[chapter 26][PyTorch][MNIST 测试实战】
本文主要讨论了在深度学习中训练模型时遇到的过拟合问题及其解决方案。通过手写数字识别的例子,文章详细介绍了训练过程中如何监控验证数据集的精度,以避免模型过拟合。以下是文章的主要观点和相关解答。
引言:
在深度学习中,训练一个模型时,我们通常会将数据集分为训练集和验证集。随着训练的进行,模型在训练集上的表现会逐渐提升,但如果在验证集上的表现不再提升,甚至下降,这通常意味着模型开始过拟合。
相关问题:
1. 什么是过拟合?
过拟合是指模型在训练数据上表现得很好,但在未见过的数据上表现不佳的现象。这通常是因为模型过于复杂,以至于它学习了训练数据中的噪声和细节,而不仅仅是数据的模式。
2. 如何监控验证集的精度?
一个有效的方法是定期在验证集上进行验证。这可以通过以下几种方式实现:
- 每训练几个batch(小批量)验证一次
- 每训练完一个epoch(一轮)验证一次
- 每训练几轮后验证一次
一旦验证集的精度达到一个满意水平,并且在接下来的验证中出现了下降,就可以停止训练,以避免过拟合。
相关答案:
在实际操作中,可以通过编写代码来定期测试模型在验证集上的表现。以下是一个简单的Python代码示例,展示了如何在一个batch上进行验证:
def validation(logits, label):
pred = F.softmax(logits, dim=1)
pred_label = pred.argmax(dim=1)
correct = torch.eq(pred_label, label).float().sum().item()
acc = correct / label.size(0)
print(f'Accuracy: {acc:.4f}')
通过这种方法,可以及时监控模型在验证集上的表现,并根据需要调整训练策略。
参考代码:
以下是一个完整的训练和验证流程的代码示例,展示了如何在每轮训练后进行验证:
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
# 训练步骤
# ...
# 验证步骤
if batch_idx % 100 == 0:
validation(logits, target)
# 测试步骤
test_loss = 0
correct = 0
for data, target in test_loader:
# 测试步骤
# ...
test_loss += criteon(logits, target).item()
pred = logits.data.max(dim=1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)n'.format(
test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))
通过这种方式,可以有效地监控模型的训练过程,及时发现并解决过拟合问题。
总之,深度学习中的过拟合是一个常见问题,但通过合适的监控和验证方法,可以有效避免模型在训练集上过拟合,从而提高模型在实际数据上的泛化能力。
![[chapter 26][PyTorch][MNIST 测试实战】](http://pic.ttrar.cn/nice/%5bchapter26%5d.jpg)
前言
这里面结合手写数字识别的例子,讲解一下训练时候注意点
目录
- 训练问题
- 解决方案
- 参考代码
一 训练问题
训练的时候,我们的数据集分为Train Data 和 validation Data。
随着训练的epoch次数增加,我们发现Train Data 上精度
先逐步增加,但是到一定阶段就会出现过拟合现象。
validation Data 上面不再稳定,反而出现下降的趋势,泛化能力变差.
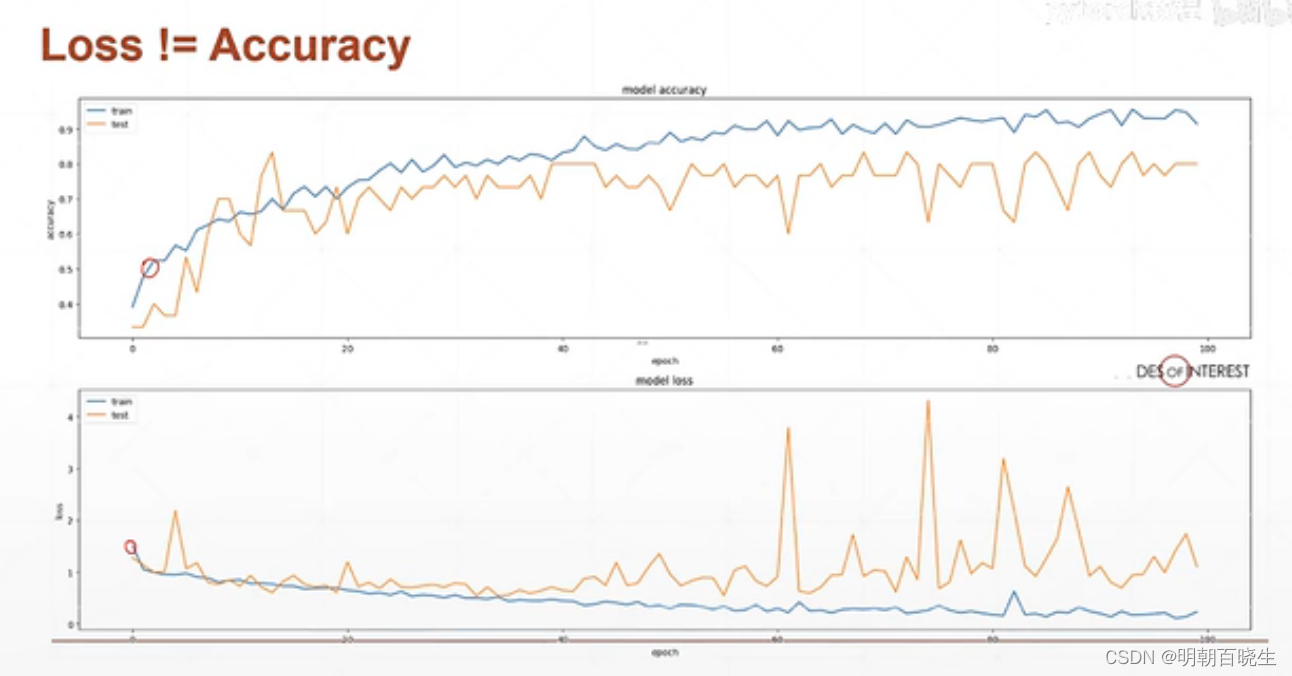
二 解决方案
test once serveral batch(几个batch,验证一次)
test once per epoch(每一轮训练完后,验证一次)
test once serveral epoch(几轮训练后,验证一次)
当发现验证集acc到达一定精度,且下降后,停止训练
三 参考代码
# -*- coding: utf-8 -*-
"""
Created on Mon Apr 10 21:51:21 2023@author: cxf
"""import torch
import torch.nn.functional as Fdef validation():logits = torch.rand(6,10)pred = F.softmax(logits, dim=1)print(pred.shape)pred_label= pred.argmax(dim=1)print(pred_label)label= torch.tensor([0,1,2,3,4,5])N = label.shape[0]correct = torch.eq(pred_label, label)print(correct)acc = correct.sum().float().item()/Nprint("\\n acc %f"%acc)validation()import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms#超参数
batch_size=200
learning_rate=0.01
epochs=10#获取训练数据
train_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=True, download=True, #train=True则得到的是训练集transform=transforms.Compose([ #transform进行数据预处理transforms.ToTensor(), #转成Tensor类型的数据transforms.Normalize((0.1307,), (0.3081,)) #进行数据标准化(减去均值除以方差)])),batch_size=batch_size, shuffle=True) #按batch_size分出一个batch维度在最前面,shuffle=True打乱顺序#获取测试数据
test_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()# 定义网络的每一层,nn.ReLU可以换成其他激活函数,比如nn.LeakyReLU()self.model = nn.Sequential( nn.Linear(784, 200),nn.ReLU(inplace=True),nn.Linear(200, 200),nn.ReLU(inplace=True),nn.Linear(200, 10),nn.ReLU(inplace=True),)def forward(self, x):x = self.model(x)return xdevice = torch.device('cuda:0') #使用第一张显卡
net = MLP().to(device)
# 定义sgd优化器,指明优化参数、学习率
# net.parameters()得到这个类所定义的网络的参数[[w1,b1,w2,b2,...]
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)for epoch in range(epochs):for batch_idx, (data, target) in enumerate(train_loader):data = data.view(-1, 28*28).to(device) # 将二维的图片数据摊平[样本数,784]target = target.to(device)logits = net(data) # 前向传播loss = criteon(logits, target) # nn.CrossEntropyLoss()自带Softmaxoptimizer.zero_grad() # 梯度信息清空loss.backward() # 反向传播获取梯度optimizer.step() # 优化器更新if batch_idx % 100 == 0: # 每100个batch输出一次信息print('Train Epoch: {} [{}/{} ({:.0f}%)]\\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))test_loss = 0correct = 0 # correct记录正确分类的样本数for data, target in test_loader:data = data.view(-1, 28 * 28).to(device)target = target.to(device)logits = net(data)test_loss += criteon(logits, target).item() # 其实就是criteon(logits, target)的值,标量pred = logits.data.max(dim=1)[1] # 也可以写成pred=logits.argmax(dim=1)correct += pred.eq(target.data).sum()test_loss /= len(test_loader.dataset)print('\\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))
参考:
课时53 MNIST测试实战_哔哩哔哩_bilibili
https://www.cnblogs.com/douzujun/p/13323078.html