Torch常用函数随记

文章目录
-
- torch.ones(*sizes, out=None):
- torch.zeros(*sizes, out=None):
- torch.normal(means, std, out=None):
- pytorch的顺序容器torch.nn.Sequential()
- torch.nn.MSELoss()
torch.ones(*sizes, out=None):
返回一个全为1的张量,形状由可变参数sizes定义
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
torch.zeros(*sizes, out=None):
返回一个全为标量0的张量,形状由可变参数sizes定义
torch.normal(means, std, out=None):
返回一个张量,包含从给定means, std的离散正态分布中抽取随机数,均值和标准差的形状不须匹配,但每个张量的元素个数须相同
- means(Tensor) - 均值
- std(Tensor) - 标准差
- out(Tensor, optional)-可选的输出张量
pytorch的顺序容器torch.nn.Sequential()
使用方式:
# 写法一
net = nn.Sequential(nn.Linear(num_inputs, 1)# 此处还可以传入其他层)# 写法二
net = nn.Sequential()
net.add_module('linear', nn.Linear(num_inputs, 1))
# net.add_module ......# 写法三
from collections import OrderedDict
net = nn.Sequential(OrderedDict([('linear', nn.Linear(num_inputs, 1))# ......]))torch.nn.MSELoss()
求predict和target之间的loss
MSE: Mean Squared Error(平均平方误差,均方误差)
含义:均方误差,是预测值与真实值之差的平方和的平均值,即:
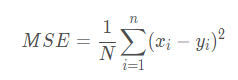
nn.MSELoss()函数新版的只有一个reduction参数。reduction的意思是维度要不要缩减,以及怎么缩减,有三个选项:
- ‘none’: no reduction will be applied.
- ‘mean’: the sum of the output will be divided by the number of elements in the output.
- ‘sum’: the output will be summed.
如果不设置reduction参数,默认是’mean’。
参考:程序实例博客