聚集索引和非聚集索引

聚集索引和非聚集索引
- 1. InnoDB和B+树
- 2. 聚集索引和非聚集索引
- 3. 回表查询
- 4. 索引覆盖
- 5. 最左匹配原则
- 6. 总结
- 参考
聚集索引和非聚集索引是针对MySQL的索引而言的。是索引的两种不同的存储形态。要了解聚集索引和非聚集索引,首先要了解MySQL的InnoDB存储引擎的存储结构。
1. InnoDB和B+树
MySQL默认的存储引擎是InnoDB,而InnoDB的索引存储形式就是B+ Tree。
B+树是一种自平衡的有序树数据结构。B-Tree和B+Tree都从一个Root节点开始,可能有Internal Nodes和Leaf Nodes。但是与B-Tree不同的是,B+Tree将所有的key都存储在叶子节点中,相邻的Leaf节点通过指针链接起来,简化了范围扫描。
如果没有索引,每当我们寻找给定的列值时,我们都需要扫描所有表记录并将每个列值与提供的值进行比较。表越大,为了找到所有匹配的记录就必须扫描更多的页面。
有了索引,就可以根据索引树,快速定位到想要的数据。
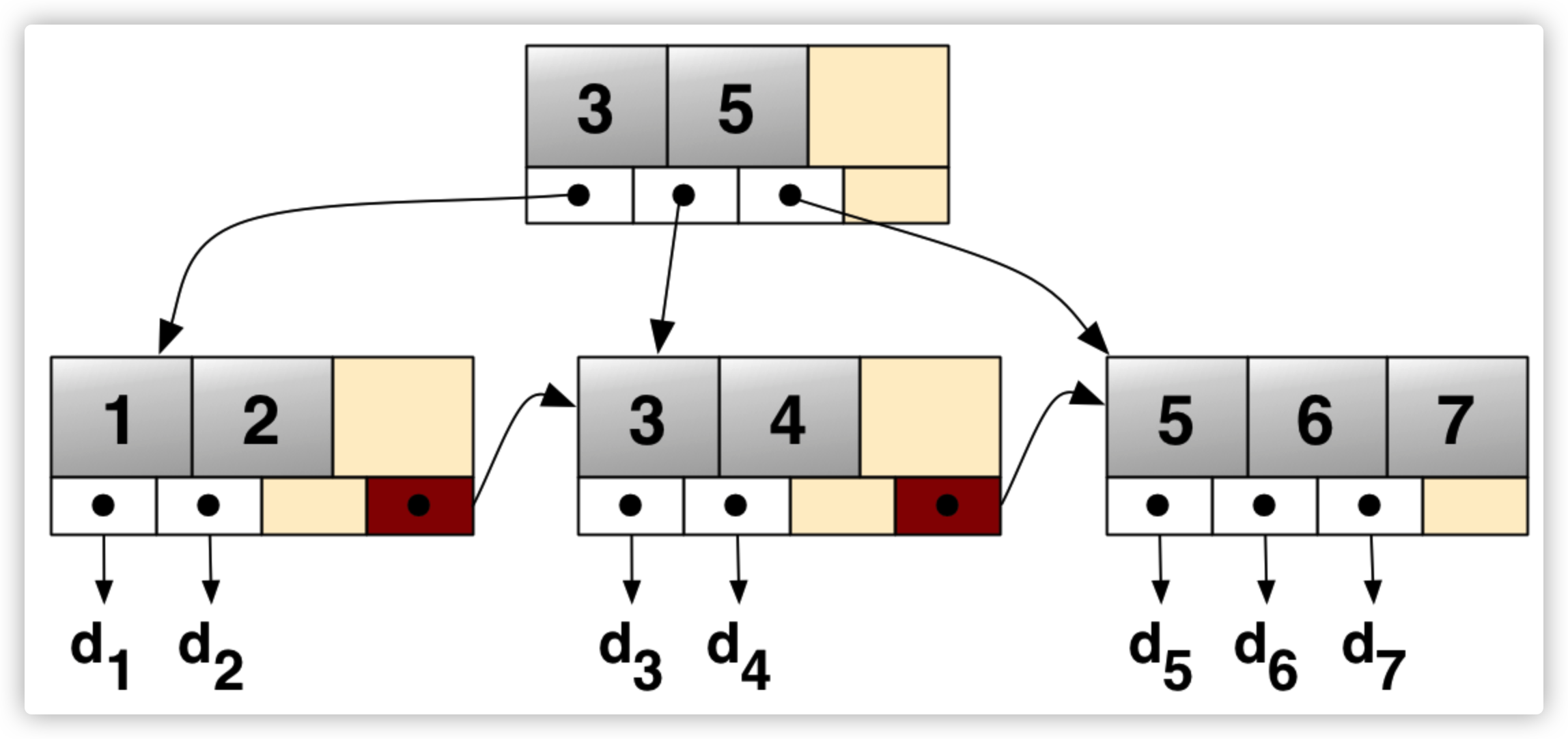
2. 聚集索引和非聚集索引
MySQL底层使用B+树来存储索引,数据均存在叶子节点上。对于InnoDB而言,主键索引和行记录时存储在一起的,因此叫做聚集索引(clustered index)。除了聚集索引,其他所有都叫做非聚集索引(secondary index),包括普通索引、唯一索引等。
聚集索引
在InnoDB中,只存在一个聚集索引:
- 若表存在主键,则主键索引就是聚集索引;
- 若表不存在主键,则会把第一个非空的唯一索引作为聚集索引;
- 否则,会隐式定义一个rowid作为聚集索引。
聚集索引基本上是一个树状组织的表。聚集索引不是将记录存储在未排序的堆表空间中,而是基本上是一个主键 B+Tree 索引,其叶子节点(按聚簇键列值排序)存储实际的表记录,如下图所示:
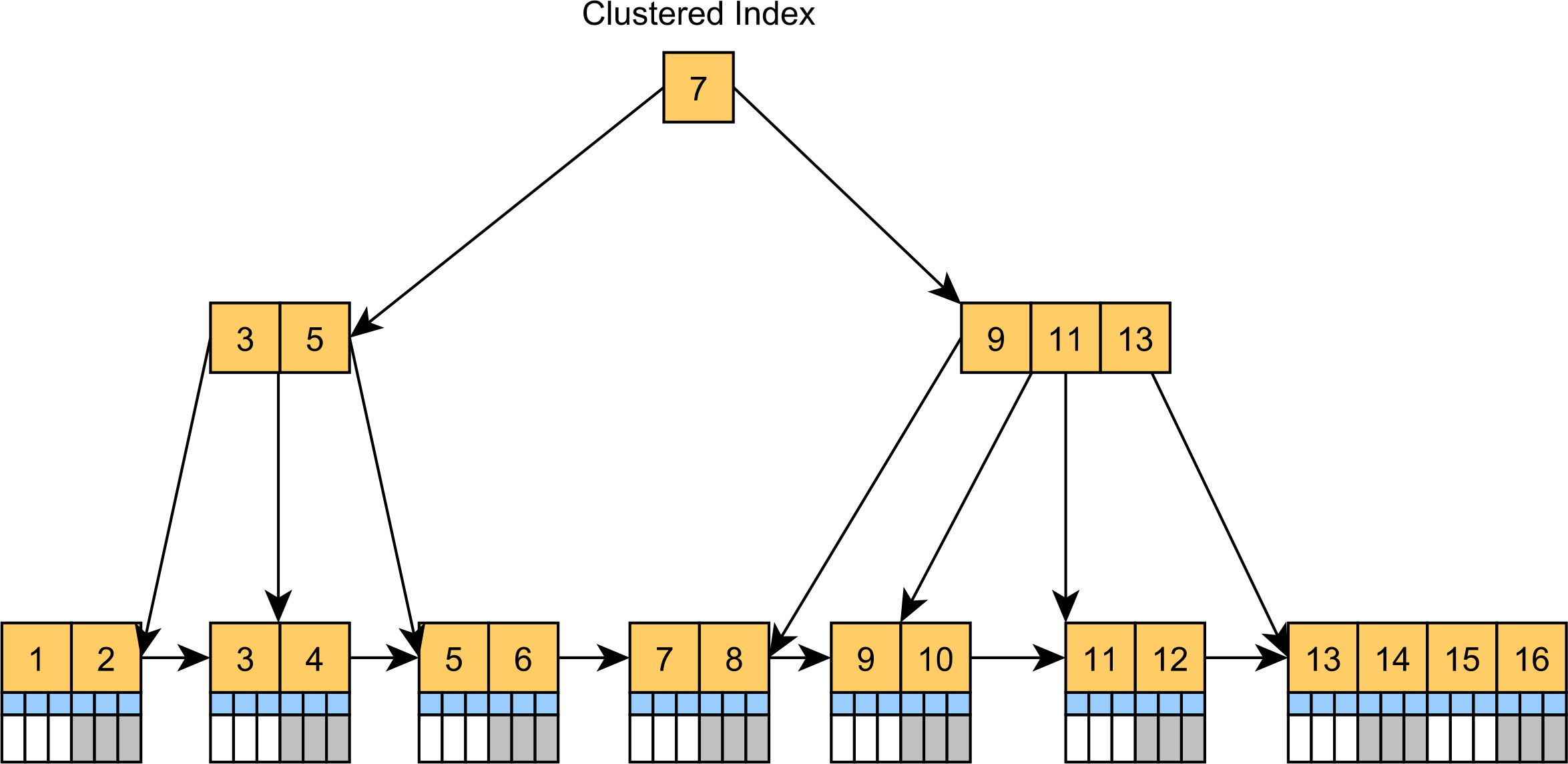
非聚集索引
由于聚集索引是使用主键列值构建的,如果您想加速使用其他列的查询,则必须添加二级索引,又叫做非聚集索引。
非聚集索引将在其叶子节点中存储主键值,如下图所示:
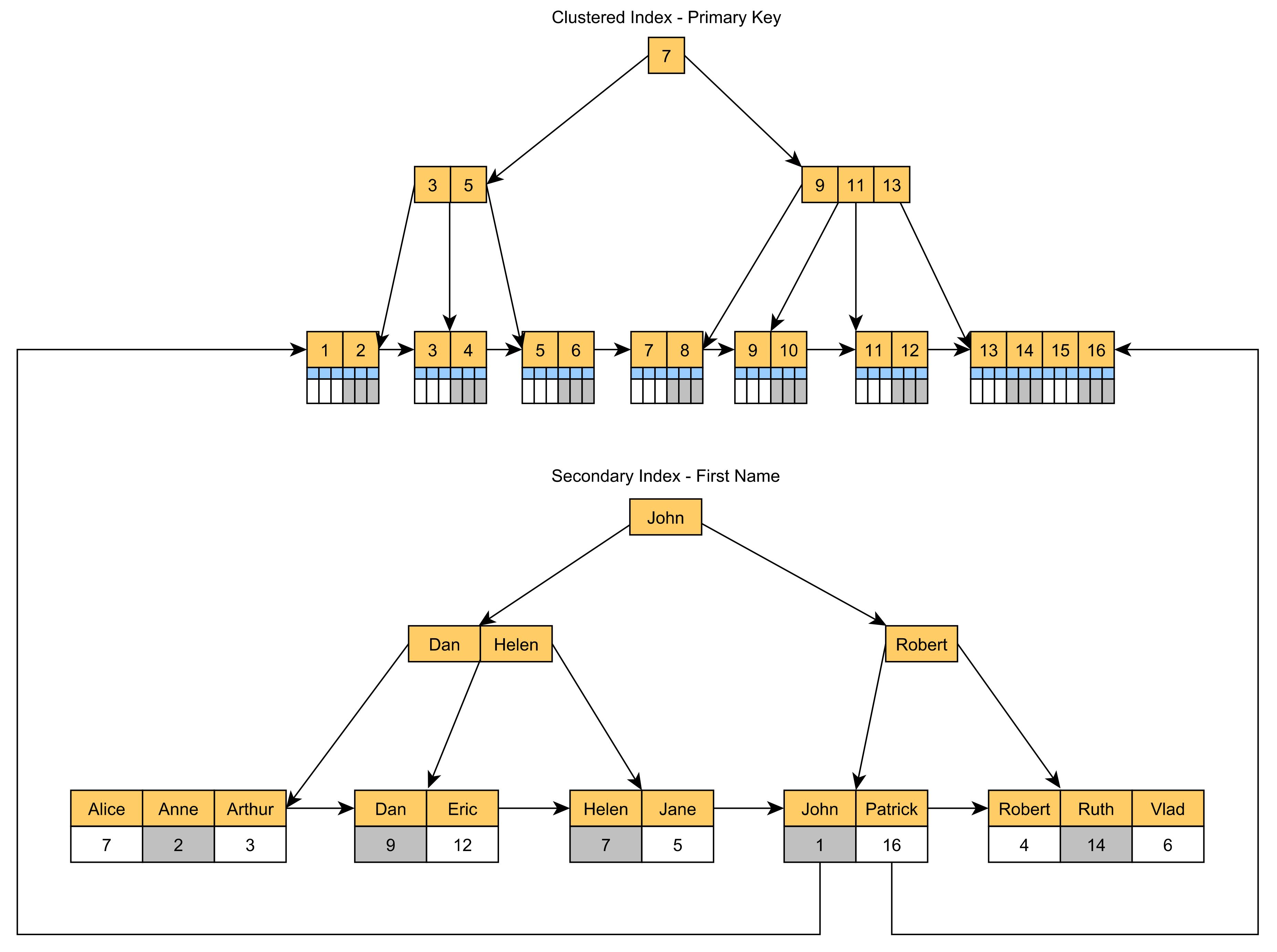
3. 回表查询
在聚集索引树上,因为叶子节点存储了所有的行记录(数据),所以通过主键查一次,就可以得到所有想得到的数据,速度很快。
但在非聚集索引树上,因为叶子节点存储的是主键信息,所以想得到非主键外的其他数据,还需要再拿着这个主键再次查询聚集索引,这个过程就叫做回表查询。
显然回表查询增加一次查找过程,速度会变慢。
4. 索引覆盖
既然回表查询会变慢,那怎么避免呢?答案就是索引覆盖。所谓索引覆盖,就是在使用这个索引查询时,使它的索引树的叶子节点上的数据可以覆盖你查询的所有字段,就可以避免回表了。
说通俗点,就是可以建立联合索引。索引树的叶子节点,就会存储联合索引的列的值,这样,当查找的是联合索引的列值时,就只需要查一遍联合索引的索引树,不需要回表了。
5. 最左匹配原则
指的是联合索引中,优先走最左边列的索引。
关于最左匹配原则,可以看这篇文章。
6. 总结
-
聚集索引全表就一个,其索引树叶子节点存储所有数据。
-
非聚集索引可以有多个,其索引树叶子节点,存储的是联合索引的列值,以及主键值。
-
当某次查询,命中非聚集索引,但是没能查出想要的列时,就会进行回表查询。
-
开发中要尽量避免产生回表。
参考
https://vladmihalcea.com/clustered-index/
https://worktile.com/kb/p/24047