云原生应用之对象存储设计方案

背景
项目中需要到图片上传的功能,对于非结构化的数据存储在S3中。于是设计了一个图片上传的方案。这个方案要求必须在用户上传的图片后,s3已经能获取到图片后才更新图片新的地址。
方案
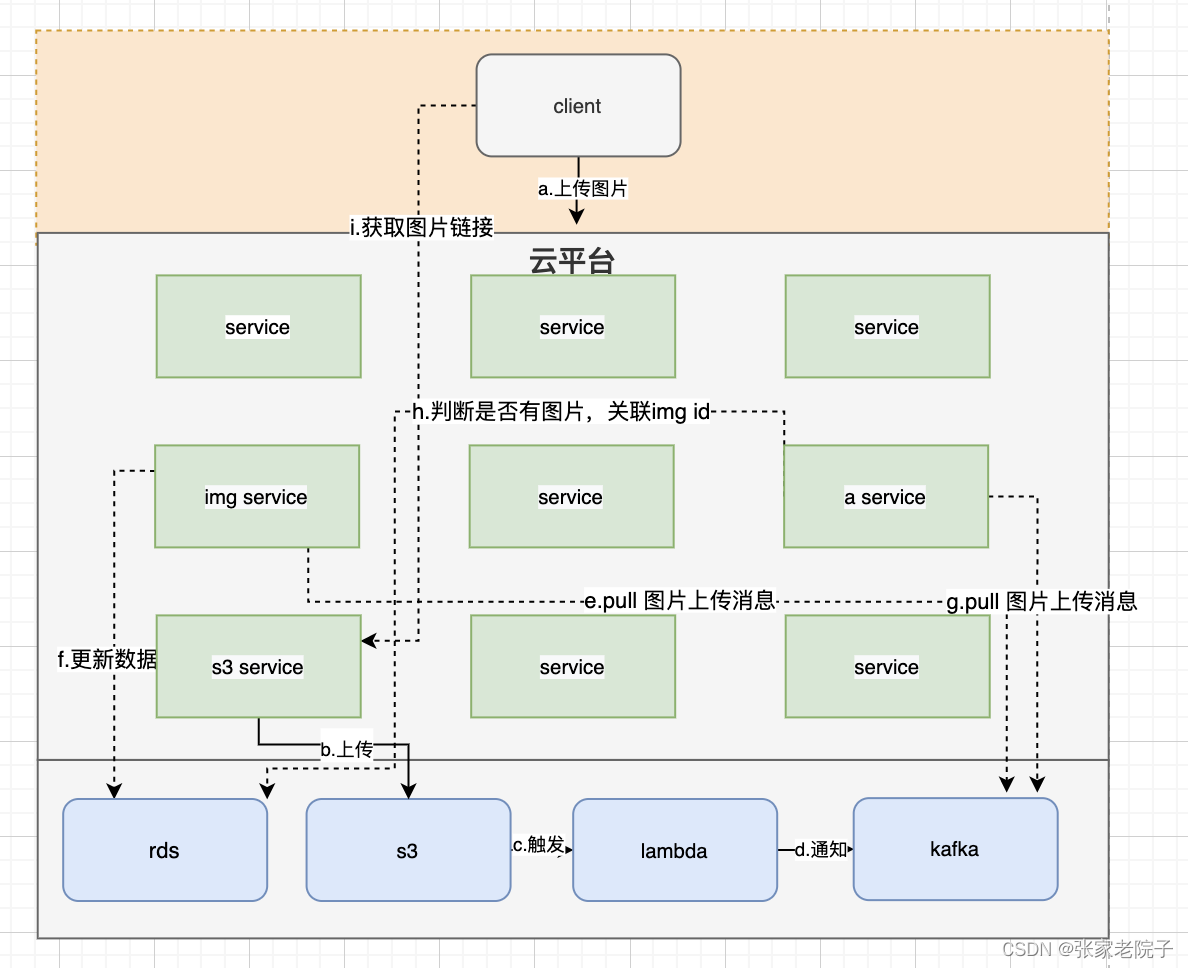
整体流程:
a.客户端通过业务服务接口上传图片,并通过img 服务保存img信息,业务服务将业务id信息,img id等放在图片名称中;
b.业务服务通过s3统一服务上传图片,,此时业务不和imgId关联;
c. 判断图片是否上传成功,通过路径获取业务模块和业务id的消息;
d.消息发送到kafka;
e.img 服务监听到回掉消息;
f.通过img id 更新img的路径和状态;
g.a 服务也监听图片上传的消息;
h.a服务根据消息,判断是否是自己业务,然后根据业务id和img id关联;
i.最后client获取到图片信息;
总结经过这样处理,能完全保持只要图片上传成功就会能关联到新的图片。
主要流程
1.上传图片的格式:
/part/3738-1680862599359.jpg
3738: 数据库对应的Image Id
part:S3的存放的文件夹,也对应part service
1680862599359: 则是时间戳
2. 解析S3的事件:
{
"Records": [
{
"eventVersion":"2.1",
"eventSource":"aws:s3",
"awsRegion":"eu-west-2",
"eventTime":"2020-04-05T13:55:30.970Z",
"eventName":"ObjectCreated:Put",
"userIdentity": {
"principalId":"A2RFWU4TTDGK95"
},
"requestParameters": {
"sourceIPAddress":"HIDDEN"
},
"responseElements": {
"x-amz-request-id":"024EF2A2E94BD5CA",
"x-amz-id-2":"P/5p5mDwfIu29SeZcNo3wjJaGAiM4yqBqp4p3gOfLVPeZhf+w5sRjnxsost3BuYub1FVf7tuMFs9KoC98+fwSI9NrT5WbjYq"
},
"s3": {
"s3SchemaVersion":"1.0",
"configurationId":"ImageUpload",
"bucket": {
"name":"HIDDEN",
"ownerIdentity": {
"principalId":"A2RFWU4TTDGK95"
},
"arn":"arn:aws:s3:::HIDDEN"
},
"object": {
"key":"activity1.png",
"size": 41762,
"eTag":"9e1645a32c2948139a90e75522deb5ab",
"sequencer":"005E89E354A986B50D"
}
}
}
]
}
然后lambda解析S3的事件实现流程如下:
1. 根据eventSource判断是不是来自s3;
2. 通过size判断图片是否是空,图片类型是否正确;
3. 通过key解析那个业务模块,image id;
4. 然后将业务模块和image id封装消息;
5. 发送kafka消息。
python
import json
import boto3
from kafka import KafkaProducerdef lambda_handler(event, context):# 获取S3事件信息eventSource = event['Records'][0]['eventSource']if eventSource not 'aws:s3':returns3_event = event['Records'][0]['s3']bucket_name = s3_event['bucket']['name']size = s3_event['object']['size']if size < 1:returnpath = s3_event['object']['key']service_name = path.split('/')[0]iamge_id = filename.split('-')[0]# 创建Kafka生产者kafka_producer = KafkaProducer(bootstrap_servers=['kafka-broker1:9092', 'kafka-broker2:9092'],value_serializer=lambda m: json.dumps(m).encode('ascii'))# 发送消息到Kafkamessage = {'service_name': service_name,'iamge_id': iamge_id}kafka_producer.send('my-topic', message)return {'statusCode': 200,'body': json.dumps('Message sent to Kafka')}3. 上传s3的代如下:
@Service
public class S3Service {@Autowiredprivate AmazonS3 s3Client;@Value("${aws.bucketName}") private String bucketName;public String uploadFile(MultipartFile file) throws IOException {String key = UUID.randomUUID().toString();ObjectMetadata metadata = new ObjectMetadata();metadata.setContentLength(file.getSize());metadata.setContentType(file.getContentType());PutObjectRequest request = new PutObjectRequest(bucketName, key, file.getInputStream(), metadata);s3Client.putObject(request);return s3Client.getUrl(bucketName, key).toString();}
}