数据库浅谈之 LLVM

数据库浅谈之 LLVM
HELLO,各位博友好,我是阿呆 🙈🙈🙈
这里是数据库浅谈系列,收录在专栏 DATABASE 中 😜😜😜
本系列阿呆将记录一些数据库领域相关的知识 🏃🏃🏃
OK,兄弟们,废话不多直接开冲 🌞🌞🌞
一 🏠 概述
了解 LLVM
LLVM,一个自由软件项目,是一种编译器的基础建设,底层 C++ 实现
它利用虚拟技术,创造出编译时期,链接时期,运行时期最优化
它目标为所有静态和动态语言创造出动态编译技术,LLVM 源自于底层虚拟机(Low Level Virtual Machine)首字字母缩写
它提供了一种在程序运行时编译执行代码的程序框架
LLVM 特性
1、LLVM 可以在编译时期、链接时期,甚至是运行时期产生可重新定位的代码
2、LLVM 支持与语言无关的指令集架构及类型系统。LLVM 可以提供完整编译器系统的中间层,从编译器获取中间表示(IR)代码并发出优化 IR,然后将新 IR 转换并链接到目标平台的汇编语言代码
使用 LLVM API 会生成中间代码 IR,存放在内存或外部文件中。在目标文件执行,对应平台会再生成机器码执行
这意味着在 IR 层编程,在不同的 CPU 上执行,会在当前硬件平台生成最优机器码
Intel x86,不同代 CPU 优化程度也不同。例如 :LLVM 会充分利用新 CPU 上的指令集,SIMD。这一点在数据仓库做浮点数计算时会用到
3、LLVM API 可用于编码,并生成 LLVM IR 中间代码。支持多种编码语言,C/C++ 均覆盖
4、LLVM 前端编译器 clang 兼容 gcc,且性能相当。相关代码使用编译器 clang 编译,能和 gcc 编译二进制相互链接
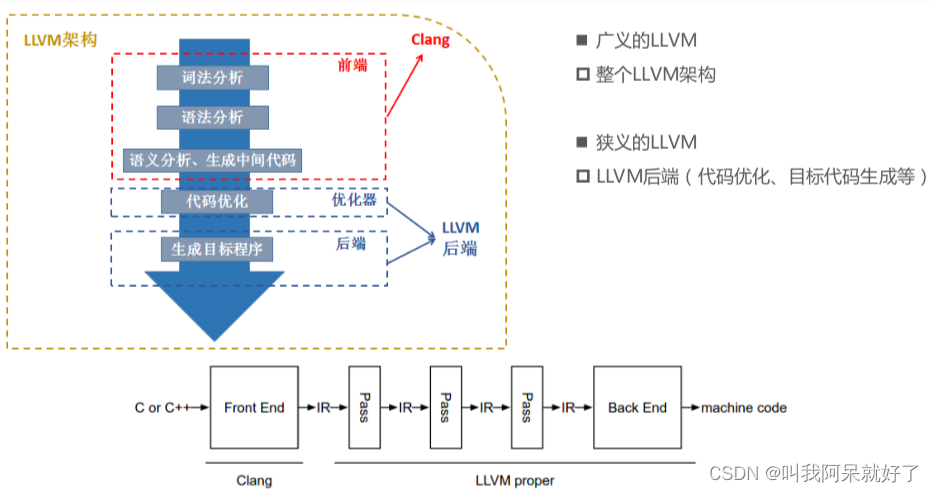
二 🏠 核心
了解 JIT
Just-In-Time Compiler,是一种动态编译中间代码的方式,根据需要,在程序中编译并执行生成的机器码,能够大幅提升动态语言的执行速度
通常高级语言分为两种 :编译型语言和解释型语言,静态编译(C / C++)程序在执行前全部被翻译为机器码,解释型(JS)则是在执行过程中一句一句边运行边翻译
JIT 混合了这二者,相对于静态编译代码,可以处理延迟绑定并增强安全性
JIT 引擎的工作原理并没有那么复杂,本质上是将原来编译器要生成机器码的部分要直接写入到当前的内存中,然后通过函数指针的转换,找到对应的机器码并进行执行
在数据库领域,单个任务为追求高性能,需尽可能利用整个集群的硬件资源进行计算
分析业务无疑是 CPU 密集型的任务,经常一个任务会调度整个集群的 CPU 满负荷运转几分钟,甚至几小时,提高 CPU 的计算效率是一个通用的性能优化任务
了解数据库内核的博友,实现应该知道后端编码往往是一套通用的数据处理。例如 :实现不同数据类型(定长,变长)组合的表结构读写,但是针对于单条 SQL 却只涉及固定表和列类型。比如 :Select * From Tab (Tab 表,列个数和类型均固定)
那么对于单条 SQL ,很多 变量,已成为 常量 ,如果在已知的条件下写固定代码,必然会去掉很多条件判断等逻辑 ,JIT 技术便可以达成这样的梦想
LLVM 应用
一、优化频繁调用的存取层
数据库执行器通过存取层装载数据,针对特定的表结构,可以定制读取和解析。例 :通常情况下通用解析流程如下,列数据类型不同,进行分支判断

当确定表结构后, 动态生成的代码

按照顺序解析数据,而不需数据类型判断,直接获取对应偏移数据,跳过不需要的列,这些都可以简化 CPU 指令。随着处理的行数增加,节省的计算量是惊人的
二、表达式计算
关系数据库,表达式计算基于一套通用框架,表达式求值类似一颗二叉树计算,过程是从叶节点计算到根节点,整个步骤递归执行(表达式越复杂,递归层级越深)
但是在获取到查询计划之后再 动态编译,只需如下

具体优势
1、递归改为顺序执行
2、整个过程一个函数调用完成,性能提高明显
3、去掉分支判断,高效利用 CPU Cache
4、CPU 指令大量减少,高效利用 CPU计算
5、循环展开和 SIMD
使用基于内存计算的 LLVM 技术来提高表达式引擎的计算能力,适用于复杂 SQL 场景下,在任意位置上出现表达式计算场景,提高 CPU 执行效率,显著降低硬件成本
三 🏠 结语
身处于这个浮躁的社会,却有耐心看到这里,你一定是个很厉害的人吧 👍👍👍
各位博友觉得文章有帮助的话,别忘了点赞 + 关注哦,你们的鼓励就是我最大的动力
博主还会不断更新更优质的内容,加油吧!技术人! 💪💪💪