《极客兔兔GeeCache第五天 分布式节点》中节点查询的过程理解

背景:最近在跟着极客兔兔的七天Go教程写项目,刷到动手写分布式缓存 - GeeCache第五天 分布式节点这一篇后感觉节点查询部分非常绕非常难以理解,并且看到评论区有其他读者也有相同的感受,因此把自己花了三四个小时才搞懂的节点选择和数据查询的整个过程记录下了,希望能帮到其他有相同困惑的读者。如果有说的不对的点,欢迎评论区一起讨论。
观前提醒:本文仅是对动手写分布式缓存 - GeeCache第五天 分布式节点的补充说明,请完整学习该文后再阅读本文,不然很多地方都会觉得看不懂
一、每个节点的内容
首先每个节点都有本地的数据库和缓存,在main.go中用一个map来做了个简单的定义:

缓存是一个Group结构体,定义如下:

二、启动节点服务器
2.1 在main函数里边,先初始化一个group
func createGroup() *geecache.Group {// Group的属性:// name、// getter(缓存未命中时获取源数据的回调)、// mainCache(并发缓存)、// peers(返回一个PickPeer,它可以调用Get方法从相应的节点中查询数据)return geecache.NewGroup("score", 2<<10, geecache.GetterFunc(func(key string) ([]byte,error){log.Println("main.go,lin25,[SlowDB] search key",key)if v,ok := db[key]; ok{return []byte(v),nil}return nil,fmt.Errorf("%s not exist",key)}))
}
gee := createGroup()
2.2 初始化一个列表,存有3个节点的地址:
addrMap := map[int]string{8001:"http://localhost:8001",8002:"http://localhost:8002",8003:"http://localhost:8003",
}// 这个应该是一系列的地址
var addrs []string
for _,v := range addrMap{addrs = append(addrs,v)
}
2.3 在各个端口上启动HTTP服务端,这又包括其中几个小步骤,在后面会讲到:
// 启动缓存服务器,创建HTTPPool,添加节点信息,注册到gee中,启动http服务(3个端口,8001,8002,8003),用户不感知
func startCacheServer(addr string,addrs []string,gee *geecache.Group){// HTTPool有两个属性,一个是基础地址,一个是用来指明节点间通信时的地址前缀peers := geecache.NewHTTPPool(addr)// 实例化一致性哈希算法、为每个真实节点分配通信地址peers.Set(addrs...)// 这个缓存由刚刚实例化了的peers(HTTPPool)来进行节点的选择gee.RegisterPeers(peers)log.Println("geecache is running at",addr)log.Fatal(http.ListenAndServe(addr[7:],peers))
}startCacheServer(addrMap[port], []string(addrs),gee)
1)根据地址和端口(addr)初始化一个自定义的客户端HTTPPool
peers := geecache.NewHTTPPool(addr)
这个客户端的结构如下:
// HTTPPool是用于承载节点间HTTP通信的核心数据结构(包括服务端和客户端)
type HTTPPool struct{self string // 记录这个节点的基础URL,比如http://example.net:8000// 作为节点间通讯地址的前缀,默认是/_geecache/,// 这样一来,以http://example.com/_geecache/开头的请求,就用于节点间的访问basePath string mu sync.Mutexpeers *consistenthash.Map //用来根据具体的key选择节点httpGetters map[string]*httpGetter //映射远程节点与对应的httpGetter,每个远程节点对应一个httpGetter
}
2)把其它节点的地址传到这个客户端中来,以便实现节点间的通信;这个Set函数还实现了一致性哈希算法的实例化
peers.Set(addrs...)
3)把刚实例化过了的客户端注册到group的peer属性下
gee.RegisterPeers(peers)
4)调用http.ListenAndServe函数,监听对某个节点的请求,然后可以用刚处理过的HTTPPool(peers)来处理
log.Fatal(http.ListenAndServe(addr[7:],peers))
三、启动API服务
这个API主要是与用户进行交互,这样用户只需要和9999端口上启动的API服务进行交互即可,不需要管数据是存到哪个端口上
// 启动一个API服务,比如在端口9999启动服务,来与用户交互,进行用户感知
func startAPIServer(apiAddr string,gee *geecache.Group){http.Handle("/api",http.HandlerFunc(func(w http.ResponseWriter,r *http.Request){key:= r.URL.Query().Get("key")log.Println("main.go,line50")// 这里调用的是Group的Get函数,如果在本机缓存上没有找到,那就通过http请求向其它节点请求数据,// 具体的请求是用http.Get进行请求的,如果这个节点开启了服务,并且实现了ServeHTTP函数,那么会调用这个节点的这个函数处理这个http请求// 最后从这个节点的缓存上进行数据的查询view, err := gee.Get(key)log.Println("main.go,line52")if err != nil{http.Error(w,err.Error(),http.StatusInternalServerError)return}w.Header().Set("Content-Type","application/octet-stream")w.Write(view.ByteSlice())}))log.Println("fontend server is running at",apiAddr)log.Fatal(http.ListenAndServe(apiAddr[7:],nil))
}
// 在相应的节点上启动API,让用户得以通过这个API进行数据查询
if api {go startAPIServer(apiAddr,gee)
}
极客兔兔用的是下面这种方式来启动3个端口的服务和API的:
go build -o server
./server -port=8001 &
./server -port=8002 &
./server -port=8003 -api=1 &
go build就是把main.py编译成可执行文件server;
./server -port=8001(8002) &就是在8001端口或者8002端口上启动服务;
./server -port=8003 -api=1 &是在8003端口上启动服务,并且在8003端口上启动API服务的。这样一来,用户通过API进行访问时,首先会访问的是8003端口(这块我不太确定,我是根据我的实际操作结果来推断的,不是很严谨)
四、数据查询
我只启动了8001节点和8002节点,并且在8002上启动了API服务,启动后的效果如下:


4.1 数据查询命中
一共有13个步骤,其中节点选择是在第4~8步
1)有3个数据可以查询:Tom、Jack、Sam,经过哈希后Tom数据应该存在8001节点上,因此我们另外开一个终端,输入以下请求:
curl "http://localhost:9999/api?key=Tom"
2)startAPIServer:这个请求首先会被startAPIServer函数中定义的http.HandlerFunc接收,接着通过8002节点的gee接收,然后调用Group类的Get函数对键值进行查询
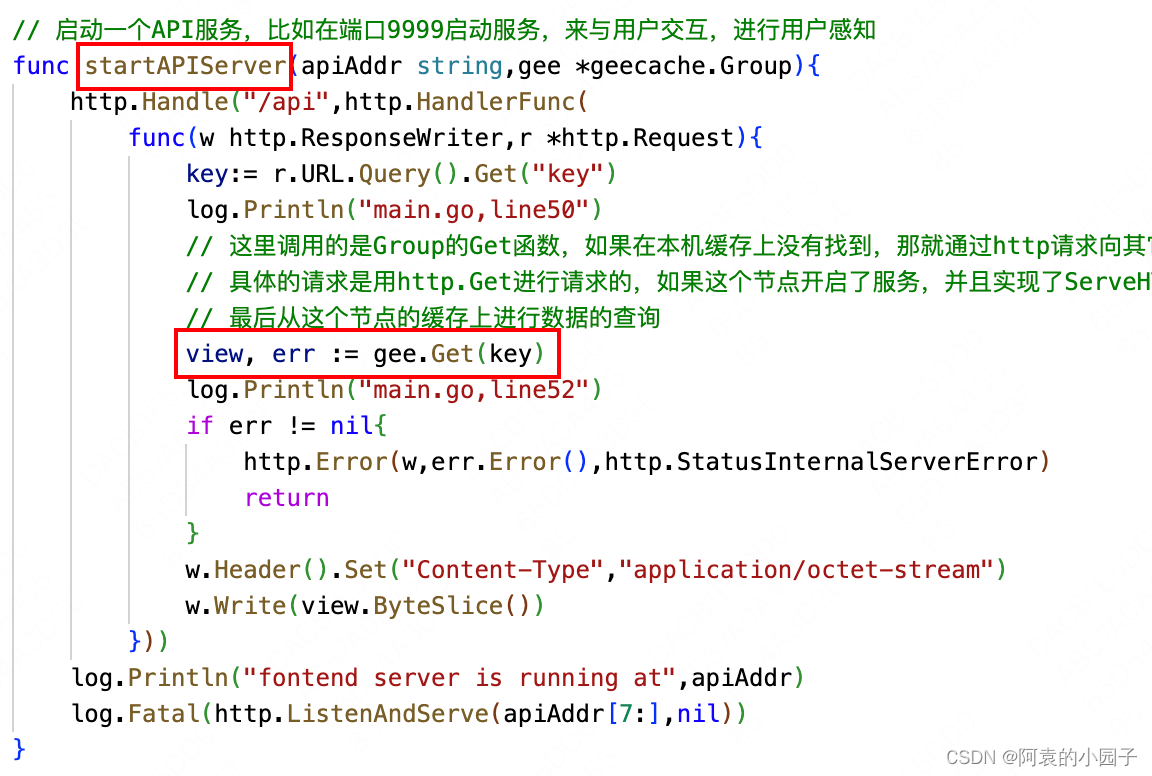
3)Group.Get:在Group.Get中,它是先查询当前节点的缓存,如果没有,那么就进入Group.load函数中进行下一步

4)Group.load:首先会调用Group.peers.PickPeer进行节点的选择

5)Group.peers.PickPeer:调用HTTPPool.peers.Get方法进行判断。

这时候HTTPPool.peers的类型是consistenthash.Map,也是自定义的类型,结构如下:

6)consistenthash.Map.Get:
这个方法直接返回的就是从第3)步开始一步步传下来的这个Key值,所应该在的节点的地址,比如Tom这个Key应该返回8001节点的地址:localhost:8001
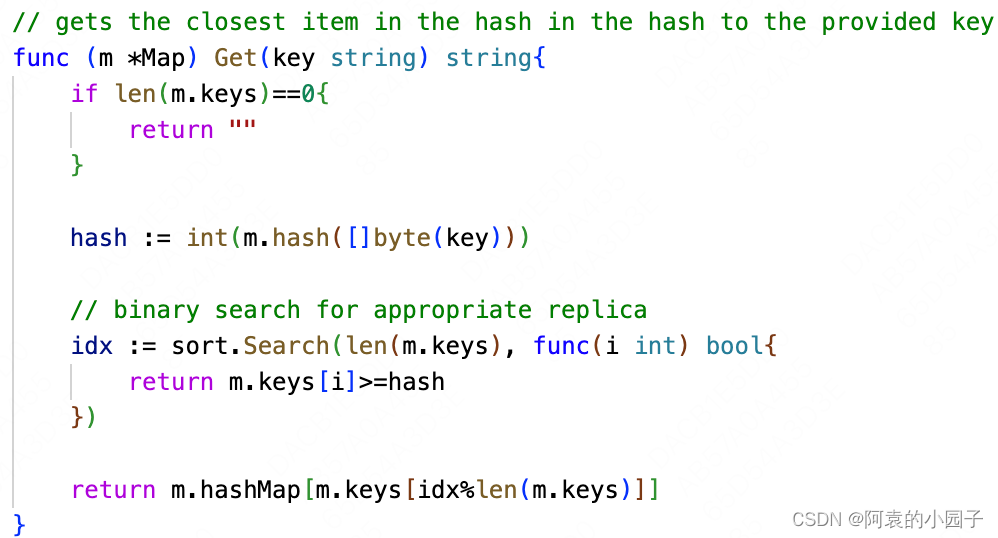
7)Group.peers.PickPeer:回到Group.peers.PickPeer,如果不是本机节点(在我们这个例子中,本机节点为8002),那么就返回一个httpGetter节点
这个httpGetter节点的定义如下:

它实现了Get接口:
8)Group.load:回到Group.load,进入第二个if分支,调用Group.getFromPeer
9)Group.getFromPeer(peer,key):这个函数调用了peer.Get函数。
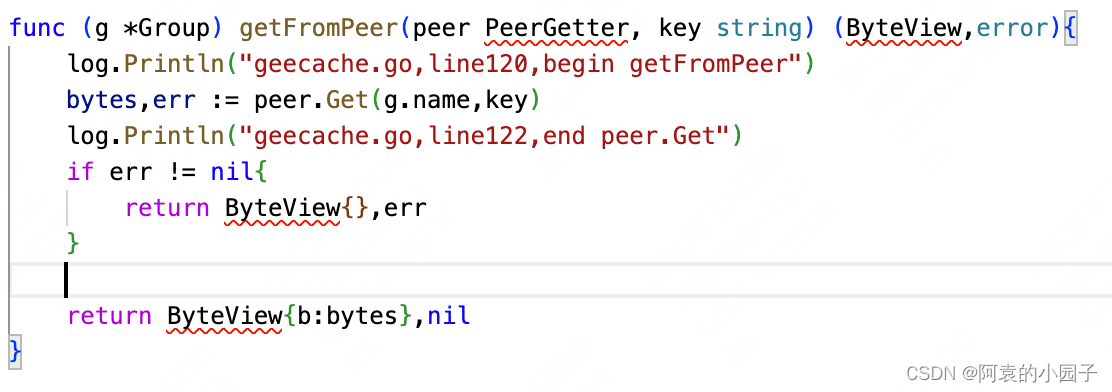
这里可以看到,在函数的形参里,peer的类型是PeerGetter,但是为什么我在第7点说它是httpGetter呢?因为PeerGetter是一个接口,有一个函数为Get

而httpGetter类是实现了这个Get函数的(具体内容在第10点),所以如果是要调用Get函数,那么是可以传入一个类型为httpGetter的变量的
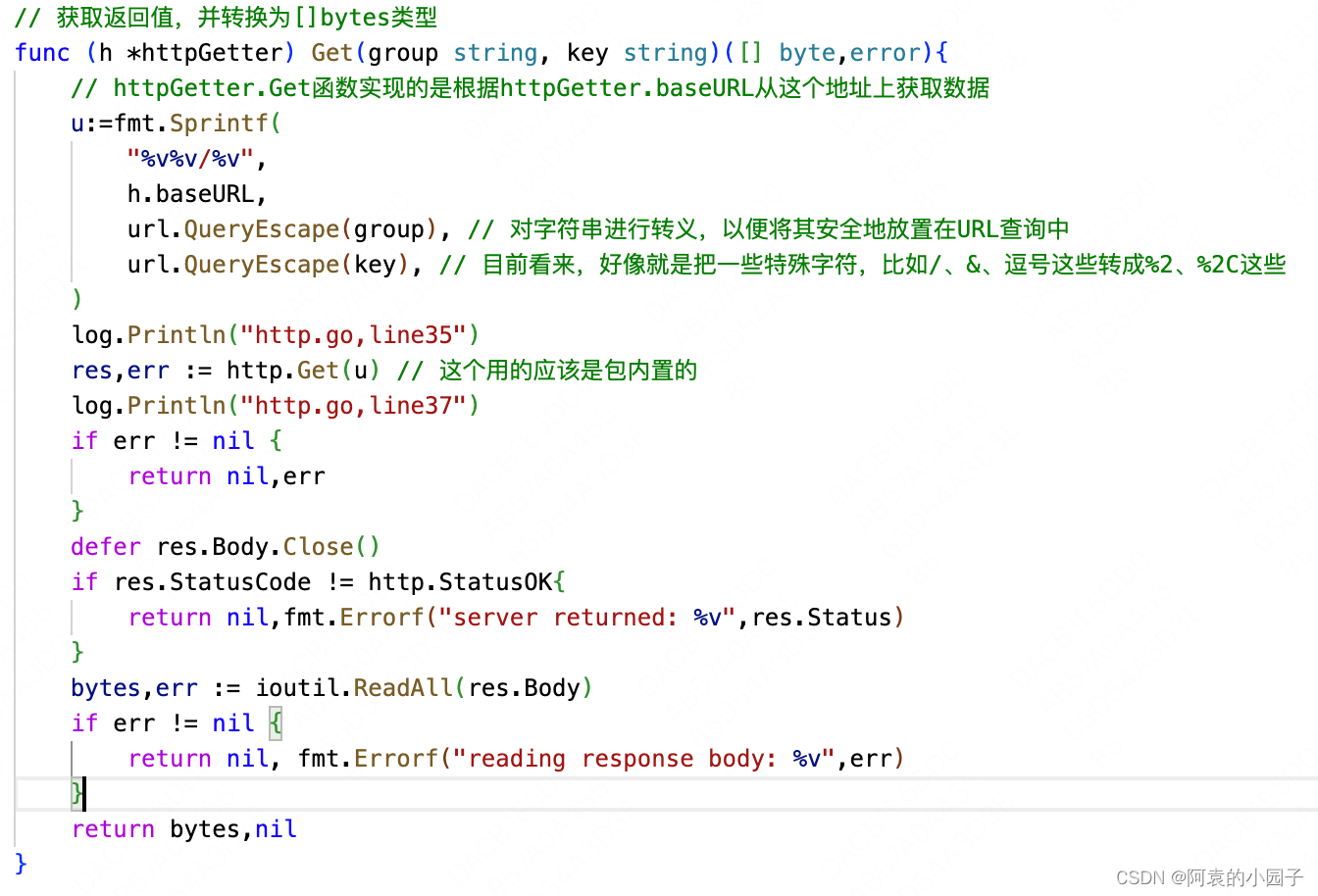
10)httpGetter.Get:这个函数涉及到一些http传参和处理的事项,主要看第36行的http.Get函数,这里把key值装进变量u里进行了传参。

这个http.Get是Go内定的包,这里有个自动跳转:ServeHTTP是net/http的接口,如果实现了这个接口,请求就会被路由到h.baseURL的实现函数中,也就是HTTPPool.ServeHTTP中
11)HTTPPool.ServeHTTP:这里主要看第127行,从对应的缓存group里根据键值获取value
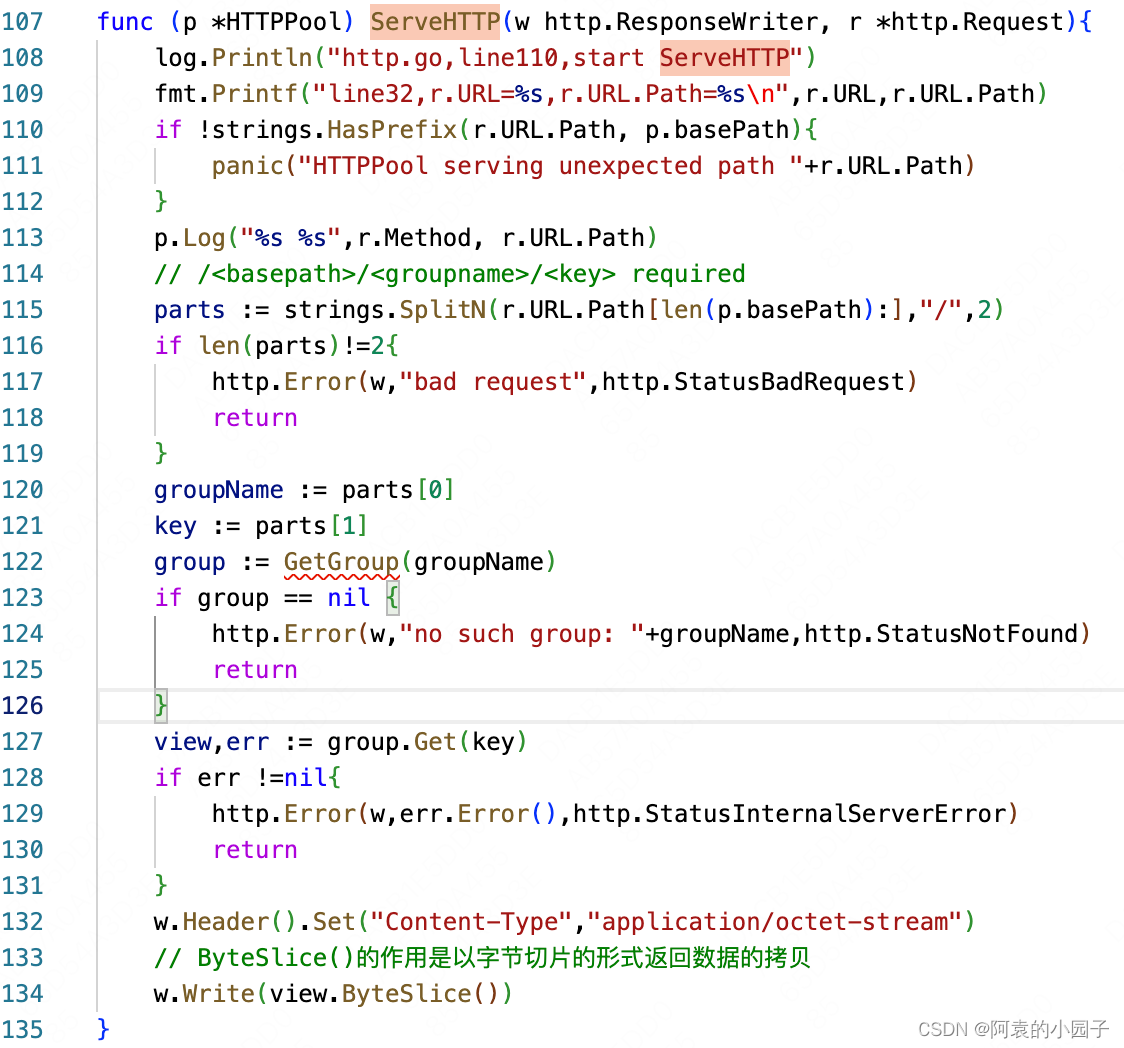
在group.Get(Key)函数里,就会重复上面的第3第4步,但是会直接进入Group.getLocally(key)中,因为这时候是在当前节点上进行的查找,所以第4步到第5步的条件不成立
12)Group.getLocally:这时候的Group.getter.Get就相当于从本地数据库里取数据用于返回;接着到第75行,使用populateCache函数把这个键值加入到本机的缓存里。

13)完成上述第3到第12步后,就完成了一次完整的数据存取,接着回到第2步,执行log.Println("main.go,line52")。
4.2 数据查询所需要的那个节点挂了怎么办
如果挂了,或者没有启动,那么在第4步就直接进入了g.getLocally,接着把数据从当前节点的数据库中取出来存到当前节点的缓存上