大数据五次作业回顾

文章目录
-
- 1. 大数据作业1
-
- 1.本地运行模式部分
- 2. 使用scp安全拷贝部分
- 2. 大数据作业2
-
- 1、Rrsync远程同步工具部分
- 2、xsync集群分发脚本部分
- 3、集群部署部分
- 3. 大数据作业3
-
- 1. 配置历史服务器及日志
- 2. 日志部分
- 3. 其他
- 4. 大数据作业4
-
- 编写本地wordcount案例
- 一、源代码
- 二、信息截图
- 5. 大数据作业5
-
- 编写手机号码流量统计案例
- 一、源代码
- 二、信息截图
1. 大数据作业1
作业内容:
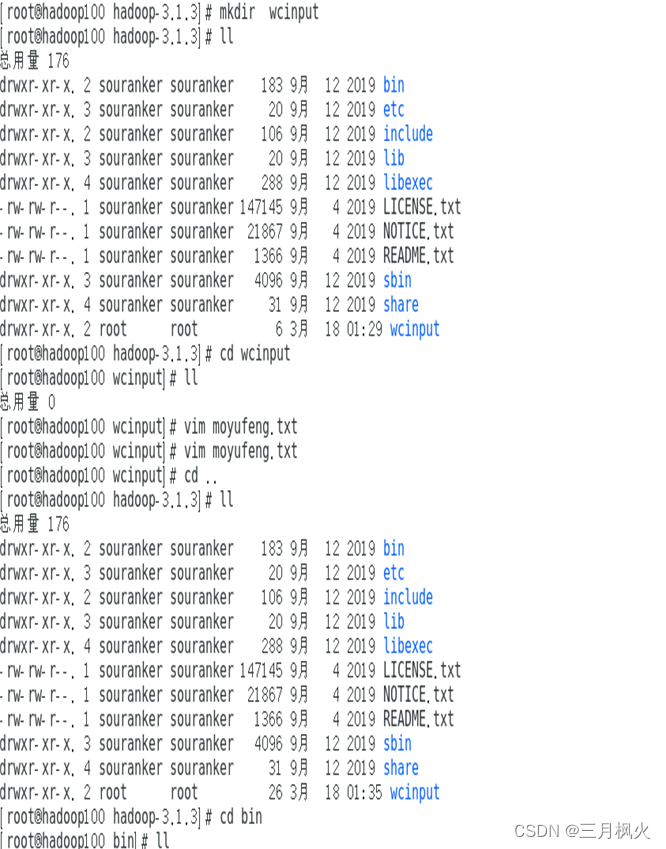
1.本地运行模式
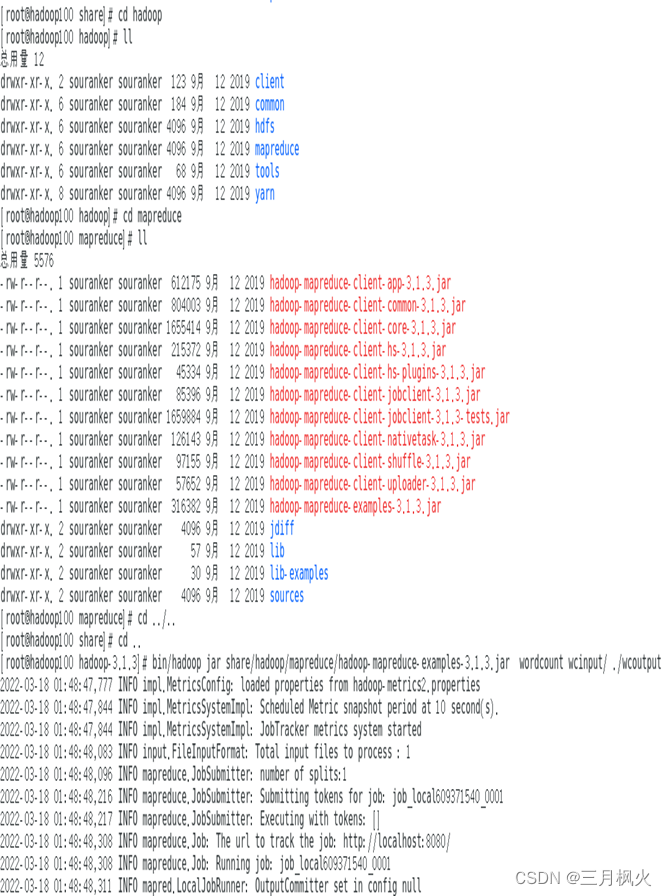
1)在hadoop100中创建wcinput文件夹
2)在wcinput文件下创建一个姓名.txt文件
3)编辑文件,在文件中输入单词,单词包括自己姓名
4)执行程序,并查看结果,要求结果打印每个词出现了几次
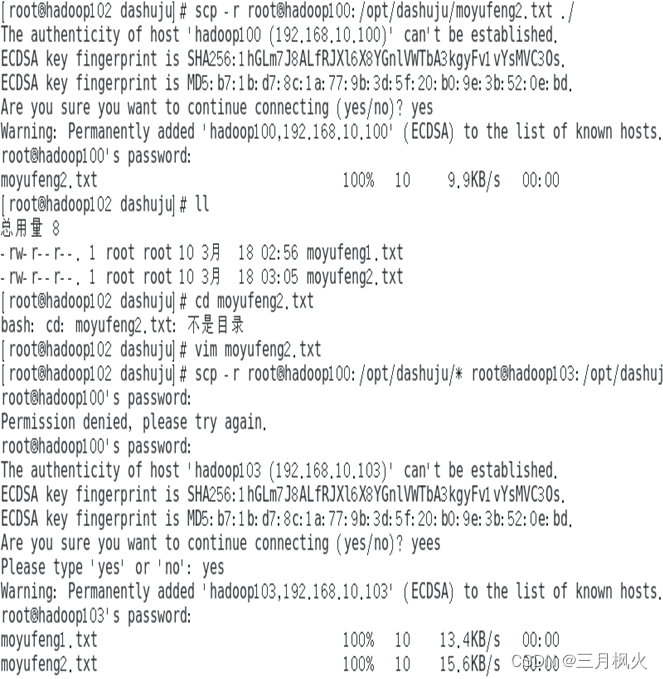
2.使用scp安全拷贝
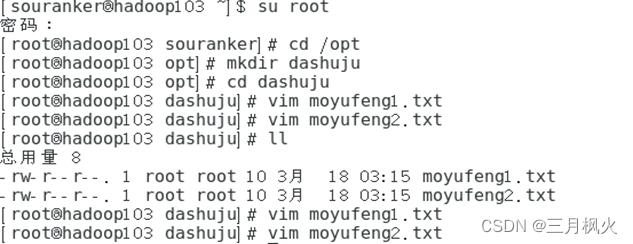
1)分别在hadoop100、hadoop102、hadoop103中新建文件夹及自己姓名1.txt、自己姓名2.txt文件
1)在hadoop100上将姓名1.txt文件拷贝至102得对应文件夹中
2)在hadoop102上拷贝hadoop100中姓名2.txt文件
3)在hadoop102上将hadoop100中姓名1.txt、姓名2.txt文件拷贝到hadoop103对应文件夹中
1.本地运行模式部分

2. 使用scp安全拷贝部分



2. 大数据作业2
作业内容:
-
Rrsync远程同步工具
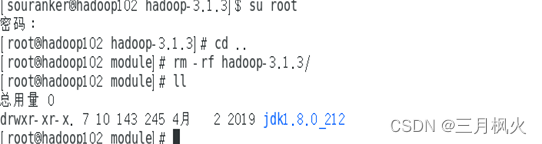
1)删除hadoop102中/opt/module下hadoop-3.1.3文件夹
2)使用rsync将hadoop中/opt/module下hadoop-3.1.3文件夹发送至hadoop102相同目录下 -
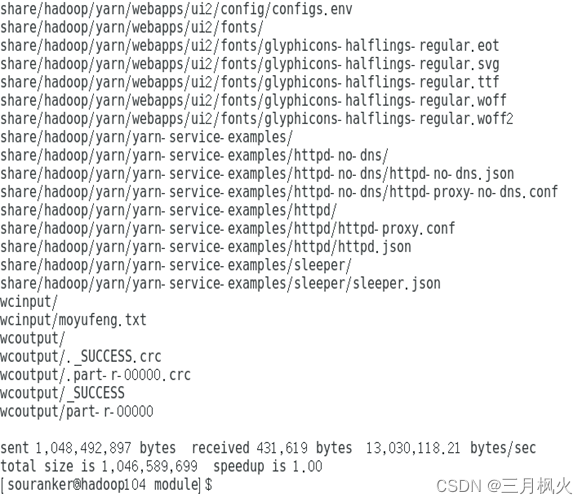
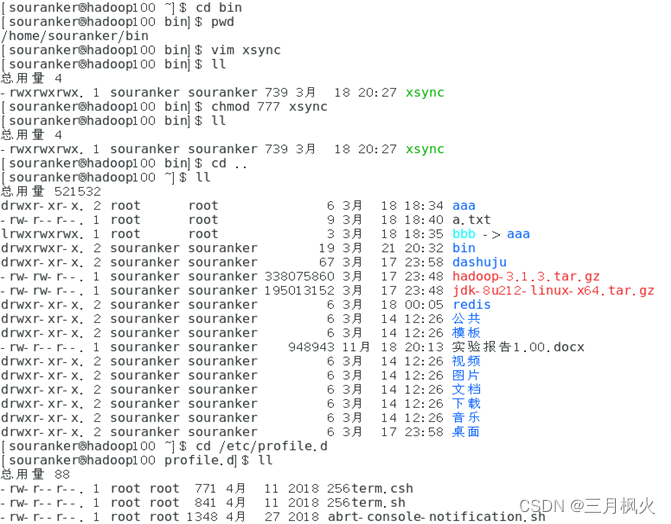
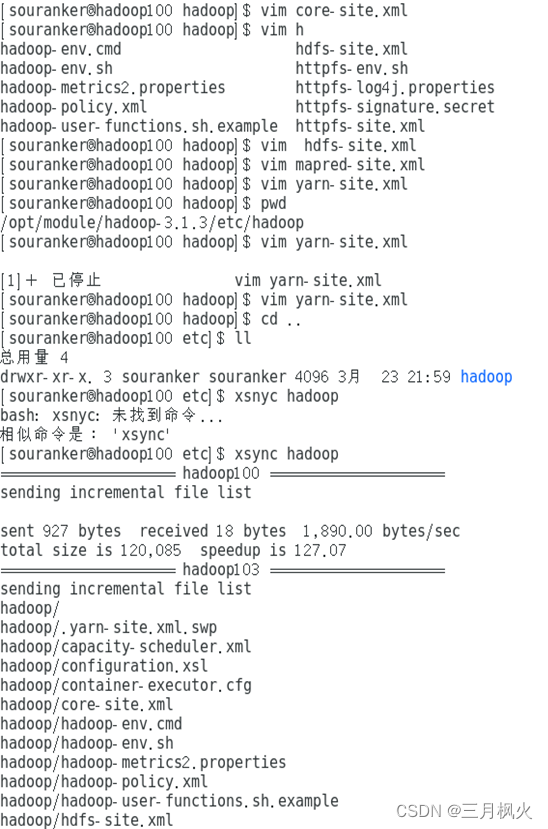
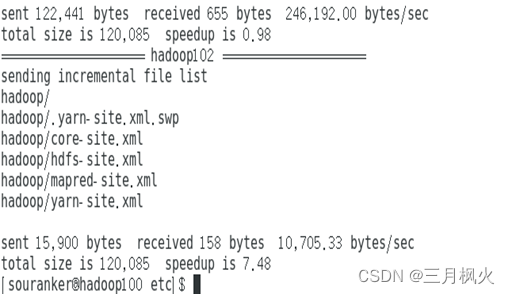
xsync集群分发脚本
- 理解脚本内容
- 在hadoop中编写脚本
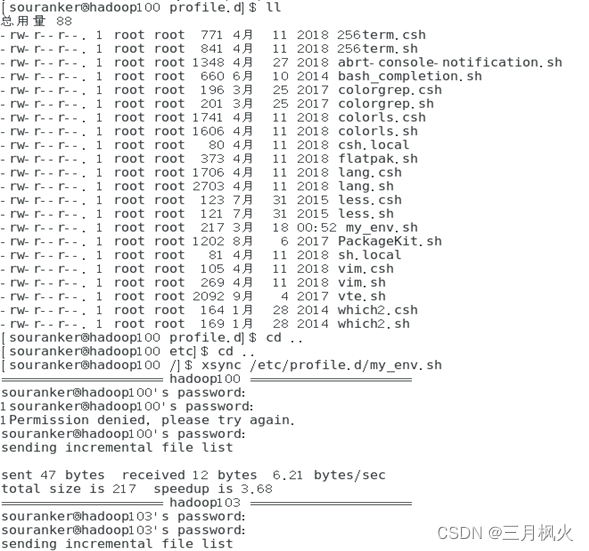
- 将环境变量my_env分发到102和103服务器中,并实现免密功能
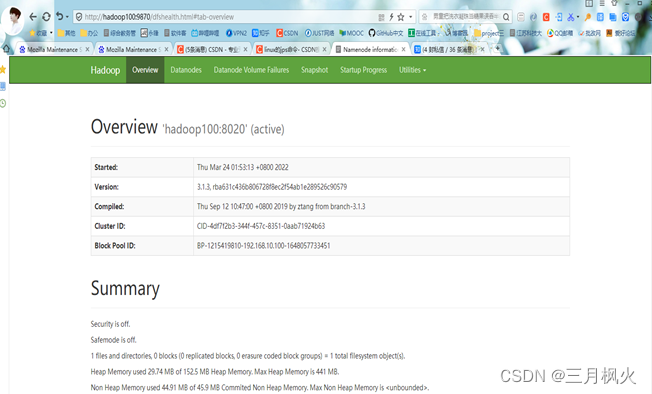
- 集群部署
1)修改配置文件并启动集群
2)分别在本机和集群创建姓名+学号文件夹
3)创建姓名.txt并上传至集群中
1、Rrsync远程同步工具部分
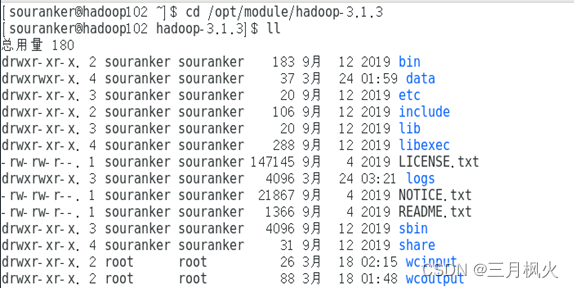

2、xsync集群分发脚本部分



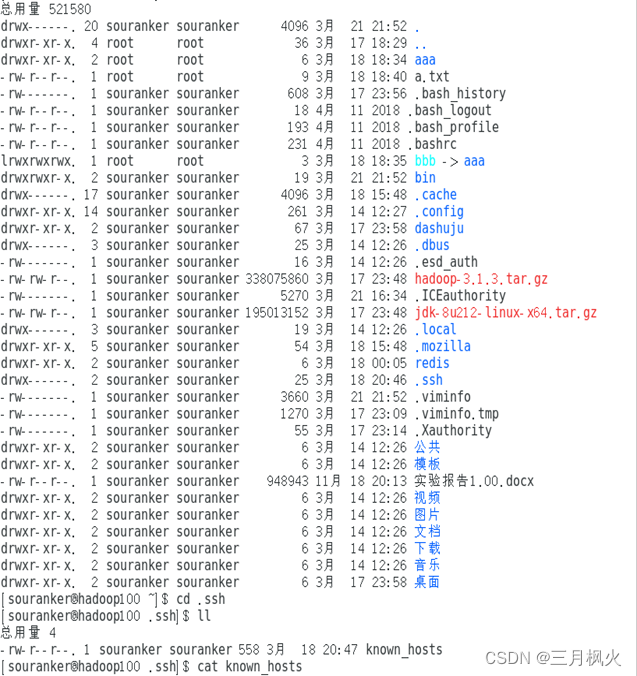
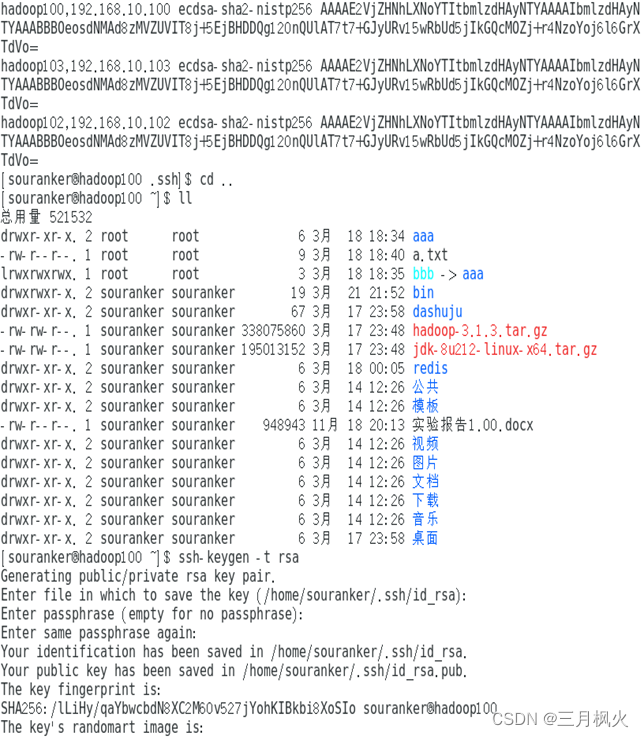
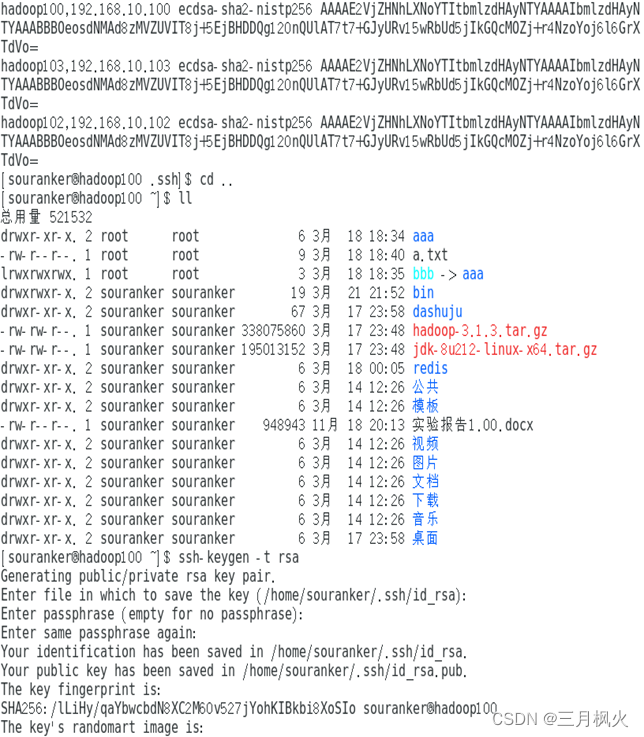
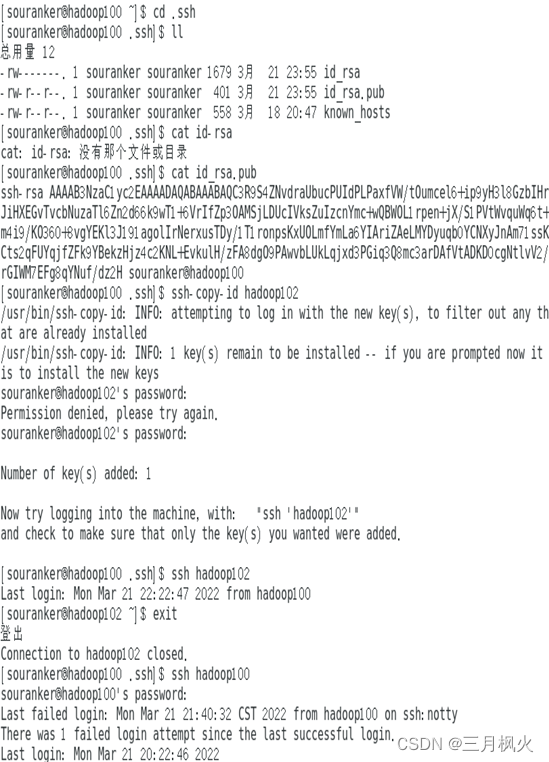


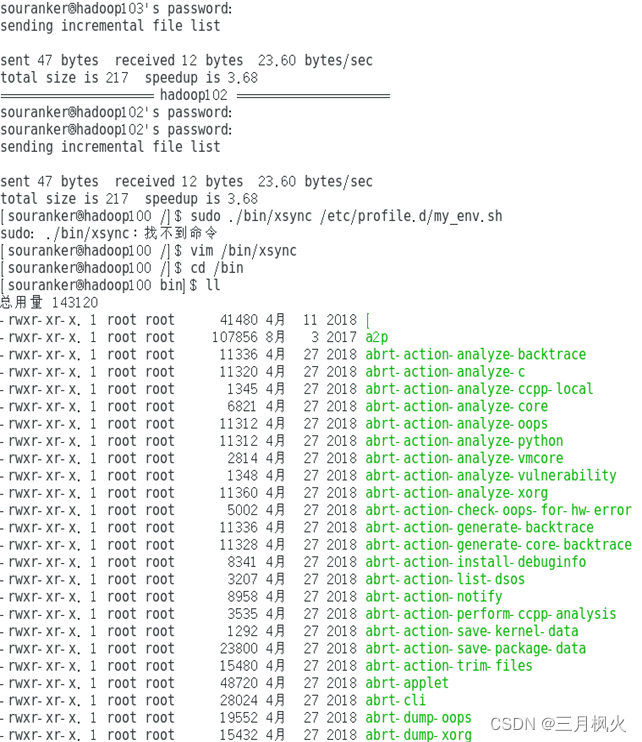

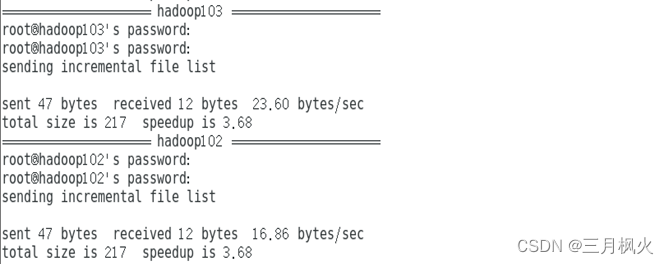


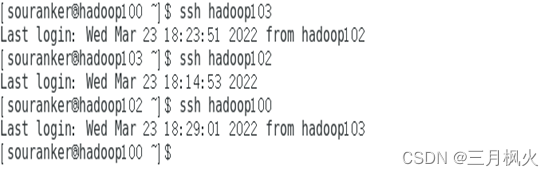
3、集群部署部分
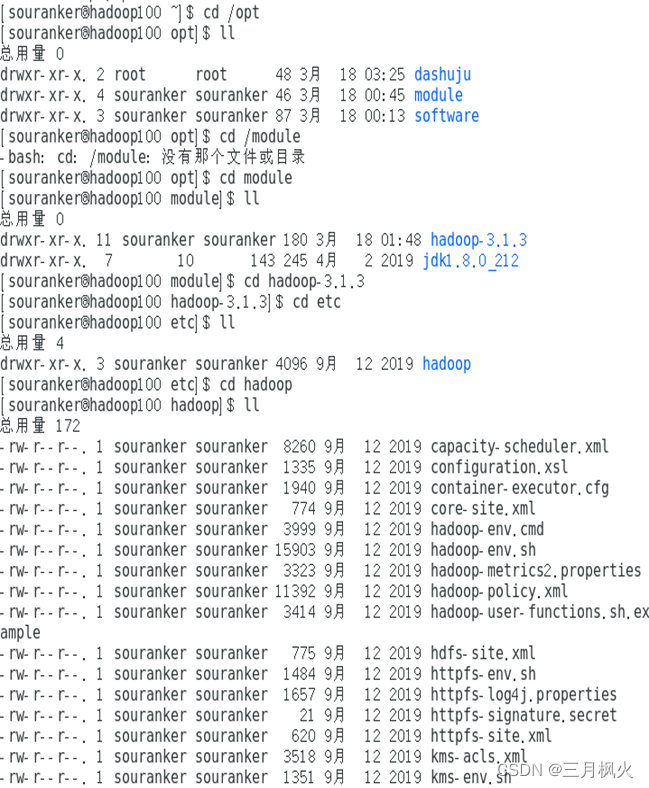
3.1 配置core-site.xml

3.2 配置hdfs-site.xml

3.3 配置mapred-site.xml

3.4 配置yarn-site.xml

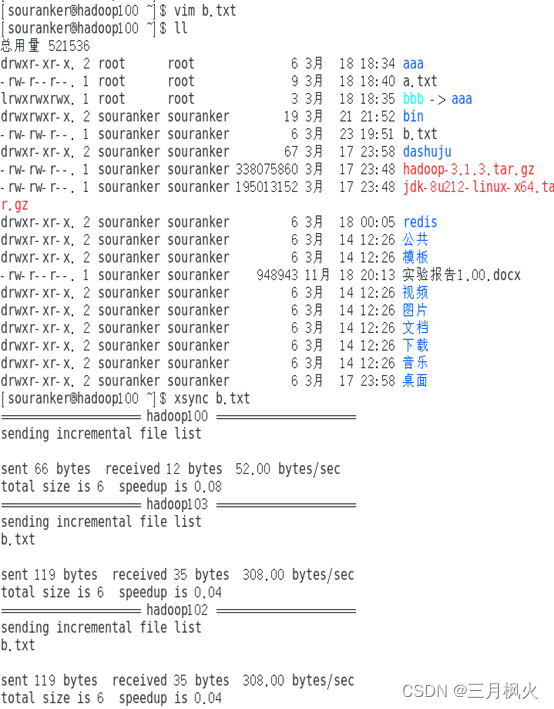

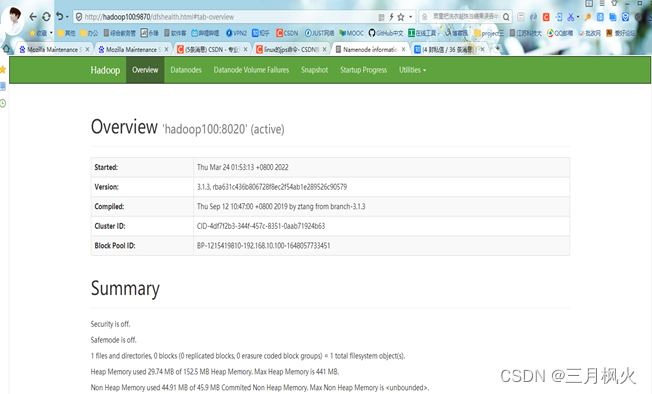
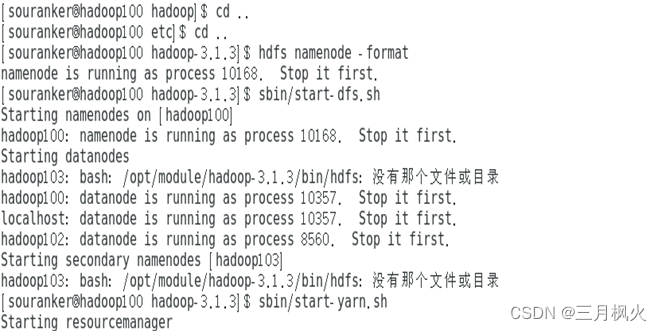
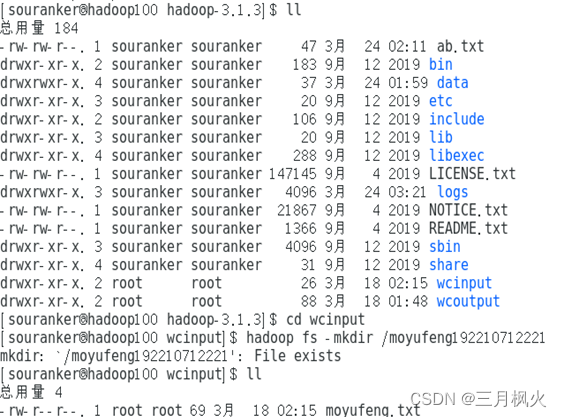

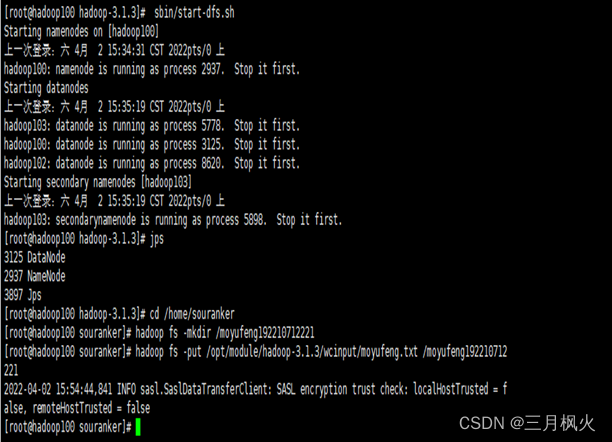

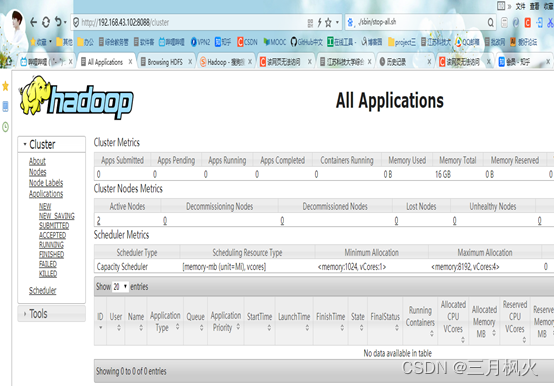
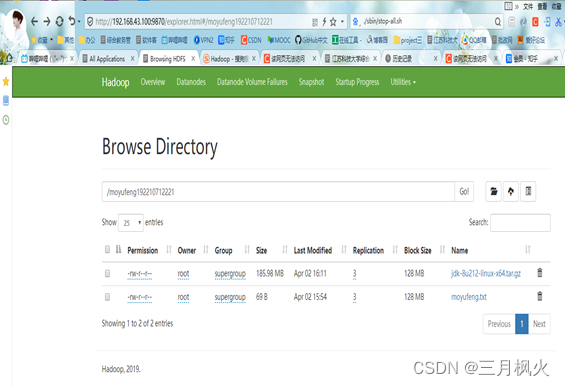
3. 大数据作业3
1. 配置历史服务器及日志
历史服务器部分:
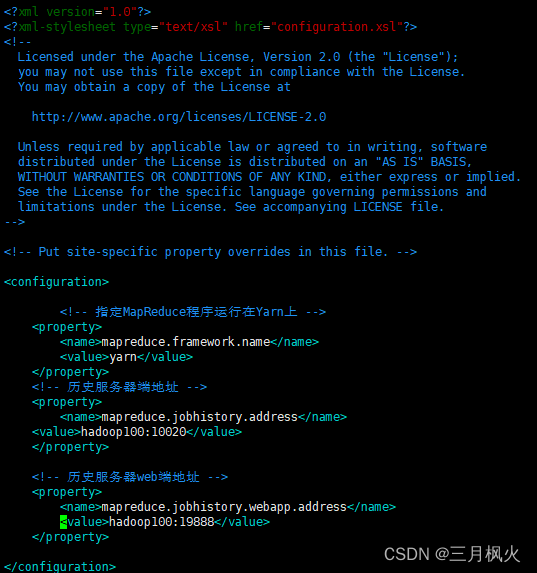
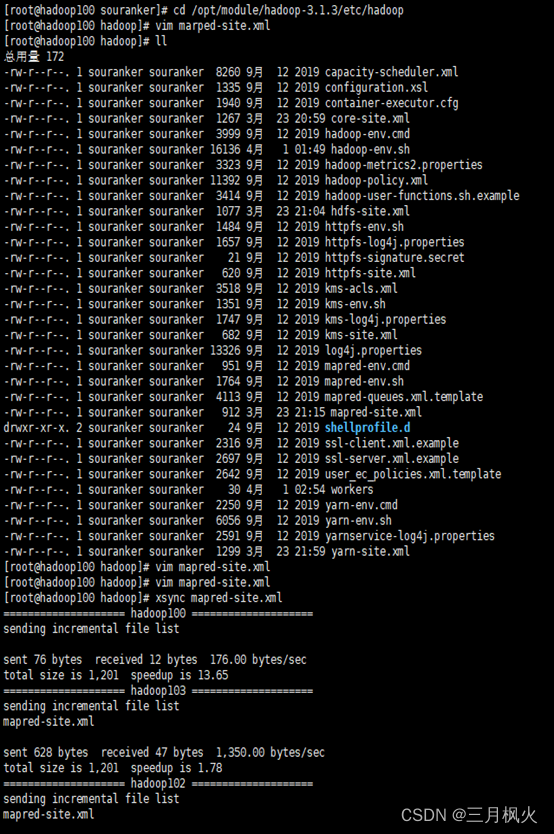
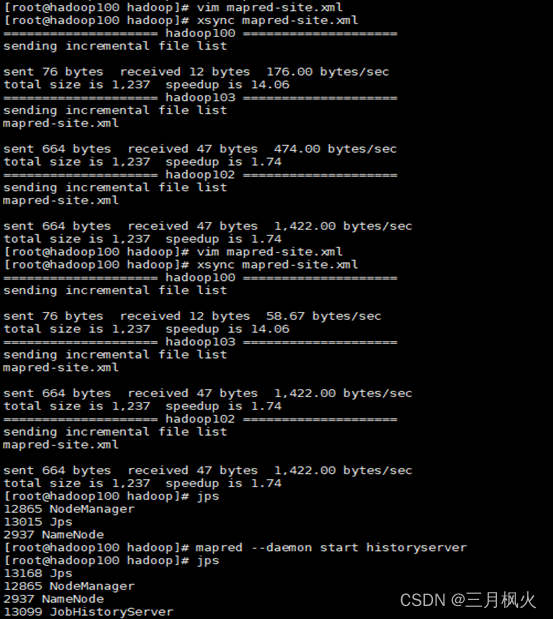
2. 日志部分
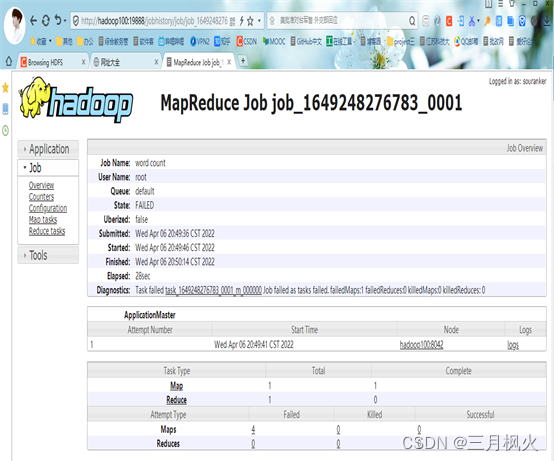
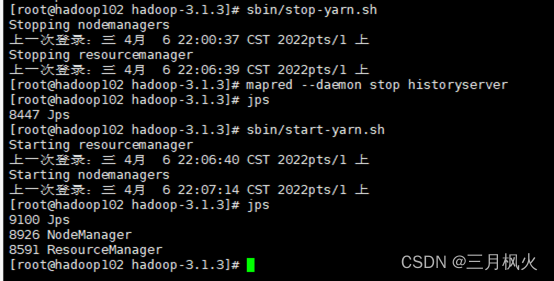
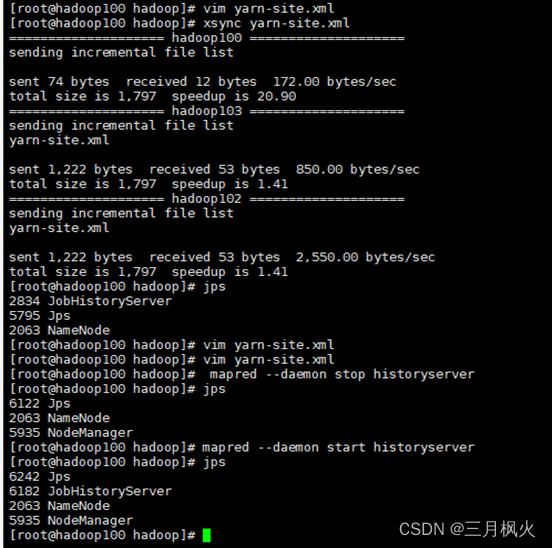
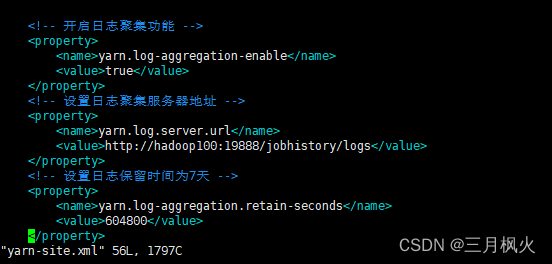
3. 其他
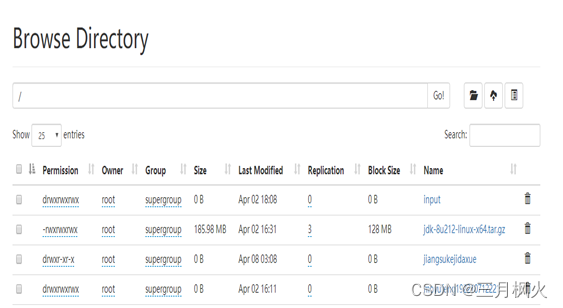
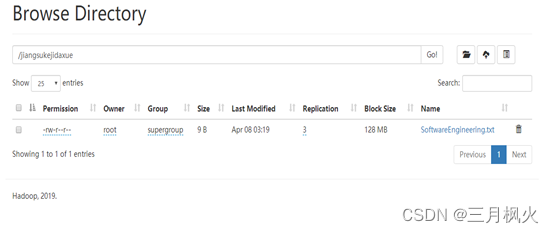
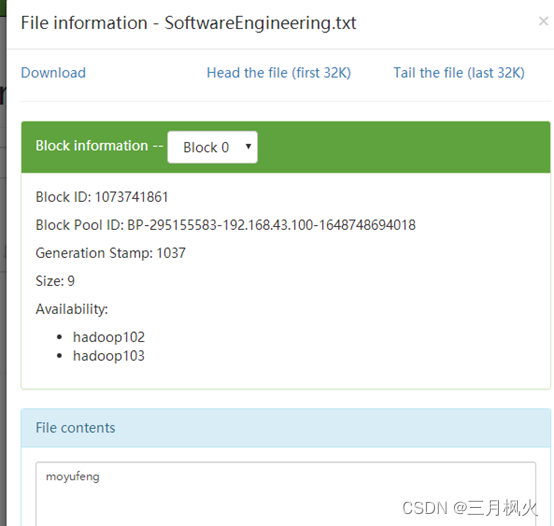
- 创建学校文件夹并上传至集群
- 创建专业.txt(文本内容为姓名)并上传至集群学校文件夹中
- 创建姓名.txt(文本内容为学号)并拼接至集群专业.txt文件内容中
- 将集群中拼接后文件下载至本地服务器的当前目录中

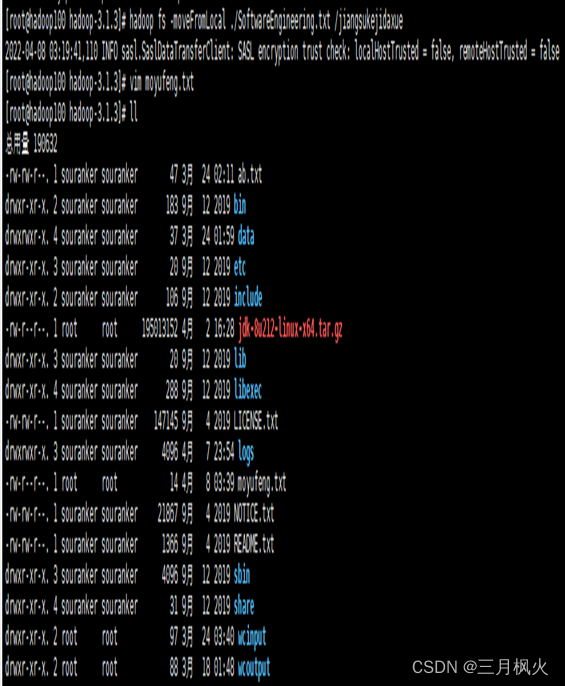
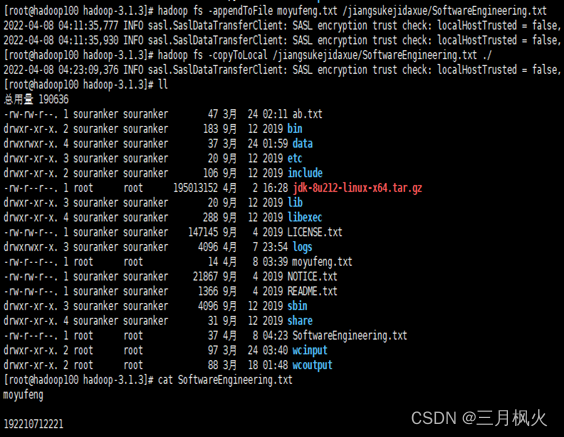
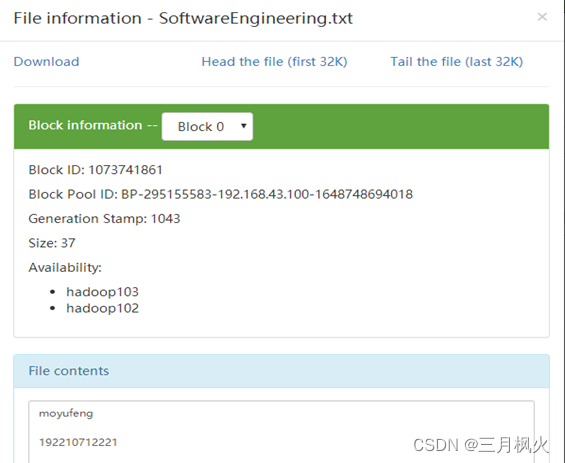
4. 大数据作业4
编写本地wordcount案例
一、源代码
- com.igeek.mapreduceDemo.wordcount.WordCountDriver
package com.igeek.mapreduceDemo.wordcount;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.获取配置信息,获取job对象实例Configuration conf=new Configuration();Job job=Job.getInstance(conf);
// 2.关联本Driver得jar路径job.setJarByClass(WordCountDriver.class);
// 3.关联map和reducejob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);
// 4.设置map得输出kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);
// 5.设置最终输出得kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);
// 6.设置输入和输出路径
// FileInputFormat.setInputPaths(job,new Path("d:\\\\Desktop\\\\Hello.txt"));FileInputFormat.setInputPaths(job,new Path("f:\\\\Documentation\\\\Hello.txt"));FileOutputFormat.setOutputPath(job,new Path("f:\\\\Documentation\\\\outHello1"));
// FileOutputFormat.setOutputPath(job,new Path("d:\\\\Desktop\\\\outHello1"));
// 7.提交jobboolean boo=job.waitForCompletion(true);System.out.println(boo);}
}- com.igeek.mapreduceDemo.wordcount.WordCountMapper
package com.igeek.mapreduceDemo.wordcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/* KEYIN Map阶段得输入key类型 LongWritable* VALUEIN Map阶段输入value类型 Text* KEYIN map阶段输出key类型 Text* VALUEIN map阶段输出得value类型 IntWritable/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {Text outk=new Text();
// 目前不进行聚合,只统计次数,所以给个1IntWritable outV=new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1.将数据转为string类型String line=value.toString();
// 2.根据空格进行切割String[] words=line.split(" ");
// 3。输出for(String word:words){outk.set(word);context.write(outk,outV);}}
}- com.igeek.mapreduceDemo.wordcount.WordCountReducer
package com.igeek.mapreduceDemo.wordcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/* KEYIN Reduce阶段得输入key类型 Text* VALUEIN reduce阶段输入value类型 IntWritable* KEYIN reduce阶段输出key类型 Text* VALUEIN reduce阶段输出得value类型 IntWritable/
public class WordCountReducer extends Reducer<Text, IntWritable,Text, IntWritable> {IntWritable outv=new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 1.累计求和int sum=0;for(IntWritable count:values){sum+=count.get();}
// 2.输出outv.set(sum);context.write(key,outv);}
}- com.igeek.mapreduceDemo.wordcount2.WordCountDriver
package com.igeek.mapreduceDemo.wordcount2;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.获取配置信息,获取job对象实例Configuration conf=new Configuration();Job job=Job.getInstance(conf);
// 2.关联本Driver得jar路径job.setJarByClass(WordCountDriver.class);
// 3.关联map和reducejob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);
// 4.设置map得输出kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);
// 5.设置最终输出得kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);
// 6.设置输入和输出路径FileInputFormat.setInputPaths(job,new Path(args[0]));FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 7.提交jobboolean boo=job.waitForCompletion(true);System.out.println(boo);}
}- com.igeek.mapreduceDemo.wordcount2.WordCountMapper
package com.igeek.mapreduceDemo.wordcount2;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/* KEYIN Map阶段得输入key类型 LongWritable* VALUEIN Map阶段输入value类型 Text* KEYIN map阶段输出key类型 Text* VALUEIN map阶段输出得value类型 IntWritable/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {Text outk=new Text();
// 目前不进行聚合,只统计次数,所以给个1IntWritable outV=new IntWritable(1);String i;int age;@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1.将数据转为string类型String line=value.toString();
// 2.根据空格进行切割String[] words=line.split(" ");
// 3。输出for(String word:words){outk.set(word);context.write(outk,outV);}}@Overridepublic String toString() {return "WordCountMapper{" +"i='" + i + '\\'' +", age=" + age +'}';}
}- com.igeek.mapreduceDemo.wordcount2.WordCountReducer
package com.igeek.mapreduceDemo.wordcount2;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/* KEYIN Reduce阶段得输入key类型 Text* VALUEIN reduce阶段输入value类型 IntWritable* KEYIN reduce阶段输出key类型 Text* VALUEIN reduce阶段输出得value类型 IntWritable/
public class WordCountReducer extends Reducer<Text, IntWritable,Text, IntWritable> {IntWritable outv=new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 1.累计求和int sum=0;for(IntWritable count:values){sum+=count.get();}
// 2.输出outv.set(sum);context.write(key,outv);}
}- pom.xml补充
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.3.1</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency>
</dependencies>
<build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins>
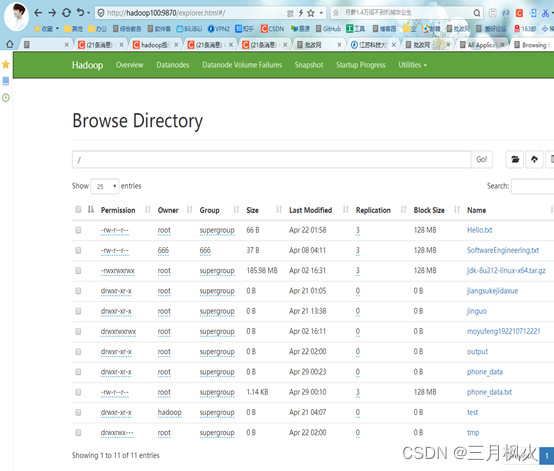
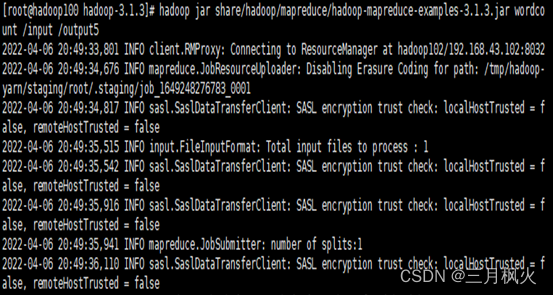
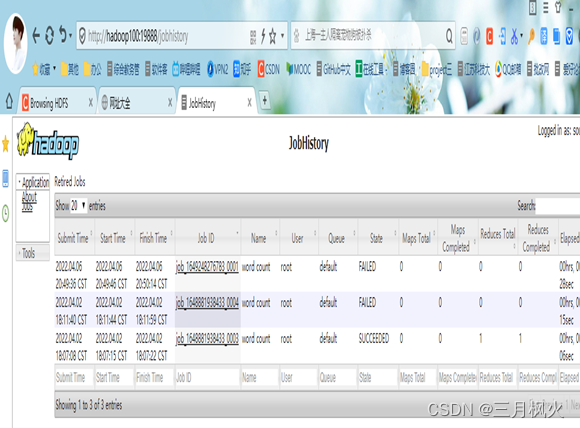
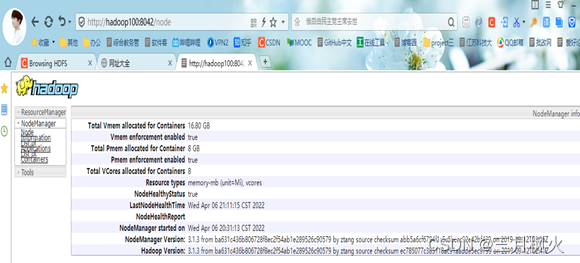
</build>二、信息截图
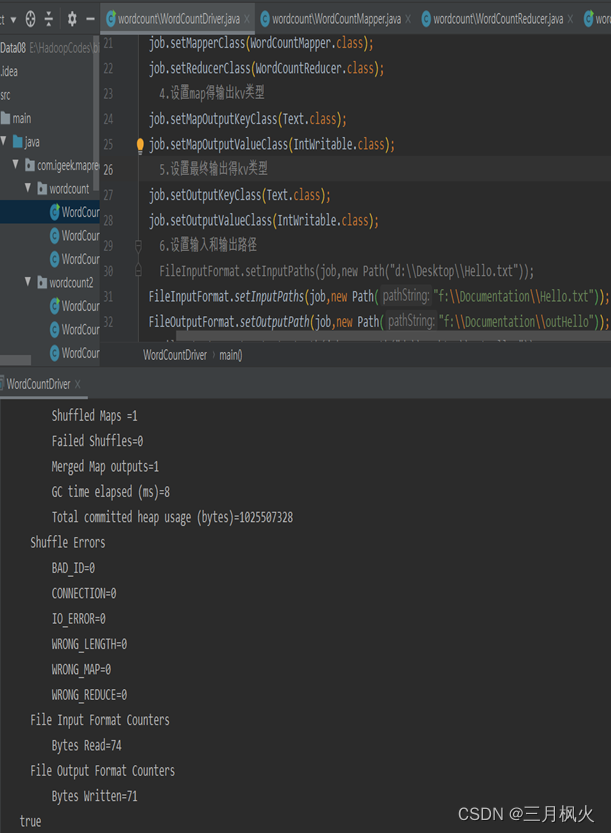
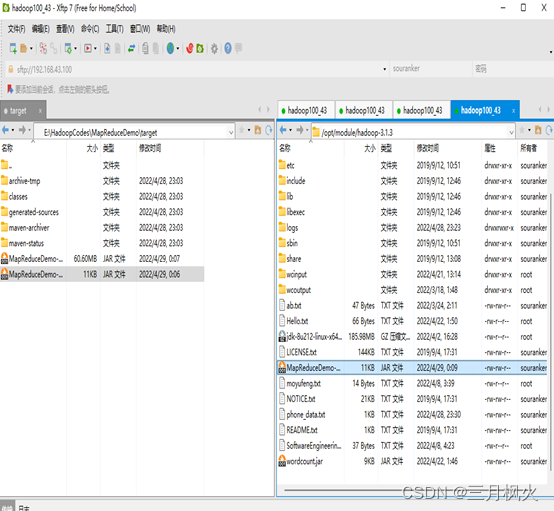
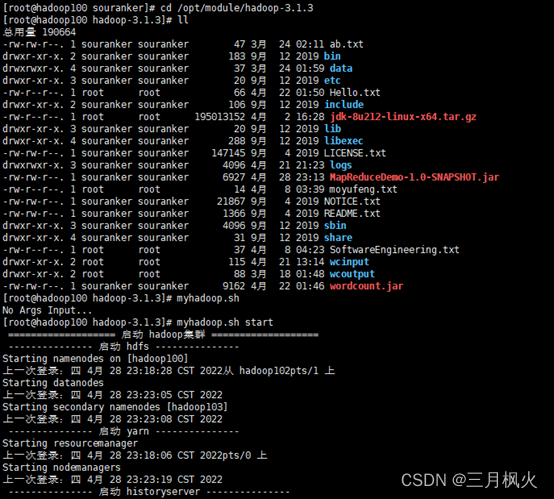
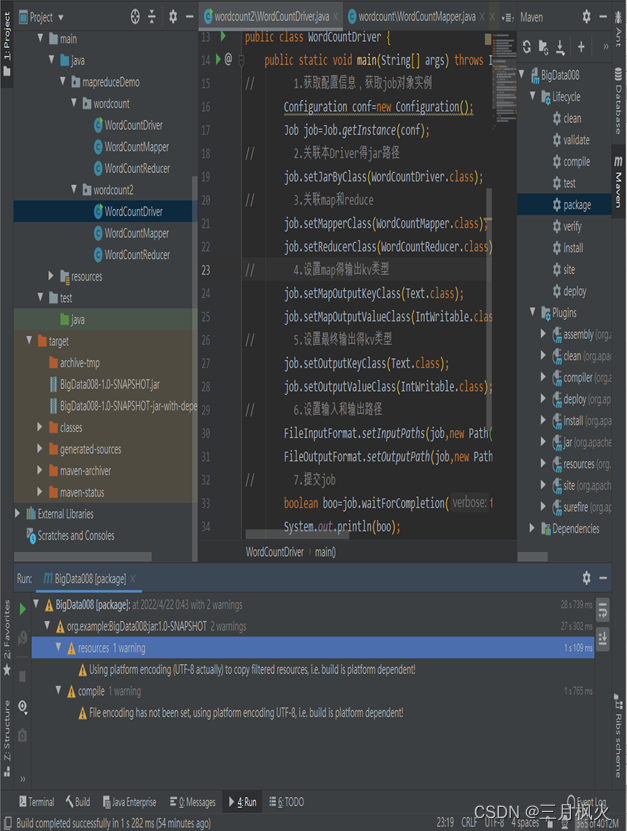
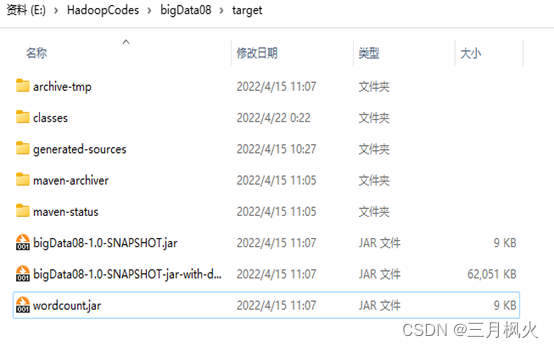
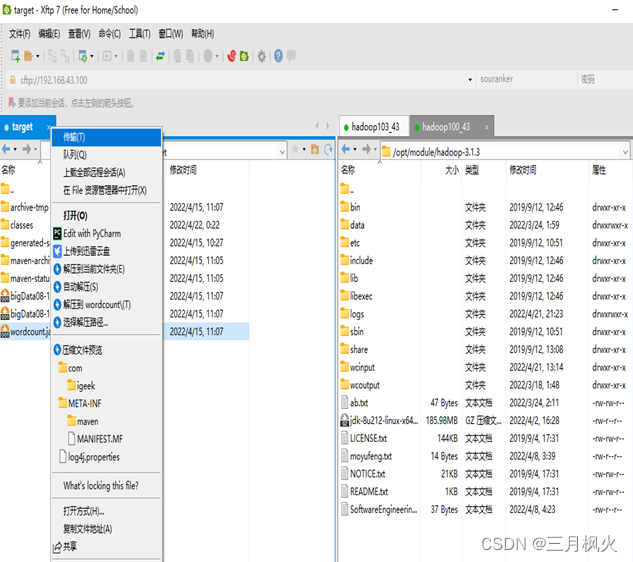
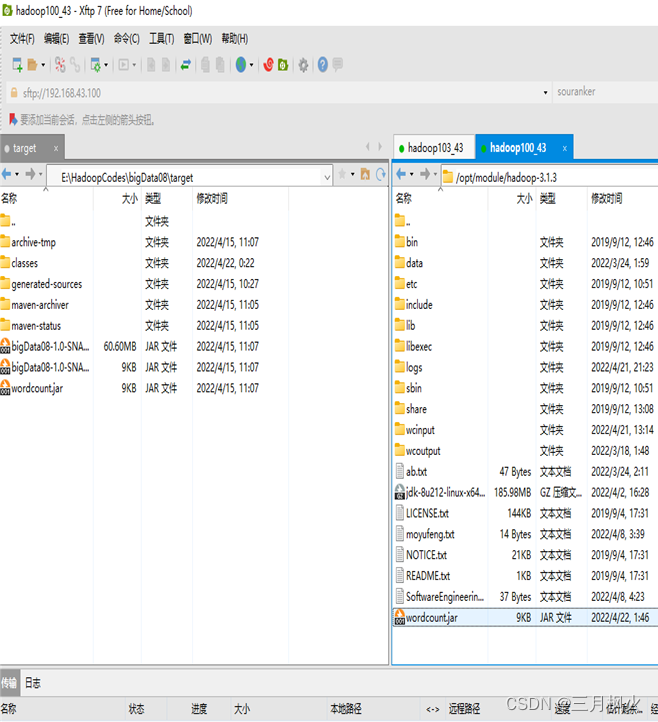
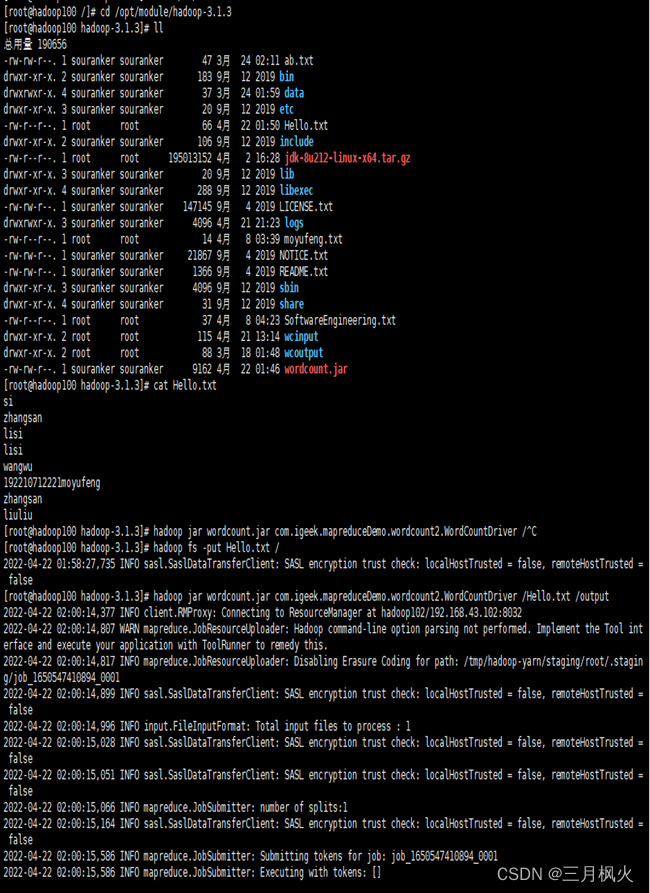
- 项目打包上传至集群
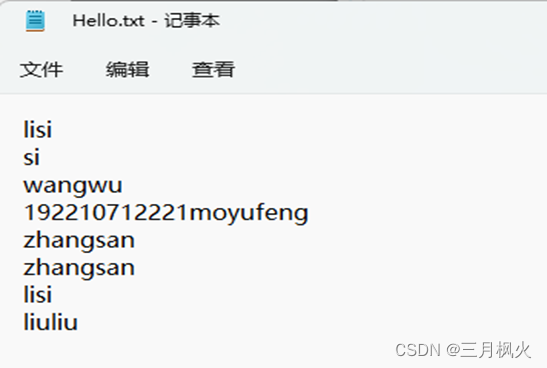
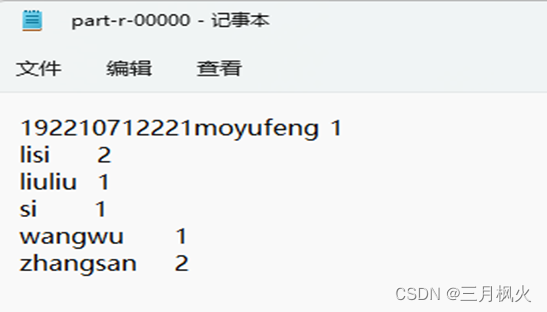
- 集群测试自写wordcount
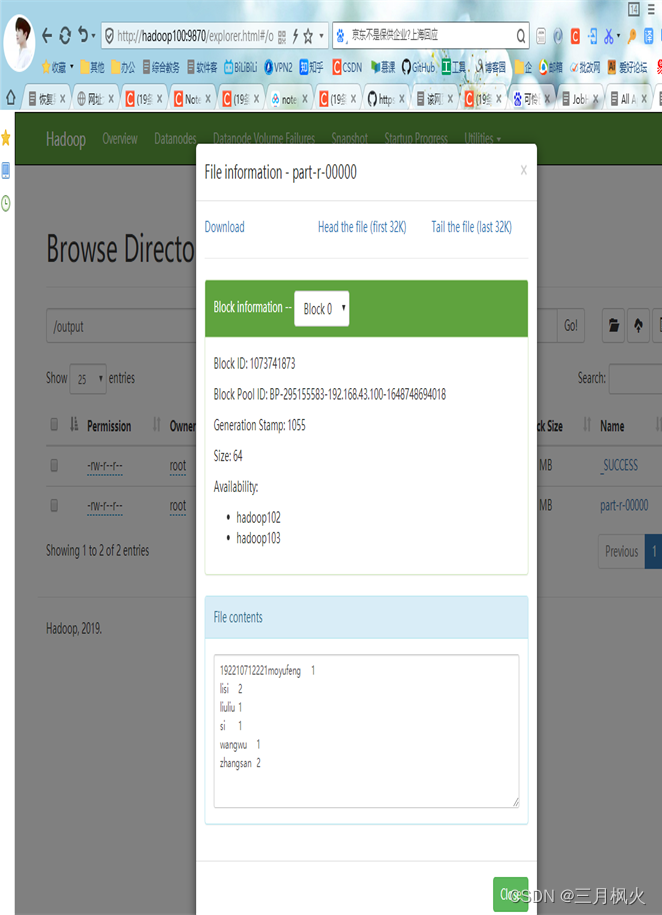
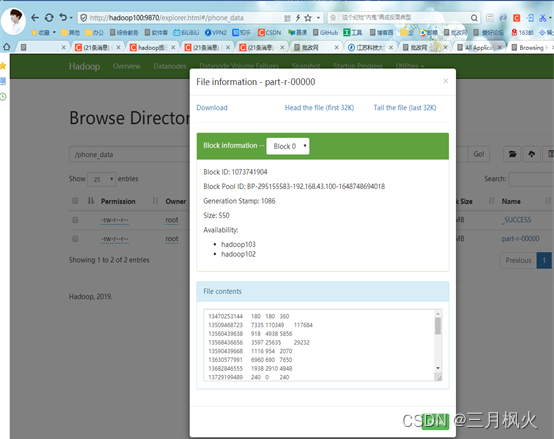
5. 大数据作业5
编写手机号码流量统计案例
- 编写本地序列化案例实现手机号码流量统计
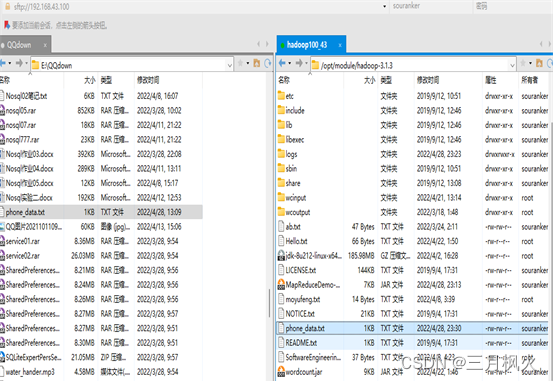
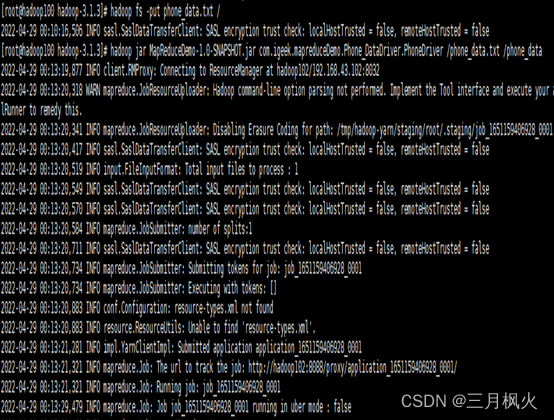
- 项目打包上传至集群
- 集群测试
一、源代码
1、 com.igeek.mapreduceDemo.flow.FlowBean
package com.igeek.mapreduceDemo.flow;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;/* 1.实现writable接口* 2.重写序列化和反序列化方法* 3.提供空参构造* 4.tostring*/public class FlowBean implements Writable {private long upFlow;//上行流量private long downFlow;//下行流量private long sumFlow;//总流量public FlowBean() {}public long getUpFlow() {return upFlow;}public long getDownFlow() {return downFlow;}public void setDownFlow(long downFlow) {this.downFlow = downFlow;}public long getSumFlow() {return sumFlow;}public void setSumFlow() {this.sumFlow = this.downFlow+this.upFlow;}public void setUpFlow(long upFlow) {this.upFlow = upFlow;}@Overridepublic void write(DataOutput out) throws IOException {out.writeLong(upFlow);out.writeLong(downFlow);out.writeLong(sumFlow);}@Overridepublic void readFields(DataInput in) throws IOException {this.upFlow=in.readLong();this.downFlow=in.readLong();this.sumFlow=in.readLong();}@Overridepublic String toString() {return upFlow + "\\t"+downFlow+"\\t" + sumFlow;}
}2、 com.igeek.mapreduceDemo.flow.FlowMapper
package com.igeek.mapreduceDemo.flow;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class FlowMapper extends Mapper<LongWritable, Text,Text,FlowBean> {private Text outk=new Text();private FlowBean outv=new FlowBean();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//获取一行数据,并转储为字符串String line=value.toString();//切割对象String[] splits=line.split("\\t");String phone=splits[1];String up=splits[splits.length-3];String down=splits [splits.length-2];//封装outk,outvoutk.set(phone);outv.setUpFlow(Long.parseLong(up));outv.setDownFlow(Long.parseLong(down));outv.getSumFlow();//写出outk,outvcontext.write(outk,outv);}
}3、 com.igeek.mapreduceDemo.flow.FlowReduce
package com.igeek.mapreduceDemo.flow;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class FlowReducer extends Reducer<Text,FlowBean,Text,FlowBean> {private FlowBean outv=new FlowBean();@Overrideprotected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {long totalUp=0;long totalDown=0;for (FlowBean flowBean: values){totalUp+=flowBean.getUpFlow();totalDown+=flowBean.getDownFlow();}//封装outvoutv.setUpFlow(totalUp);outv.setDownFlow(totalDown);outv.setSumFlow();//写出outk,outvcontext.write(key,outv);}
}4、 com.igeek.mapreduceDemo.flow.FlowDriver
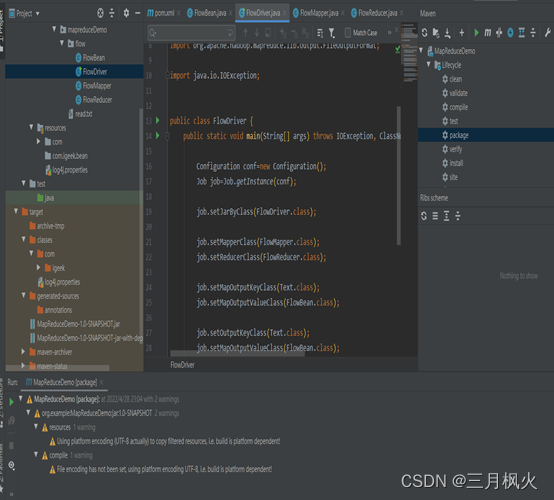
package com.igeek.mapreduceDemo.flow;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class FlowDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration conf=new Configuration();Job job=Job.getInstance(conf);job.setJarByClass(FlowDriver.class);job.setMapperClass(FlowMapper.class);job.setReducerClass(FlowReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);job.setOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);FileInputFormat.setInputPaths(job,new Path("E:\\\\QQdown\\\\phone_data.txt"));FileOutputFormat.setOutputPath(job,new Path("F:\\\\Documentation\\\\flowOutPut"));boolean b =job.waitForCompletion(true);System.out.println(b?0:1);}}5、com.igeek.mapreduceDemo.Phone_DataDriver.FlowMapper
package com.igeek.mapreduceDemo.Phone_DataDriver;import com.igeek.mapreduceDemo.flow.FlowBean;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class FlowReducer extends Reducer<Text,FlowBean,Text,FlowBean> {private FlowBean outv=new FlowBean();int phone;int up;int down;int sum;@Overridepublic String toString() {return "FlowReducer{" +"phone=" + phone +", up=" + up +", down=" + down +", sum=" + sum +'}';}@Overrideprotected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {long totalUp=0;long totalDown=0;for (FlowBean flowBean: values){totalUp+=flowBean.getUpFlow();totalDown+=flowBean.getDownFlow();}//封装outvoutv.setUpFlow(totalUp);outv.setDownFlow(totalDown);outv.setSumFlow();//写出outk,outvcontext.write(key,outv);}
}6、com.igeek.mapreduceDemo.Phone_DataDriver.FlowReducer
package com.igeek.mapreduceDemo.Phone_DataDriver;import com.igeek.mapreduceDemo.flow.FlowBean;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class FlowReducer extends Reducer<Text,FlowBean,Text,FlowBean> {private FlowBean outv=new FlowBean();int phone;int up;int down;int sum;@Overridepublic String toString() {return "FlowReducer{" +"phone=" + phone +", up=" + up +", down=" + down +", sum=" + sum +'}';}@Overrideprotected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {long totalUp=0;long totalDown=0;for (FlowBean flowBean: values){totalUp+=flowBean.getUpFlow();totalDown+=flowBean.getDownFlow();}//封装outvoutv.setUpFlow(totalUp);outv.setDownFlow(totalDown);outv.setSumFlow();//写出outk,outvcontext.write(key,outv);}
}7、com.igeek.mapreduceDemo.Phone_DataDriver.PhoneDriver
package com.igeek.mapreduceDemo.Phone_DataDriver;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class PhoneDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.获取配置信息,获取job对象实例Configuration conf=new Configuration();Job job=Job.getInstance(conf);
// 2.关联本Driver得jar路径job.setJarByClass(PhoneDriver.class);
// 3.关联map和reducejob.setMapperClass(FlowMapper.class);job.setReducerClass(FlowReducer.class);
// 4.设置map得输出kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);
// 5.设置最终输出得kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);
// 6.设置输入和输出路径FileInputFormat.setInputPaths(job,new Path(args[0]));FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 7.提交jobboolean boo=job.waitForCompletion(true);System.out.println(boo);}
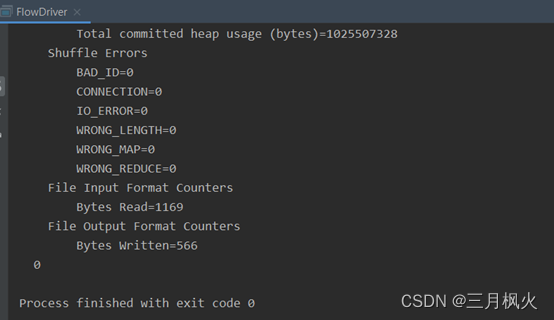
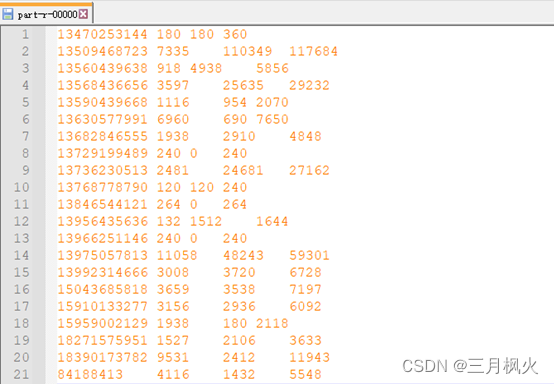
}二、信息截图