mit6.824-MapReduce概念及Lab1的实现

本文是我学习MIT 6.824 Lab1的笔记,主要内容是对于MapReduce的理解和Lab1的实现。
MapReduce框架
如果还没有接触过MapReduce,最好先阅读一下MapReduce论文,如果阅读英文论文对你来说有些困难,也可以阅读MapReduce论文译文。
MapReduce是什么
MapReduce是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。
它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
MapReduce能做什么
MapReduce的思想是“分而治之”,因此MapReduce尤其擅长处理大数据。
比如Google可以利用MapReduce框架处理大量的爬虫获取到的文档、网络请求日志等原始数据,获得倒排索引等衍生数据。
MapReduce由两个主要的过程构成,即“Map(映射)”和“Reduce(归约)”。
-
Mapper负责“分”,即把大量、复杂的任务分解为若干个“简单的任务”,其中“简单的任务”需要满足以下几点要求:- 数据规模相较于原任务要极大缩小
- 满足“就近计算原则”,即计算过程最好发生在存放需要计算数据的节点上
- 每个小任务之间几乎没有依赖关系,这些小任务可以并行计算
-
Reducer负责“汇总”,即把Mapper处理完的数据收集起来。
举一个简单的例子:
假如我们有1TB的英文文本数据,怎么才能统计出文本中每个不同的单词出现的次数呢?
当数据量很小的时候,我们很容易想到,只需要声明一个哈希表map,把每个单词出现的次数记录到map中就可以解决问题。但是现在文本的大小是以TB为单位,如果此时我们继续采取上述策略,在一台机器上运行,那么无论是在时间上还是在空间上都是不可行的。
此时,MapReduce就派上用场了。
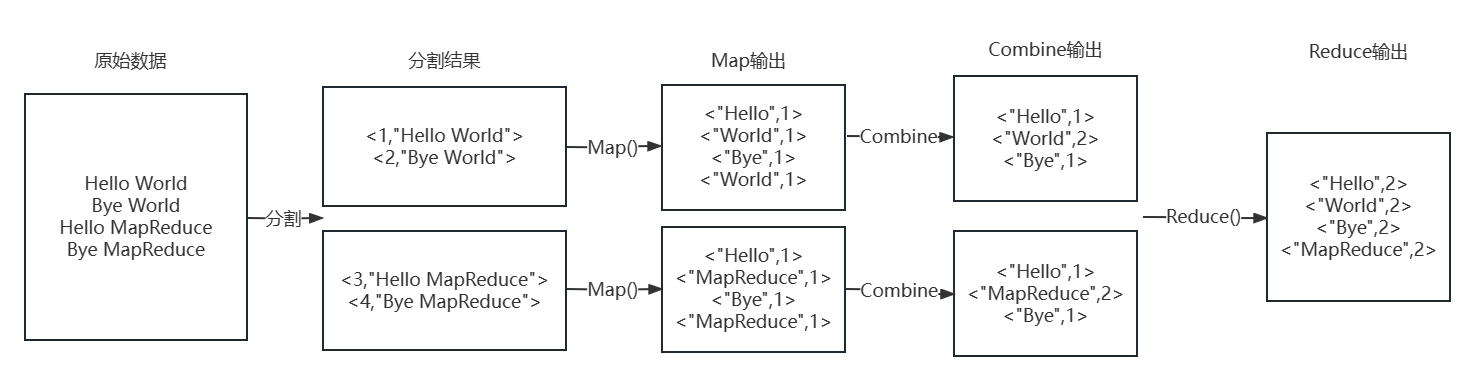
如上图,
- 在进行
MapReduce之前我们需要先把数据分割成若干份小数据,以便让它们在多台机器上并行运算,分割后的结果是<Key,Value>类型,其中Key可能有多种含义,在后续运算中一般不会用到,每一个Value是若干单词的集合。 - 分割完成后,在每一台机器上都会先进行
Map过程,Map方法会统计出输入数据中每个单词出现的次数,并以<Key,Value>形式展现,其中Key是单词,Value是该单词的出现次数,在本例中Value值都为1。 - 完成
Map过程后,有可能会有一个Combine聚合过程,该过程会把Key相同的几组数据聚合成一组。 - 最后是
Reduce过程,该过程会汇总所有机器Combine后的结果,并把Key相同的几组数据聚合成一组,最终得到原始数据中每个单词出现的次数。
MapReduce的工作机制
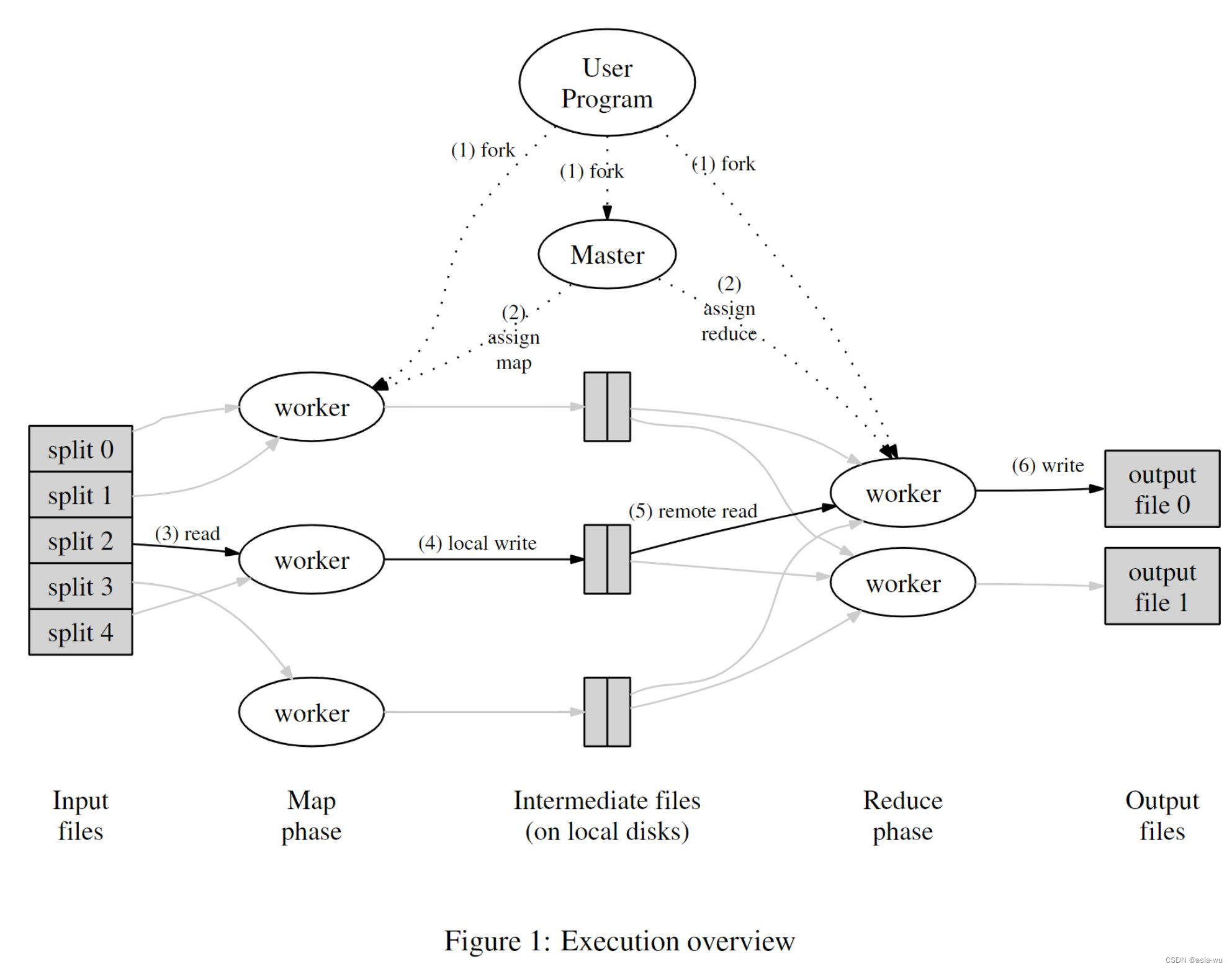
上图是论文中对于MapReduce流程的描述。
它主要包含以下四个角色:
User Program:用户程序,即客户端,用来提交MapReduce任务。Master:master进程用于分配任务,协调任务的进行。Map Worker:执行Map方法的进程。Reduce Worker:执行Reduce方法的进程。
输入数据以文件形式进入系统。在master进程的调整、分配下一些进程运行map任务,拆分了原任务,产生了一些中间体,这些中间体可能以键值对形式存在。另外一些进程运行了reduce任务,利用中间体产生最终输出。
Lab1: MapReduce
前言
Lab1的官方说明在Lab1 Note。- 在动手实现
Lab1之前,一定要先阅读MapReduce论文。 mit 6.824的所有Lab都是用GoLang来实现的,如果之前没有学习过Go语言,可以从以下途径中任选一条进行学习:-
Go 官方指南
-
Go语言编程快速入门
-
Go构建Web程序
-
- 这是初始实验的git仓库:
git://g.csail.mit.edu/6.824-golabs-2020 6.824,所有代码需要运行在Linux或Mac OS上。
总览
Lab1要求我们实现一个和MapReduce论文类似的机制,也就是数单词个数Word Count。
在正式开始写分布式代码之前,我们先理解一下任务和已有的代码。
输入文件在src/main中,文件名是pg-*.txt,其中每一个文件都是一本电子书,内容很多,我们的任务是统计出所有pg-*.txt文件中所有出现的单词以及它们的出现次数。
非分布式实现
在单机中,实现这个程序很简单,初始实验条件中已经给出了示例,在src/main/mrsequential.go中可以看到代码实现。
尝试在合适的系统中运行该示例:
cd src/main
go build -buildmode=plugin ../mrapps/wc.go
go run mrsequential.go wc.so pg*.txt
如果运行成功,输出结果将存在于src/main/mr-out-0文件中,里面展示了所有文章出现的所有单词以及它们的出现次数。
其中,go build -buildmode=plugin ../mrapps/wc.go将 wc.go 文件编译为一个插件模块,可以在运行时被其他代码加载和使用。wc.go中定义了名为Map和Reduce的函数,这两个函数在mrsequential.go被加载和调用。
go run mrsequential.go后面的两项是传入的命令行参数,可以在mrsequential.go中用os.Args获取到,第一个参数表示要加载的插件,第二个参数表示要统计单词次数的输入文件名。
mrsequential.go的代码比较容易理解,在此不再过多解释,在我的GitHub仓库中该代码有详细的中文注释,可以去查看以方便理解。
mrsequential.go的实现是非分布式的,但分布式下的代码和非分布式下的代码运行得到的结果应该是完全一样的,因此mr-out-0的内容将作为分布式下代码运行结果的评估标准的一部分。
分布式实现
我们要写的代码在src/mr中,src/mr中的代码将由src/main/mrmaster.go和src/main/mrworker.go调用,这两个代码的作用是启动进程、加载wc.so插件。
其中,前者需要运行一次以启动一个master进程,后者需要运行多次以启动多个worker进程。
master进程用于监听worker进程的RPC调用,并给它们分配合适的map/reduce任务,在此过程中master需要关注worker是否完成了任务,如果没有按时完成,需要将任务重新分配给其他worker。
worker进程启动后会主动请求master进程要任务,具体要到的是map还是reduce任务由master决定。
map方法传入文件名和文件内容,对文件内容进行处理,分割每一个单词,形成许多key-value键值对并作为结果返回,key是一个个单词,value的值都为 111 ,因为一个输入文件中可能有很多相同的单词,所以会出现很多相同的key。
reduce方法接收到的是同一个键(key)所对应的所有值(value)集合,而这些值(value)来自于不同的 map 任务,由于map返回的所有value都为 111 ,所以reduce只需要返回传入集合中数据的个数,这个值就是单词key在所有输入文件中出现的次数,合并所有reduce任务的返回结果就可以得到Word Count的结果。
运行过程:
go build -buildmode=plugin ../mrapps/wc.go
rm mr-out*
go run mrmaster.go pg-*.txt
# 运行一个或多个mrworker
go run mrworker.go wc.so
#将所有mr-out-*文件合并、排序后查看结果
cat mr-out-* | sort | more
Lab1的原始代码中已经提供了RPC的实现和调用示例,我们只需要按照示例写出发送的信息args、要接收的信息reply和远程调用的方法名(反射实现)。
我们最终的目标是通过src/main/test-mr.sh中的五个测试:
- 基本的
Word Count测试:先生成正确的输出,然后使用mrmaster和mrworker运行测试。如果输出结果与正确的结果相同,则测试通过。 indexer测试:先生成正确的输出,然后使用mrmaster和mrworker运行测试。如果输出结果与正确的结果相同,则测试通过。map并行度测试:在启动mrmaster和mrworker后,同时启动两个mtiming.so的worker,通过比较输出结果判断是否达到预期的并行度。reduce并行度测试:在启动mrmaster和mrworker后,同时启动两个rtiming.so的worker,通过比较输出结果判断是否达到预期的并行度。- 容错测试:在启动
mrmaster和crash.so worker后,它会不断重启crash.so worker直到完成任务。完成后,比较输出结果与正确结果是否相同。
仔细查看test-mr.sh中第一个测试部分的代码,其中有一行
sort mr-out* | grep . > mr-wc-all
意思是把所有mr-out-*文件合并并排序后存放在mr-wc-all中,之后再拿mr-wc-all和Word Count正确的结果对比。
因此,我们的任务不是像mrsequential.go一样生成最终的一个mr-out-0文件,而是生成多个mr-out-*文件,具体个数由mrmaster中传入的nReduce的值决定,即一个reduce任务最终生成一个mr-out-*文件,这就要求我们每个reduce任务处理的单词不能一样,即所有相同的单词都要被放到同一个reduce任务里执行。
Lab1 Note中已经给出了提示,每个map任务处理一个pg-*txt文件,一个map任务产生的中间文件应该命名为mr-X-Y,可能有多个,如mr-X-0、mr-X-1…
其中X为mapWorkerId,Y是由处理到的单词通过ihash方法联合nReduce决定的,表示把这个单词分给哪个reduce任务。因此,不同文件中相同的单词被分到的mr-*-Y文件Y的值一定相同,之后执行第i个reduce任务时只需要读取所有的mr-*-i文件并合并处理就可以实现所有相同的单词被同一个reduce任务处理的效果,最终经过reduce任务的处理,产生文件mr-out-i。
GoLand配置
如果在Ubuntu或Mac OS上用的IDE是GoLand,有以下几个配置可以简化运行时的操作:
-
因为每次更改
worker.go后,在运行测试前都要重新加载插件,所以可以把加载插件的语句放在一个sh脚本里,比如我代码里的src/main/wc-build.sh,里面其实只有一句:CGO_ENABLED=1 go build -race -buildmode=plugin ../mrapps/wc.go -
另外因为运行
mrmaster.go和mrworker.go需要传入命令行参数,所以可以在GoLang右上角"编辑配置"中进行如下配置:-
mrsequential.go: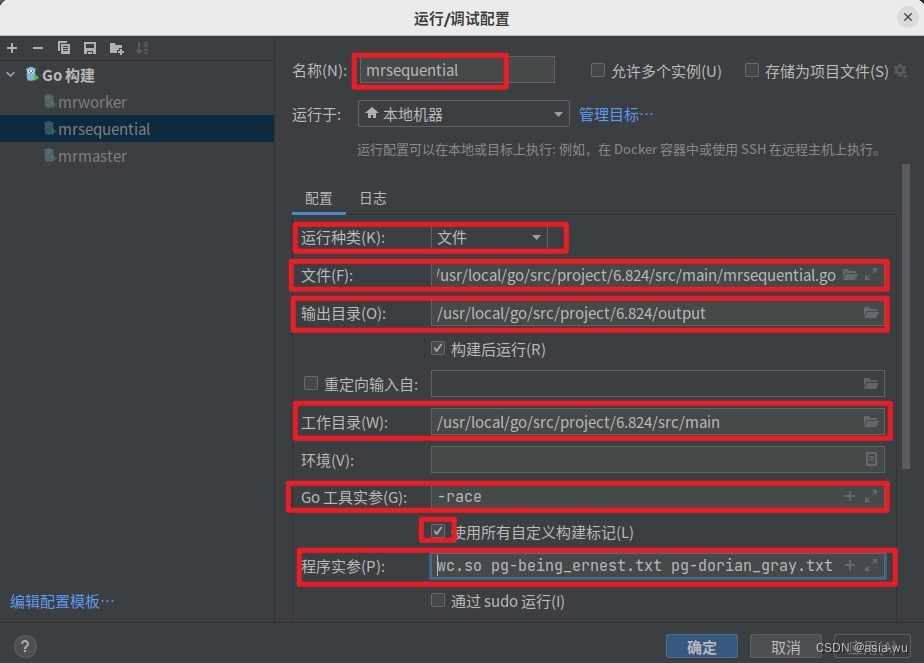
-
mrmaster.go: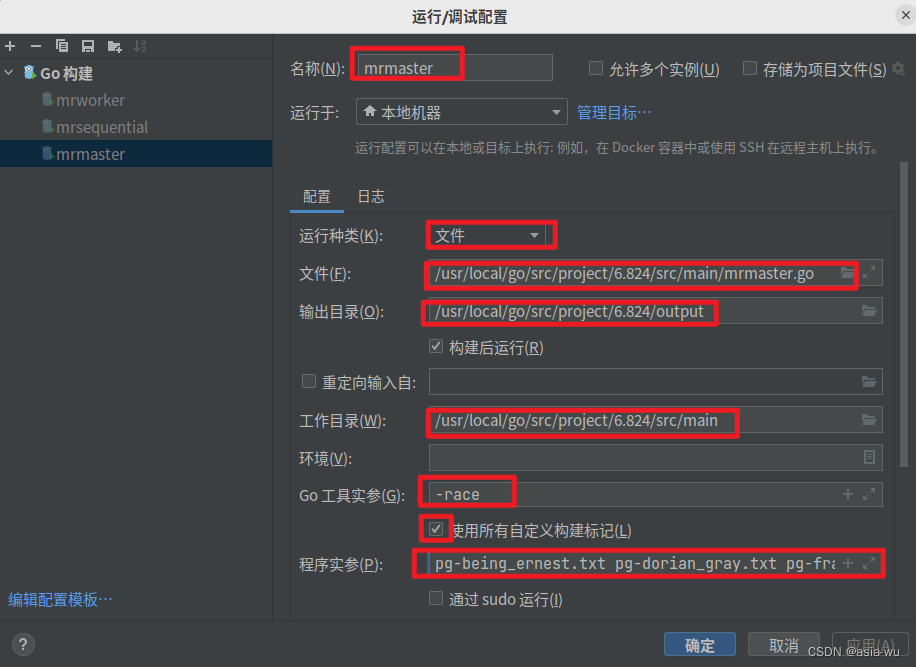
-
mrworker.go: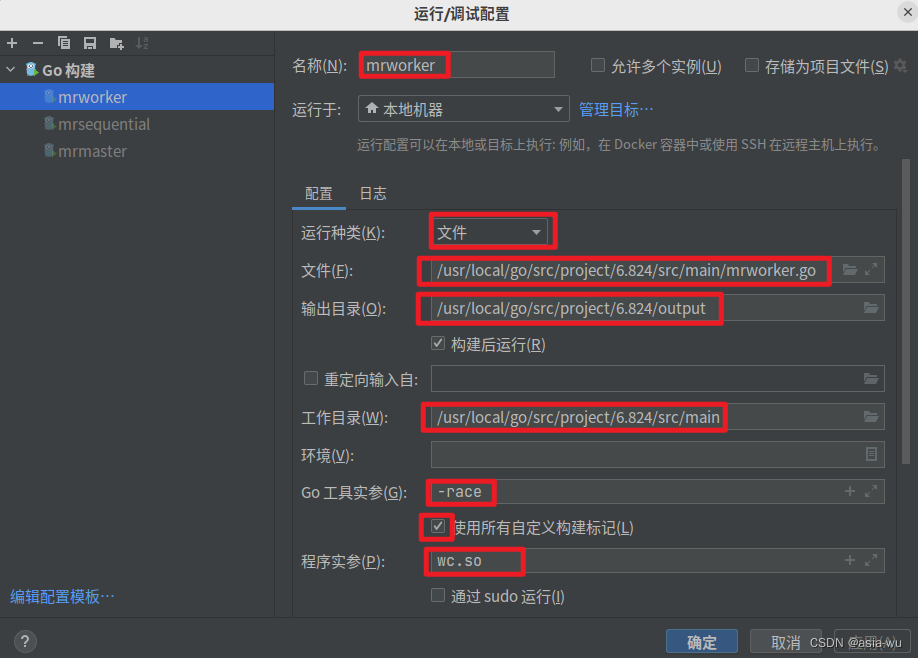
-
注意,因为GoLand的实参不支持通配符,所以在写文件名时不能写pg-*txt,要把所有文件的文件名都写上,具体如下:
pg-being_ernest.txt pg-dorian_gray.txt pg-frankenstein.txt pg-grimm.txt pg-huckleberry_finn.txt pg-metamorphosis.txt pg-sherlock_holmes.txt pg-tom_sawyer.txt
上面两项都配置好之后,就可以按如下顺序启动并测试程序:
- 运行
wc-build.sh - 运行
mrmaster.go - 运行
mr-worker.go
程序运行流程
因为所有代码加起来代码量很大,所以在这里不会展示具体的代码,只详细解释程序运行的流程,代码可以去GitHub仓库查看。
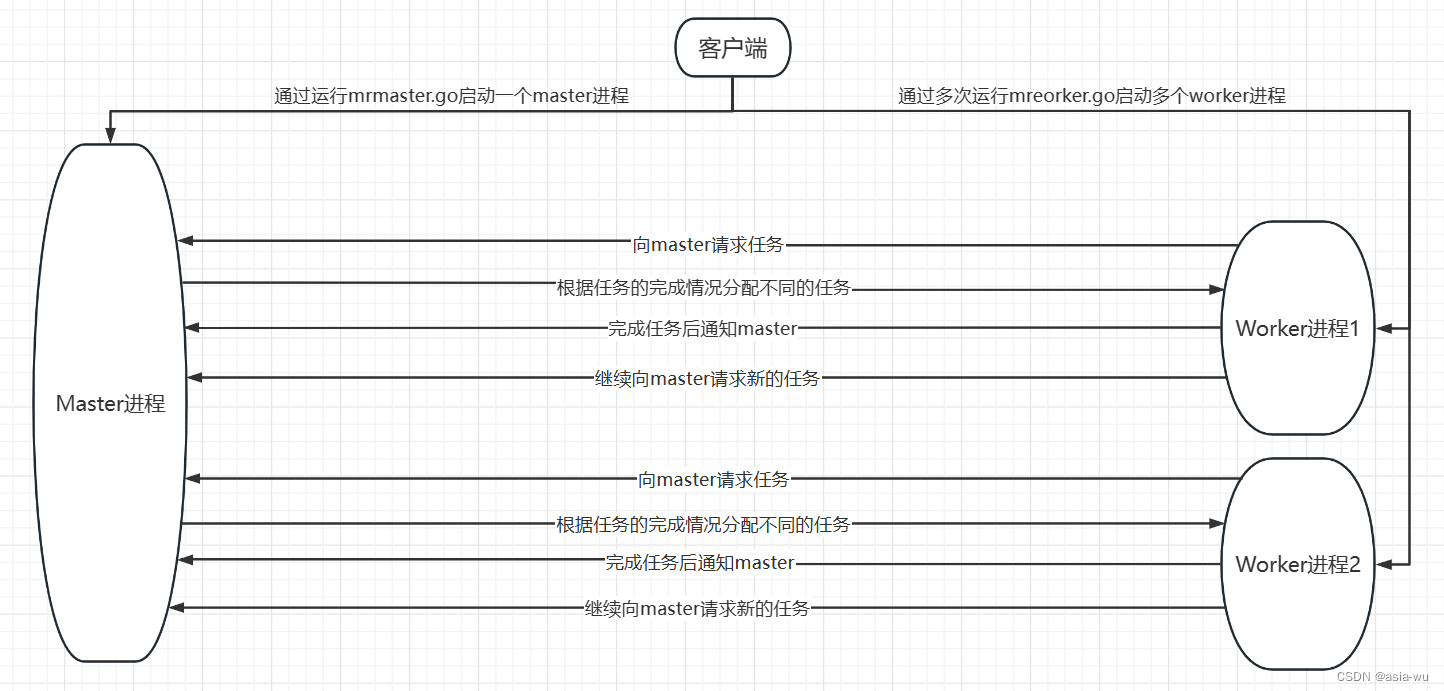
上图简要展示了程序运行的流程,具体流程如下:
-
客户端通过运行一次
mrmaster.go启动一个master进程,启动时,会进行以下操作:- 创建一个
Master结构体 - 根据命令行传入的文件生成所有
map任务并存放在Master的MapChannel中 - 开启一个新的线程不断循环判断有没有过期(分配出去但十秒内未完成)的
map和reduce任务 - 开始监听来自
worker的RPC调用
- 创建一个
-
客户端通过运行多次
mrworker.go启动多个worker进程,每个worker启动时,都会进行以下操作:- 创建一个
AWorker结构体 - 只要
master进程没有通知worker进程所有任务都已经完成,worker进程就一直向master进程要任务
- 创建一个
-
master接收到worker的要任务请求后,根据所有任务的完成情况给worker分配任务,分配规则是:所有map任务全部完成后才可以去分配reduce任务 -
当
worker要到任务后,worker会首先判断这个任务是map任务还是reduce任务,并根据任务类型执行不同的逻辑- 如果是
map任务,会执行doMap逻辑,全部执行完后会在/var/tmp目录下生成文件名为mr-X-Y的临时文件,其中X是当前mapWorker的ID,Y是通过ihash方法计算出来的 - 如果是
reduce任务,会执行doReduce逻辑,worker会从src/main中读取所有mr-*-Y文件,其中Y是当前reduceWorker的reduce任务的编号,最终会在/var/tmp目录下生成文件名为mr-out-Y的临时文件
- 如果是
-
worker执行完自己的任务后,会执行mapTaskDone或reduceTaskDone方法,告诉master自己的任务完成了,通知完之后会立马继续向master要新的任务 -
master在接收到worker完成任务的通知后,会先判断这个worker完成这个任务有没有超时,具体就是判断这个任务的状态是不是Running,如果是就没有超时;否则,如果状态是Ready,就说明该任务已经被master中的循环检测任务过期的线程判定为过期并设为Ready状态;如果状态是Finished,说明这个任务被判定为超时后又被分配给其他worker并被那个worker按时完成 -
如果
master判断worker在规定时间内完成了任务,则:worker执行的是map任务:master会调用generateMapFile方法,将worker在/var/tmp中生成的临时文件mr-X-Y复制到src/main中,作为正式的该map任务完成后产生的中间文件,表示master接受了该worker的成果worker执行的是reduce任务:master会调用generateReduceFile方法,将worker在/var/tmp中生成的临时文件mr-out-Y复制到src/main中,作为正式的该reduce任务完成后产生的最终文件,表示master接受了该worker的成果
-
当
master的MapChannel中存储的所有任务都被完成后,master会将任务分配阶段由MapPhase调整为ReducePhase,在这之后,master就会给来请求任务的worker分配reduce任务 -
当
master的ReduceChannel中存储的所有任务都被完成后,表示所有的map任务和reduce任务都已经完成,此时master会调用finish方法,准备终止master进程,并通知所有的master任务完成了,终止所有worker
注意事项
-
因为同一时间可能会有多个
worker请求同一个master,所以一定要注意master里共享变量的读写,在适当的地方加锁。 -
每次运行测试前一定要清空上一次测试生成的文件,防止对本次运行产生干扰。
-
多输出调试信息,可以用
fmt.Print*,也可以用log.Print*,在第一次输出正确的Word Count结果之前,输出越详细越好。 -
用于
RPC通信的结构体、变量名首字母要大写,否则会拿不到数据。
因为同一时间可能会有多个worker请求同一个master,所以一定要注意master里共享变量的读写,在适当的地方加锁。 -
每次运行测试前一定要清空上一次测试生成的文件,防止对本次运行产生干扰。
-
多输出调试信息,可以用
fmt.Print*,也可以用log.Print*,在第一次输出正确的Word Count结果之前,输出越详细越好。 -
用于
RPC通信的结构体、变量名首字母要大写,否则会拿不到数据。