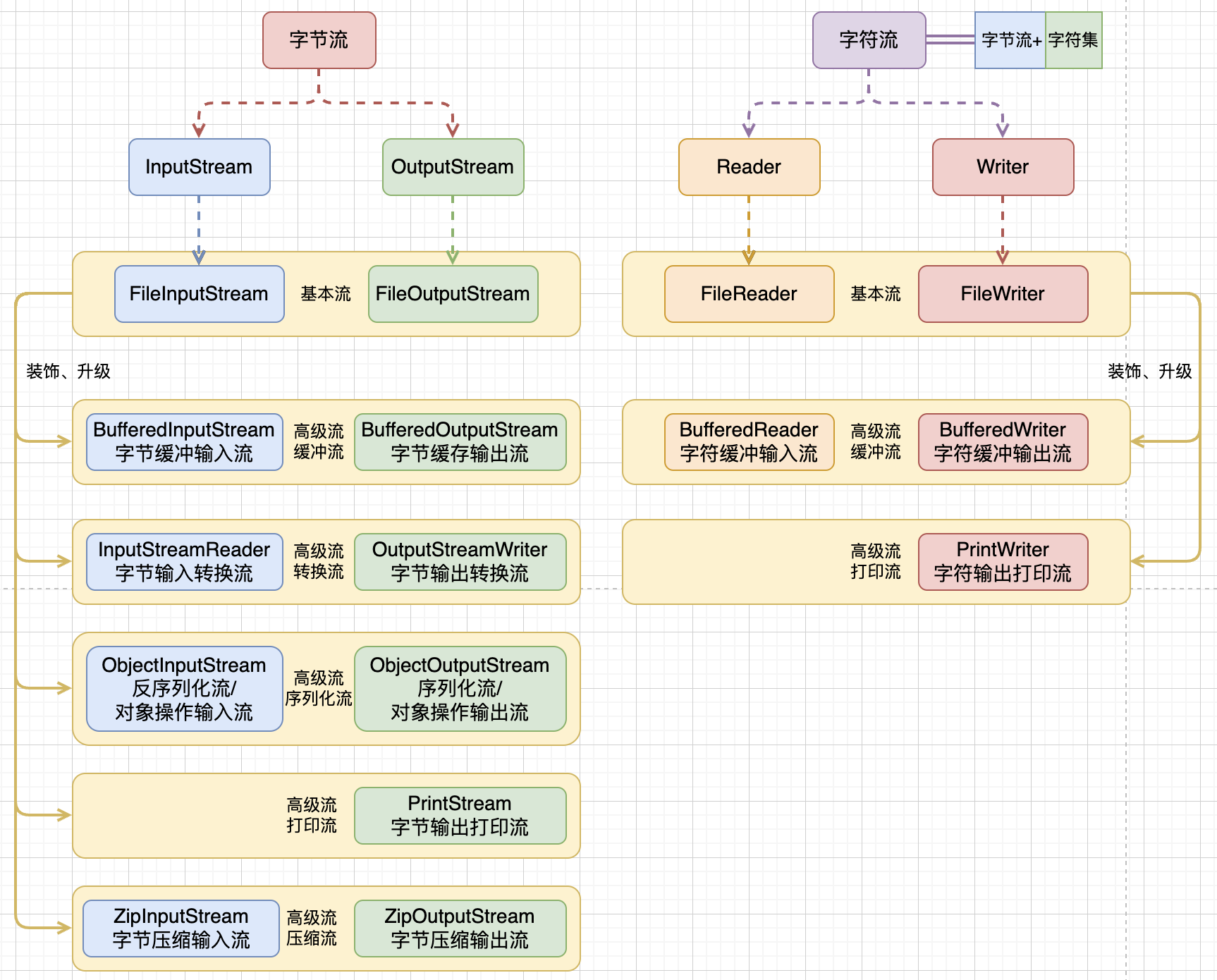
JavaIO流学习总结,字符编码,字节流+字符流

JAVA IO
文章目录
一,介绍
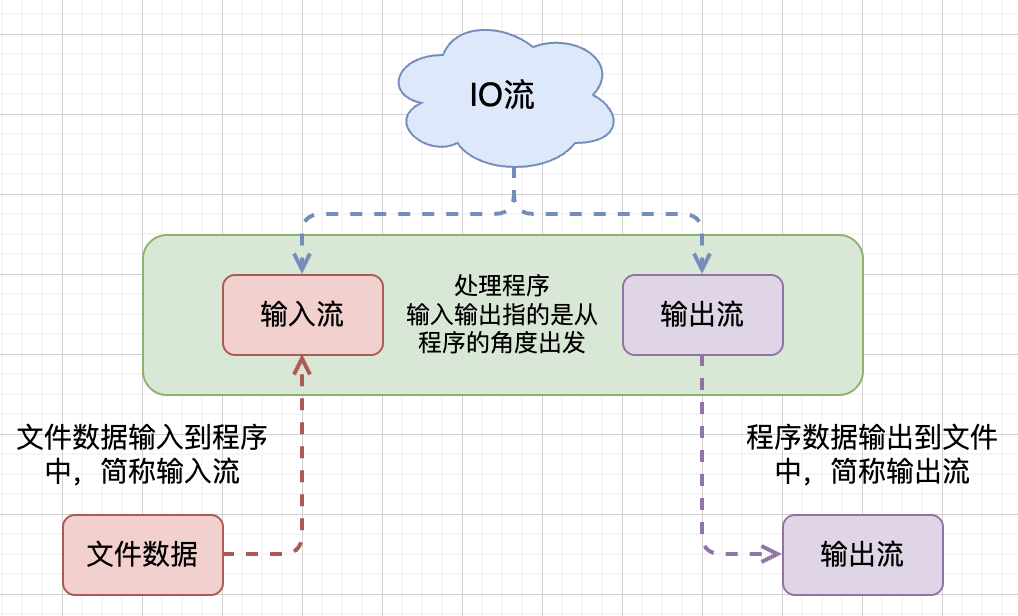
IO流,就是存储和读取数据的解决方案,I代表input、O代表output、流表示像水流一样传递数据。其可以帮我们读写本地或网络上的数据文件。
我们通常将流分为两大类,输入流与输出流,这样的划分方式其实就是处理流的程序对象为主体划分的,比如输入流:指的是文件里的数据输入到程序中;输出流:指的是程序中的数据输入到文件中。
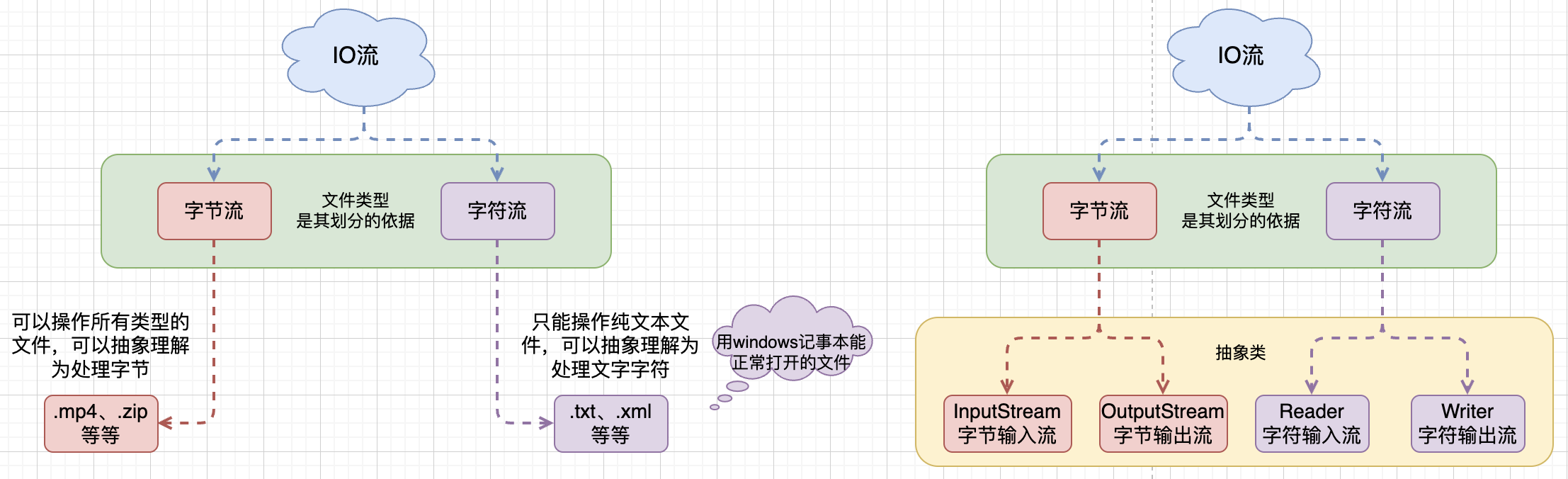
从代码的角度来讲,Java将IO流主要分为了两大类,字节流与字符流,主要是为了针对不同的文件类型。
二,字符编码
学习IO流之前建议先学习字符编码,就比如换行符在不同的操作系统中编码是不一样的,这一点一定要注意,之前就是linux服务器识别不了我的配置文件:windows换行=
\\r\\n,linux换行=\\n,mac换行=\\r。参考:https://blog.csdn.net/a156438/article/details/121417824
字符编码指的是一种隐射规则,根据这个映射规则就可以将某个字符映射成其他形式的数据以便在计算机中存储和传输。例如ASCII字符编码规定使用单字节(一字节等于8个bit位)中的低7个比特去编码所有的字符,比如A的ASCII码就是65,也就是二进制的0100 0001。
常见的几种编码:
| 编码 | 制定时间 | 作用 | 所占字节数 |
|---|---|---|---|
| ASCII | 1967年 | 表示英语和西欧语言 | 8bit/1bytes |
| GB2312 | 1980年 | 国家简体中文字符集,兼容ASCII | 2bytes |
| Unicode | 1991年 | 国际标准组织统一的标准字符串 | 2bytes |
| UTF-8 | 1992年 | Unicode的一种编码方式,不定长编码 | 1~3bytes |
| GBK | 1995年 | GB2312的扩展字符集,支持繁体字,兼容GB2312 | 2bytes |
Java中的字节:
| Type | Bit(位) | Byte(字节) |
|---|---|---|
| byte | 8 bit | 1 bytes |
| char | 16 bit | 2 bytes |
| short | 16 bit | 2 bytes |
| int | 32 bit | 4 bytes |
| float | 32bit | 4bytes |
| long | 64bit | 8bytes |
| double | 64bit | 8bytes |
jdk8以及之前String的底层都是char vlaues[],而从jdk9开始便被替换为了byte vlaues[],目的就是为了优化。
三,字节流
介绍几个常用的字节流,其他字节流万变不离其宗。
字符流可以操作任意类型的数据,每次操作也可以操作任意大小的字节数组。
3.1)File Input/Output Stream
- FileInputStream
基本的读取数据,无缓存处理,直接与硬盘上的文件做交互,每次要读取指定长度的数据(默认1字节)时,是直接去硬盘上读取指定长度的数据。
/* int read() 一次读一个字节,读出来的是数据在ASCII上对应的数字* 读取到文件末尾时,返回值为 -1*/
@Test
public void read() {try (FileInputStream fis =new FileInputStream("./src/test/java/com/shadowy/io/FileIOTest.txt")) {// read读取数据时,每次读取一个数据就移动一次指针,因此不用显示的移动指针int b;while ((b = fis.read()) != -1) {System.out.print((char) b);}} catch (IOException e) {throw new RuntimeException(e);}
}/* int read(byte[]) 一次读取一个字节数组的长度* byte[1] = 1字节 = 8bit位(0000 0001)* byte[1024] = 1KB* byte[1024 * 1024] = 1MB* 注意:并不是byte字节数组越大越好,因为大数组会占用很多内存空间*/
@Test
public void readArr() {try (FileInputStream fis = new FileInputStream("./Dockerfile")) {byte[] bytes = new byte[1024 * 1024];int len;while (((len = fis.read(bytes)) != -1)) {System.out.print(bytes);}} catch (IOException e) {throw new RuntimeException(e);}
}
- FileOutputStream
基本的写入数据,无缓存处理,直接与硬盘上的文件做交互,写数据操作都是实时的。每次创建该对象时会先创建一个File文件,如果已经存在则会清空里面的内容,可在构造方法中指定append属性来表示追加模式。
/* FileOutputStream* void write(int b) 一次写一个字节的数据* void write(byte[] b) 一次写一个字节数组的数据* void write(byte[] b, int off, int len) 一次写一个字节数组的部分数据*/
@Test
public void write() {try (FileOutputStream fos =new FileOutputStream("./src/test/java/com/shadowy/io/FileIOTest.txt")) {fos.write(97);String str = "|myHeavyHead|";byte[] bytes = str.getBytes();fos.write(bytes);fos.write(bytes, 0, 3);} catch (IOException e) {throw new RuntimeException(e);}
}
3.2)Buffered Input/Output Stream
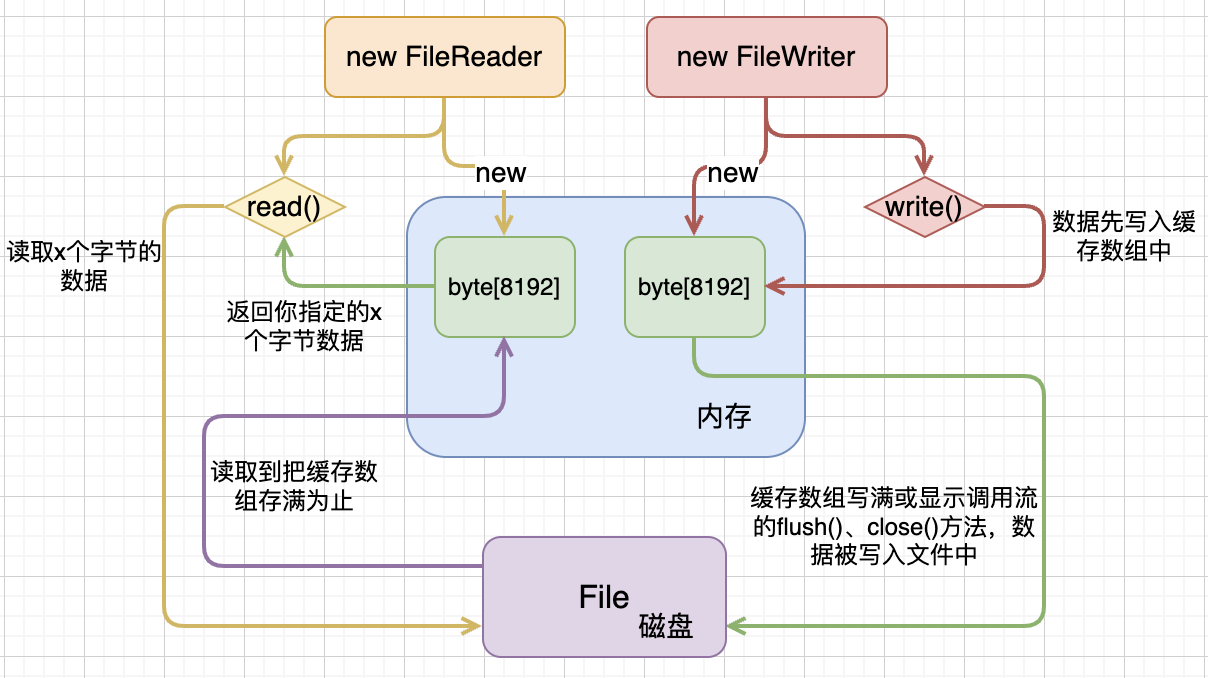
Buffered是对基本类型File的增强,前面说过File~是无缓存的,所有的读写操作都是直接与硬盘进行交互,这就会带来极大的用户态和内核态切换开销,因此通过给予缓存,能极大提升其性能。默认的在创建对应的流时就会自动创建一个默认大小的数组byte[8192],当然这个值可以显示的指定修改。

其交互流程大致如下,和字符流FileReader、FileWriter很类似:

通过一个复制文件的例子感受一下:
/* 高级流,字节缓冲输入输出流,BufferedInputStream + BufferedOutputStream* 默认会创建byte[8192]大小的缓冲区,用来交换数据* private static int DEFAULT_BUFFER_SIZE = 8192;*/
@Test
public void bufferFileTest() {try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("./LICENSE"));BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("./src/test/java/com/shadowy/io/LICENSE_Copy"))) {byte[] bytes = new byte[1024];int len;while ((len = bis.read(bytes)) != -1) {bos.write(bytes, 0, len);}} catch (IOException e) {throw new RuntimeException(e);}
}
四,字符流
介绍几个常用的字符流,其他字符流万变不离其宗。
字符流只能操作本地文件的纯文本数据,它的底层其实就是字节流+字符集,但字符流默认是带缓存区的,无论输入还是输出流都有缓存区的帮助。
字符输入流:一次读取一个字节,遇到中文时,根据字符集一次读取多个字节;
字符输出流:底层会把数据按照指定的编码方式进行编码,变成字节然后再写入到文件中去。
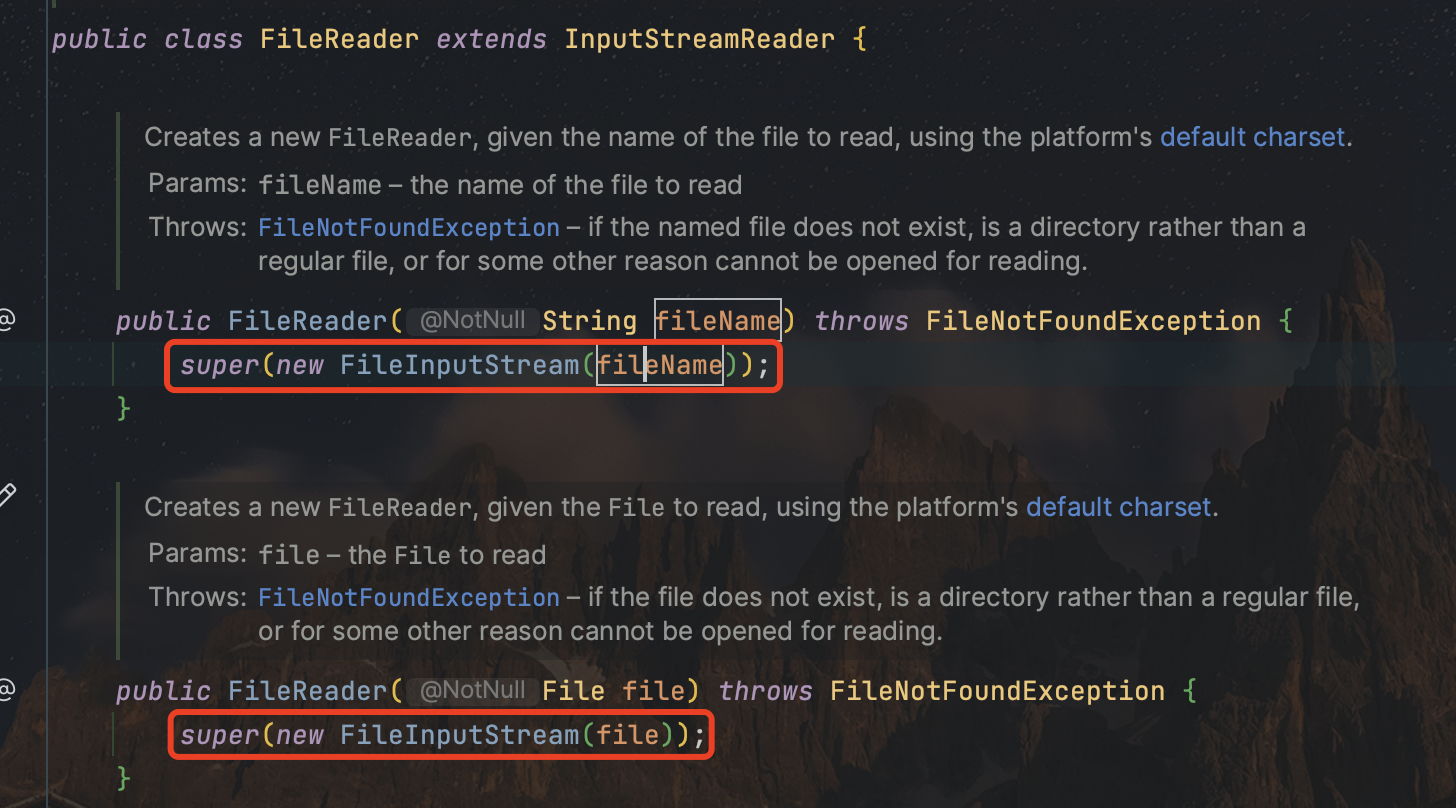
4.1)File Reader/Writer
- FileReader
字符流的底层就是字节流,因此他也支持多字节读取,默认是一个字节一个字节进行读取,但是遇到中文时会自动一次性读取多个字节。
/* read():* 1)默认一个字节一个字节读取,遇到中文读取多个字节;* 2)在读取之后,方法的底层会将其转码并转换为十进制,最终将这个十进制作为返回值。* 英文二进制数:01100001,读取之后,解码并转为十进制=97* 中文二进制数(UTF-8):11100110 10110001 10001001,读取之后解码转十进制=27721* 如果想转为最开始的中文汉字,就把读取出来的十进制数强转为我们需要的编码即可*/
@Test
public void testRead() {try (FileReader fr = new FileReader("./Dockerfile")) {int chars;while ((chars = fr.read()) != -1) {System.out.print((char) chars);}} catch (IOException e) {throw new RuntimeException(e);}
}/* read(char[] buffer): 一次读取多个字符* 1)带参数的read方法将 读取数据、解码、强转三步都合并了,他会自动将强转之后的字符放到数组当中去*/
@Test
public void testReadFile() {try (FileReader fr = new FileReader("./Dockerfile")) {char[] buffer = new char[2];int len;while ((len = fr.read(buffer)) != -1) {System.out.print(new String(buffer, 0, len));}} catch (IOException e) {throw new RuntimeException(e);}
}
- FileWriter
字符流写入数据也支持多种数据类型写入,但由于缓存区的存在,写入操作并不是像fileOutputStream那样实时展现在文件上的。
/* void write(int c) 写出一个字符,会自动将int转编码然后写入* void write(String str) 写出一个字符串* void write(String str, int off, int len) 写出一个字符串的一部分* void write(char[] cBuffer) 写出一个字符数组* void write(char[] cBuffer, int off, int len) 写出一个字符数组的一部分*/
@Test
public void testWriteFile() {try (FileWriter fw = new FileWriter("./src/test/java/com/shadowy/io/RWIOTest.txt")) {fw.write(25105);fw.write("\\rmyheavyhead我的头好重");char[] cBuffer = new char[]{'\\r', 'm', 'y', 'h'};fw.write(cBuffer);} catch (IOException e) {throw new RuntimeException(e);}
}
- 缓存区
对于字符流FileReader与FileWriter,每次关联文件(创建)时,都会自动在内存中创建一个长度为8192也就是8kb的字节数组,当我们要读写数据时,该缓存区都会帮助我们提升效率。
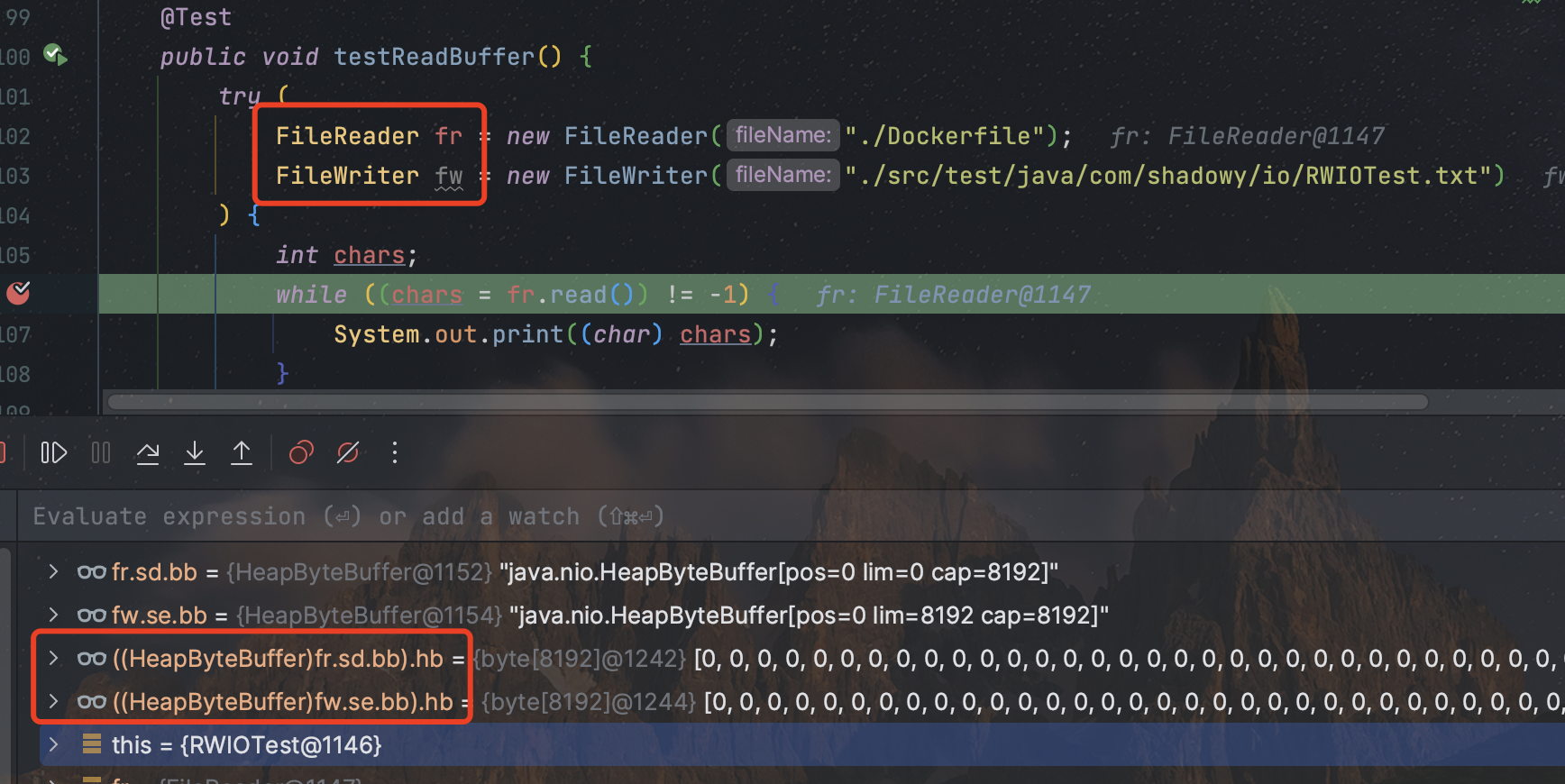
字符输入流原理:
/* 1)创建字符输入流对象* 底层:关联文件时,会自动创建一个缓冲区(长度为8192的byte[]数组,8个字节)* 2)读取数据* 底层:2.1 判断缓冲区中有无数据可以读取* 2.2 缓冲区中没有数据时,就从文件中读取数据,装到缓冲区中,每次尽可能装满缓冲区,如果文件也没有数据,返回-1* 2.3 缓冲区中有数据时,就从缓冲区中读取:* 2.3.1 无参的read()方法:一次读取一个字节,遇到中文时一次读取多个字节,并把字节转码为十进制返回* 2.3.2 有参的read()方法:把读取字节、转码、强转三步合并,强转之后的字符放到数组中*/
@Test
public void testReadBuffer() {try (FileReader fr = new FileReader("./Dockerfile");) {int chars;while ((chars = fr.read()) != -1) {System.out.print((char) chars);}} catch (IOException e) {throw new RuntimeException(e);}
}
字符输出流原理:
/* 字符输出流原理解析:* 1)创建字符输出流对象* 底层:关联文件时,会自动创建一个缓冲区(长度为8192的byte[]数组,8个字节)* 2)写入数据* 底层:2.1 判断缓冲区中有无空闲位置可以写入* 2.2 缓冲区中有空闲位置时,就把要写入的内容先写入缓冲区* 2.3 缓冲区没有空闲位置时,先把已经满的缓冲区都写入文件中,再执行2.2步骤* 2.4 可以显式的调用flush或close方法强制把缓冲区的内容写入文件中*/
@Test
public void testWriteBuffer() {try (FileWriter fw = new FileWriter("./src/test/java/com/shadowy/io/RWIOTest.txt")) {for (int i = 100; i < 199; i++) {fw.write(i);}} catch (IOException e) {throw new RuntimeException(e);}
}
4.2)Buffered Reader/Writer
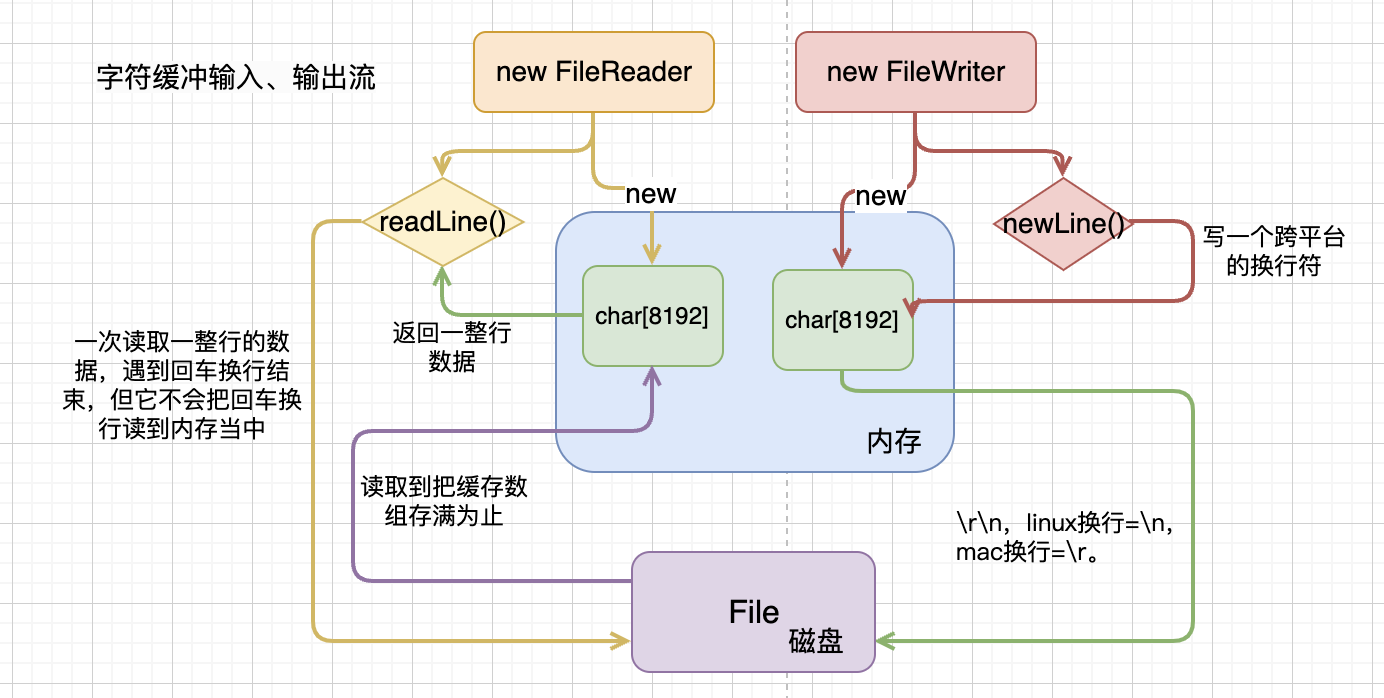
前面说过字符基本流就已经带有缓冲区的能力了,那为什么还有字符缓冲流。其实它的出现就是为了更好的处理文本数据,普通字符流创建时会在内存中创建一个byte[8192],而字符缓冲流则会创建一个char[8192],而char=2byte,所以其缓冲区是普通流的两倍,可以显著提高字节流的读写性能。字符缓冲流还提供了两个特有的方法用于操作数据:
BufferedReader.readLine():一次读取一整行的数据,遇到回车换行结束,但它不会把回车换行读到内存当中;BufferedWriter.newLine():写一个跨平台的换行符。
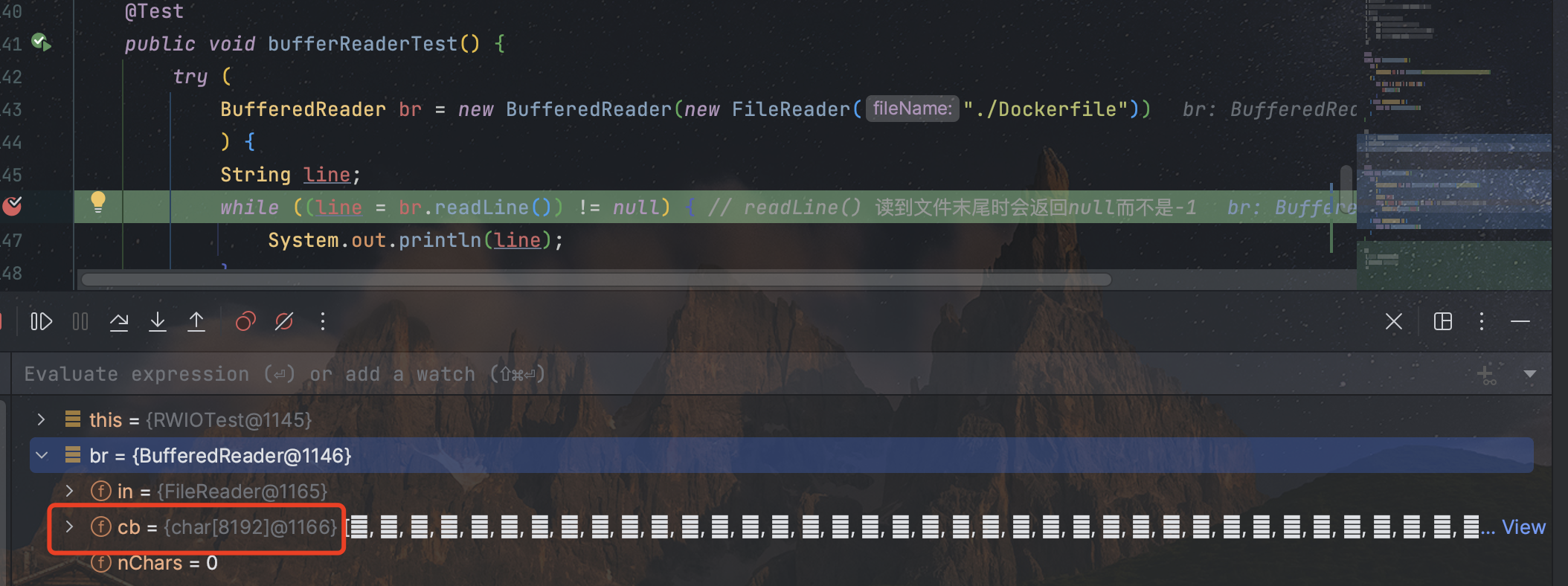
@Test
public void bufferReaderTest() {try (BufferedReader br = new BufferedReader(new FileReader("./Dockerfile"))) {String line;while ((line = br.readLine()) != null) { // readLine() 读到文件末尾时会返回null而不是-1System.out.println(line);}} catch (IOException e) {throw new RuntimeException(e);}
}@Test
public void bufferWriterTest() {try (BufferedWriter bw = new BufferedWriter(new FileWriter("./src/test/java/com/shadowy/io/bufferWriterTest.txt"))) {bw.write("myheavyhead");bw.newLine();bw.write("我的头好重");bw.newLine();bw.write("bye~");} catch (IOException e) {throw new RuntimeException(e);}
}
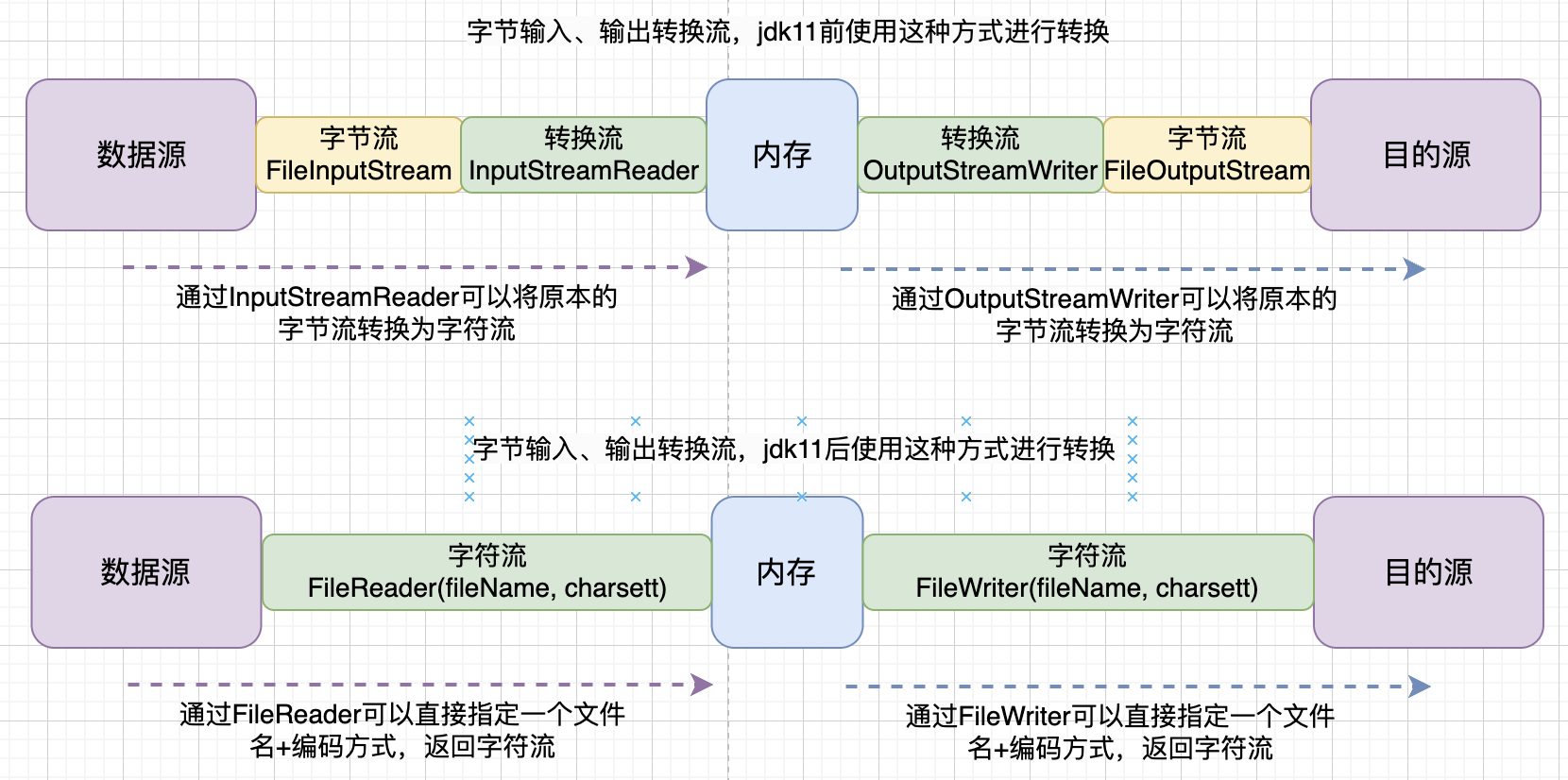
五,转换流
转换流是字符流与字节流之间的桥梁。字节流可以读取任意类型的文件但无法指定编码,字符流可以指定编码并且字符缓冲流还有着readLine()、newLine()这两个强大的方法,二者各有优势,但我们有时候只能拿到一个字节流,却想使用字符流的能力,这个时候就需要用到转换流了。
- InputStreamReader:可以将字节流转换为字符流,语法:
new InputStreamReader(FileInputStream, Charset)传入一个字节输入流并指定编码。但这种方式在jdk11中被淘汰了,取而代之的是下面这种。- FileReader:jdk11中为FileReader新增了构造方法,可以直接返回一个指定字符集的字符流,其实底层和jdk8一样会做一次转换,语法:
FileReader(String fileName, Charset charset)传入一个文件路径并指定编码。
- FileReader:jdk11中为FileReader新增了构造方法,可以直接返回一个指定字符集的字符流,其实底层和jdk8一样会做一次转换,语法:
- OutputStreamWriter:可以将字节流转换为字符流,语法:
new OutputStreamWriter(FileOutputStream, Charset)传入一个字节输出流并指定编码。但这种方式在jdk11中被淘汰了,取而代之的是下面这种。- FileWriter:jdk11中为FileWriter新增了构造方法,可以直接返回一个指定字符集的字符流,其实底层和jdk8一样会做一次转换,语法:
FileWriter(String fileName, Charset charset)传入一个文件路径并指定编码。
- FileWriter:jdk11中为FileWriter新增了构造方法,可以直接返回一个指定字符集的字符流,其实底层和jdk8一样会做一次转换,语法:
/* 使用转换流读取文件数据:* InputStreamReader 可以将字节流转换为字符流,这样字节流就拥有了字符流的能力(指定编码)* 但是这种方法在jdk11中被淘汰了,不推荐使用,取而代之的是下一个*/
@Test
public void convertISR() {try (InputStreamReader isr = new InputStreamReader(new FileInputStream("./Dockerfile"), "GBK")) {int ch;while ((ch = isr.read()) != -1) {System.out.print((char) ch);}} catch (IOException e) {throw new RuntimeException(e);}
}/* 使用转换流读取文件数据:* jdk11中新增FileReader 新的构造方法,可以直接返回一个指定字符集的字符流,而底层是FileInputStream字节流* public FileReader(String fileName, Charset charset) throws IOException {* super(new FileInputStream(fileName), charset);* }* 可能这样无法直观的看出其的作用,可以通俗理解为,字节流本身是没有字符集的,但我们可以通过字符流直接* 将一个无字符集的字节流转换为字符流,供我们使用。*/
@Test
public void convertISRNew() {try (FileReader fr =new FileReader("./Dockerfile", Charset.forName("GBK"))) {int ch;while ((ch = fr.read()) != -1) {System.out.print((char) ch);}} catch (IOException e) {throw new RuntimeException(e);}
}/* 使用转换流往文件中写数据:* OutputStreamWriter 可以将字节流FileOutputStream转换为字符流,这样原本的字节流也有了字符流的能力(自定义编码)* 但这种方式在jdk11中被取代了,有了更简便的方法*/
@Test
public void convertOSW() {try (OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("./src/test/java/com/shadowy/io/convertOSW.txt"), Charset.forName("GBK"))) {osw.write("hello 头好重");} catch (IOException e) {throw new RuntimeException(e);}
}/* 使用转换流往文件中写数据:* jdk11中新增FileWriter 新的构造方法,可以直接返回一个指定字符集的字符流,而底层是FileOutputStream字节流* public FileWriter(String fileName, Charset charset) throws IOException {* super(new FileOutputStream(fileName), charset);* }* 可能这样无法直观的看出其的作用,可以通俗理解为,字节流本身是没有字符集的,但我们可以通过字符流直接* 将一个无字符集的字节流转换为字符流,供我们使用。*/
@Test
public void convertOSWNew() {try (FileWriter osw = new FileWriter("./src/test/java/com/shadowy/io/convertOSWNew.txt",Charset.forName("GBK"))) {osw.write("hello again 头好重");} catch (IOException e) {throw new RuntimeException(e);}
}/* 将本地刚写出的conberOSW文件(字符集为GBK),转换为UTF-8* 要求使用旧方法*/
@Test
public void convertCharset() {try (// 先用GBK读取数据InputStreamReader isr = new InputStreamReader(new FileInputStream("./src/test/java/com/shadowy/io/convertOSW.txt"), Charset.forName("GBK"));// 再用UTF-8存储数据OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("./src/test/java/com/shadowy/io/convertOSW_2.txt"), StandardCharsets.UTF_8)) {char[] chars = new char[1024];int len;while ((len = isr.read(chars)) != -1) {osw.write(chars, 0, len);}} catch (IOException e) {throw new RuntimeException(e);}
}/* 将本地刚写出的convertOSWNew文件(字符集为GBK),转换为UTF-8* 要求使用新方法*/
@Test
public void convertCharsetNew() {try (FileReader fr = new FileReader("./src/test/java/com/shadowy/io/convertOSWNew.txt",Charset.forName("GBK"));FileWriter fw = new FileWriter("./src/test/java/com/shadowy/io/convertOSWNew2.txt",StandardCharsets.UTF_8)) {char[] chars = new char[1024];int len;while ((len = fr.read(chars)) != -1) {fw.write(chars, 0, len);}} catch (IOException e) {throw new RuntimeException(e);}
}
六,序列化流
序列化流可以将Java对象保存至本地文件中,这个过程我们称之为(正)序列化,从本地文件中将Java对象读取出来,这个过程我们称之为反序列化。
- 序列化流ObjectOutputStream,可以将java对象序列化然后保存至本地文件中;
- 反序列化流ObjectInputStream,可以将序列化到本地文件中的对象,反序列化读取到程序中来。

Java对象如果想实现序列化,需要实现Serializable接口,否则会出现java.io.NotSerializableException,用ObjectOutputStream进行序列化示例代码如下:
// JavaBean
public class Dish implements Serializable {@Serialprivate static final long serialVersionUID = 2932977146505342394L;@NotNullprivate transient String id;...
}// 序列化方法
@Test
public void objectWriteTest() {try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("./src/test/java/com/shadowy/io/ObjectIOTest.txt"))) {Dish dish = Dish.builder().id("123").status(1).build();oos.writeObject(dish);} catch (IOException e) {throw new RuntimeException(e);}
}
关键字解释:
- serialVersionUID:类如果实现了Serializable接口,那么就表示该类可以被序列化,Java会根据这个类的成员变量、静态变量、构造方法、成员方法进行计算得到一个long类型的序列号,类似与这个类的版本号,如果序列化之后再去修改类,那么原来的文件反序列化时会报错,因为版本号不一样了。不过可以手动定义类的版本号,这样可以修改类的字段与方法,但此时就不能再修改UID了。
- transient:瞬态关键字,被这个关键字修饰的字段,在序列化时不会将此字段的值序列化到文件中,但是字段还是会存在,只会给予一个初始默认值。
我们可以随时对本地文件进行反序列化,以得到我们想要的对象数据,不过反序列化出来的对象类型默认是Object,需要自己去处理类型转换,用ObjectInputStream进行反序列化示例代码如下:
@Test
public void objectReadTest() {try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("./src/test/java/com/shadowy/io/ObjectIOTest.txt"))) {Dish dish = (Dish) ois.readObject();System.out.println(dish);} catch (IOException | ClassNotFoundException e) {throw new RuntimeException(e);}
}

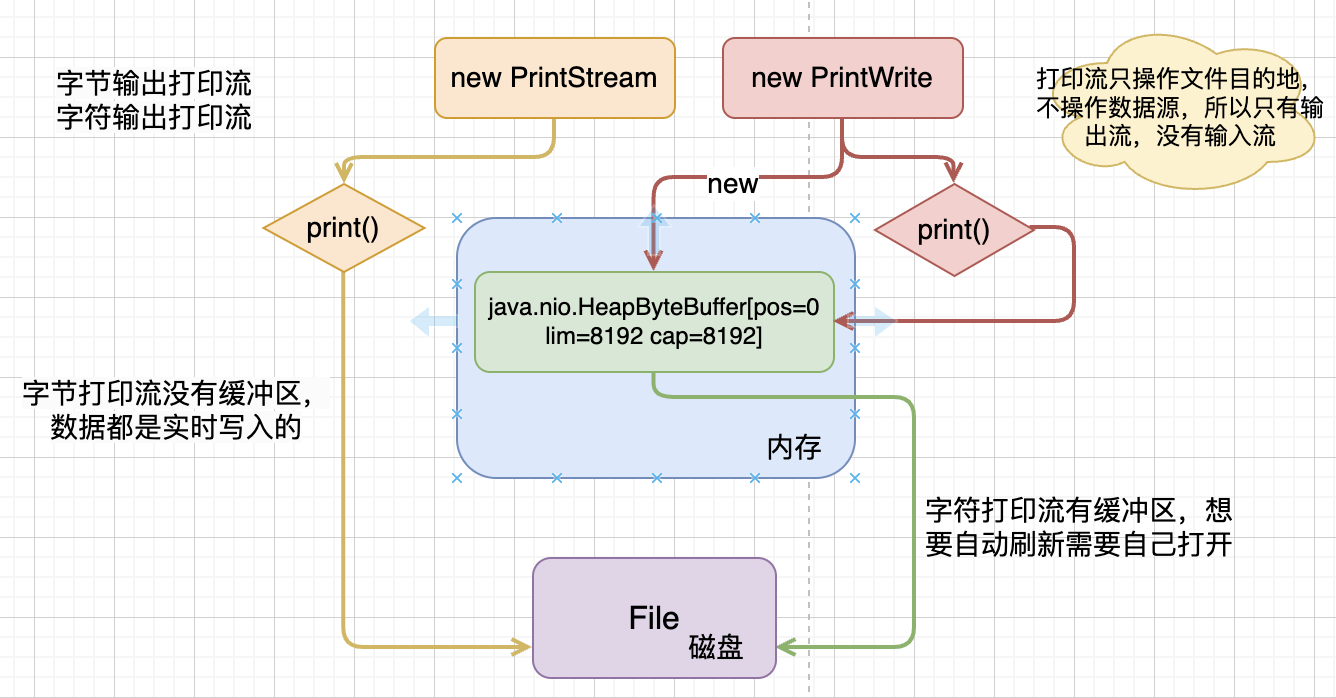
七、打印流
打印流,可以将数据直接输出到本地文件中,Java中的System.out就是获取一个内置的打印流,此打印流在虚拟机启动的时候会由虚拟机创建,默认指向控制台。打印流的输出语句就是print、println这类函数:
- PrintStream:字节输出打印流,没有缓冲区,数据都是直接写入到本地文件中的;
- PrintWrite:字符输出打印流,继承了字符流的能力,有缓冲区,如果想要实时刷新需要自己打开开关。
@Test
public void printStreamTest() {try (PrintStream ps = new PrintStream(new FileOutputStream("./src/test/java/com/shadowy/io/printStreamTest.txt"), true, StandardCharsets.UTF_8)) {// 往文件中写入数据,写操作类似于 System.out.printlnps.println(97); // 写出数据+自动刷新+换行ps.print(true);ps.print("我的头好重");} catch (FileNotFoundException e) {throw new RuntimeException(e);}
}@Test
public void printWriter() {try (PrintWriter pw = new PrintWriter(new FileWriter("./src/test/java/com/shadowy/io/printStreamTest.txt"), true)) {pw.println(97); // 写出数据+自动刷新+换行pw.print(true);pw.print("我的头好重");} catch (IOException e) {throw new RuntimeException(e);}
}
八、压缩流
压缩流可以操作压缩包将其解压或者操作本地文件将其添加到某个压缩包中。
-
ZipInputStream:字节压缩输入流,从压缩包中读取内容的方法
zis.getNextEntry(),返回值是ZipEntry,无文件可读时返回null;private void unzip(File src, File dest) {// 解压的本质:把压缩包里面的每个文件或者文件夹读取出来,按照层级拷贝至目的地当中// 创建一个解压缩路用来读取压缩包中的数据try (ZipInputStream zis = new ZipInputStream(new FileInputStream(src));) {ZipEntry zipEntry;// 获取压缩包中的每一个zipEntry对象while ((zipEntry = zis.getNextEntry()) != null) {if (zipEntry.isDirectory()) {// 如果是文件夹则需要再目的地dest处同时创建一个同样的文件夹File file = new File(dest, zipEntry.toString());file.mkdirs();} else {FileOutputStream fos = new FileOutputStream(new File(dest, zipEntry.toString()));// 如果是文件,需要读取压缩包中的文件,并将其复制一份到dest目的地文件夹中int b;while ((b = zis.read()) != -1) {fos.write(b);}fos.close();}}} catch (IOException e) {throw new RuntimeException(e);} } -
ZipOutputStream:字节压缩输出流,往压缩包中添加文件,前提是在压缩包中新增
ZipEntry对象。private void toZip(File src, File dest) {// 压缩的本质:把目的文件读取出来,拷贝至压缩文件中try (// 1. 创建压缩流来关联压缩包文件ZipOutputStream zos = new ZipOutputStream(new FileOutputStream(new File(dest, "newZip.zip")));// 2. 创建ZipEntry对象,用来表示压缩包里面的每个文件和文件夹FileInputStream fis = new FileInputStream(src)) {// 3. 把ZipEntry对象放入压缩包中ZipEntry entry = new ZipEntry("魄罗开心.jpeg");zos.putNextEntry(entry);// 4. 把源原件数据写入到压缩包中去int b;while ((b = fis.read()) != -1) {zos.write(b);}} catch (IOException e) {throw new RuntimeException(e);} }
九,总结
Java 中的 IO 流主要包括字节流和字符流两种,字节流主要用于处理二进制数据,字符流主要用于处理文本数据。推荐使用commons-io或Hutool-io第三方工具类。