【Python_Selenium学习笔记(二)】基于Selenium模块实现网络爬虫

基于Selenium模块实现网络爬虫
前言
此篇文章主要介绍如何使用 Selenium 模块进行简单的网络爬虫,并以具体的示例进行展示。
正文
1、需求梳理
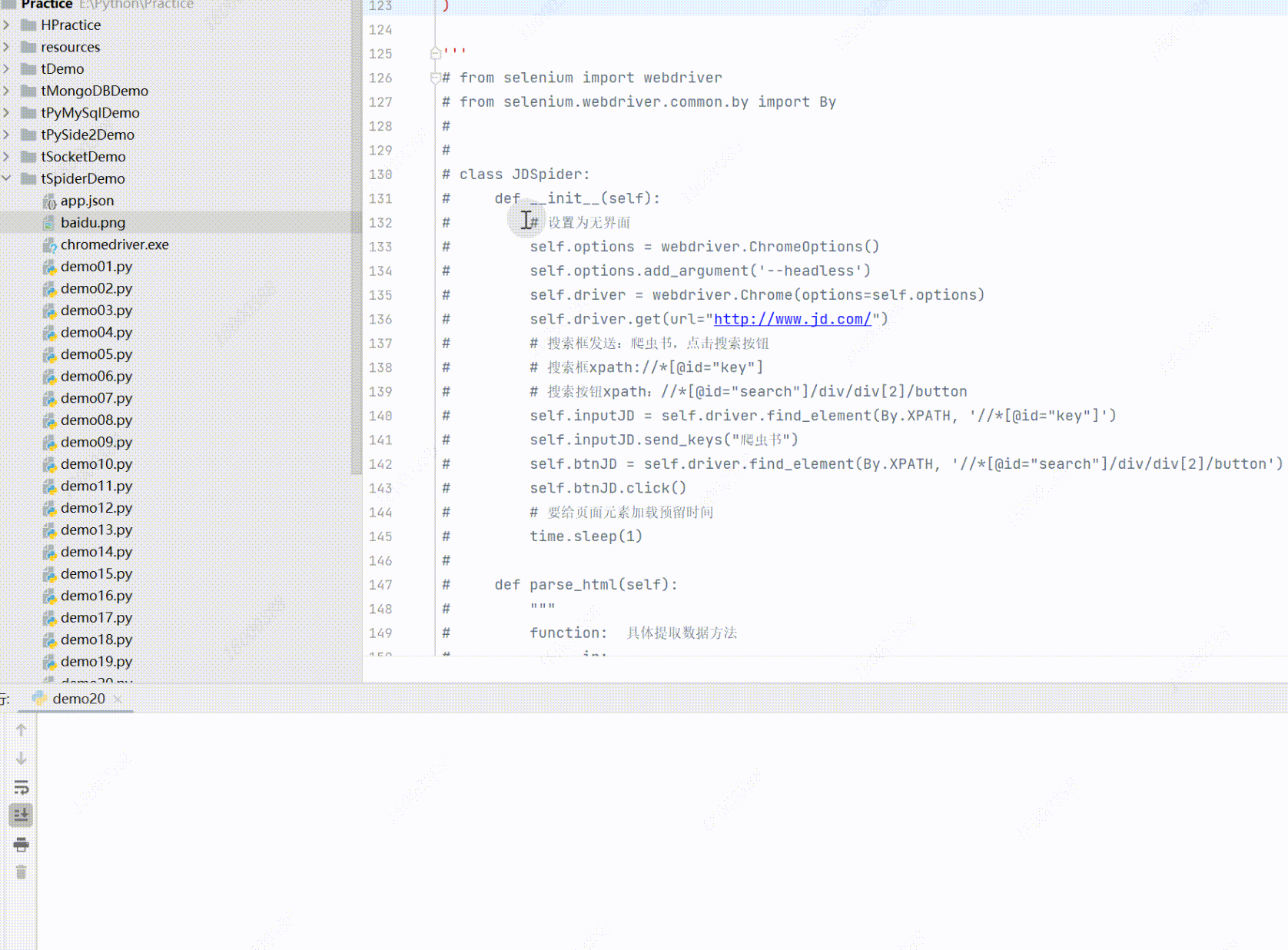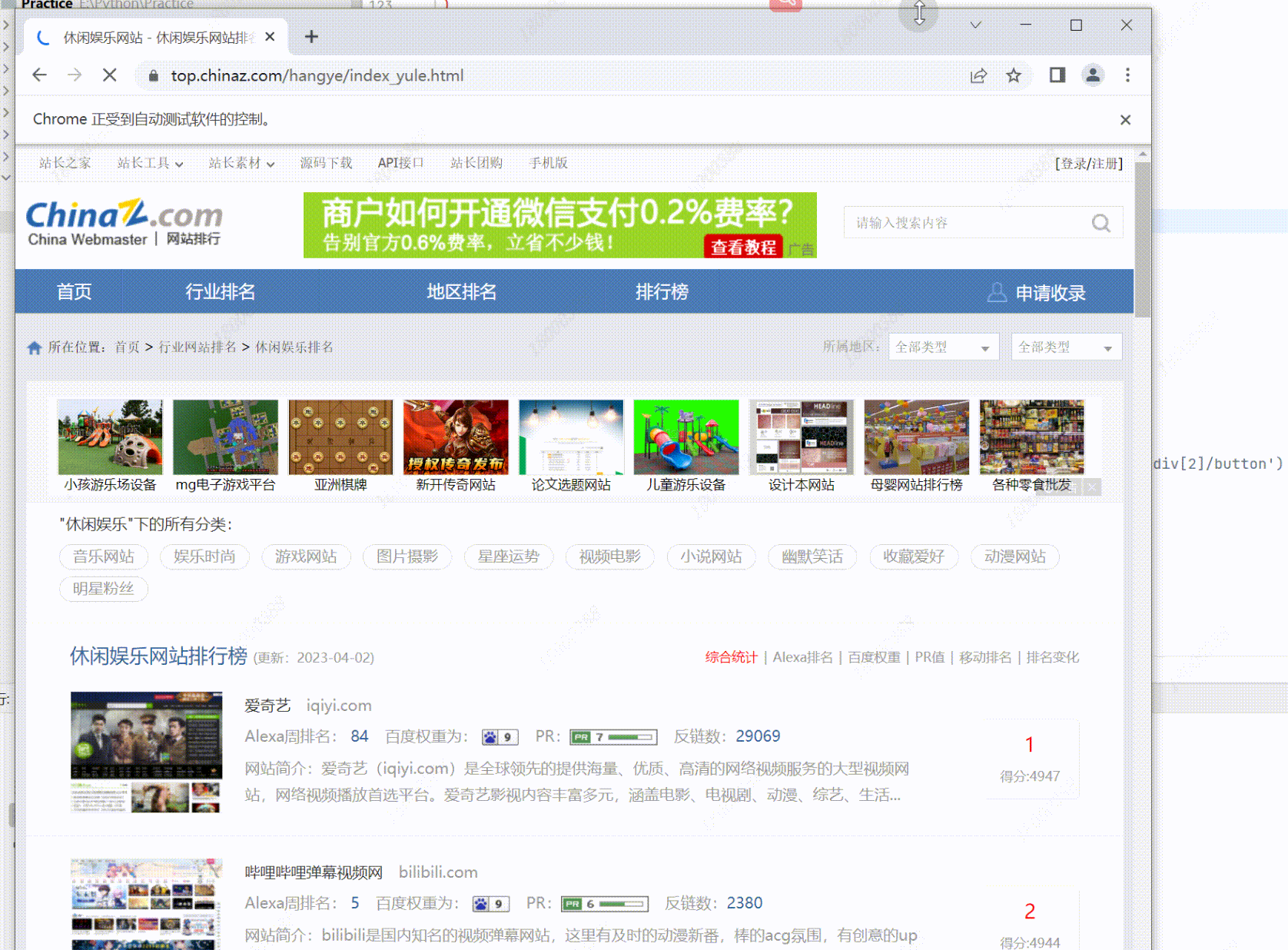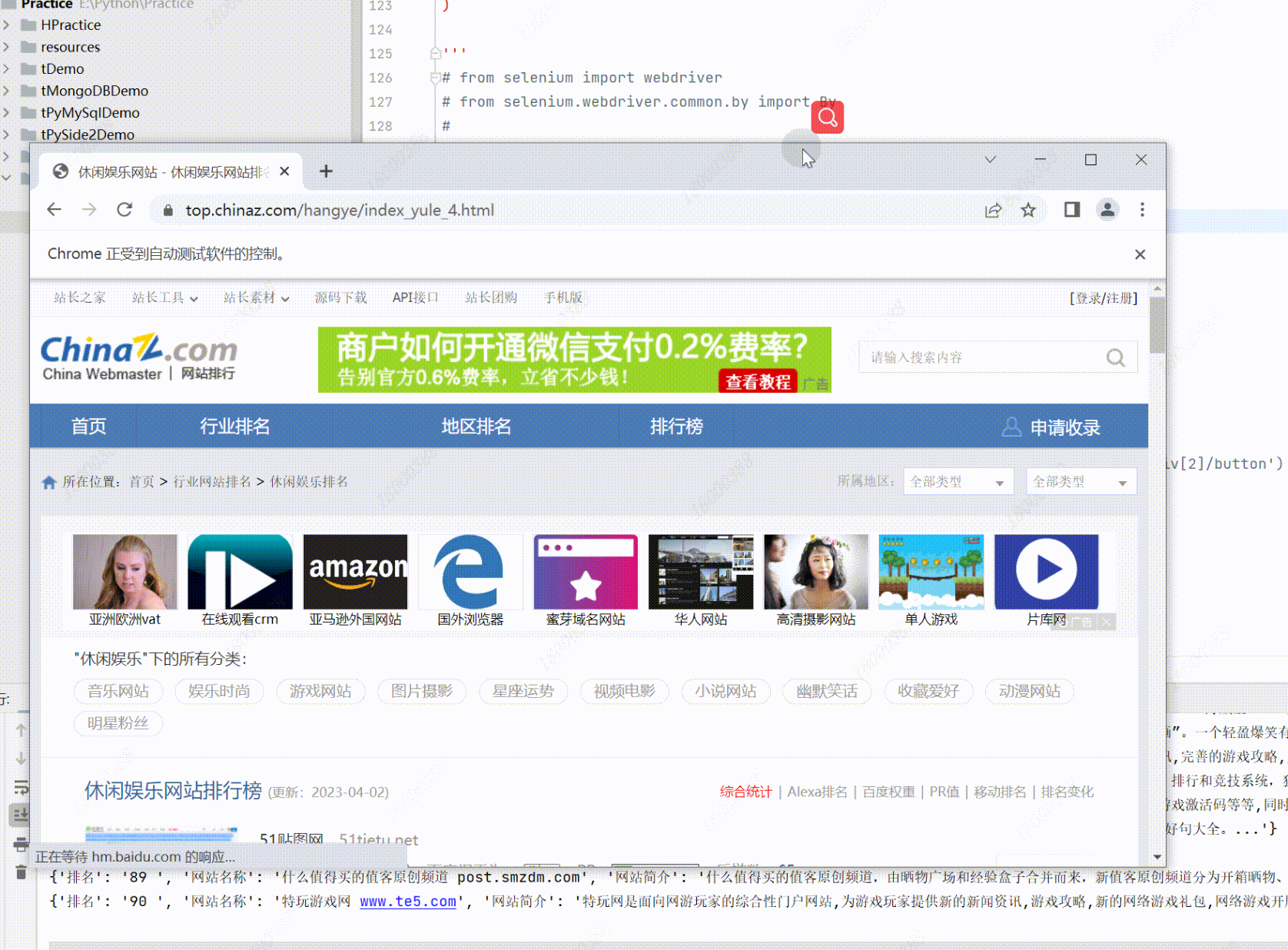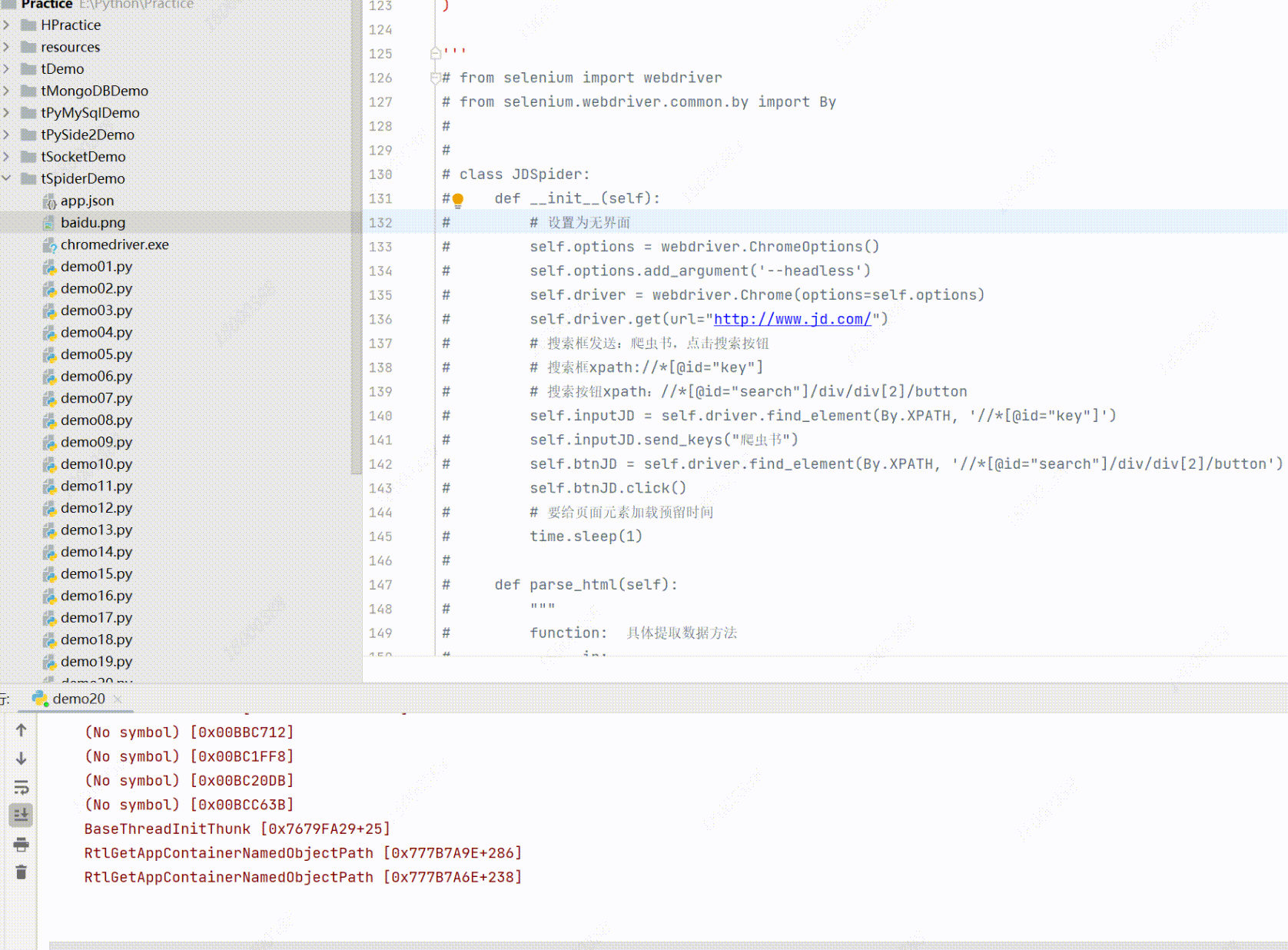
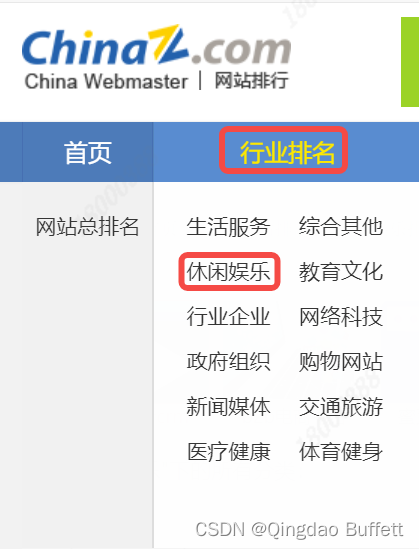
基于 Selenium + Chrome 抓取 中国排行网-行业排名-休闲娱乐下的网站信息
2、爬虫思路
-
打开浏览器输入 Top100 主页地址
https://top.chinaz.com/hangye/index_yule.html; -
使用 Selenium 的 Xpath 找到 行业网站信息 节点对象列表;
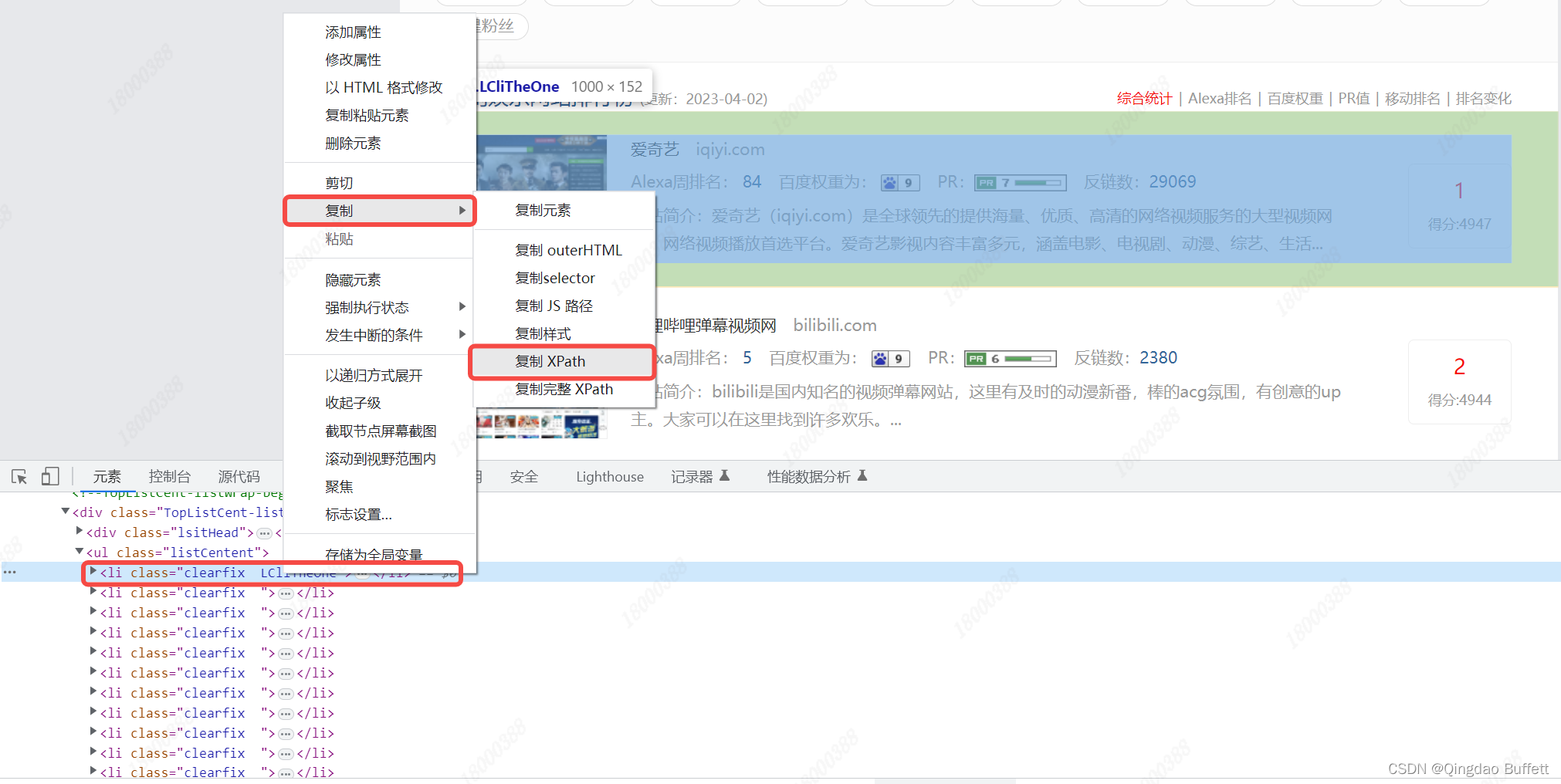
//*[@id="content"]/div[4]/div[3]/div[2]/ul/li[1] -
依次遍历每个元素,并依次提取每个行业网站信息;
-
可利用 find_element(By.PARTIAL_LINK_TEXT, “”) 方法 判断是否为最后一页。

3、程序实现
- 创建浏览器对象:
browser = webdriver.Chrome() # 构造浏览器对象,打开浏览器
browser.get(url="https://top.chinaz.com/hangye/index_yule.html") # 进入主页
- 编写获取一页数据的函数
def get_one_page():"""function: 获取一页数据的函数in: Noneout: Nonereturn: Noneothers: Get One Page Data Func"""li_list = browser.find_elements(By.XPATH,'//*[@id="content"]/div[4]/div[3]/div[2]/ul/li') # 基准的xpath:匹配每个行业网站信息的节点对象列表item = {} # 定义一个空字典for li in li_list:one_info_list = li.text.split("\\n") # text属性:获取当前节点以及其子节点和后代节点的文本内容item['排名'] = one_info_list[6].strip().split('得分:')[0]item['网站名称'] = one_info_list[0].strip()item['网站简介'] = one_info_list[5].strip().split('网站简介:')[1]print(item) # 打印
- while 循环抓取
while True:get_one_page() # 调用 获取一页数据的函数try:# selenium 在找节点时,如果找不到,会抛出异常browser.find_element(By.PARTIAL_LINK_TEXT, ">").click() # 看是否能找到'>'的except Exception as e:browser.quit() # 退出浏览器break
4、完整代码
from selenium import webdriver
from selenium.webdriver.common.by import Bybrowser = webdriver.Chrome() # 构造浏览器对象,打开浏览器
browser.get(url="https://top.chinaz.com/hangye/index_yule.html") # 进入主页def get_one_page():"""function: 获取一页数据的函数in: Noneout: Nonereturn: Noneothers: Get One Page Data Func"""li_list = browser.find_elements(By.XPATH,'//*[@id="content"]/div[4]/div[3]/div[2]/ul/li') # 基准的xpath:匹配每个行业网站信息的节点对象列表item = {} # 定义一个空字典for li in li_list:one_info_list = li.text.split("\\n") # text属性:获取当前节点以及其子节点和后代节点的文本内容item['排名'] = one_info_list[6].strip().split('得分:')[0]item['网站名称'] = one_info_list[0].strip()item['网站简介'] = one_info_list[5].strip().split('网站简介:')[1]print(item) # 打印while True:get_one_page() # 调用 获取一页数据的函数try:# selenium 在找节点时,如果找不到,会抛出异常browser.find_element(By.PARTIAL_LINK_TEXT, ">").click() # 看是否能找到'>'的except Exception as e:browser.quit() # 退出浏览器break5、实现效果