李宏毅2021春季机器学习课程视频笔记7-模型训练不起来问题(自动调整学习率)


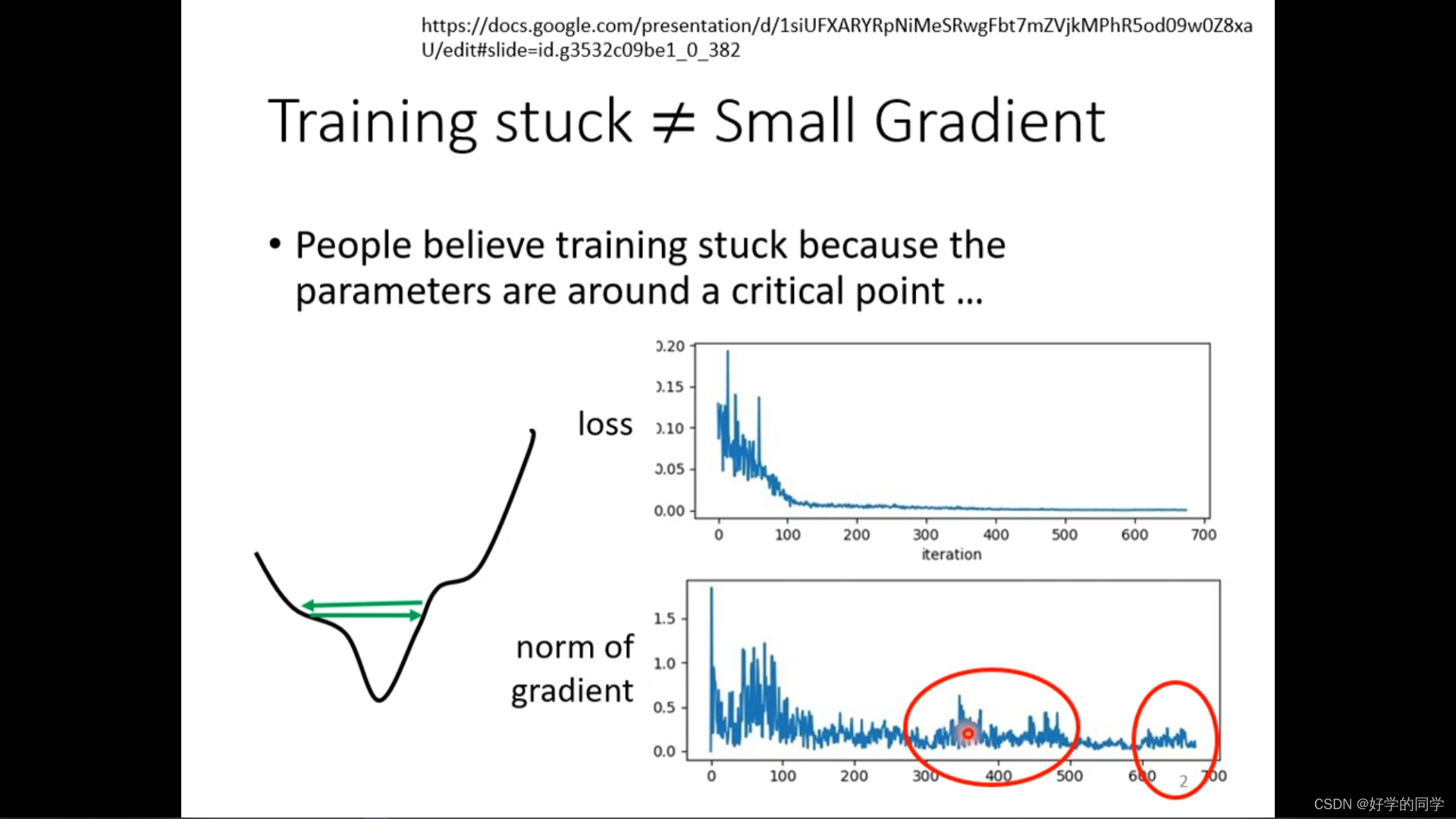
当模型在训练过程中发现损失函数不再下降,可能会猜测由于模型参数进入了Critical Point。但是在实际中并不一定是Critical Point,其gradient并没有非常小。这样可能模型在Minima附近的跳动。
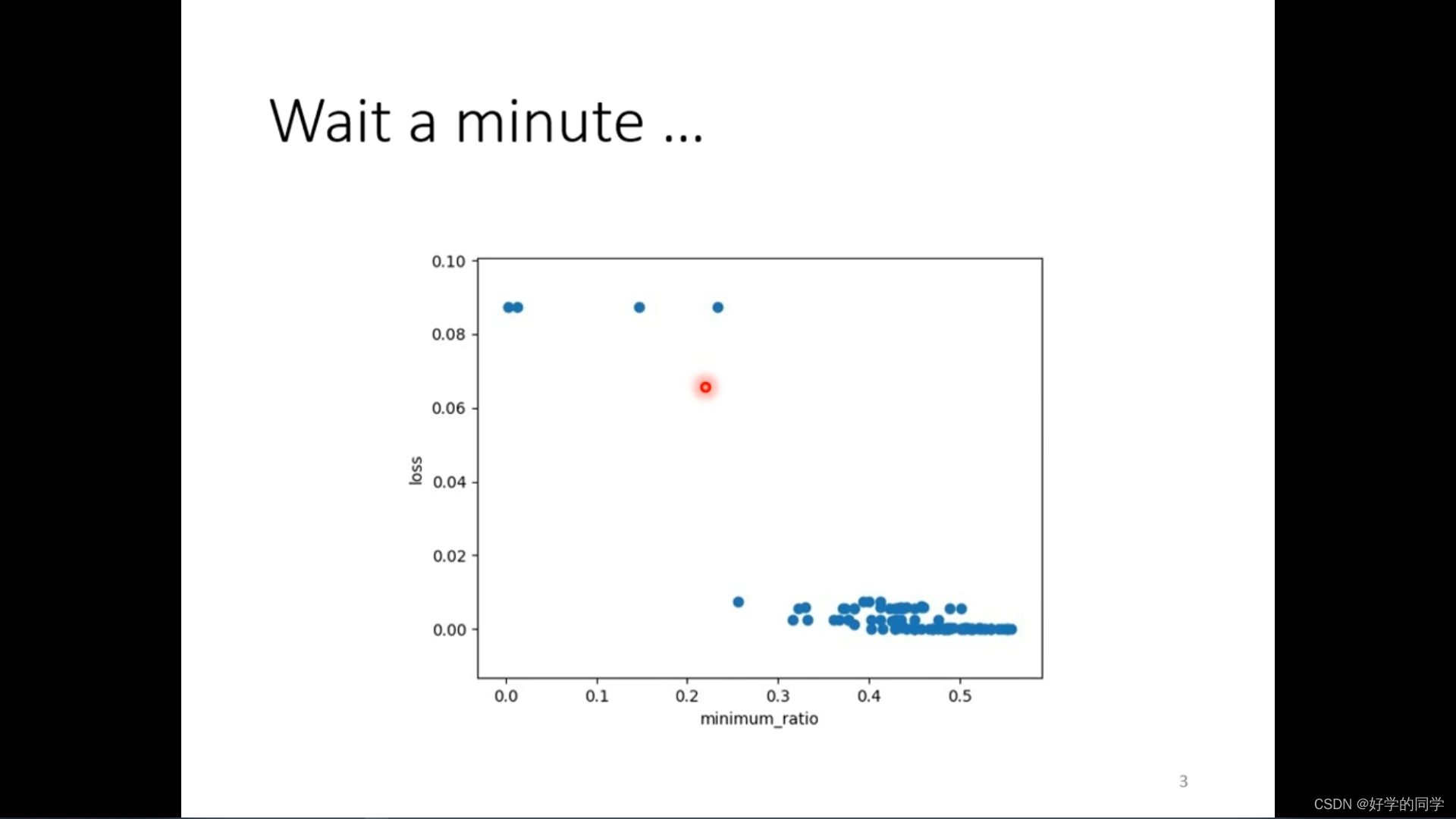
模型中在没有critical point时模型的训练也比较困难。
Convex Surface的优化流程:
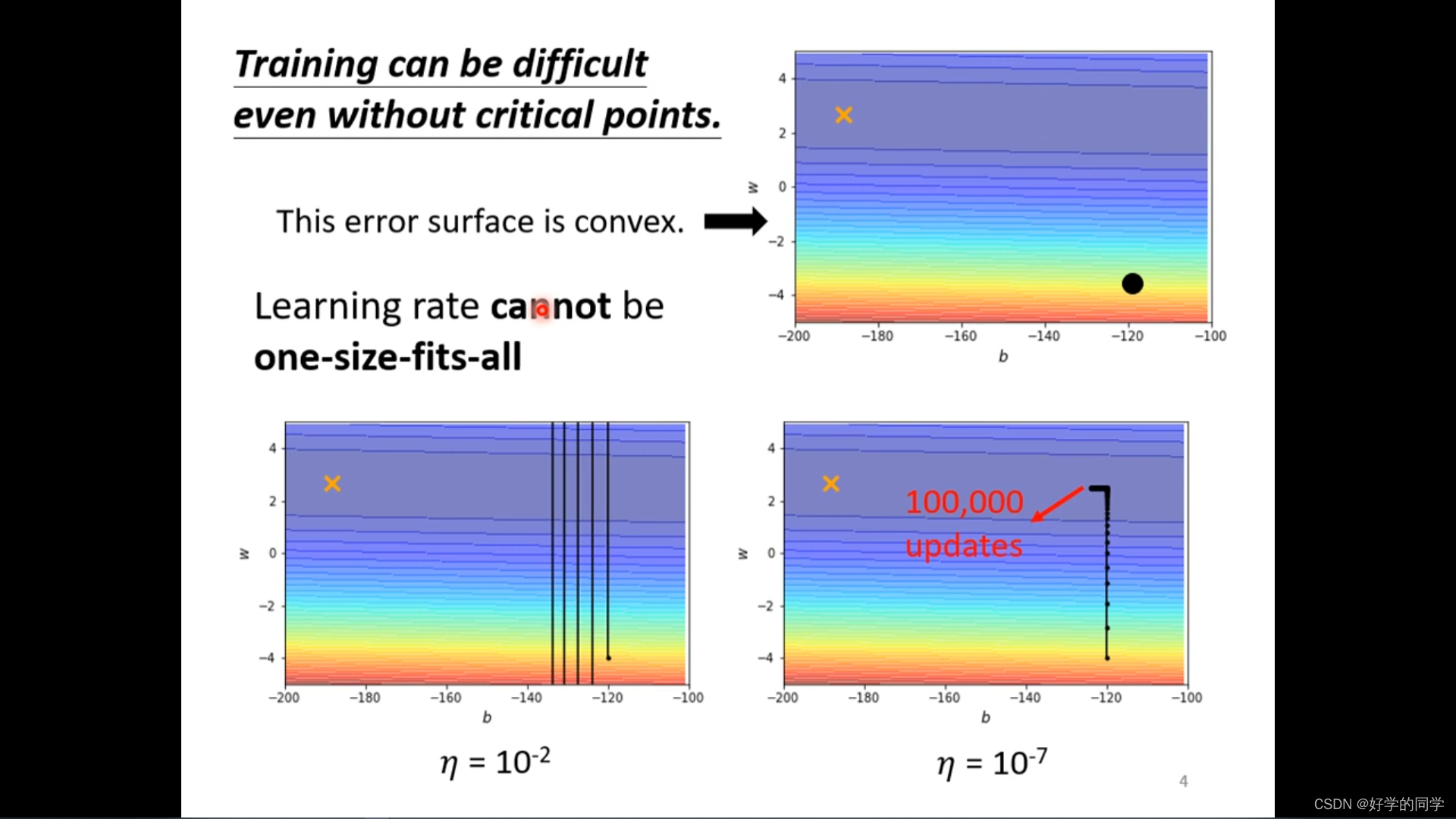
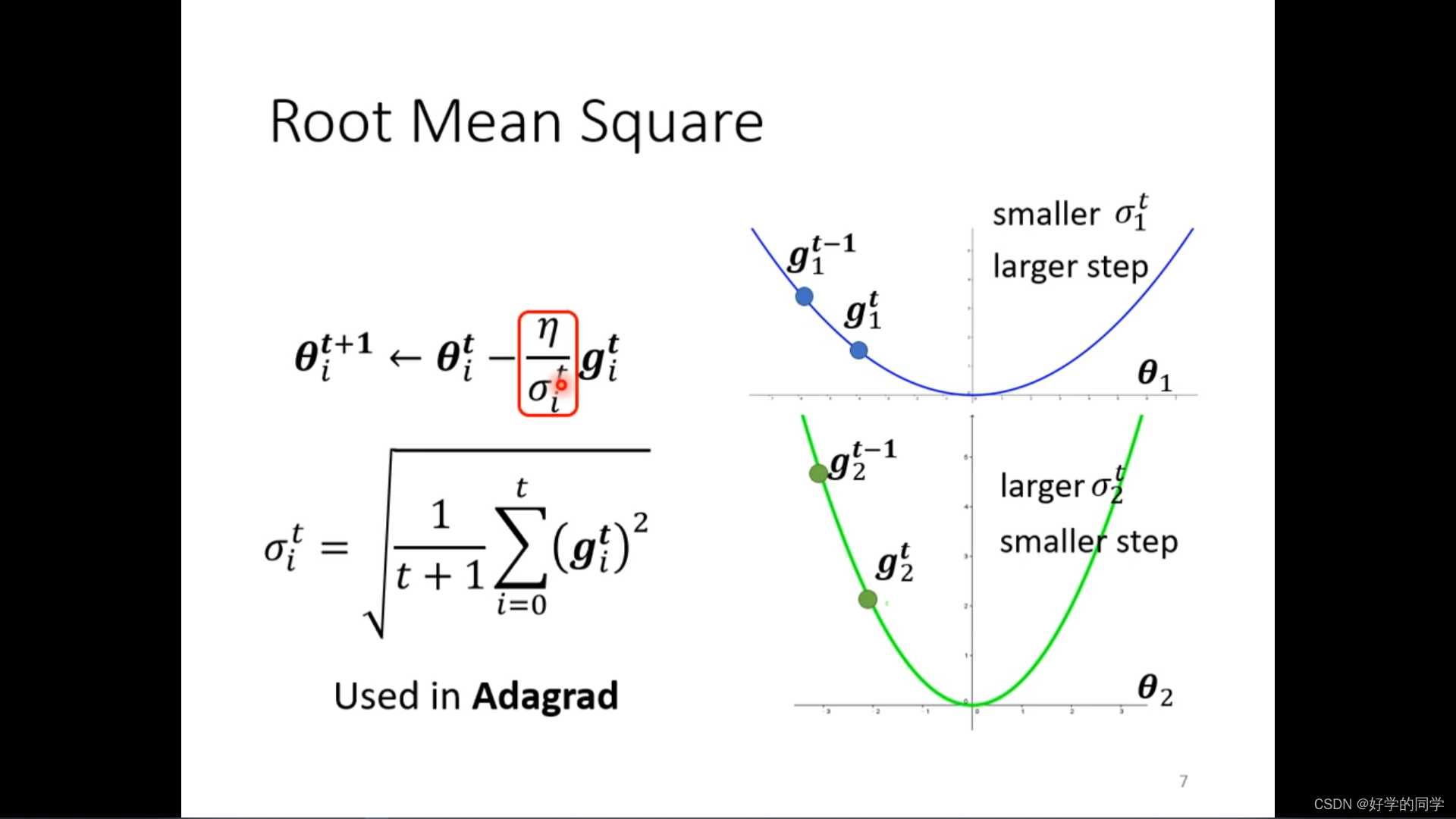
不同的学习率设置:当损失函数关于参数下降比较陡的时候,设置比较大的学习率,当下降比较平缓的时候就采用比较小的学习率,同时学习率的设置与参数有关,与迭代的次数也有关。
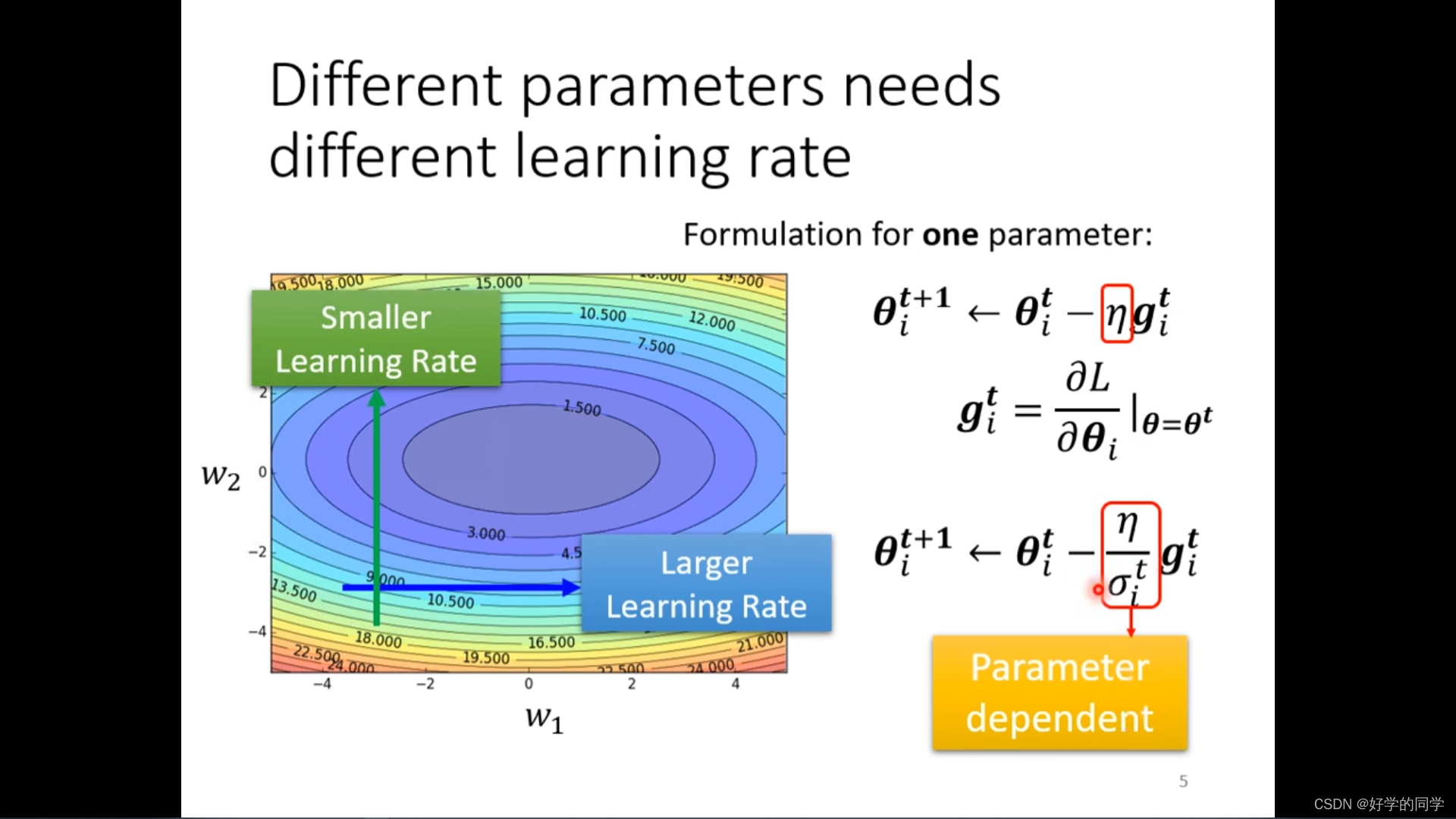
这一方法被采用在Adagrad中
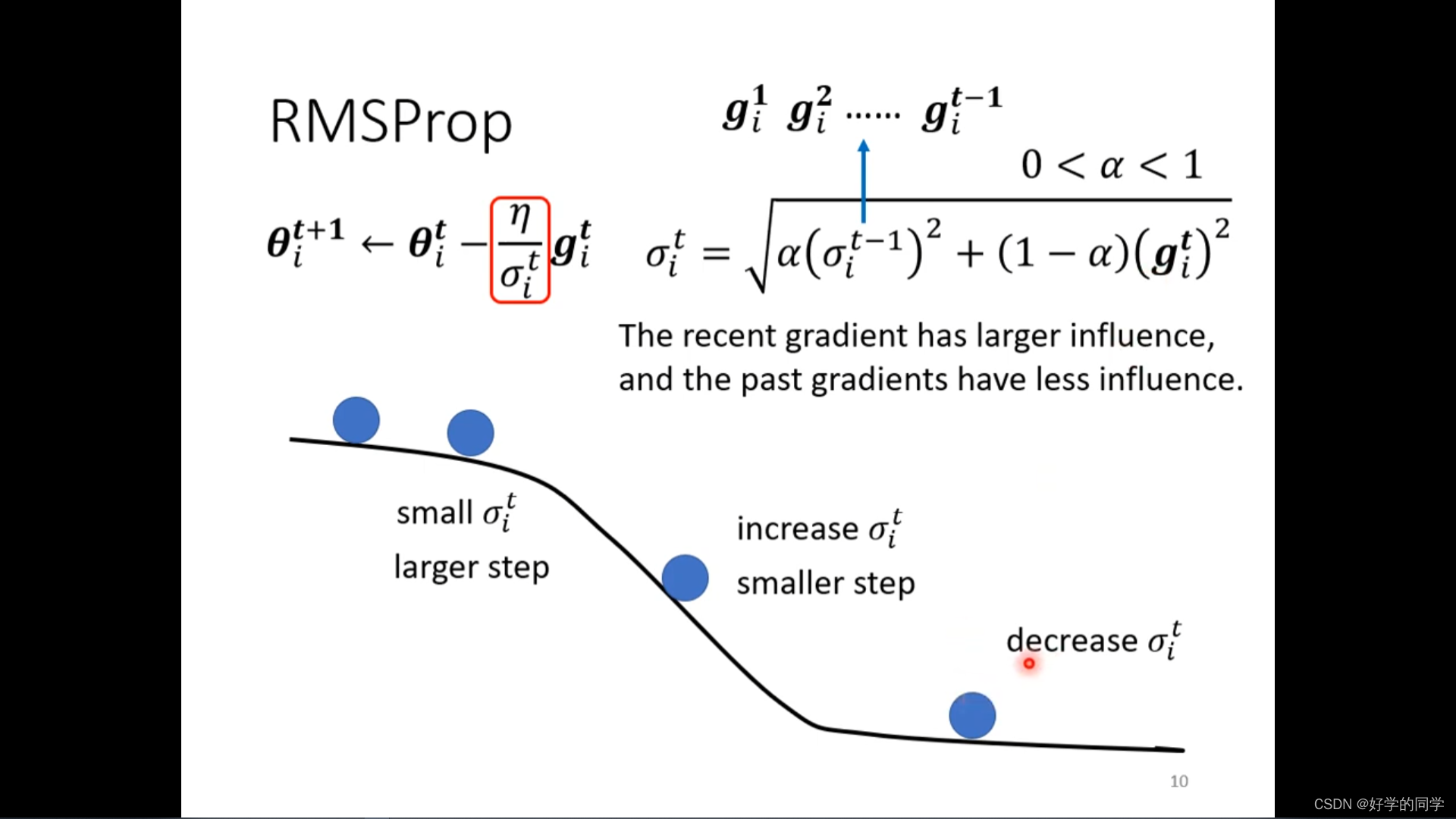
RMSProp方法

Adam : RMSProp + Momentum
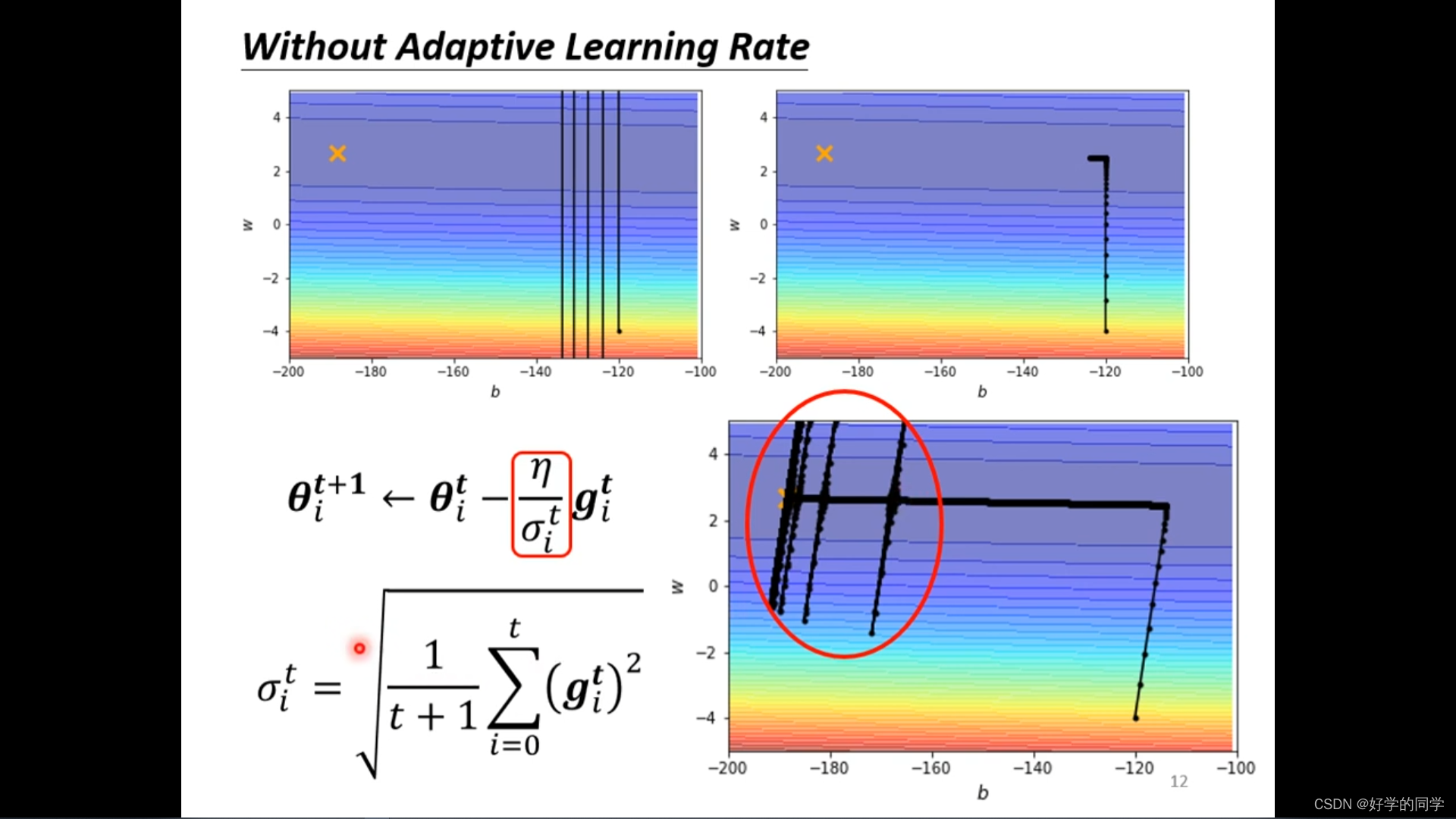
 在没有使用自适应的学习率时候,在下图右下角中,在训练中模型的梯度开始很大时候,叠加的次数还比较小,整个学习率相对较大,Loss快速的下降,但是当在平缓的地方,长时间的小梯度就会导致模型的学习率暴增,突然出现向左右两侧喷射的现象,但是也会逐步收敛回来。
在没有使用自适应的学习率时候,在下图右下角中,在训练中模型的梯度开始很大时候,叠加的次数还比较小,整个学习率相对较大,Loss快速的下降,但是当在平缓的地方,长时间的小梯度就会导致模型的学习率暴增,突然出现向左右两侧喷射的现象,但是也会逐步收敛回来。
针对于上述问题,可以采用Learning Rate Scheduling来解决。考虑是关于时间的参数,随着时间进行,模型的训练逐步完成,并更新参数,使得
减小。
Learning Rate Decay (持续变小)
Warm Up(先变大后变小)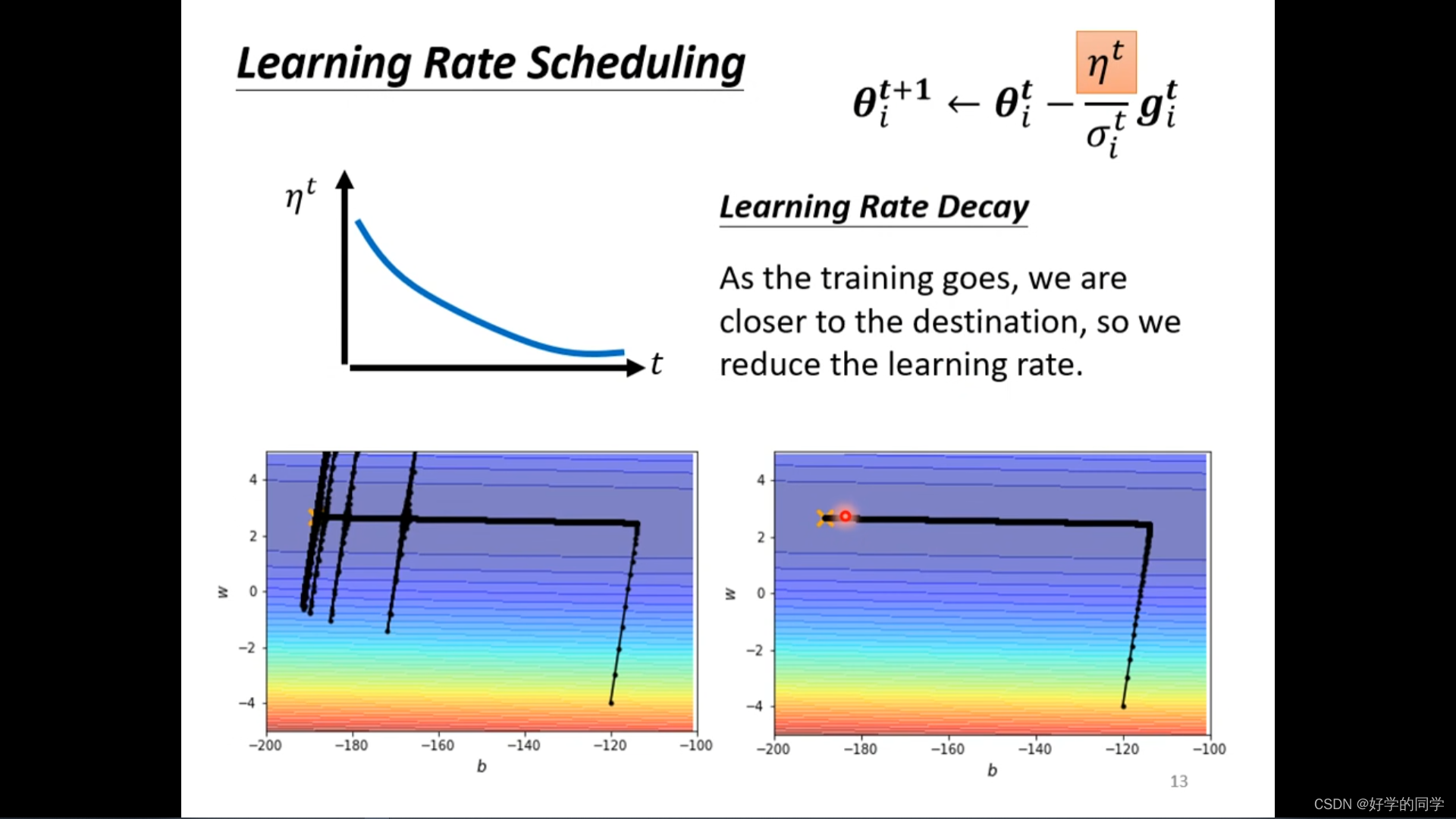
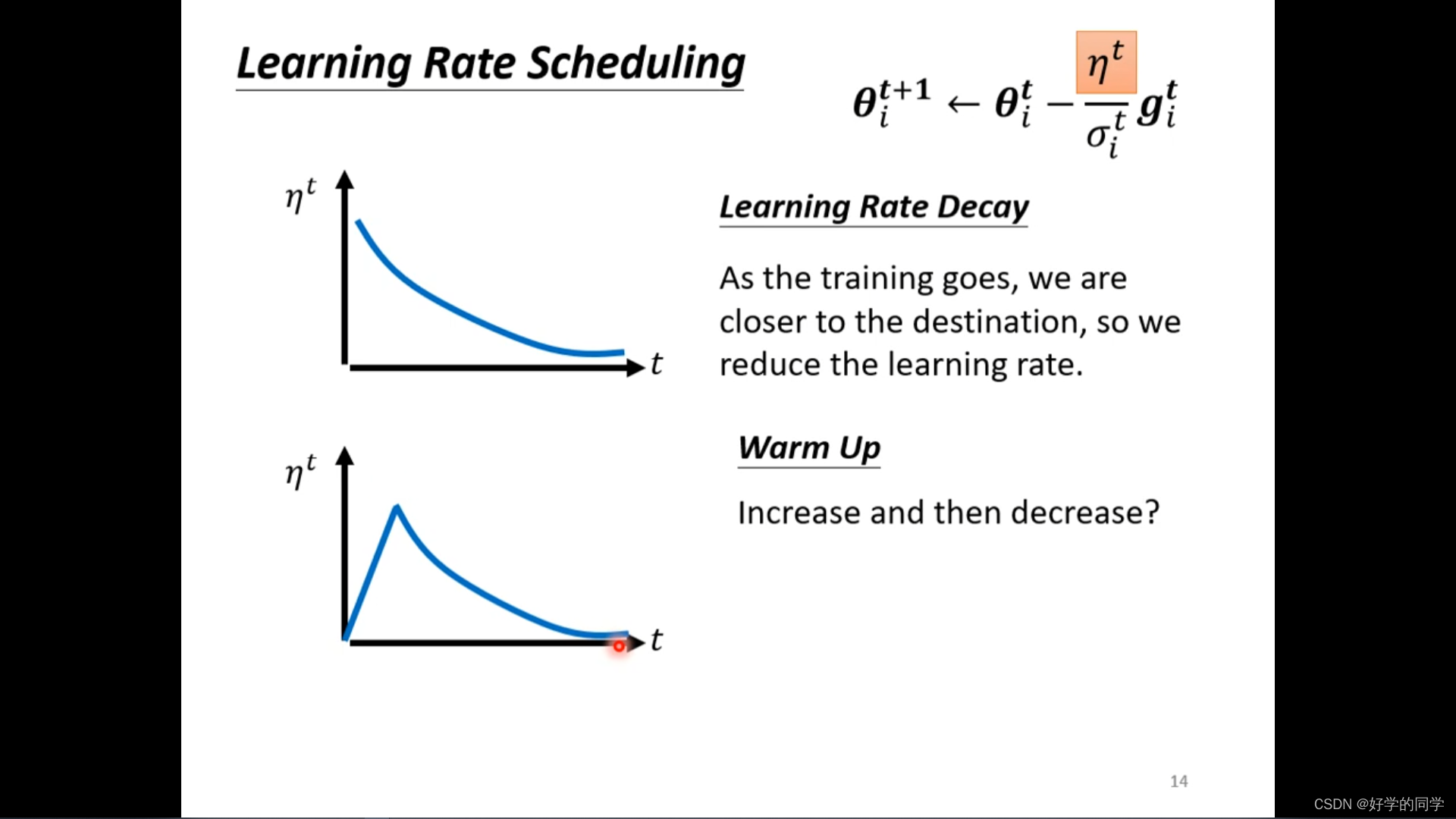
Residual Network和Transformer(均采用了warm up)

可以从统计的角度理解,开始统计信息较少,对模型不够熟悉,因此在更新参数的过程中都是比较谨慎的,但是随着统计信息的增加,模型的状态逐步熟悉并先增大学习率,后减小。
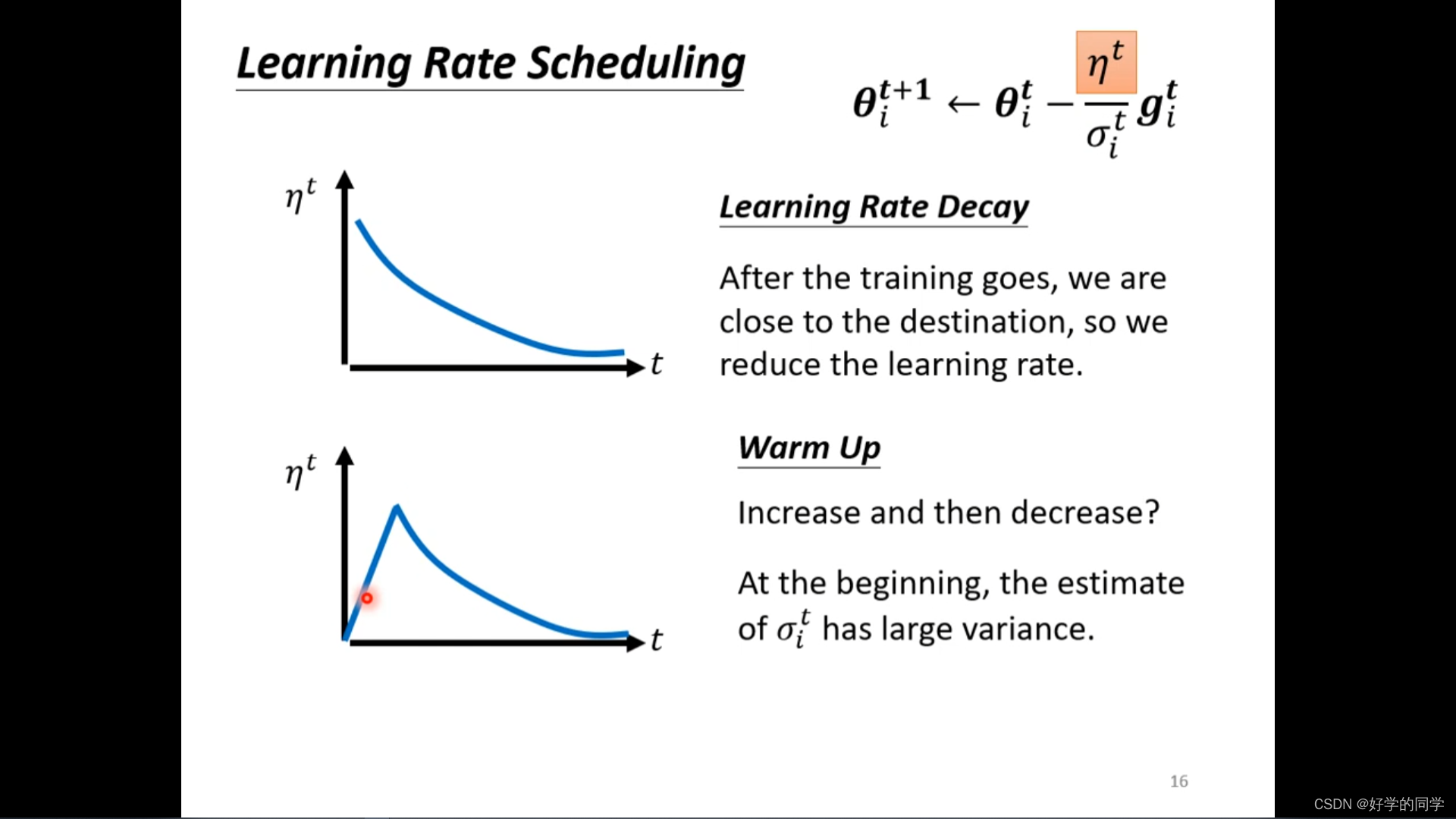

后续考虑:如何将一个难以优化的Loss调整成为一个可以很好进行最优值寻找的形式。
