爬虫攻守道 - 猿人学第一题 - 机票价格

前言
网上的教程,讲的什么解混淆,找加密函数,都是故弄玄虚,误人子弟。
第1步:过掉无限Debugger
这个是最基本的,只需要在 debugger 处单击右键 Never Stop here,然后继续即可

第2步:找到请求
这个还是非常明显的。在Payload 部分可以看到有个 m 参数。

第3步:找到发起请求的地方
切换到 Initiator ,查看请求栈。定位到 request 处
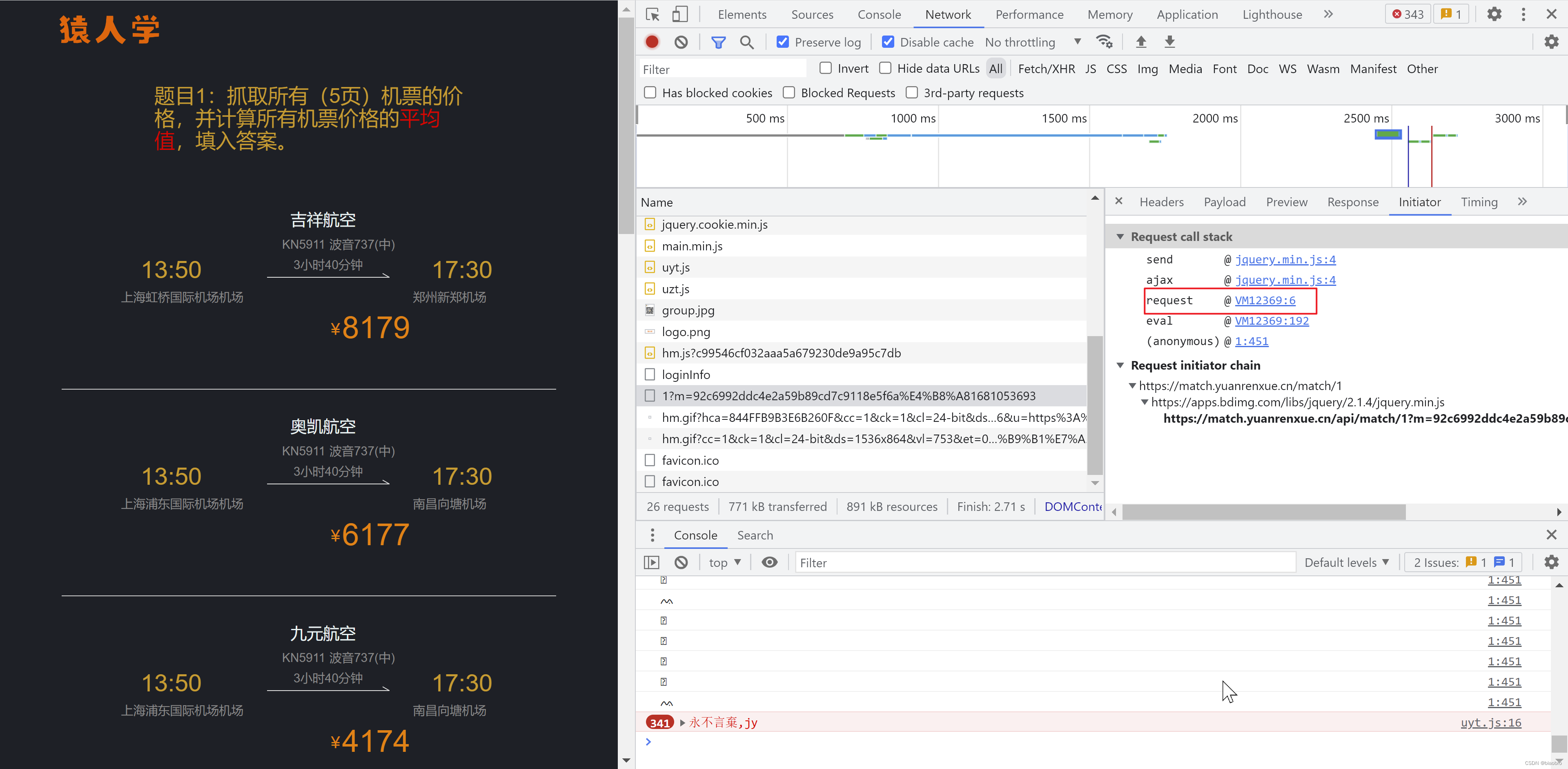
在request 文件中打上断点,可以看到第1个断点是获取时间戳然后做些加减运算,得到1个值。在第2个断点处,将第1给断点处得到的值,调用oo0O0 函数,就得到请求 paylad 的m参数的前半部分。
第3个断点就是把 第1个和第2个断点处得到的值 做个拼接,赋值给 m,
所以接下来的关键,就是找到 oo0O0 函数。

单步调试,代码就会来到 https://match.yuanrenxue.cn/match/1.html
这里好像网站做了限制,格式化不生效,没关系可以复制代码到 Pycharm,保存为 html 文件,然后格式化,找到我们要的函数,复制粘贴到 新的 js 文件。

无脑执行这个 js 文件,他会相继提示你 window 没有定义,window.a 没有定义,document 没有定义,window.c 没有定义,但是没有关系,全局定义一个 window,剩下的从 1.html 里找补就行,加起来也就处理 for 循环里的1行代码而已。
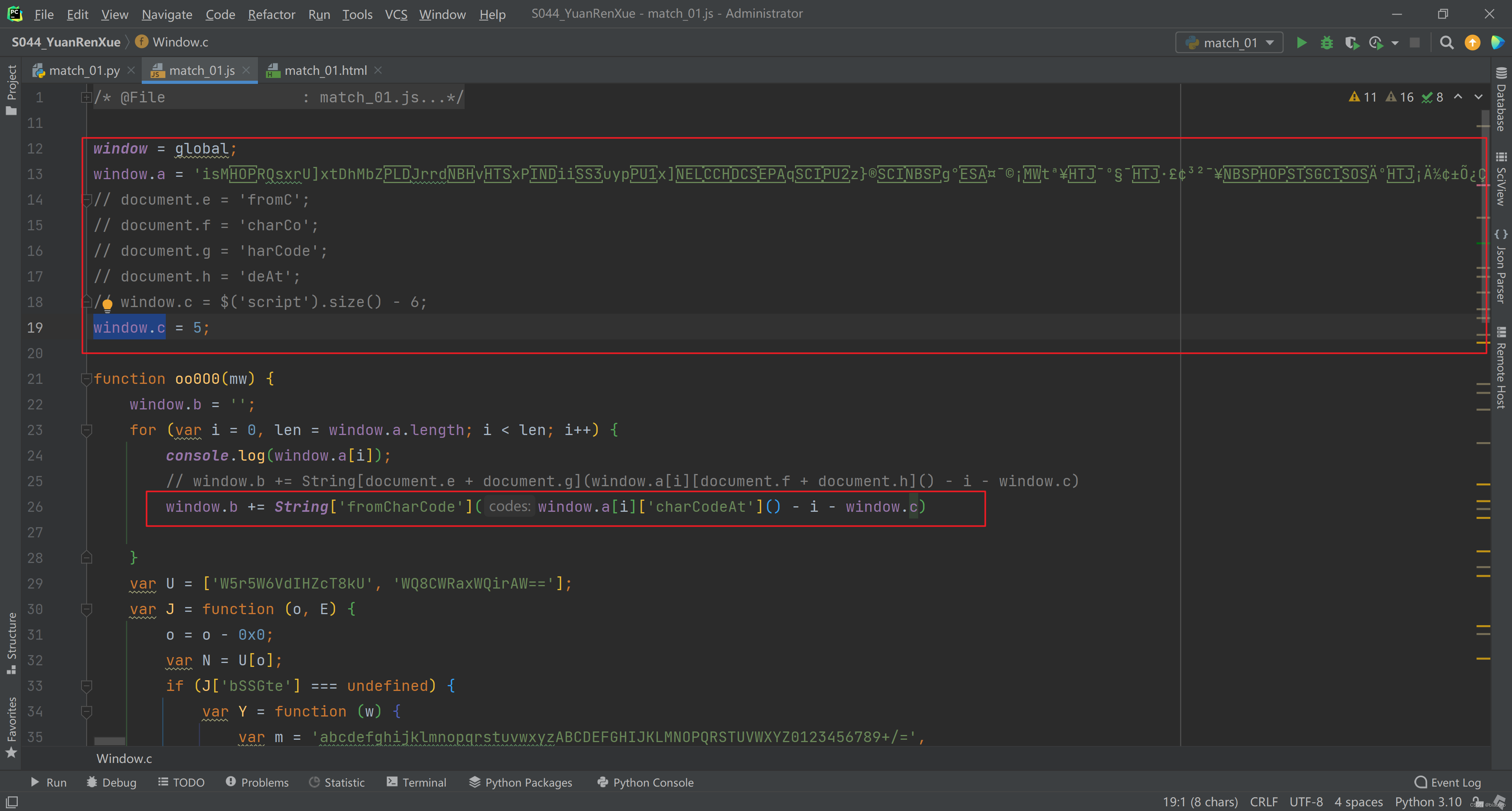
再次无脑执行,没有报错。就可以补业务逻辑了。其实就是把断点处,先后得到3个值的代码补起来就好。测试一把,完美得到 m
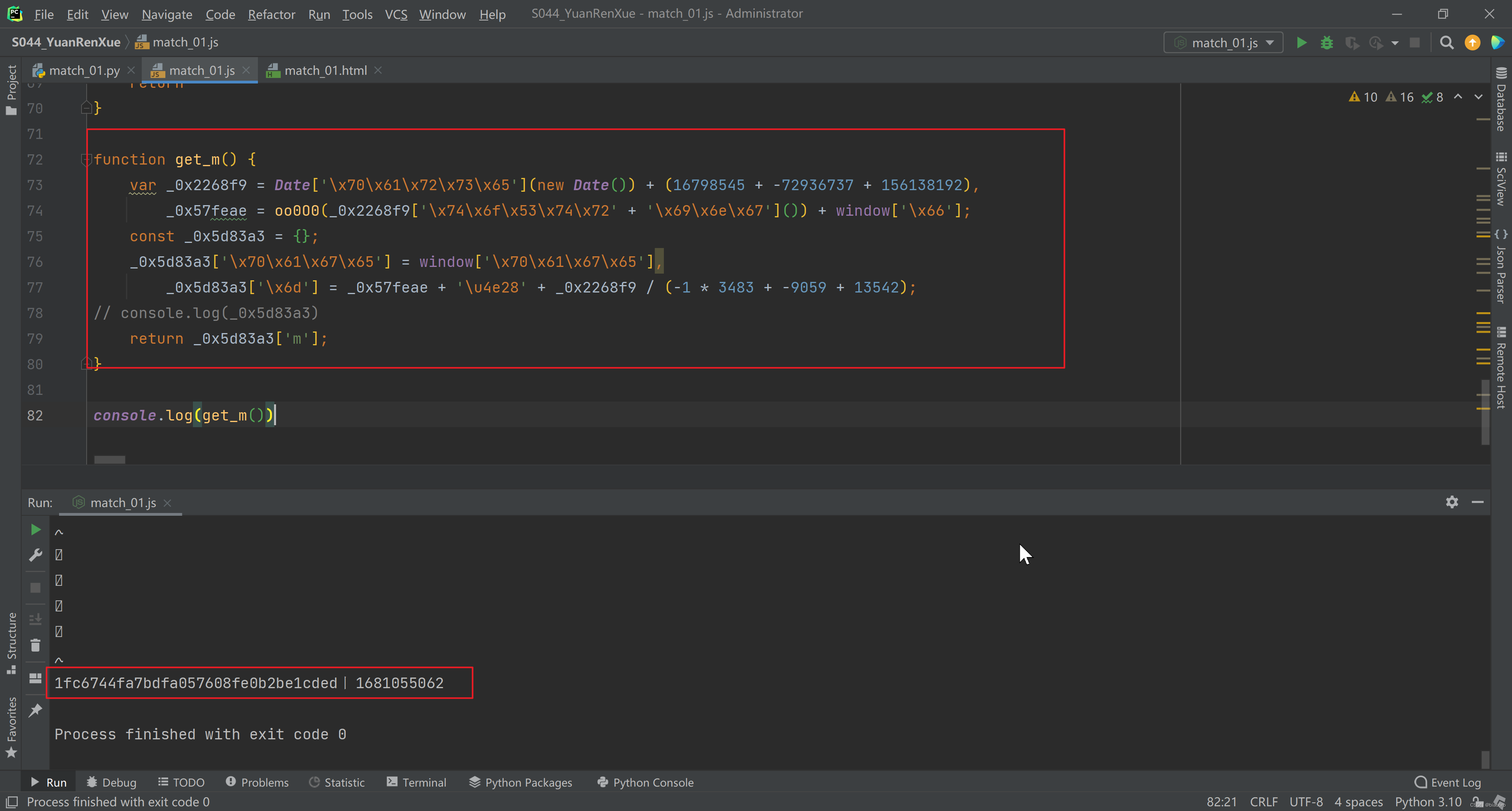
第4步:Python实现
# !/usr/bin/env python3
# _*_ coding:utf-8 _*_
"""
@File : match_01.py
@Project : S044_YuanRenXue
@CreateTime : 2023/4/8 17:14
@Author : biaobro
@Software : PyCharm
@Last Modify Time : 2023/4/8 17:14
@Version : 1.0
@Description : None
"""
import requests
import execjs
from urllib.parse import urlencodectx = execjs.compile(open('match_01.js', 'r', encoding='utf-8').read())total = 0
count = 0for i in range(1, 6):p_total = 0p_count = 0m = ctx.call('get_m')payload = {'page': i,'m': m,}url = "https://match.yuanrenxue.cn/api/match/1?" + urlencode(payload)# print(url)resp = requests.get(url)# print(resp.text)values = resp.json()['data']print(values)for value in values:p_total = p_total + value['value']p_count = p_count + len(values)print(p_total, p_count)total = total + p_totalcount = count + p_countprint(f'total:{total}, count:{count}, average:{total / count}')
第5步:得到结果
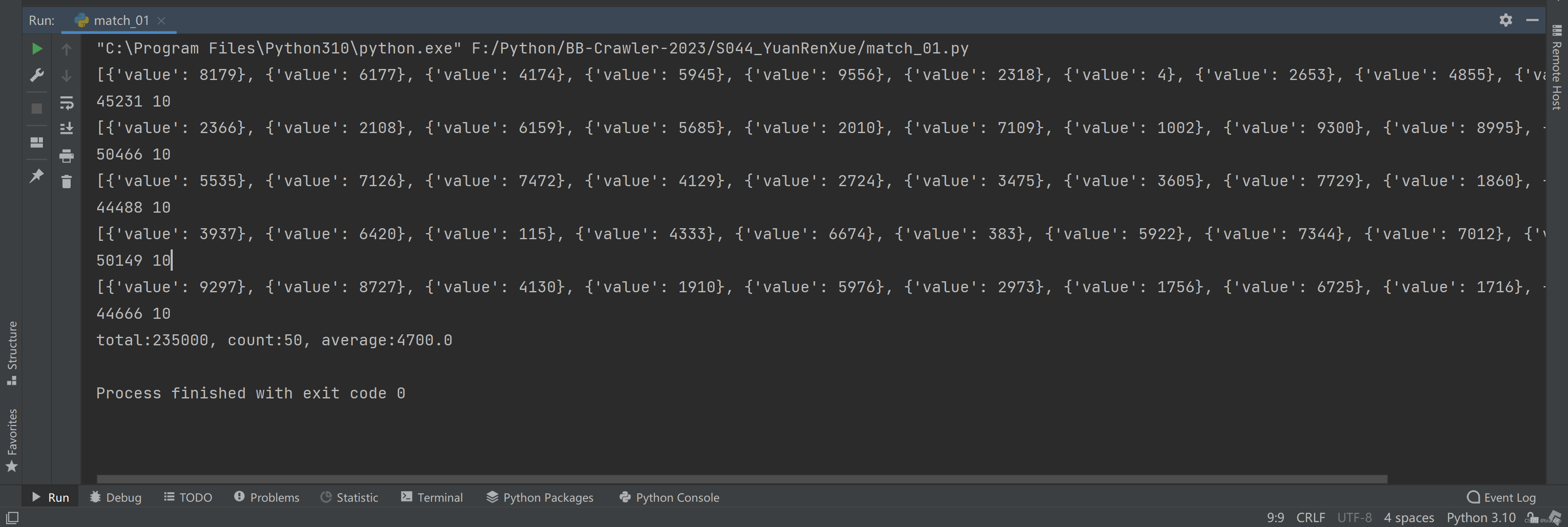
第6步:总结
为什么说网上的教程故弄玄虚? 因为解混淆、找加密函数这些完全没有必要,前提是你清楚知道你的目标是什么。