自定义类型并没有重写 CompareTo 怎么办?
答:会按照 key 的哈希值来进行比较,所以就算转换成红黑树也不会关于 key 有序。或者可能只是哈希表中一个下标位置下的结构是红黑树,其他的仍然可能是链表

++modCount 是有效元素个数的自增,判断节点插入后是否需要对数组进行扩容
2、HashSet
HashSet 的底层就是 HashMap,只不过 HashSet 是纯 key 模型的,而 HashMap 是键值对模型的

通过 HashSet 的构造方法就可以证明 HashSet 的底层就是 HashMap
add 方法:


当对 HashSet 插入元素的时候,value 会给一个默认值