手写分布式系统CP协议-实现中

按学习的进度安排,从深到广后重新写深入的项目》》》 终于到这一步了。
项目意义
为了秀肌肉
CP协议
CP二词来自CAP理论的CP二词,是在分布式系统中的核心概念【一致性】和【分区容错性】,在分布式系统中有不可提代的需求地位,包括目前流行的分布式:
- kafka
- k8s
- nacos
其中都有CP协议的实现,其意义和用途都非常的重要;
不懂P协议的必要性的读者可能得先深入了解分布式系统的实现
现状
当前的各项目CP协议实现都是高度定制、融合进项目,采用起来不方便
意义
- 秀肌肉&学习&铺路
- 分布式基础的深入了解
- 实现更高的性能
调研
主流协议
Paxos算法
著名的zookeeper采用的算法实现,十分的复杂,后多数采用Raft实现,本文不做调研
Raft算法
Raft是一种分布式一致性算法,用于在分布式系统中实现数据的一致性。Raft算法由Stanford大学的Diego Ongaro和John Ousterhout于2013年提出,相对于Paxos算法来说更易于理解和实现。
当下许多分布式系统采用该协议包括但不限于以下:
- Kafka
- K8s
- Nacos
本文的核心调研项目主要在Kafka和Nacos的实现中做调研。
无法直接告知读者CP协议的意义与用途,需要自己通过积累,去了解分布式中间件&集群的实现&理论知识
比如:mysql集群的实现和缺点、集群中心、分布式锁的意义、配置中心的系统架构与实现等等的分布式知识积累;
一个动画模拟网站 http://thesecretlivesofdata.com/raft/
Raft算法核心
所谓算法其实就是给定一个问题得到一个优秀的答案,
问题:分布式系统中(在多台机子)怎么实现数据的强一致性
解:按Raft定义的操作实现:
选举-核心、一
- 节点可以处于 3 种状态之一 : Follower、Candidate、Leader
- 一开始都是以Follower存在开始
- 每个节点都应该有一个明确的Leader,是自己或其他节点
- 如果Follower没有明确的Leader,那么他们可以成为Candidate
- Candidate会向其他节点发起投票,请求其他节点投选自己为Leader
- 接收到多数节点的【投票】回馈,那发起投票的Candidate就可以成为Leader
- 系统的所有更改都在Leader节点上完成
过程被称为Leader Election(选举)
选举-核心、二
现在要解释的是发生了一个更改的流程
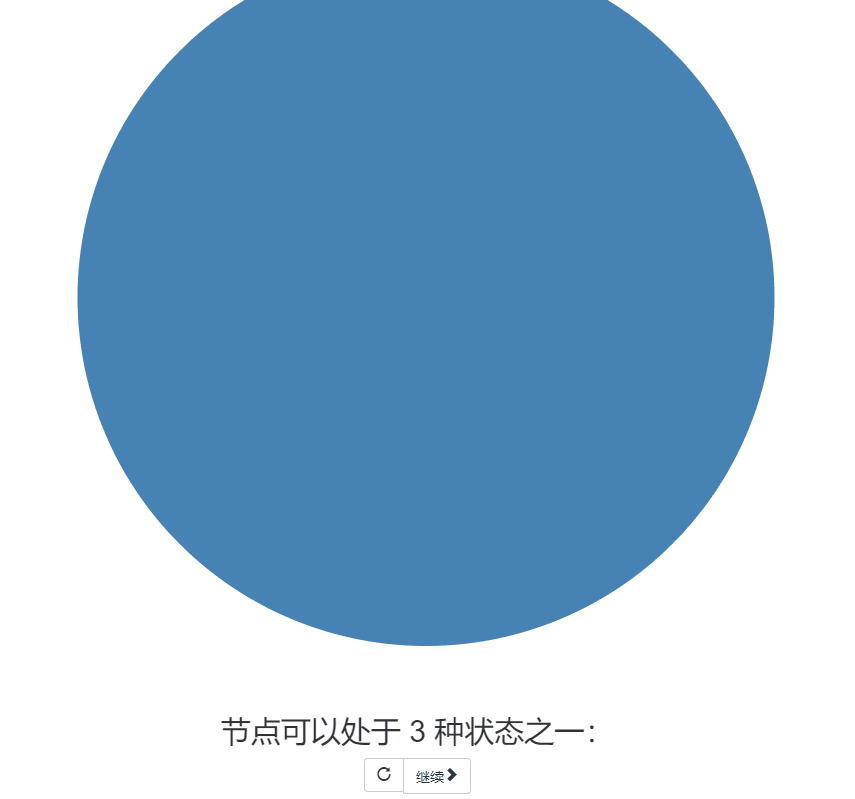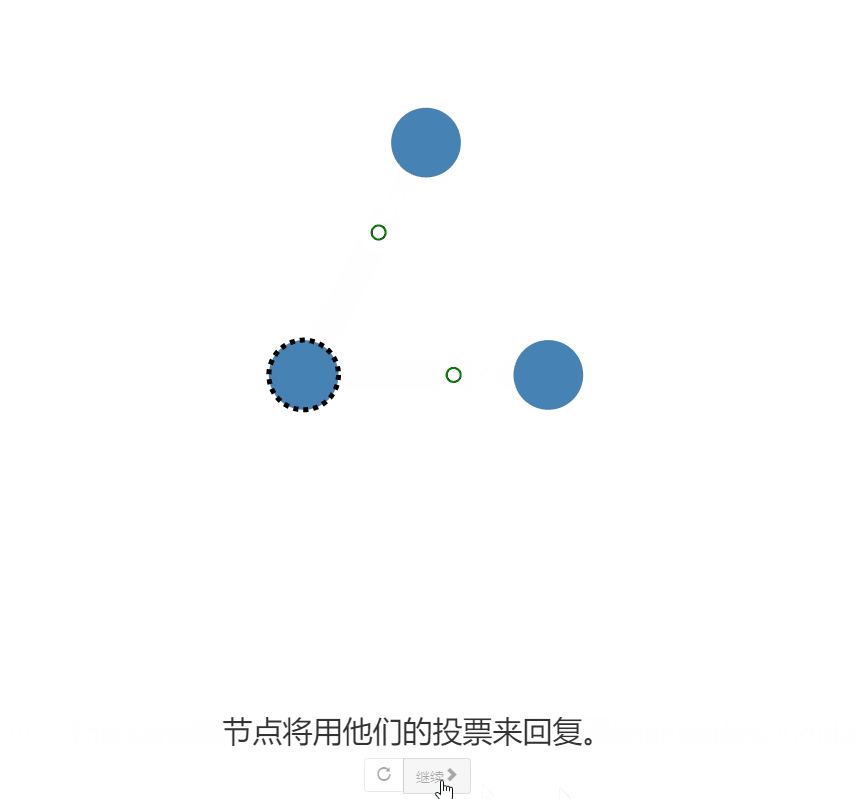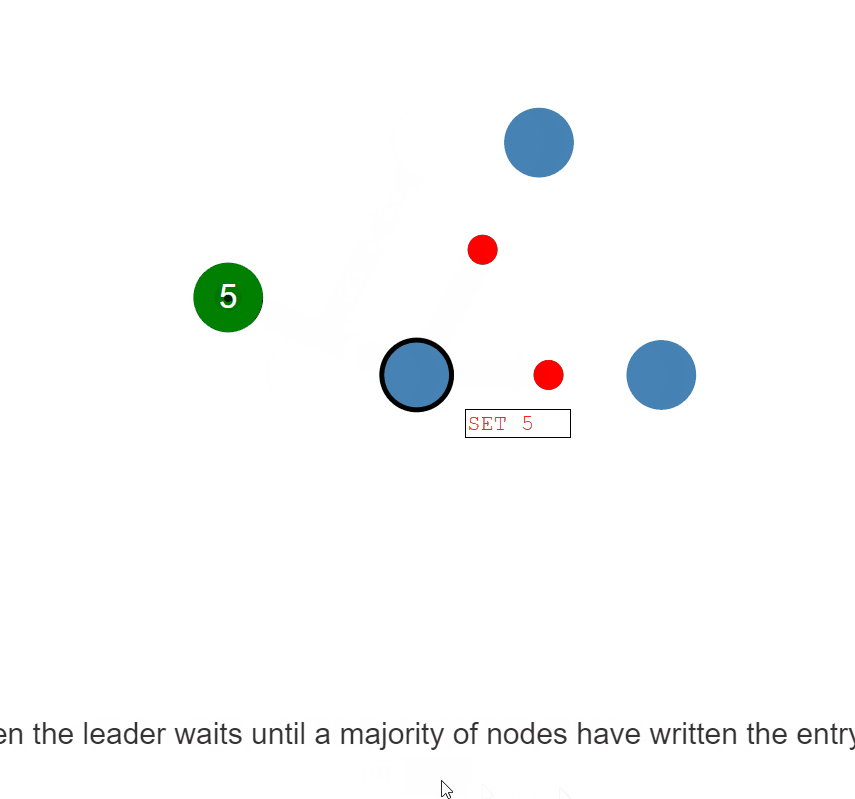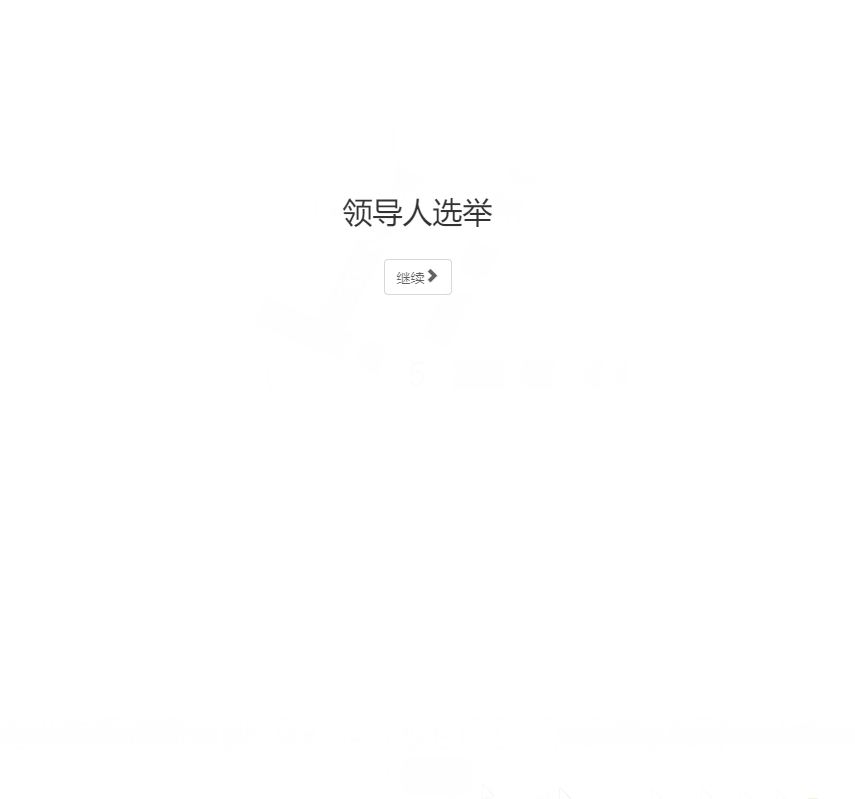
每个更改都作为一个条目添加到节点的日志中 -> 一开始日志条目当前未提交,因此不会更新节点的值
-> 要提交条目,节点首先将其复制到跟随者节点 -> 然后领导者等待,直到大多数节点都写入了条目
-> 该条目现在已在领导节点上提交 -> 然后领导者通知追随者该条目已提交
- 集群现在已经就系统状态达成共识
- 这个过程称为日志复制
这个过程会有一次的通知准备,确认后,通知全体提交
建议看图解http://thesecretlivesofdata.com/raft/
选举-核心、三
单纯的实现以上其实不难,但需要考虑到很多细节,一下是对选举过程的深入;
在 Raft 中有两个超时设置来控制选举
选举超时
选举超时是追随者等待成为候选人的时间,选举超时随机在 150 毫秒到 300 毫秒之间。
也就是说:假如有三个集群节点,按【核心一】的描述,一开始它们都没有leader,如果同时成为的Condidate,那会造成冲突(冲突发起也没关系,可以通过代码逻辑去解决),使用随机的倒计时,倒计时决定Follower什么时候成为iCondidate,避免节点之间的Condidate冲突
- 选举超时后,跟Follower为Condidate并开始新的选举任期
- 并向其他节点发送请求投票消息,走【核心一】的流程
- 如果接收节点在这个任期内还没有投票,那么它将投票给候选人并且节点重置其选举超时
- 一旦候选人获得多数选票,它就成为领导者
- 领导者开始向其追随者发送附加条目消息
- 这些消息按心跳超时指定的时间间隔发送
- 追随者然后响应每个附加条目消息
- 这个选举任期将一直持续到跟随者停止接收心跳并成为候选人为止
【重置其选举超时】因为此时所有节点之间还没有共同的leader,所以在回票以后只重置选举超时时间
【附加条目消息】相当于告诉其他节点,我是Leader你重置【选举超时时间】,一种心跳保活机制
【心跳超时指定的时间】 在此之间是【选举超时时间】,在此之后的倒计时是统一的心跳过去时间
选举-核心、四
在Leader节点挂了后呢?
重新选举
在Leader节点出现意外
- 停止向Folllower发送【附加条目消息
- 此时【心跳倒计时】结束
- 重新开始随机的【选举超时】倒计时
- 重新开始【核心一】和【核心三】的流程
这次的选举后任期【Term】也变成了2,出现了第二任期的Leader
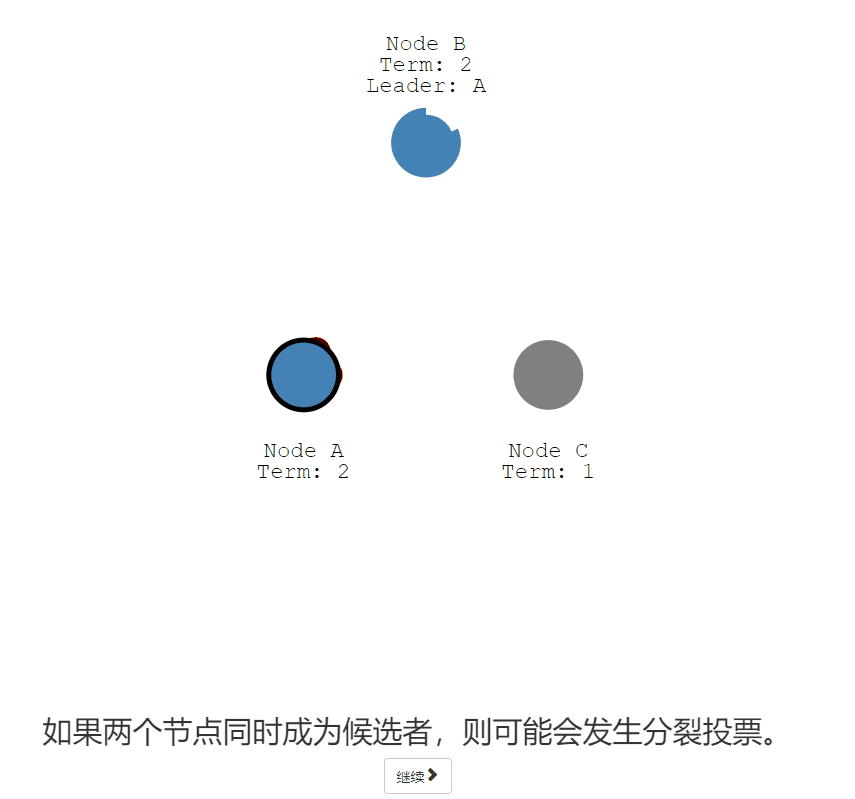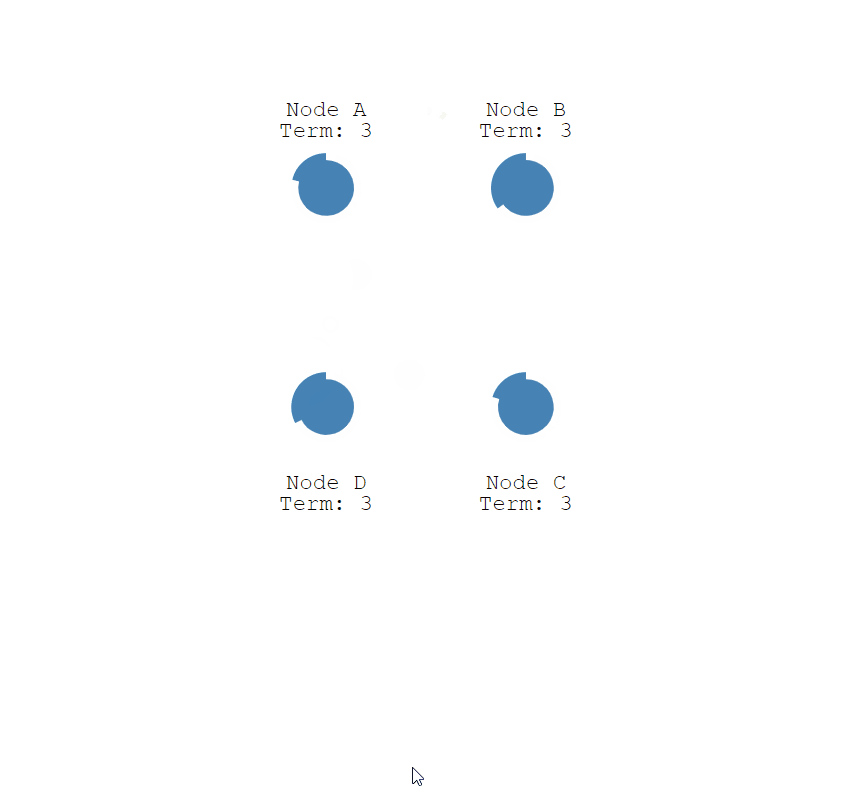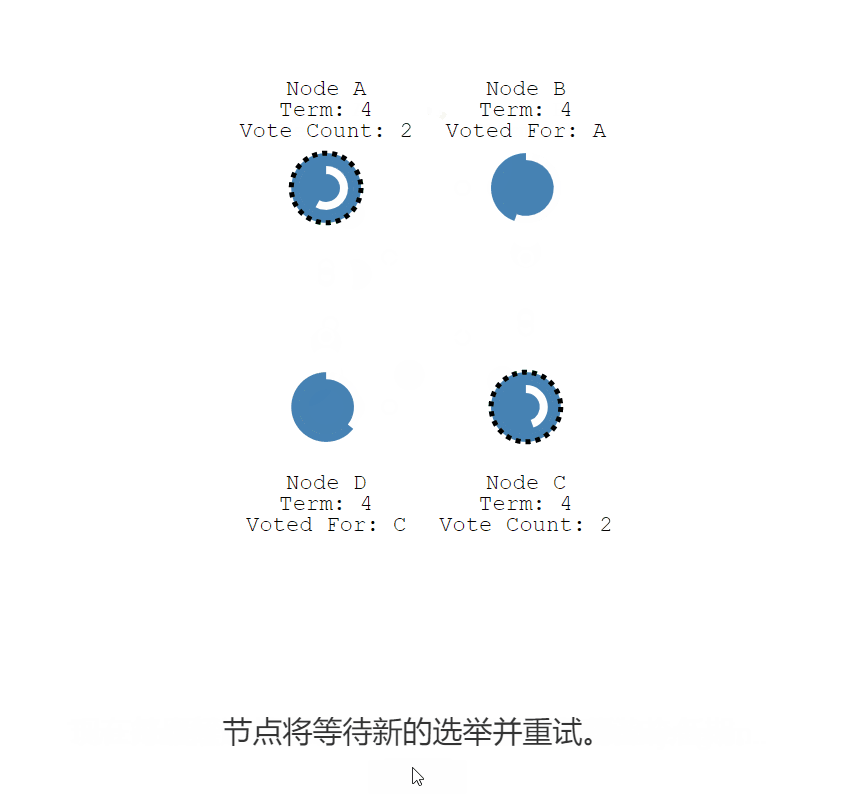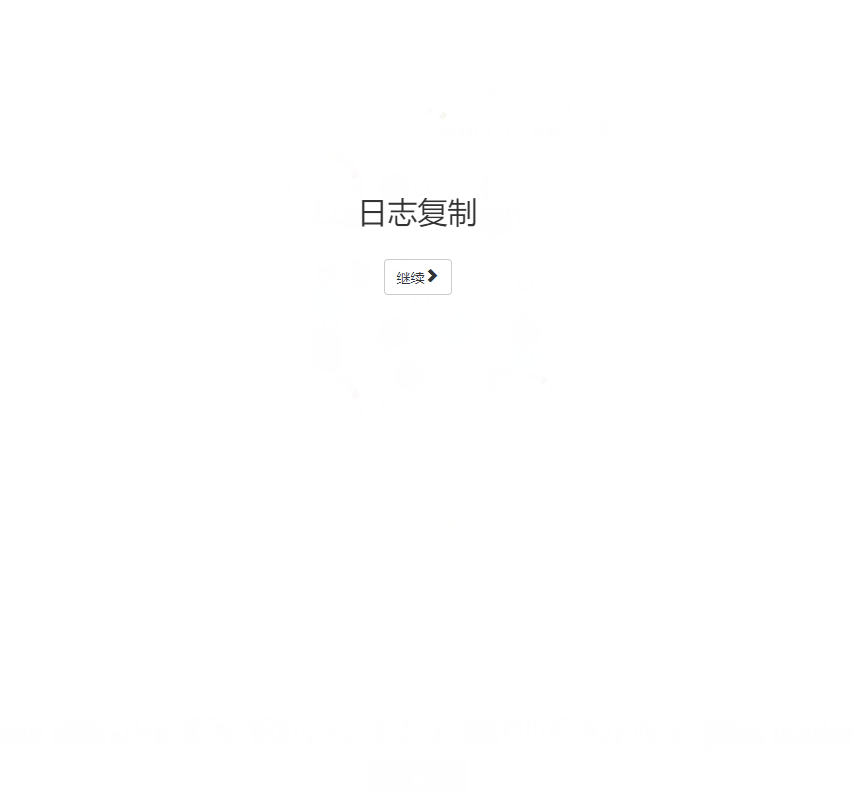
重复的Condidate
如果两个节点同时成为候选者,则可能会发生分裂投票。
随机的【选举超时】就是为了尽量避免
- 两个节点都开始了同一任期的选举
- 并且每个都先于另一个到达一个跟随者节点
- 现在每个候选人有 2 票,并且不能再获得这个任期
- 结束本期任期倒计时,节点重新随机【选举超时】
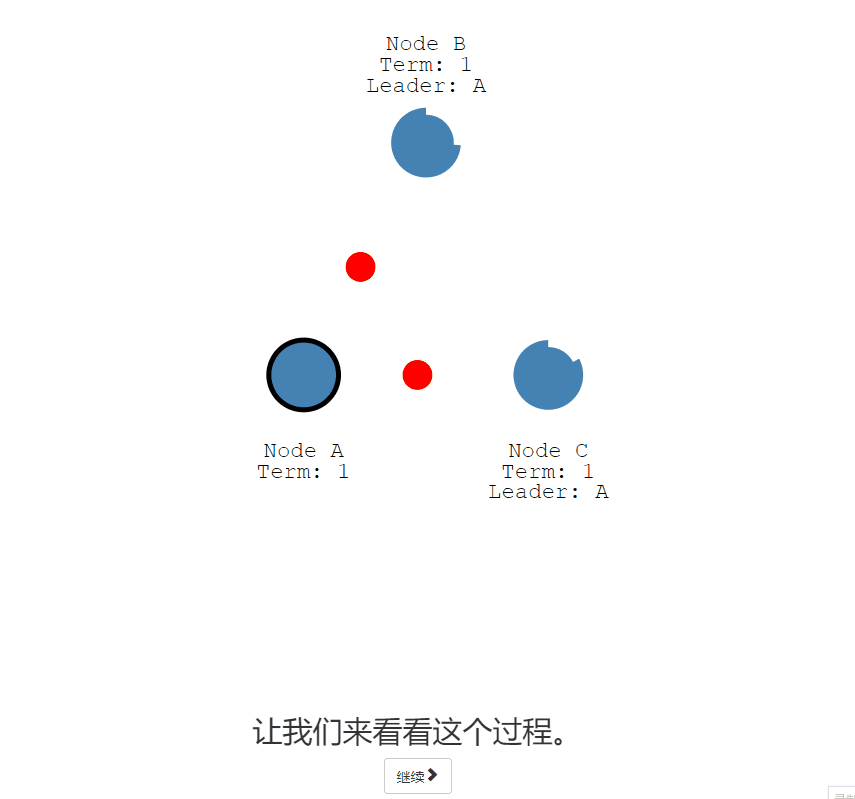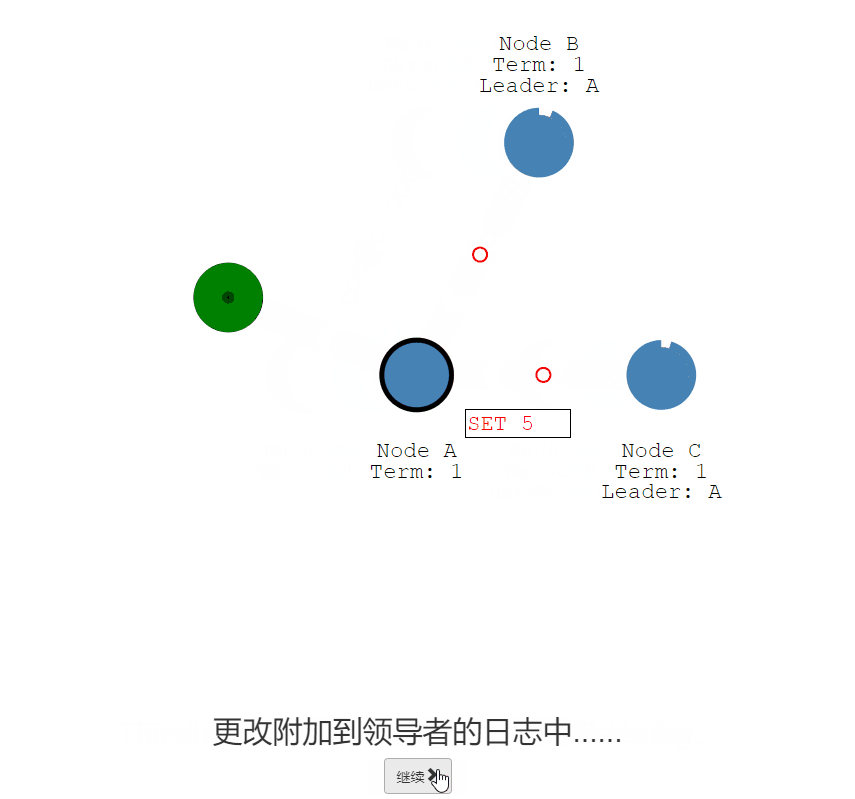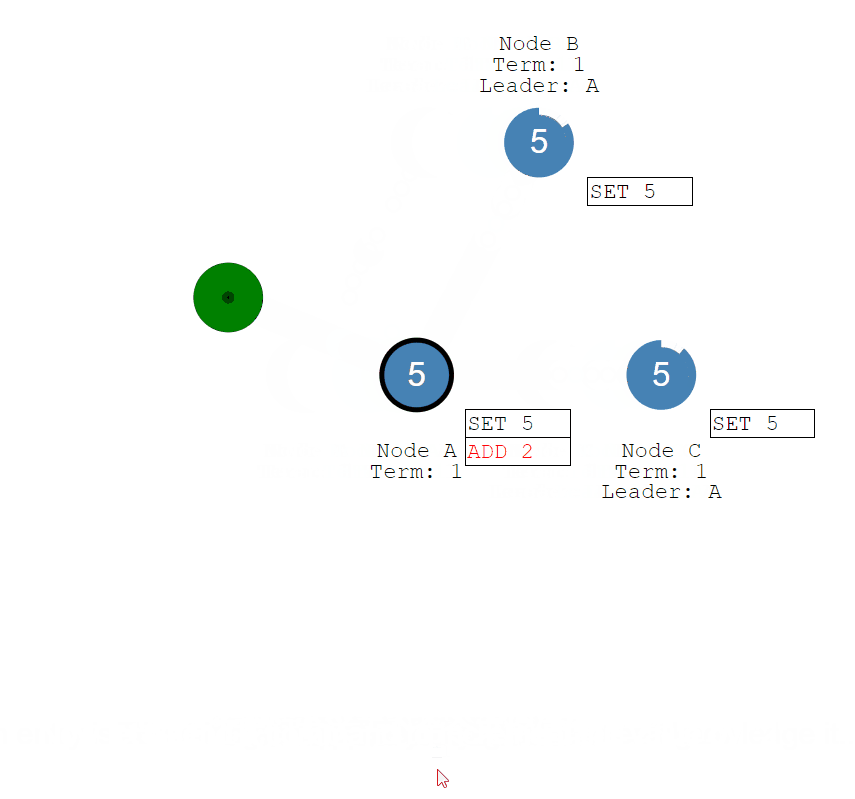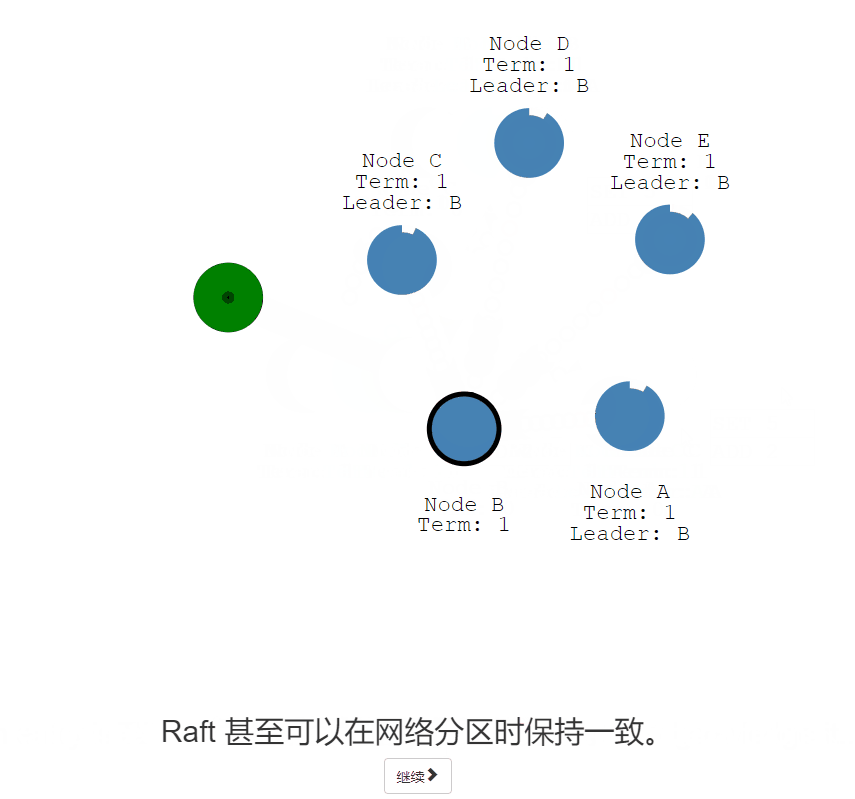
日志-核心、五
一旦我们选出了领导者,我们需要将对我们系统的所有更改复制到所有节点。
通过使用用于心跳的相同附加条目消息来完成的
- 首先,客户向领导者发送更改
- 更改附加到领导者的日志中,然后在下一次心跳时将更改发送给关注者
- 一旦大多数追随者承认,条目就会被提交,并向客户端发送响应
核心、六
Raft 甚至可以在网络分区时保持一致。
- 出现了网络分区,即将导致有两位不同任期的领导人
- 如果无法复制到多数(<1),因此它的日志条目保持未提交状态。
- 看到更高的选举任期并下台
- 回滚它们未提交的条目并匹配新领导者的日志
小结
简单了解后主要流程,可视的问题还有一些如下:
- 同步时等待下一次心跳携带日志发送,实时性不强
- 出现网络分区时,如果出现三个网络分区,其中两个分区的任期一致,在修复后怎么选择Leader
JRaft的实现
功能特性
- Leader 选举和基于优先级的半确定性 Leader 选举
- 日志复制和恢复
- 只读成员(学习者角色)
- 快照和日志压缩
- 集群线上配置变更,增加节点、删除节点、替换节点等
- 主动变更 Leader,用于重启维护,Leader 负载平衡等
- 对称网络分区容忍性
- 非对称网络分区容忍性
- 容错性,少数派故障,不影响系统整体可用性
- 多数派故障时手动恢复集群可用
- 高效的线性一致读,ReadIndex/LeaseRead
- 流水线复制
- 内置了基于 Metrics 类库的性能指标统计,有丰富的性能统计指标
- 通过了 Jepsen 一致性验证测试
- SOFAJRaft 中包含了一个嵌入式的分布式 KV 存储实现
1
- 多种日志存储实现: Berkeley DB、Hybrid、RocksDB(默认)、Logit
- SofaRpc: 金融级稳定框架
2
- 多种场景节点通信、用户端等都是用Netty对于场景特化不够好,性能损耗高
- 协程模型
Kafka的实现
网络模型
Kafka的网络模型是基于TCP协议的,采用了一种基于事件驱动的非阻塞I/O模型,称为NIO(New I/O)。Kafka的网络模型主要包括以下几个组件:
- Broker:Kafka的服务器节点,负责接收和处理客户端的请求。
- Producer:生产者,向Kafka集群发送消息。
- Consumer:消费者,从Kafka集群中消费消息。
- Topic:消息主题,Kafka中的消息按照主题进行分类。
- Partition:分区,每个主题可以分为多个分区,每个分区可以在不同的Broker上进行副本复制。
- Replica:副本,每个分区可以有多个副本,用于提高数据的可靠性和可用性。
- Controller:控制器,负责管理Kafka集群的状态和分区的分配。
Kafka的网络模型采用了多线程的方式处理客户端请求,每个线程都维护一个Selector对象,用于监听多个Channel的事件。当有事件发生时,Selector会通知相应的线程进行处理。Kafka的网络模型还采用了零拷贝技术,避免了数据的多次复制,提高了性能和吞吐量。
一套代码看下来,他的selector适合创建多个,并且在每个特定的场景下共用,基本上每个selector都是单线程下,然后获取读取出来的请求体再进行业务操作
开源实现的优缺点
新设计
相比开源项目的优化点
- 协程
- 原生Nio
- Zore-Copy