0204强连通性-有向图-数据结构和算法(Java)

1 概述
定义。如果2个顶点是相互可达的,则称它们为强连通的。如果一幅有向图中的任意两个顶点都是强连通的,则称这幅有向图也是强连通的。
环在强连通的理解上起着重要的作用。
两个顶点时强连通的当且仅当它们都在一个普通的有向环中。
2 强连通分量
2.1 定义
有向图中的强连通性也是一种顶点之间的定价关系,因为它有着以下性质。
- 自反性:任意顶点v都是和自己强连通的。
- 对称性:如果v和w是强连通的,那么w和v也是强连通的。
- 传递性: 如果v和w是强连通的且w和x是强连通的,那么v和x也是强连通的。
做为一种等价关系,强连通性将所有顶点分为了一些等价类,每个等价类都是由相互均为强连通的顶点的最大子集组成的。我们将这些子集称为强连通分量。
在有向图中,强连通分量是指有向图中的一个最大的强连通子图。也就是说,它是一个包含尽可能多的节点的强连通子图,并且无法再添加任何其他节点使其变成更大的强连通子图。
2.2 Kosaraju算法
2.2.1 算法实现
Kosaraju算法就是用来在有向图中计算强连通分量的,算法如下:
- 在给定的一幅有向图G中,计算她的反向图的逆后序排序;
- 在G中进行标准的深度优先搜索,但是要按照刚才计算得到的顺序而非标准的顺序来访问所有未被标记的顶点。
- 一次dfs()方法调用中被访问到的顶点都在同一个强连通分量重,将它们按照和之前无向图处理连通分量一样的方式识别出来。
算法非递归实现代码2.2.1-1如下所示:
package com.gaogzhen.datastructure.graph.directed;import com.gaogzhen.datastructure.stack.Stack;
import edu.princeton.cs.algs4.Digraph;
import edu.princeton.cs.algs4.TransitiveClosure;import java.util.Iterator;/* 计算强连通分量* @author gaogzhen*/
public class KosarajuSharirSCC {/* 访问标记*/private boolean[] marked;/* 连通分量标记*/private int[] id;/* 连通分量数量*/private int count;/* 计算强连通分量* @param digraph 有向图*/public KosarajuSharirSCC(Digraph digraph) {// compute reverse postorder of reverse graphDepthFirstOrder dfs = new DepthFirstOrder(digraph.reverse());// run DFS on digraph, using reverse postorder to guide calculationmarked = new boolean[digraph.V()];id = new int[digraph.V()];for (int v : dfs.reversePost()) {if (!marked[v]) {dfs(digraph, v);count++;}}// check that id[] gives strong componentsassert check(digraph);}/* 深度优先搜索计算强连通分量* @param digraph 优先图* @param s 起点*/private void dfs(Digraph digraph, int s) {// 栈记录搜索路径Stack<Iterator<Integer>> path = new Stack<>();if (!marked[s]) {// 起点默认没标记,可以不加是否标记判断marked[s] = true;id[s] = count;Iterable<Integer> iterable = digraph.adj(s);Iterator<Integer> it;if (iterable != null && (it = iterable.iterator()) != null){// 顶点对应的邻接表迭代器存入栈path.push(it);}}while (!path.isEmpty()) {Iterator<Integer> it = path.pop();int x;while (it.hasNext()) {// 邻接表迭代器有元素,获取元素x = it.next();if (!marked[x]) {// 顶点未被标记,标记marked[x] = true;id[x] = count;if (it.hasNext()) {// 邻接表迭代器有元素重新入栈path.push(it);}// 深度优先原则,当前迭代器入栈,新标记顶点的邻接表迭代器入栈,下次循环优先访问Iterable<Integer> iterable = digraph.adj(x);if (iterable != null && (it = iterable.iterator()) != null){path.push(it);}break;}}}}/* 连通分量数量* @return 连通分量数量*/public int count() {return count;}/* 顶点v和w是强连通的吗* @param v 顶点v* @param w 顶点w* @return {@code true} if vertices {@code v} and {@code w} are in the same* strong component, and {@code false} otherwise* @throws IllegalArgumentException unless {@code 0 <= v < V}* @throws IllegalArgumentException unless {@code 0 <= w < V}*/public boolean stronglyConnected(int v, int w) {validateVertex(v);validateVertex(w);return id[v] == id[w];}/* 顶点v所在的强连通分量标记* @param v 指定顶点v* @return the component id of the strong component containing vertex {@code v}* @throws IllegalArgumentException unless {@code 0 <= s < V}*/public int id(int v) {validateVertex(v);return id[v];}/ @param digraph 有向图* @return*/private boolean check(Digraph digraph) {TransitiveClosure tc = new TransitiveClosure(digraph);for (int v = 0; v < digraph.V(); v++) {for (int w = 0; w < digraph.V(); w++) {if (stronglyConnected(v, w) != (tc.reachable(v, w) && tc.reachable(w, v))) {return false;}}}return true;}/* 校验顶点v* @param v 顶点v*/private void validateVertex(int v) {int V = marked.length;if (v < 0 || v >= V) {throw new IllegalArgumentException("vertex " + v + " is not between 0 and " + (V-1));}}
}
算法实现相对简单,但是理解起来有些费劲,兄弟被这个问题困扰了好几天。通过参考底下链接[2][3]加上之前内容学习,才解开疑惑。
2.2.2算法测试
以下图2.2.2-1所示有向图为例:

测试代码如下2.2.2-1所示:
public static void testKosaraju() {String path = System.getProperty("user.dir") + File.separator + "asserts/tinyDG1.txt";In in = new In(path);Digraph digraph = new Digraph(in);KosarajuSharirSCC scc = new KosarajuSharirSCC(digraph);// number of connected componentsint m = scc.count();StdOut.println(m + " strong components");// compute list of vertices in each strong componentQueue<Integer>[] components = (Queue<Integer>[]) new Queue[m];for (int i = 0; i < m; i++) {components[i] = new Queue<Integer>();}for (int v = 0; v < digraph.V(); v++) {components[scc.id(v)].enqueue(v);}// print resultsfor (int i = 0; i < m; i++) {for (int v : components[i]) {StdOut.print(v + " ");}StdOut.println();}
}
- 有兴趣可以把全部连通分量分组封装为一个方法
测试结果:
5 strong components
1
0 2 3 4 5
9 10 11 12
6
7 8
2.2.3 算法理解
最开始关于算法的疑惑:
- 深度优先搜索算法下,一个连通分量只要有顶点出度,必然会去访问非当前连通分量中的顶点,怎么确定连通分量的分界呢?
- 反向图的逆后序排列和原有向图有啥关系,这样的话不用费劲先构建反向图获取反向图的逆后序排列,在去深度优先搜索原图
下面是一些我们来一步一步分析:
- 前置知识点
- 有向无环图有n个顶点对应有n个连通分量,即一个顶点对应一个连通分量;
- 有向环中顶点在同一连通分量内,那么有向图和其反向图具有相同的连通分量。
- 我们知道强连通分量中顶点是等价的,可以把同一强连通分量看作一个顶点,该顶点称为该强连通分量的缩点。
- 有向图的逆后序排列就是有向边优先从排在前面的元素指向排在后面的元素
如下图2.2.3-1所示,为我们在#2.2.2中示例有向图对应的连通分量:

第一步,我们先来分析连通分量与连通分量之间的关系。
下面我们把同一连通分量做成一个缩点,如下图2.2.3-2所示:
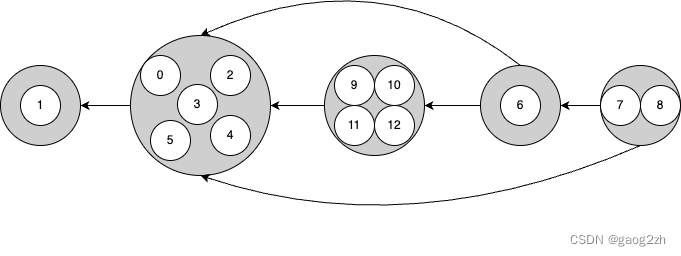
我们期望的访问访问顺序1所在的连通分量->0所在的连通分量->9所在的连通分量->6所在的连通分量->7所在的连通分量。这样在访问后面的连通分量时,即使有指出的连接,它所指向的连通分量顶点已经被标记访问过,即当前访问的顶点一定在同一连通分量内。
如何确定访问顺序呢?很容易想到逆后序排列可以实现,但是我们需要后指向优先,所以我们需要调转原有的方向,即我们先得到有向图G的反向图GRG^RGR 的逆后序排列,在按照该顺序深度优先搜索有向图G。
一次dfs()调用,确定一个连通分量。
第二步,我们来分析连通分量内部顶点之间的关系。
上面解释了不同连通分量之间的问题,下面还有两个问题,关于同一连通分量内的顶点:
- (1)每个和s强连通的顶点v都会在一次dfs(G,s)中被访问到?
- (2)一次dfs调用的dfs(G,s)所到达的任意顶点v都必然是和s强连通的?
证明:
(1) 反证法假设“有一个和s强连通的顶点v不在dfs(G,s)中被访问到“。因为存在从s到v的路径,所以v肯定在之前就已经被标记过。但是因为也存在从v到s到路径,在dfs(G,v)的调用中s肯定会被标记,因此构造函数应该是不会调用dfs(G,s)的。矛盾。
(2)设v为dfs(G,s)到达的某个顶点。那么G中必然存在一条从s到v的路径,因此只需要证明G中还存在一条从v到s到路径即可。这也等价于证明GRG^RGR 中存在一条从s到v的路径。
证明的核心在于,按照逆后序进行的深度优先搜索意味着,在GRG^RGR中进行的深度优先搜索中,dfs(G,v)必然在dfs(G,s)之前就已经结束了,这样dfs(G,v)的调用就只会出现两种情况:
- 调用在dfs(G,s)的调用之前(并且也在dfs(G,s)的调用之前结束)
- 调用在dfs(G,s)的调用之后(并且也在dfs(G,s)的结束之前结束)
第一种情况是不可能存在的,因为在GRG^RGR中存在一从v到s到路径;而第二中情况则说明GRG^RGR中存在一条从s到v的路径。
上述证明摘自书中,第一条证明很容易理解,但是第二条证明看得有我使劲挠头也没能理解。主要是没能给区分出我们要找的s到v和v到s 是在哪里找。
首先证明一次dfs(G,s)所到达的任意顶点都是和s强连通的,很明显存在从s到v的路径,即先遍历s后遍历v,这个顺序是从反向图GRG^RGR 的逆后序排列获得的;G中存在从s到v的路径,那么反向图GRG^RGR中必然存在从v到s到路径,按照逆后序排列,顺序应该是先v在s;那么有向图G的dfs调用中顶点v必然先于顶点s被被标记,也就不可能存在从s到v的路径,所以GRG^RGR中必然存在从s到v的路径,即G存在从v到s到路径。
那么G中s顶点可达但是不在同一连通分量中的顶点呢?这些属于其他连通分量的顶点,根据之前讲述的连通分量与连通分量之间的讨论,必然先于顶点s被标记。
不知道该算法当初是怎么被发现的呢?真好奇,这个问题困扰了我好几天了。
3 强连通性
强连通性:给定一幅有向图,回答“给定的两个顶点是强连通的吗?这幅有向图中含有多个强连通分量?”等类似问题
命题I。Kosaraju算法等预处理所需时间和空间与V+E成正比且支持常数时间等有向图强连通性的查询。
证明。该算法会处理有向图的反向图并进行两次深度优先搜索。这3步骤所需的时间都与V+E成正比。
结语
如果小伙伴什么问题或者指教,欢迎交流。
❓QQ:806797785
⭐️源代码仓库地址:https://gitee.com/gaogzhen/algorithm
参考链接:
[1][美]Robert Sedgewich,[美]Kevin Wayne著;谢路云译.算法:第4版[M].北京:人民邮电出版社,2012.10.p378-383.
[2]图解:有向环、拓扑排序与 Kosaraju 算法[CP/OL].
[3]如何理解Kosaraju算法?[CP/OL].