Word2Vec Efficient Estimation of Word Representations inVector Space论文笔记

Title
Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.
Summary
Word2vec是一种基于神经网络的自然语言处理技术,用于将单词表示为向量。这种技术的最大好处是它能够理解单词之间的语义和上下文关系。Word2vec是由Google在2013年首次推出的,从那时起就被广泛应用于各种自然语言处理任务中。
Word2vec的核心思想是将单词表示为向量,使得这些向量能够反映单词的语义和关联性。这些向量可以用于许多自然语言处理任务,如文本分类、命名实体识别、情感分析等。Word2vec使用了两种不同的算法,分别是连续词袋模型(CBOW)和Skip-gram模型。
CBOW模型是一种基于上下文预测目标单词的算法。它根据周围单词的上下文环境来预测当前单词的向量表示。Skip-gram模型与CBOW相反,它是基于目标单词来预测周围上下文单词的向量表示。这两种算法都是基于神经网络的方法,使用了反向传播算法来训练模型。
Word2vec具有许多优点。首先,它能够处理大型数据集,因为它使用了高效的并行计算方法。其次,它能够处理大量的单词,因为它使用了稠密向量表示。最后,Word2vec能够处理长文本,因为它使用了滑动窗口方法。
总的来说,Word2vec是一种非常有用的自然语言处理技术,它可以将单词表示为向量,从而使得单词能够反映其语义和关联性。这种技术已被广泛应用于各种自然语言处理任务中,并且它将在未来的自然语言处理领域中扮演越来越重要的角色。
#ImportantPaper
Research Objective
作者的研究目标。
研究一种编码方法,将词映射到高维空间,实现词之间的相似性和相异性,研究单词之间的语义和上下文关系。

Problem Statement
解决词编码的问题,得到更好的特征空间。
比如King,Man,Woman这3个词,King和Man的特征需要接近,Woman的特征差异会更大。

Method(s)
解决问题的方法/算法是什么?
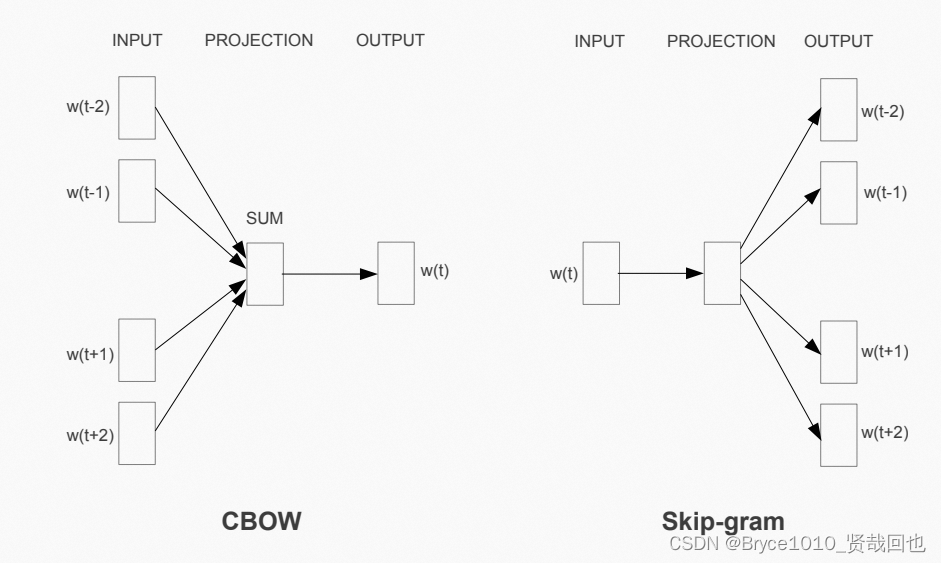
CBOW
通过周围的词,预测中心的词。

Skipgram
绿色是输入词,通过中心词去预测周围的词。

通过这样的数据,进行训练。

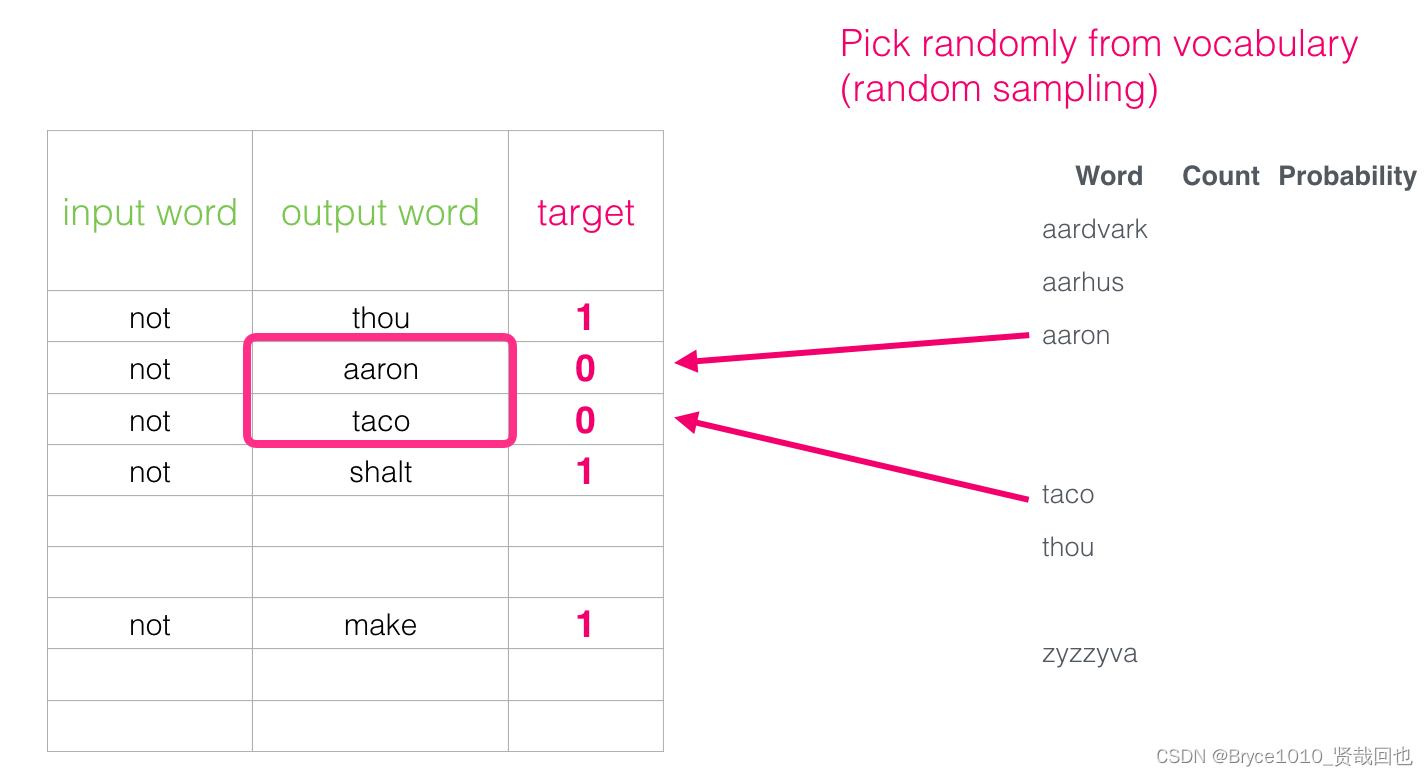
负采样
通过计算两个词的相似度:

引入一些负样本样例,降低模型过拟合。
Refs
- Jay Alammar. The Illustrated Word2vec. Blog. 2019.04