尝试全流程用paddlepaddle做AI安全管理 安全帽识别

尝试全流程用paddlepaddle做完一个项目,项目基于paddledetection套件,主要应用于装配式工厂以及工地的安全管理及使用摄像头推流的模式进行是否佩戴安全帽的识别,抽烟,识别。
选择飞浆主要是因为飞浆可以白嫖算力,初步选择的是yolov8的模型,考虑到后期的优化加速v5可能会比较好用v5也会训练一个。
首先是数据的处理,安全帽的数据主要来自于GitHub和飞浆的公开数据集这个还是不错的,这种常规的数据集相对比较多也很全,最主要下载速度很快。后期会把整理好的数据集也公开在飞浆的数据大厅。
数据集链接:
数据及整理:

其中annitation里面一共有25951个文件 ,jpegimages里面有26234个文件,因为是把搜集到的数据粗略的放到一起,造成了数据和标注匹配不上。顺便从网上找个脚本(00.py)查看一下标注情况。
import os
import xml.dom.minidomxml_path = '.\\Annotations\\\\'
files = os.listdir(xml_path)gt_dict = {}if __name__ == '__main__':for xm in files:xmlfile = xml_path + xmdom = xml.dom.minidom.parse(xmlfile) # 读取xml文档root = dom.documentElement # 得到文档元素对象filenamelist = root.getElementsByTagName("filename")filename = filenamelist[0].childNodes[0].dataobjectlist = root.getElementsByTagName("object")##for objects in objectlist:namelist = objects.getElementsByTagName("name")objectname = namelist[0].childNodes[0].dataif objectname == '-':print(filename)if objectname in gt_dict:gt_dict[objectname] += 1else:gt_dict[objectname] = 1# for nl in namelist:# objectname = nl.childNodes[0].data# if objectname in gt_dict:# gt_dict[objectname] += 1# else:# gt_dict[objectname] = 1dic = sorted(gt_dict.items(), key=lambda d: d[1], reverse=True)print(dic)print("总类别",len(dic))输出结果不出所料同一种类比标注不统一:
[('person', 115976), ('hat', 21791), ('helmet', 18966), ("['Wear_helmet']", 13095), ('P', 8163), ('head', 5785), ('PH', 5174), ('PHV', 3735), ("['No_helmet']", 3173), ('PLC', 2403), ('PV', 2304), ('dog', 3), ('cavity', 1)]
总类别 13首先就是统一标签格式主要分为这三类person、helmet、head
这时候就出现一个问题 一些数据集只有 安全帽是否佩戴 没有人体 比如这种:

当然有很多种思路解决这个样本的问题 我这算是比较工程一些的做法
这里介绍一个大佬的开源自动标注工具 https://github.com/cnyvfang/labelGo-Yolov5AutoLabelImg
可以用这个工具重新自动标注一下顺便微调一下也可以
统一标签命名,打开标注软件大概过一下具体标注,毕竟数据集良莠不齐甚至都能出现dog这种完全不好猜测的。
此时发现里面混入了大量反光衣数据集,且带有安全帽:

思虑再三,决定把它们放到反光衣数据集里面毕竟安全帽的数据已经够多,而且安全检测主要是针对不佩戴安全帽的检测。后期可能会把安全帽&人体,反光衣,吸烟,烟火分别训练一个模型以便于灵活部署。然后再用训练好的模型上面这种重新标注一遍再把所有数据放到一起训练一次。结合精度、效率、推理设备性能综合考量怎么部署。
把数据清理后重新执行一下 统计功能
[('hat', 21791), ('helmet', 18966), ("['Wear_helmet']", 13095), ('P', 6147), ('person', 5969), ('head', 5785), ("['No_helmet']", 3173), ('PH', 17), ('dog', 3), ('PHV', 2)]需要更改的
['hat']\\['Wear_helmet']=>helmet
['No_helmet']=>head
['p']=>person
('PH', 17), ('dog', 3), ('PHV', 2)]直接删除掉。
接下来就是训练的步骤 这里是使用的飞浆的AIstudio平台
数据集也可以从这里直接下载,可以的话请各位给个小赞:
https://aistudio.baidu.com/aistudio/datasetdetail/204978
然后就是飞浆的paddledetection
有很多选择,首先选用的是ppyoloe
https://gitee.com/paddlepaddle/PaddleDetection/tree/release/2.6/configs/ppyoloe
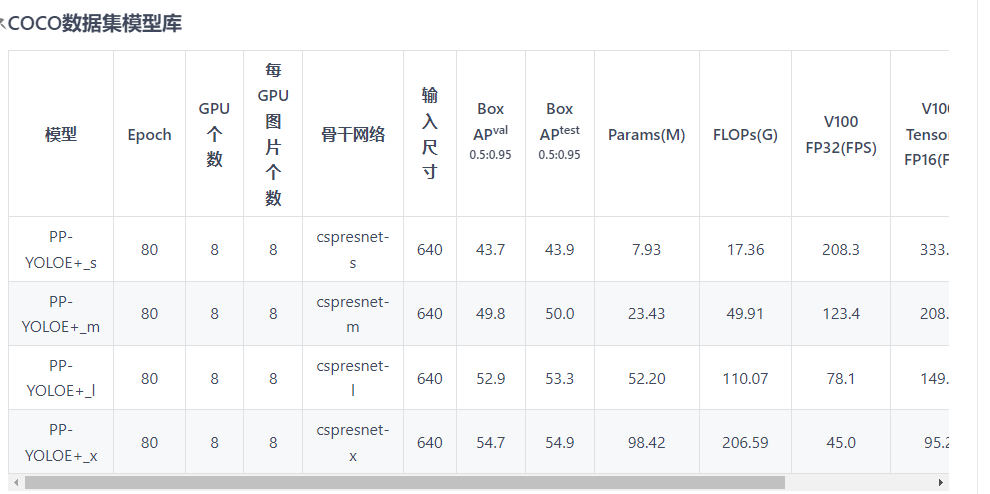
PP-YOLOE是基于PP-YOLOv2的卓越的单阶段Anchor-free模型,超越了多种流行的YOLO模型。PP-YOLOE有一系列的模型,即s/m/l/x
PP-YOLOE+_l在COCO test-dev2017达到了53.3的mAP, 同时其速度在Tesla V100上达到了78.1 FPS。
Tiny模型
|
模型 |
Epoch |
GPU个数 |
每GPU图片个数 |
骨干网络 |
输入尺寸 |
Box APval 0.5:0.95 |
Box APtest 0.5:0.95 |
Params(M) |
FLOPs(G) |
T4 TensorRT FP16(FPS) |
模型下载 |
配置文件 |
|
PP-YOLOE+_t-aux(640) |
300 |
8 |
8 |
cspresnet-t |
640 |
39.9 |
56.6 |
4.85 |
19.15 |
344.8 |
model |
config |
|
PP-YOLOE+_t-aux(640)-relu |
300 |
8 |
8 |
cspresnet-t |
640 |
36.4 |
53.0 |
3.60 |
12.17 |
476.2 |
model |
config |
|
PP-YOLOE+_t-aux(320) |
300 |
8 |
8 |
cspresnet-t |
320 |
33.3 |
48.5 |
4.85 |
4.80 |
729.9 |
model |
config |
|
PP-YOLOE+_t-aux(320)-relu |
300 |
8 |
8 |
cspresnet-t |
320 |
30.1 |
44.7 |
3.60 |
3.04 |
984.8 |
model |
config |
先训练一个tiny版本 精度达不到的话 再考虑换一个模型或者微调一些参数
下期写用来详细训练的
项目已经公开 欢迎大家fork
项目地址:https://aistudio.baidu.com/aistudio/projectdetail/5861470