Scala数据结构

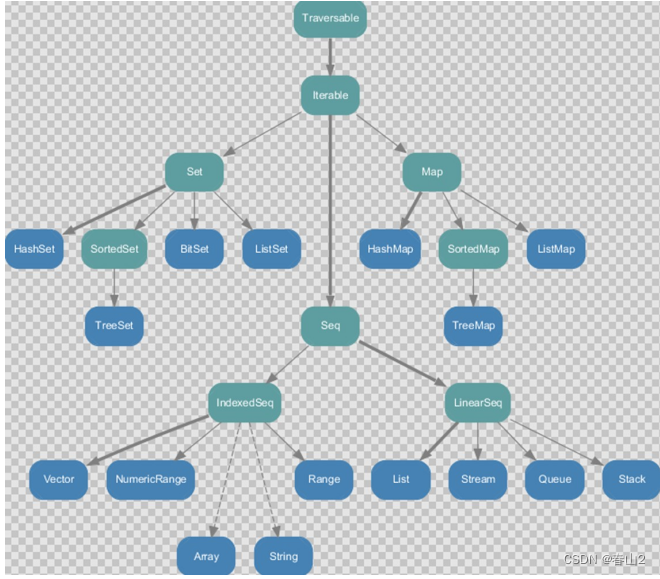
Scala中, 有两种数组,一种是定长数组,另一种是变长数组.
定长数组
-
数组的长度不允许改变.
-
数组的内容是可变的.
格式1:
val/var 变量名 = new Array[元素类型](数组长度)格式2:
val/var 变量名 = Array(元素 1 , 元素 2 , 元素 3 ...)代码示例:
-
定义一个长度为 10 的整型数组, 设置第 1 个元素为11, 并打印第 1 个元素.
-
定义一个包含"java", "scala", "python"这三个元素的数组, 并打印数组长度.
package test7object Test10 {def main(args: Array[String]): Unit = {val arr = new Array[Int](10)arr(0) = 11println(arr(0))val arr1 = Array("java", "scala", "python")println(arr1.length)}
}
变长数组
数组的长度和内容都是可变的,可以往数组中添加、删除元素.
格式一:
val/var 变量名 = ArrayBuffer[元素类型]()格式二:
val/var 变量名 = ArrayBuffer(元素 1 ,元素 2 ,元素 3 ....)代码示例:
package test8import scala.collection.mutable.ArrayBufferobject Test1 {def main(args: Array[String]): Unit = {val arr1 = new ArrayBuffer[Int]()println(s"arr1 : $arr1")val arr2 = ArrayBuffer("hadoop", "strom", "spark")println(s"arr2 : $arr2")}
}
代码示例:
package test8import scala.collection.mutable.ArrayBufferobject Test2 {def main(args: Array[String]): Unit = {val arr = ArrayBuffer("hadoop", "spark", "flink")arr += "flume"arr -= "hadoop"arr ++= Array("hive", "sqoop")arr --= Array("sqoop", "spark")println(s"arr : $arr")}
}
代码示例:
package test8object Test3 {def main(args: Array[String]): Unit = {val arr = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)//方式一for (i <- 0 to arr.length - 1) {print(arr(i) + " ")}println()for (i <- 0 until arr.length) {print(arr(i) + " ")}println()//方式二for (i <- arr) {print(i + " ")}println()//其他方式for (i <- arr.indices) {print((i + 1) + " ")}println()}
}
代码示例:
-
sum()方法: 求和 -
max()方法: 求最大值 -
min()方法: 求最小值 -
sorted()方法: 排序, 返回一个新的数组. -
reverse()方法: 反转, 返回一个新的数组.
package test8object Test4 {def main(args: Array[String]): Unit = {val arr = Array(4, 1, 6, 5, 3, 2)println(s"sum : ${arr.sum}")println(s"max : ${arr.max}")println(s"min : ${arr.min}")val arr1 = arr.sortedvar arr2 = arr.sorted.reversefor (i <- arr1) {print(i + " ")}println()for (i <- arr2) {print(i + " ")}}
}
元组
元组一般用来存储多个不同类型的值。例如同时存储姓名,年龄,性别,出生年月这些数据, 就要用到元组来存储了。并且元组的长度和元素都是不可变的。
格式一:
val/var 元组 = (元素 1 , 元素 2 , 元素 3 ....)格式二:
val/var 元组 = 元素 1 -> 元素 2注意: 这种方式, 只适用于元组中只有两个元素的情况.
代码示例:
package test8object Test5 {def main(args: Array[String]): Unit = {val tuple1 = ("张三", 23)val tuple2 = "张三" -> 23println(tuple1)println(tuple2)}
}
访问元组中的元素
在Scala中, 可以通过元组名.编号的形式来访问元组中的元素,1表示访问第一个元素,依次类推.
也可以通过元组名.productIterator的方式, 来获取该元组的迭代器, 从而实现遍历元组.
格式一:
println(元组名._ 1 ) //打印元组的第一个元素.
println(元组名._ 2 ) //打印元组的第二个元组.
...格式二:
val tuple1 = (值 1 , 值 2 , 值 3 , 值 4 , 值 5 ...) //可以有多个值
val it = tuple1.productIterator //获取当前元组的迭代器对象
for(i <- it) println(i) //打印元组中的所有内容.代码示例:
package test8object Test6 {def main(args: Array[String]): Unit = {val tuple1 = "张三" -> "male"println(s"姓名:${tuple1._1},性别:${tuple1._2}")val iterable = tuple1.productIteratorfor (i <- iterable) {print(i + " ")}}
}
列表
列表(List)是Scala中最重要的, 也是最常用的一种数据结构。它存储的数据, 特点是: 有序, 可重复.
在Scala中,列表分为两种, 即: 不可变列表和可变列表.
-
有序的意思并不是排序, 而是指元素的存入顺序和取出顺序是一致的.
-
可重复的意思是列表中可以添加重复元素
不可变列表
不可变列表指的是: 列表的元素、长度都是不可变的。声名list时必须初始化。
格式一:
val/var 变量名 = List(元素 1 , 元素 2 , 元素 3 ...)格式二:通过Nil创建一个空列表.
val/var 变量名 = Nil格式三:
val/var 变量名 = 元素 1 :: 元素 2 :: Nil注意: 使用::拼接方式来创建列表,必须在最后添加一个Nil
代码示例:
package test8object Test7 {def main(args: Array[String]): Unit = {val list1 = List(1, 2, 3, 4)val list2 = Nilval list3 = 1 :: 2 :: 3 :: Nilprintln(s"list1 : $list1")println(s"list2 : $list2")println(s"list3 : $list3")}
}
可变列表
可变列表指的是列表的元素、长度都是可变的.
格式一:
val/var 变量名 = ListBuffer[数据类型]()格式二:
val/var 变量名 = ListBuffer(元素 1 ,元素 2 ,元素 3 ...)代码示例:
package test8import scala.collection.mutable.ListBufferobject Test8 {def main(args: Array[String]): Unit = {val list1 = new ListBuffer[Int]()val list2 = ListBuffer(1, 2, 3, 4)println(s"list1 : $list1")println(s"list2 : $list2")}
}
可变列表的常用操作
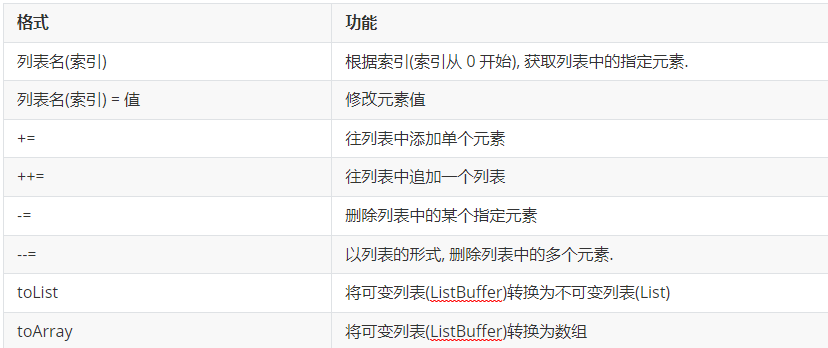
代码示例:
package test8import scala.collection.mutable.ListBufferobject Test9 {def main(args: Array[String]): Unit = {val list1 = ListBuffer(1, 2, 3)println(list1(0))list1 += 4println(list1)list1 ++= List(5, 6, 7)println(list1)list1 -= 7println(list1)list1 --= List(5, 6)println(list1)//装换为不可变列表val list2 = list1.toList//可变链表转换为数组val arr = list1.toArrayprintln(s"list1 : $list1")println(s"list2 : $list2")println(s"arr : $arr")}}
列表的常用操作
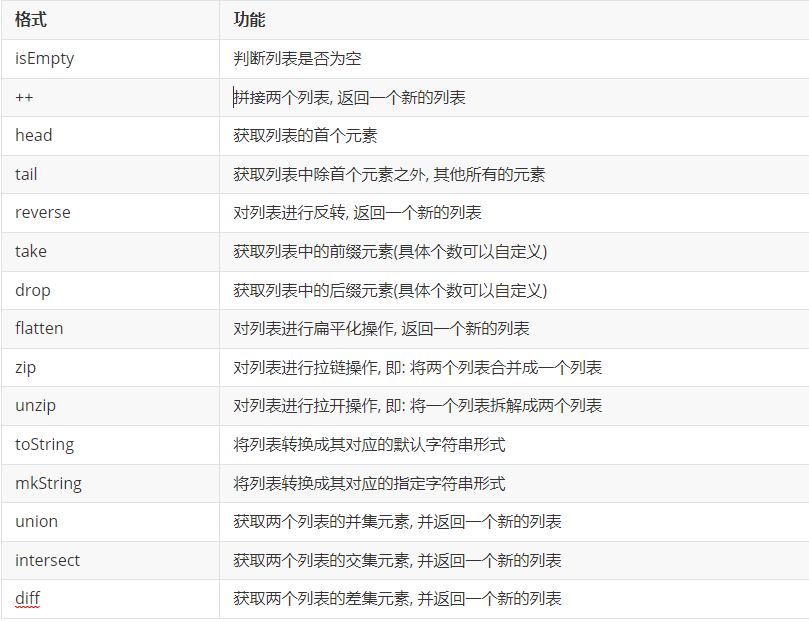
代码示例:
package test8object Test10 {def main(args: Array[String]): Unit = {val list1 = List(1, 2, 3, 4)println(s"isEmpty : ${list1.isEmpty}")val list2 = List(4, 5, 6, 7)val list3 = list1 ++ list2println(s"list3 : $list3")println(s"head : ${list3.head}")val list4 = list3.reverseprintln(s"list4 : $list4")println(s"take : ${list3.take(3)}")println(s"drop : ${list3.drop(3)}")}
}
集
Set(也叫: 集)代表没有重复元素的集合。特点是: 唯一, 无序
Scala中的集分为两种,一种是不可变集,另一种是可变集。
-
唯一的意思是Set中的元素具有唯一性, 没有重复元素
-
无序的意思是Set集中的元素, 添加顺序和取出顺序不一致
不可变集
不可变集指的是元素, 集的长度都不可变.
格式一:
val/var 变量名 = Set[类型]()格式二:
val/var 变量名 = Set(元素1 , 元素2 , 元素3 ...)代码示例:
package test9object Test2 {def main(args: Array[String]): Unit = {val set1 = Set[Int]()val set2 = Set(1, 1, 3, 2, 4, 8)println(s"set1 : $set1")println(s"set2 : $set2")}
}
不可变集的常见操作
-
获取集的大小(size)
-
遍历集(和遍历数组一致)
-
添加一个元素,生成一个新的Set(+)
-
拼接两个集,生成一个新的Set(++)
-
拼接集和列表,生成一个新的Set(++)
注意:
-
-(减号)表示删除一个元素, 生成一个新的Set
-
--表示批量删除某个集中的元素, 从而生成一个新的Set
代码示例:
package test9object Test3 {def main(args: Array[String]): Unit = {val set1 = Set(1, 1, 2, 3, 4, 5)println("set1 的长度为:" + set1.size)print("set1 集中的所有元素为:")for (i <- set1) {print(i + " ")}println()val set2 = set1 - 1println(s"set2 : ${set2}")val set3 = set1 ++ Set(6, 7, 8, 9)println(s"set3 : $set3")val set4 = set1 ++ List(6, 7, 8, 9)println(s"set4 : $set4")}
}
可变集
可变集指的是元素, 集的长度都可变, 它的创建方式和不可变集的创建方式一致,只不过需要先导入可变集类。
代码示例:
package test9import scala.collection.mutableobject Test4 {def main(args: Array[String]): Unit = {val set1 = mutable.Set(1, 2, 3, 4)set1 += 5set1 ++ Set(5, 6, 7, 8)//set ++ List(5,6,7,8)set1 -= 1set1 --= Set(3, 5, 6)//set1 --= List(3,5,6)println(set1)}}
映射
映射指的就是Map。它是由键值对(key, value)组成的集合。特点是: 键具有唯一性, 但是值可以重复. 在Scala中,Map也分为不可变Map和可变Map。
注意: 如果添加重复元素(即: 两组元素的键相同), 则会用新值覆盖旧值.
不可变Map
不可变Map指的是元素, 长度都不可变.
格式一:
val/var map = Map(键->值, 键->值, 键->值...) // 推荐,可读性更好格式二:
val/var map = Map((键, 值), (键, 值), (键, 值), (键, 值)...)代码示例:
package test9object Test5 {def main(args: Array[String]): Unit = {val map1 = Map("张三" -> 23, "李四" -> 24, "王五" -> 25)val map2 = Map(("张三", 23), ("李四", 24), ("王五", 25))println(s"map1 : ${map1}")println(s"map2 : ${map2}")}
}
可变Map
可变Map指的是元素, 长度都可变. 定义语法与不可变Map一致, 只不过需要先手动导包:
package test9import scala.collection.mutableobject Test6 {def main(args: Array[String]): Unit = {val map1 = mutable.Map("张三" -> 23, "李四" -> 24)val map2 = mutable.Map(("张三", 23), ("李四", 24))println(s"map1 : ${map1}")println(s"map2 : ${map2}")}
}
Map基本操作
-
map(key): 根据键获取其对应的值, 键不存在返回None. -
map.keys: 获取所有的键. -
map.values: 获取所有的值. -
遍历map集合: 可以通过普通for实现.
-
getOrElse: 根据键获取其对应的值, 如果键不存在, 则返回指定的默认值. -
+号: 增加键值对, 并生成一个新的Map.
注意: 如果是可变Map, 则可以通过+=或者++=直接往该可变Map中添加键值对元素.
-
-号: 根据键删除其对应的键值对元素, 并生成一个新的Map.
注意: 如果是可变Map, 则可以通过-=或者--=直接从该可变Map中删除键值对元素.
代码示例:
package test9import scala.collection.mutableobject Test7 {def main(args: Array[String]): Unit = {val map1 = mutable.Map("张三" -> 23, "李四" -> 24)println(map1.get("张三"))println(map1.keys)println(map1.values)for ((k, v) <- map1) {println(s"键:$k,值:$v")}println(map1.getOrElse("王五", -1))//不可变map// val map2 = map1 + ("王五" -> 25)// println(s"map1 : $map1")// println(s"map2 : $map2")//可变mapmap1 += "王五" -> 25println(s"map1 : $map1")map1 -= "李四"println(s"map1 : $map1")}
}
迭代器
Scala针对每一类集合都提供了一个迭代器(iterator), 用来迭代访问集合.
-
使用iterator方法可以从集合获取一个迭代器.
迭代器中有两个方法:
hasNext方法: 查询容器中是否有下一个元素
next方法: 返回迭代器的下一个元素,如果没有,抛出NoSuchElementException
-
每一个迭代器都是有状态的.
即: 迭代完后保留在最后一个元素的位置. 再次使用则抛出NoSuchElementException
-
可以使用while或者for来逐个获取元素.
代码示例:
package test9object Test8 {def main(args: Array[String]): Unit = {val list1 = List(1, 2, 3, 4, 5)val it = list1.iteratorwhile (it.hasNext) {println(it.next())}println(it.hasNext)println(it.next())}
}