spark 读取 tar.gz 文件

一、准备工作 (Window 中使用 7-zip 生成)
一个json文件 压缩 成 tar.gz
t.json
[{"a": 1, "data": {"b": 1, "c": 2}}]
生成 tar 包
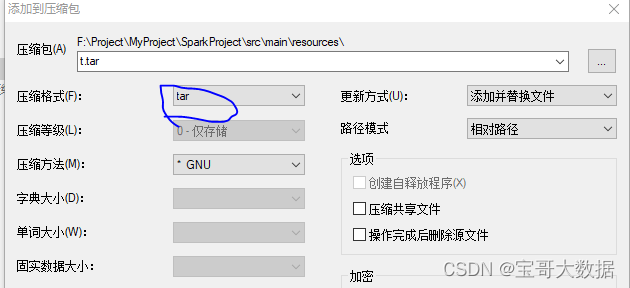
将 tar 包 在压缩为 gz
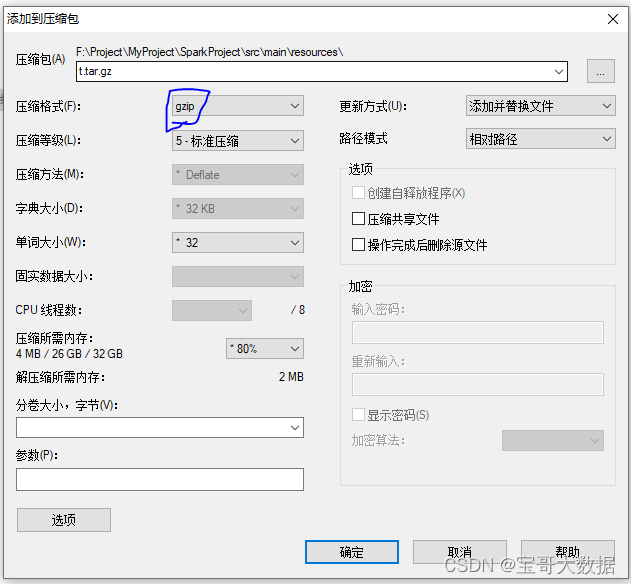
二、使用Spark 读取 tar.gz
2.1、使用 spark.read.text读取 (不采取)
val df = spark.read.text("src/main/resources/t.tar.gz")
虽然可以读取,但是 中间添加了一些文件名, 及0000777 0000000 0000000 00000000044 14411701307 007105 0 ustar 这种添加信息,对于我们解析数据很困难
+--------------------+
|value |
+---------------------+
|t.json 0000777 0000000 0000000 00000000044 14411701307 007105 0 ustar [{"a": 1, "data": {"b": 1, "c": 2}}] |
2.2、使用 spark.sparkContext.binaryFiles
有一个readBinaryFiles可以访问zip二进制数据的地方,然后您可以使用java或scala中的常规ZIP处理。
这种方法对于相对较小的tar档案来说是很好的,但不适用于较大的档案。
一个更好的解决方案似乎是将tar文件 transformation为hadoop序列文件,这些文件是可分割的,因此可以在spark中并行读取和处理(而不是tar文件)。
package com.chb.spark.sql.datasourceimport java.nio.charset.{Charset, StandardCharsets}import org.apache.spark.input.PortableDataStream
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import org.apache.commons.compress.archivers.tar.TarArchiveInputStream
import org.apache.commons.compress.compressors.gzip.GzipCompressorInputStreamimport scala.util.Tryobject TarGz {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("tarGz").master("local[*]").getOrCreate()// val df = spark.read.json("src/main/resources/t.tar.gz")import spark.implicits._// (文件名, 二进制数据流)val rdd: RDD[(String, PortableDataStream)] = spark.sparkContext.binaryFiles("src/main/resources/t.tar.gz")val df = rdd.flatMapValues(x => extractFiles(x).toOption).mapValues(_.map(decode())).map(_._2).flatMap(x => x).flatMap { x => x.split("\\n") }.toDF()df.show(false)}def extractFiles(ps: PortableDataStream, n: Int = 1024) = Try {val tar = new TarArchiveInputStream(new GzipCompressorInputStream(ps.open))Stream.continually(Option(tar.getNextTarEntry))// Read until next exntry is null.takeWhile(_.isDefined)// flatten.flatMap(x => x)// Drop directories.filter(!_.isDirectory).map(e => {Stream.continually {// Read n bytesval buffer = Array.fill[Byte](n)(-1)val i = tar.read(buffer, 0, n)(i, buffer.take(i))}// Take as long as we've read something.takeWhile(_._1 > 0).map(_._2).flatten.toArray}).toArray}def decode(charset: Charset = StandardCharsets.UTF_8)(bytes: Array[Byte]) = new String(bytes, charset)
}结果:
+------------------------------------+
|value |
+------------------------------------+
|[{"a": 1, "data": {"b": 1, "c": 2}}]|
+------------------------------------+
2.2.1、问题 (暂未解决)
在我生产的时候,出现 解析json结构失败,报错 empty.max null。
这个最后退而求次, 由将tar.gz解压,然后上传,spark.read.json去解析数据。
参考:
https://cloud.tencent.com/developer/article/1145756
https://www.codenong.com/48034069/
http://cn.voidcc.com/question/p-ahdefbij-pv.html