因果推断10--一种大规模预算约束因果森林算法(LBCF)

论文:A large Budget-Constrained Causal Forest Algorithm
论文:http://export.arxiv.org/pdf/2201.12585v2.pdf
目录
0 摘要
1 介绍
2 问题的制定
3策略评价
4 方法
4.1现有方法的局限性。
4.2提出的LBCF算法
5验证
5.1合成数据
5.2离线生成TestRCT数据。
5.3在线AB测试设置
6预算受限的治疗选择
7结论
8阅读理解
Readme
0 摘要
向用户提供奖励(例如亚马逊的优惠券,优步的折扣和抖音的视频奖金)是在线平台用来提高用户粘性和平台收入的常用策略。尽管这些营销激励已被证明是有效的,但如果使用不当,会产生不可避免的成本,并可能导致低ROI(投资回报)。另一方面,不同的用户对这些激励措施的反应不同,例如,有些用户从未在没有优惠券的情况下购买某些产品,而另一些用户则无论如何都会购买。因此,如何在预算限制下为每个用户选择合适的激励(即待遇)是一个具有重大现实意义的重要研究问题。在本文中,我们称这种问题为预算约束的治疗选择问题。挑战是如何有效地解决大规模数据集上的BTS问题,并获得比现有技术更好的结果。本文提出了一种预算约束下基于树的治疗选择算法,称为大规模预算约束因果森林(large BudgetConstrained Causal Forest, LBCF)算法,该算法也是一种适用于现代分布式计算系统的有效治疗选择算法。本文还提出了一种新的离线评估方法,以克服在随机对照试验(RCT)数据中评估BTS问题解决方案性能的内在挑战。我们将我们的方法部署在一个大型视频平台的现实场景中,该平台为了增加用户的活动参与时间而赠送奖金。仿真分析、离线和在线实验都表明,我们的方法优于各种基于树的最先进的基线1。该提议的方法目前正在为平台上的数亿用户提供服务,并在这几个月里实现了最大的改进之一。
KEYWORDS:Personalization, Heterogeneous causal effects, Constraint optimization, Treatment Selection, Distributed Computing
关键词个性化,异质因果效应,约束优化,处理选择,分布式计算
1 介绍
通过赠送奖励来开展营销活动是提高用户粘性和平台收入的一种流行而有效的方式,例如共享出行中的折扣[13](优步[31],滴滴)和电子商务中的优惠券[29](阿里巴巴[29],Booking.com[6,14])。
在工业环境中,这些营销活动受到有限的预算限制,因此有效地分配有限的激励至关重要。其中最具挑战性的任务是识别具有异质性的目标用户,即不同用户对不同级别的优惠券(如9折,8折等)的反应不同。换句话说,一些用户在没有优惠券的情况下从不购买某些产品,而另一些用户则会购买。因此,研究如何将有限的激励预算分配给具有异质性的用户,以最大化整体回报(如用户粘性、平台收益等)是一个重要的研究问题。最近的研究开始使用因果分析框架来解决这一问题,将激励和回报分别视为“治疗”和“结果”。在本文中,我们将这类问题视为预算约束的治疗选择问题(BTS)。
方法:现有的许多技术都可以解决BTS问题。挑战是如何有效地解决大规模数据集上的BTS问题,并获得比现有技术更好的结果。本文主要研究基于树的技术,因为它在工业上具有良好的性能。这些技术可以分为两类。
第一类是带贪婪处理选择的隆起随机森林。在得到所有处理的异质处理效果(本文中处理效果和隆升是可交换的)估计后,这些解,如隆升随机森林,在上下文治疗选择(Contextual Treatment Selection, CTS)[30]上,只需为每个用户选择治疗效果最大的治疗[7,17]。我们称这种治疗选择策略为贪婪治疗选择策略。在4.1.1节中,通过一个简单的例子,我们证明了这种贪婪的处理选择策略对于BTS问题是次优的。
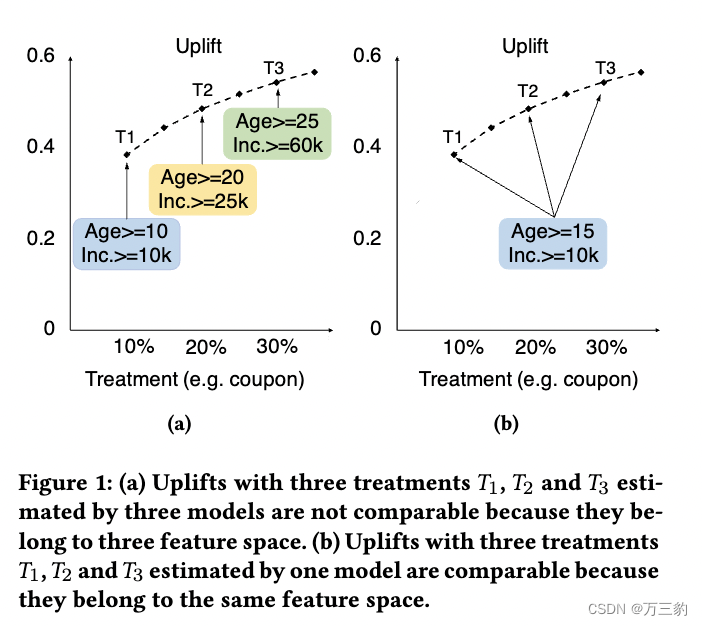
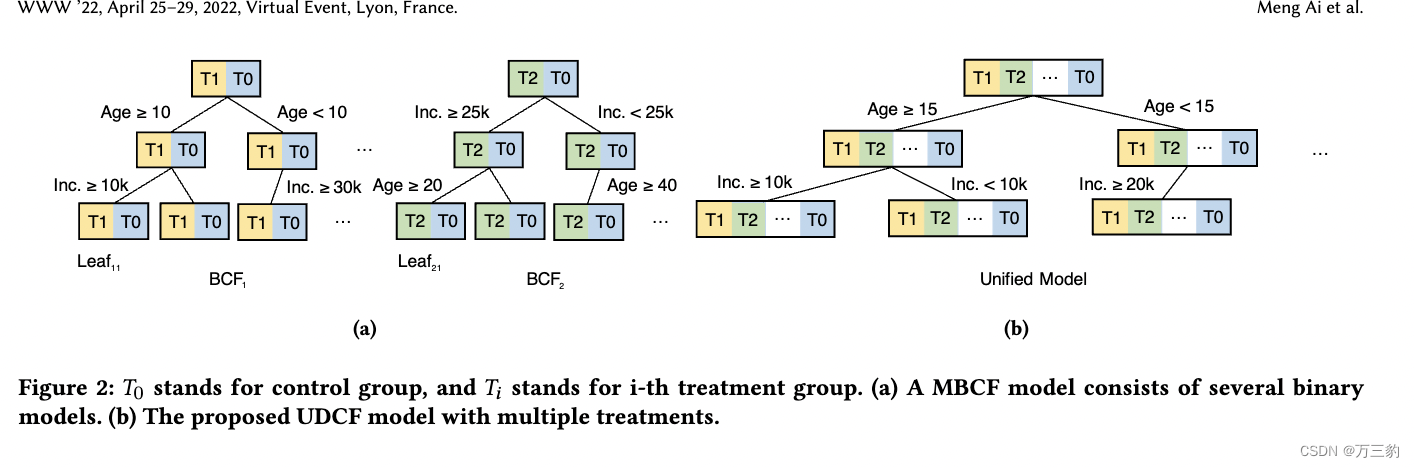
第二类是Tu等人最近提出的最优治疗选择算法[26]。该算法有两个局限性,特别是对于大规模的BTS问题。首先,在大规模数据集上,由于缺乏大规模线性规划优化求解器,作者建议采用队列级优化代替成员级优化。其次,为了利用二元因果森林(见Athey et al. [2]) (BCF)实现多处理效果估计,Tu et al.[26]提出分别训练多个二元因果森林(MBCF),每个BCF对应一个处理。尽管如此,在这种分治方法中,用户可能属于每个二进制模型中的不同叶节点(见图2a)。因此,在估计不同处理的处理效果或提升时,我们正在观察不同的特征空间(见图1a)。因此,所获得的治疗效果在不同治疗之间没有严格的可比性。此外,如果我们有多个模型同时服务,它是计算消耗和难以维护。
在本文中,我们提出了一种大规模预算约束因果森林(LBCF)算法来克服上述限制。LBCF由两部分组成:成员级治疗效果估计和预算约束优化。对于第一个组件,我们设计了一个新的分割标准,允许来自多个治疗组的类似用户驻留在同一个节点上。提出的分割准则允许我们用统一的模型处理多个处理(图2b),这样就可以在相同的特征空间内估计不同激励水平下的处理效果(图1b)。

为此,除了节点间的异质性,我们提出的方法还鼓励节点内处理效果的异质性,以促进下游预算受限的优化任务。对于另一个组成部分,在获得用户对不同激励水平的处理效果后,我们可以将预算约束优化任务制定为多选择背包问题(MCKP)[10,15,22]。尽管MCKP已经被研究了几十年(例如经典的线性时间近似算法,Dyer-Zemel算法[4]),但现有的优化方法并不是为现代基础设施设计的,特别是分布式计算框架,如Tensorflow[1]和Spark。因此,这些方法无法扩展到今天的大规模在线平台。在这项工作中,我们利用MCKP的拉格朗日对偶的凸性,设计了一种高效的可并行平分搜索算法,称为对偶梯度平分(DGB)。与其他最先进的近似优化方法相比,DGB可以更容易地部署在分布式计算系统中。(?)时间复杂度和不需要额外的超参数调优作为其基于梯度下降的替代方案。
政策评估。对防弹少年团的离线评价也是一个难题。现有的BTS问题评价方法存在诸多局限性。其中一种方法,如AUUC[8,21,23]、Qini-curve[16]和AUCC[3],在多治疗情况下,根据评分对所有用户进行排序,评分是所有可能的治疗分配中预测治疗效果最大的。然而,待评估策略并不一定选择,最大的治疗。另一种方法是Zhao等人提出的预期结果度量。在这个指标中,被评估的用户并不是全部的RCT用户,这导致消费预算随着不同的治疗选择策略而变化。为了克服这些现有评估方法的局限性,我们提出了一种新的评估指标,称为百分比平均增益(PMG)用于BTS问题。我们的指标能够对治疗选择政策进行更全面的评估。
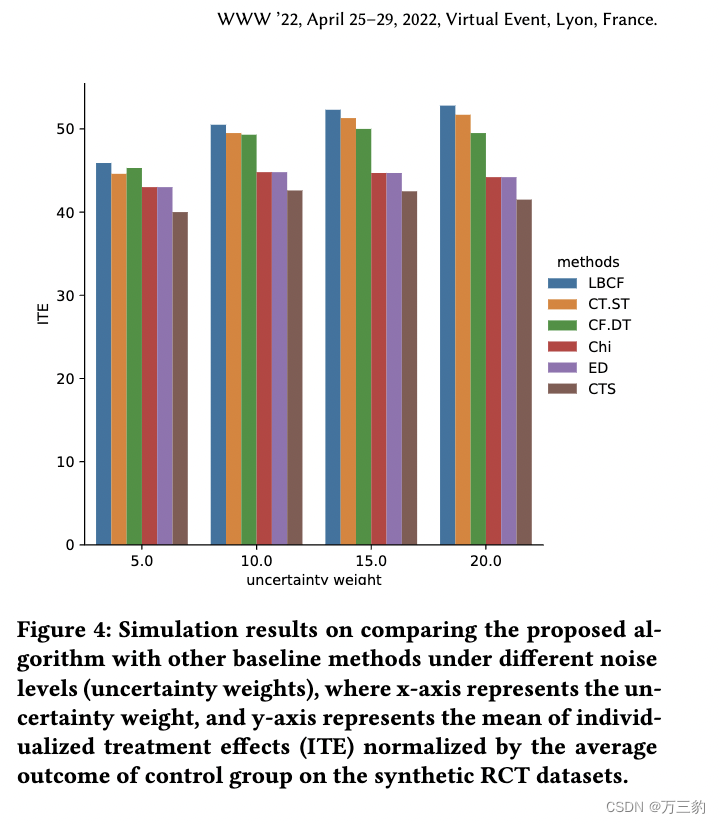
数据集和测试。为了充分验证我们的LBCF算法的性能,我们进行了三种测试:模拟测试、在实词数据集上的离线测试和在线AB测试。在模拟测试中,我们使用与Tu et al.[26]相同的方法生成合成的RCT数据集。为了得出令人信服的结果,我们还使用Tu et al.[26]中定义的相同测量指标:个性化治疗效果的归一化平均值(ITE)。我们将提出的LBCF算法与五种基于树的基线方法进行比较:基于欧几里得距离(ED)的抬升随机森林[7,17],卡方(Chi)和上下文处理选择(CTS),这些方法都来自CausalML包;随机优化因果树(CT.ST)和确定性优化因果森林(CF.DT)是Tu et al.[26].推荐的两种方法。仿真结果表明,LBCF算法在不同噪声水平下具有良好的性能。
在离线测试中,我们首先从视频流媒体平台收集了一个网络规模的RCT数据集。数据集记录了用户在七个随机登记的激励组中的活动参与时间(即“结果”),每个组提供不同级别的奖金(即“多重待遇”)。有了我们发布的完整数据集和提议的评估协议PMG,我们社区的更多研究人员可以潜在地参与相关研究。我们进一步在平台上部署了建议的方法。在线A/B实验表明,在活动参与持续时间方面,在相同的预算下,我们的算法可以显著优于基线方法至少0.9%,这是这几个月的巨大进步。在线实验也证明了LBCF算法的可扩展性。目前,LBCF算法为数亿用户提供服务。
综上所述,本文的贡献可以概括为以下几点:
- 我们提出了一种预算约束下基于树的处理选择技术,称为大规模预算约束因果森林(LBCF)算法。所提出的方法已经部署在一个服务于数亿用户的真实大型平台上。
- 我们提出了一种新的用于预算约束治疗选择(BTS)问题的离线评估方法,称为百分比平均增益(PMG),该方法解决了使用随机对照试验(RCT)收集的离线数据集评估BTS问题解决方案的内在局限性。
- 我们进行了一系列广泛的实验,包括在公共合成数据集上的模拟测试,在收集的真实数据集上的离线测试,以及在大型视频平台上的在线AB测试。结果证明了该方法的有效性,并证明了其在大规模工业应用场景下的可扩展性。
2 问题的制定
在这项工作中,我们专注于最大化总体回报,同时决定如何提供激励以遵守全球预算约束。我们采用潜在结果框架[20,24]来表达激励对回报的治疗效果,其中激励和回报分别被视为“治疗”和“结果”。我们用大写字母表示随机变量,用小写字母表示它们的实现。我们用粗体表示向量,用普通字体表示标量。
 假设我们有一个大小的数据集?包含(X,?, ?)收集自随机对照试验。我们使用上标?为了索引样本,(xi, ?吗?,吗??),吗?= 1,…,吗?. ? 吗?∈{0,1,…,吗?}。我们假设潜在结果的存在?吗?(?吗?= ?)然后呢?吗?(?吗?= 0)与我们在治疗分配中观察到的结果相对应?吗?= ?还是?吗?= 0,并尝试估计条件平均处理效果(CATE)函数,假设它们具有相同的特征值xi:
假设我们有一个大小的数据集?包含(X,?, ?)收集自随机对照试验。我们使用上标?为了索引样本,(xi, ?吗?,吗??),吗?= 1,…,吗?. ? 吗?∈{0,1,…,吗?}。我们假设潜在结果的存在?吗?(?吗?= ?)然后呢?吗?(?吗?= 0)与我们在治疗分配中观察到的结果相对应?吗?= ?还是?吗?= 0,并尝试估计条件平均处理效果(CATE)函数,假设它们具有相同的特征值xi:
吗?吗?. 另外,我们考虑随机变量?,代表与治疗相关的费用。我们假设没有成本,如果?= 0,成本呢?吗?吗?如何应用每种治疗方法?给每个用户?是事先知道的。让吗?表示总预算。然后给出(X, ?,吗?, ?)手动设定预算呢?,我们的目标是最大化

3策略评价
BTS(budget-constrained treatment selection)问题的第一个挑战是如何评估解决方案,这是一个困难的任务,因为缺少反事实的结果,例如,如果我们选择治疗,我们无法观察到客户潜在的结果变化(即治疗效果)?(例如九折优惠券)而不是治疗?(例如,没有优惠券)。在本节中,我们提出了一种新的BTS问题的评价方法。
现有方法的局限性。最近研究了两种评价方法。
第一种方法是利用从随机对照试验(RCT)中收集的用户数据,使用隆起曲线下的度量面积(AUUC)[21]来评估治疗效果[11,12,25,28]。在多重治疗的情况下,这种方法要求将所有用户按评分降序排列,评分是所有可能的治疗分配中预测的最大治疗效果。但是,待评价策略并不一定选择最大处理,因为最大处理不一定是最优处理。
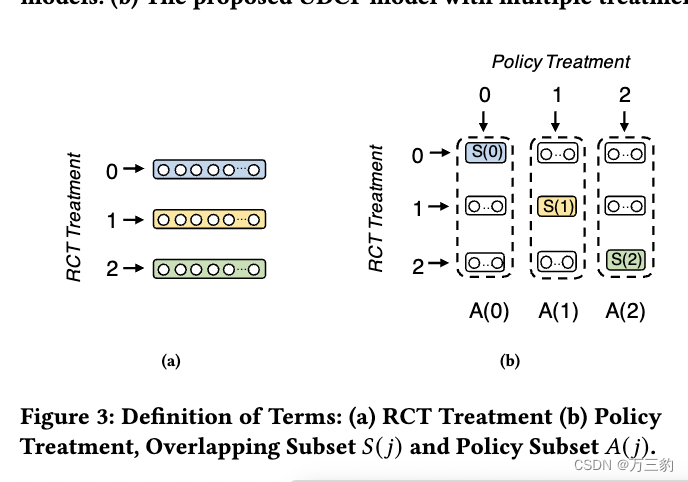
第二个是[30]提出的预期结果度量。它通过汇总RCT和政策处理匹配的用户的加权结果来估计预期结果(图3)。对于我们的BTS问题,这个指标的主要局限性是被评估的用户不是整个RCT用户。因此,预期结果并不是整个RCT使用者的平均结果,这就导致了不同治疗选择政策的消费预算的变化。两个具有不同消费预算的政策是不具有可比性的。
考虑到上述两种方法的局限性,我们针对BTS问题提出了一种新的策略评估指标,称为百分比平均增益(PMG)。
4 方法
我们比较了几种常见的基于树的方法来解决BTS问题,并介绍了一种称为大规模预算约束因果森林(LBCF)算法的新方法。
4.1现有方法的局限性。
4.1.1隆升随机森林。
在处理方法的选择上,大多数隆升随机林方法只是简单地选择处理效果最大的处理。我们称这种治疗选择策略为贪婪治疗选择策略。在下面,通过一个简单的例子,我们表明在给定的预算下,这种贪婪的治疗选择策略是次优的。
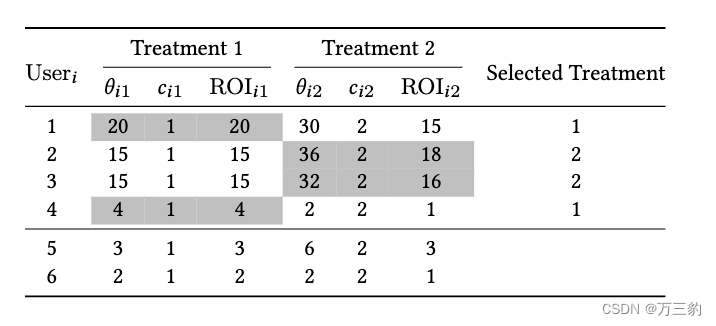

理解:贪心不考虑后续,不是全局最优。
4.1.2最优处理选择算法。
Tu等人最近提出的最优处理选择算法[26]可以用来解决BTS问题,不需要做太多修改。然而,该算法有两个局限性,特别是对于大规模的BTS问题。首先,在大规模数据集上,由于缺乏大规模线性规划优化求解器,作者提出用群体级优化代替成员级优化。然而,正如Tu等人[26]测试的那样,在低噪声级别的数据集上,成员级优化可以生成更个性化的估计。
因此,我们希望开发一种并行算法来解决大规模数据集上BST问题的成员级优化。其次,为了实现多处理效果估计,Tu等。[26]简单地分别训练多个二元因果森林[27](MBCF),即一个因果森林生成一个治疗组与对照组的治疗效果估计。然而,MBCF有两个局限性:

•训练和维护许多二元因果森林(BCF)在计算上很麻烦。
•对于一个用户来说,一个BCF产生的治疗效果估计可能与其他BCF产生的治疗效果估计属于不同的特征空间,这与CATE的定义相矛盾(Eq. 1)。例如(图2a),特征{年龄= 30,收入= 55?}将分别属于BCF1的Leaf11和BCF3的Leaf31,但Leaf11和Leaf31对应不同的特征值。
4.2提出的LBCF算法
我们将BTS问题分解为两个步骤:(i)估计CATE ?吗?吗?在成员级别上只使用一个模型。(ii)通过求解约束优化问题得到最佳处理方案z *。
4.2.1统一判别因果林。
为了克服MBCF(第4.1.2节)的局限性,并在多个处理之间区分处理效果估计,通过修改BCF,我们设计了一个新的多处理因果林模型,该模型具有以下两个特性:
•统一-该模型只构建一个因果林,所有处理被分割在一起并遵循相同的分割规则。
•可区分性——该模型可以区分节点间异构性和节点内异构性。

为了总结上面的两个分割规则,并平衡效率和有效性,特别是在大规模数据集上,我们提出了一个新的因果森林,称为统一判别因果森林(UDCF,图2b),具有两步分割标准:
(i)让?相对于所有可能分裂的总数来说是一个很小的数字。挑顶?根据公式3计算的结果,通过Inter分割规则将候选人从所有可能的分割中分割出来。(ii)从?根据式4计算的结果,用Intra splitrule拆分候选。

Termination Rule and Treatment Effect Estimation. Termination rule for tree split is just the same as BCF. After UDCF is constructed, treatment effect estimation 𝜃 (xi) can be obtained by fitting T and Y in a weighted least square regression, where theweight is the similarity between xi and all other samples. We omit the details of this part (see [2]).

4.2.2预算约束优化。
基于?在第4.2.1节中,我们可以在给定预算的情况下,制定我们的优化问题?. 我们希望通过求解以下问题得到最优的z *。
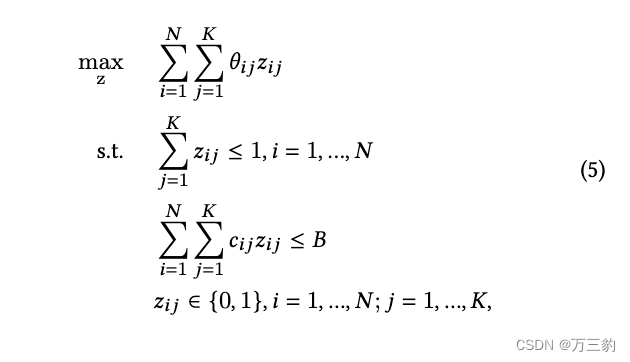
 4.2.3大规模系统与并行化。
4.2.3大规模系统与并行化。
对于BTS问题来说,“大规模”一词有两层含义:数十万用户和大量各种各样的处理,这都给这些技术应用于大规模系统带来了障碍。在处理效果估计方面,所提出的UDCF本质上是一个可以在现代分布式系统上并行运行的随机森林。而UDCF本质上是一个单一模型,哪个可以训练呢?治疗组的数据放在一起不管有多大?是多少。对于预算受限的优化,计算梯度?‘(?*)(见算法2中的第12行)可以分解为|U| = ?独立的子问题,也可以由分布式系统并行解决。总而言之,即使在大规模系统中,LBCF算法仍能表现良好,高效运行。
4.2.4总体算法。
在UDCF和DGB的基础上,我们在算法3中总结了我们的方法。
算法3 LBCF算法
1:从在线测试或合成数据集中获取RCT样本。
2:通过UDCF对不同治疗的结果进行成员级别的治疗效果估计(章节4.2.1)。
3:利用所提出的DGB(章节4.2.2)解决成员级预算约束优化问题。
5验证
为了完全符合我们的LBCF算法的性能,我们进行了三种测试:在公共合成数据集上的模拟分析,在真实字数据集上的离线测试和在线AB测试。
5.1合成数据
我们使用与Tu et al.[26]相同的方法来生成合成数据集。在这个模拟中,我们假设有8万个样本,每个样本有三个处理。我们在最大限度地提高治疗效果的同时,将成本控制在预算之内?. 此外,我们还像Tu等人一样,通过引入不确定性权重超参数来衡量不同方法在数据中不同噪声水平下的性能。[26]。测量指标。为了得到一个令人信服的结果,我们也使用了Tu等人的测量方法。

5.2离线生成TestRCT数据。
在一个视频应用程序上,我们将0.1%的在线流量分配给RCT, RCT运行两周以收集足够的样本数据,这些数据被用作5.1节中比较的所有方法的训练实例。在RCT中,活动运营商对不同实验组的应用用户提供不同的积分,而对对照组的应用用户不提供积分。一般来说,奖励点数越多,活动参与时间越长。最后,RCT数据集包含超过10万个应用访问实例。每个实例都被赋予了相关特征(如应用访问行为、区域、历史统计数据等)、结果(活动参与时长)和治疗(加分)(如果适用的话)(详见补充材料)。
结果。通过利用Eq. 2中描述的评估指标PMG,我们进行了与第5.1节相同的比较,但在不同的条件下,总预算限制。如图5所示,本文提出的LBCF方法在任何预算配置下都能获得最大的用户活动参与持续时间PMG,这与仿真分析的结果一致(见章节5.1)。
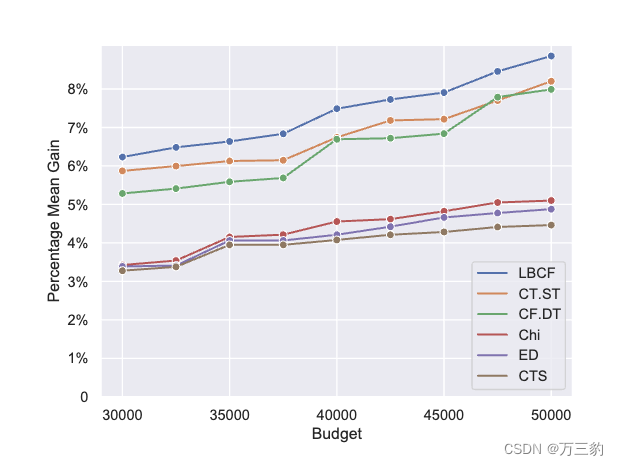
图5:在不同预算下,将提出的算法与其他基线方法进行比较的离线测试结果,其中x轴代表预算,y轴代表真实RCT数据集上活动参与持续时间的百分比平均增益(PMG)。
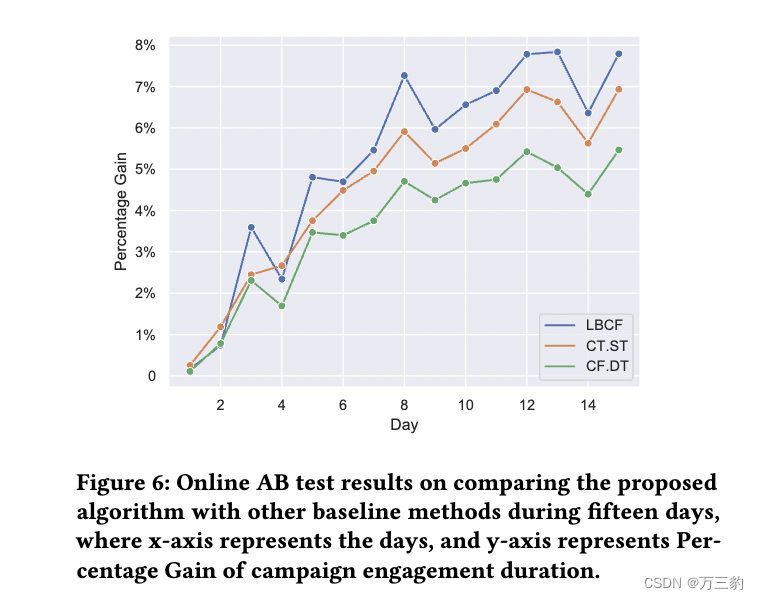
5.3在线AB测试设置
在线AB实验在5.2节提到的大型视频应用上进行了15天以上。该实验的目标是评估实验组和对照组(即无激励组)之间活动参与持续时间的增加百分比。实验组都在相同的预算约束下?对照组没有奖金。基于上述模拟测试和离线测试的结果,在本次在线实验中,我们仅将LBCF与以下两种方法进行比较:CT。ST和CF.DT,因为实现管道和启动在线A/B测试的成本很高。CF.DT的线性规划求解器不能处理大规模数据集,因此我们使用我们提出的DGB代替。因此在本试验中,CF.DT也等价于MBCF。DGB (CF实际上是MBCF模型)。•实验组:CT。Tu et al.[26]的ST -基线法•实验组:Tu et al. CF.DT (MBCF.DGB)。•实验组:LBCF (UDCF.DGB) -建议方法结果如图6所示。在最初几天后,建议的LBCF (UDCF.DGB)始终提供较高的百分比收益(最后一天为7.79%)。一个基线CF.DT (MBCF. dgb)是各组中最差的(最后一天为5.31%),因为MBCF比UDCF差,如我们在第4节中所述。另一个基线CT。ST处于中间(最后一天为6.87%),这与我们5.2节的离线测试结果基本一致。
6预算受限的治疗选择
对于BTS问题,我们主要关注基于树的技术。现有的方法有欧氏距离(ED)、卡方(Chi)和环境处理选择[30](CTS)等;随机优化的因果树(CT.ST)和确定性优化的因果森林(CF.DT),两者都是前两个Tu等人推荐的方法。[26]。这些方法的局限性是在估计隆起时不能保证相同的特征空间,经常需要训练多个模型,或者在预算限制下简单地采用次优贪婪处理选择策略。此外,预算约束优化MCKP[22]是一个著名的np难问题。在过去的几十年里,精确算法和启发式算法都被研究过,包括分支和定界[5],禁忌搜索[9],贪婪算法[22]等。不幸的是,这些传统算法并不是为现代分布式计算而设计的。因此,他们无法在一个非常大规模的数据集(例如,数十亿个决策变量)上求解MCKP。
评价指标。对于BTS问题,目前流行的评价方法有两种。一些方法,如AUUC[8,21,23]、Qini-curve[16]、AUCC[3]等,要求相似评分组表现出相似的特征,这并不一定能满足要求。另一种方法是[30]提出的预期结果度量。该指标的主要局限性是被评估的用户不是整个RCT用户,这导致不同治疗选择策略的消费预算发生变化。不同消费预算下的两种政策不具有可比性。
7结论
假设强调两点:第一点是每个单元的独立性。在我们的案例中,我们确实承认,SUTVA假设并不严格地适用于第一点。例如,两个应用程序用户可能经常相互分享激励信息(即待遇)。最近已经开展了一些工作来处理数据中的这种依赖性。第二点是每种治疗只存在一个级别。在我们的工作中,我们考虑离散的处理,我们保证每个处理都有相同数量的激励。因此,SUTVA假设可以hold住第二点。此外,我们还希望在约束优化任务中加入更多约束(如用户体验),并提出即使在大型系统中也能有效解决这类任务的解决方案。
8阅读理解
- UDCF分裂没考虑cost,没单调性约束。
Readme
代码:
LBCF:一种大规模预算约束因果森林算法
本回购包含了论文“LBCF: A large Budget-Constrained Causal Forest Algorithm”补充资料中提到的所有数据、代码文件和图片。
第五节仿真分析
重现结果的步骤:
1. 在generateSimulationData中将你的工作目录添加到“homePath”中。R在Code/Data_generation文件夹下。
2. generateSimulationData.R运行。
3.按照每个模型文件夹下的说明进行训练和预测;为每个模型运行budget_allocation.py。
4. 在代码/评估文件夹下运行Simulation_analysis.py。
5.2离线测试
注意:由于这个真实世界的离线测试数据集的版权受到保护,目前我们无法在发布之前公开此测试中使用的完整数据,但读者可以使用提供的代码在其他数据集上运行此算法。但是,数据文件夹中提供了一小部分(约2000个样本)的完整数据,仅用于测试代码,而不是重现5.2节中的结果,并且所有2000个样本都已加密。
运行代码的步骤:
1. 按照每个模型文件夹下的说明进行训练和预测。
2. 为每个模型运行budget_allocation-RCT.py。
3.在代码/评估文件夹下运行Offline_test.py。
实现细节
提出的CATE估计方法UDCF(统一判别因果森林)是通过直接修改GRF(广义随机森林)的c++源代码,采用新的分裂准则来实现的。因此,UDCF需要一个像GRF一样的c++运行环境。环境配置的详细信息请参考GRF Github页面。
提出的MCKP分布式算法DGB (Dual Gradient Bisection)是用Python编写的,并在Pytorch上运行。
基线方法:ED (Euclidean Distance)、Chi (Chi- square)和CTS (Contextual Treatment Selection)上的随机森林,都是从CausalML包Github Pages直接导入的。
基线方法:CT。Tu et al.[1]提出的ST (Causal Tree with Stochastic Optimization,随机优化因果树)和CF.DT (Causal Forest with Deterministic Optimization,确定性优化因果林)采用论文[1]中列出的算法实现。需要R包。
参考
[1]。Ye Tu, Kinjal Basu, Cyrus DiCiccio, roil Bansal, Preetam Nandy, Padmini Jaikumar和Shaunak Chatterjee, 2021。使用因果异质性的个性化治疗选择。在2021年网络会议论文集中。1574 - 1585。