ConvNeXt V2:与屏蔽自动编码器共同设计和缩放ConvNets,论文+代码+实战

ConvNeXt V2:与屏蔽自动编码器共同设计和缩放ConvNets,论文+代码+实战
自从Transformer模型在计算机视觉领域封神后,Facebook发表了ConvNeXt V1版本,证明了使用传统的卷积神经网络模型也能表现出优异的成绩,而ConvNeXt V2是对Transformer模型发起的又一新的挑战!
论文地址:
该论文的一句话总结:
本文利用MAE设计了全卷积掩码自编码器:FCMAE和新的全局响应归一化(GRN)层,并提出一个卷积主干新系列:ConvNeXt V2,它显著提高了纯ConvNet在各种视觉基准上的性能,最小的Atto版本仅有3.7M参数,而最大的Huge版本可高达88.9%准确率!
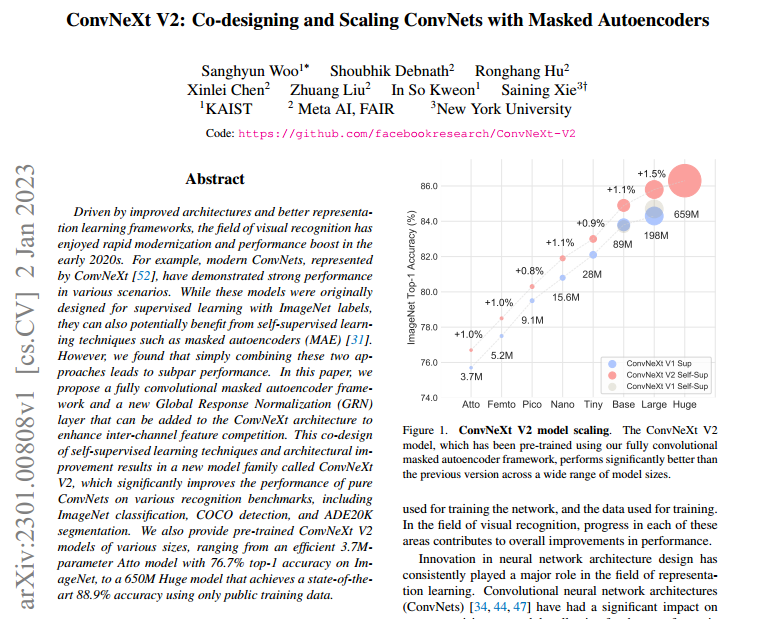
摘要:在2020年代初,随着改进的架构和更好的表示学习框架的出现,视觉识别领域经历了快速的现代化和性能提升。例如,现代的ConvNets,如ConvNeXt 在各种场景中展现出强大的性能。虽然这些模型最初是为带有ImageNet标签的监督学习而设计的,但它们也可能受益于自监督学习技术,如掩码自编码器(MAE)。然而,我们发现简单地将这两种方法组合起来会导致表现不佳。在本文中,我们提出了一个全卷积掩码自编码器框架和一个新的全局响应归一化(GRN)层,可以添加到ConvNeXt架构中,以增强通道之间的特征竞争。这种自监督学习技术和架构改进的共同设计,产生了一个名为ConvNeXt V2的新模型系列,它显著提高了纯ConvNets在各种识别基准测试中的性能,包括ImageNet分类、COCO检测和ADE20K分割。我们还提供了各种大小的预训练ConvNeXt V2模型,从高效的3.7M参数的Atto模型,其在ImageNet上拥有76.7%的top-1准确率,到650M的Huge模型,仅使用公共训练数据就实现了最先进的88.9%准确率。
1.全卷积掩码自编码器框架(FCMAE)
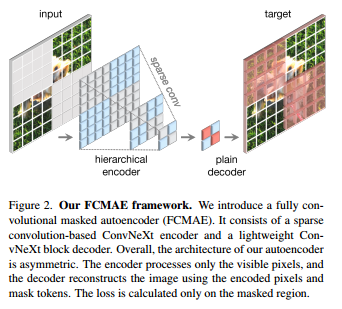
全卷积掩码自编码器框架(FCMAE)由一个基于稀疏卷积的ConvNeXt编码器和一个轻量级的ConvNeXt块解码器组成。总体而言,自动编码器的架构是不对称的。编码器只处理可见像素,解码器使用编码的像素和掩码标记重建图像。仅在遮罩区域上计算损失。
学习信号是通过以高掩蔽比随机掩蔽原始输入视觉效果并让模型在给定剩余上下文的情况下预测缺失部分来生成的。
掩蔽:使用了一种掩蔽比为0.6的随机掩蔽策略。由于卷积模型具有分层设计,其中在不同阶段对特征进行下采样,因此在最后阶段生成掩码,并递归地上采样,直到达到最佳分辨率。为了在实践中实现这一点,我们从原始输入图像中随机去除了60%的32×32个补丁。我们使用最小的数据扩充,只包括随机调整大小的裁剪。
编码器设计使用ConvNeXt模型作为方法中的编码器,但存在当掩蔽比高时,训练和测试时间不一致的问题,因此在预训练过程中,用子流形稀疏卷积转换编码器中的标准卷积层。
2.全局响应归一化(GRN)层
方法大脑中有许多促进神经元多样性的机制。例如,横向抑制可以帮助增强被激活神经元的反应,增加单个神经元对刺激的对比度和选择性,同时也可以增加神经元群体的反应多样性。在深度学习中,这种形式的横向抑制可以通过响应归一化来实现。在这项工作中,引入了一种新的响应归一化层,称为全局响应归一化(GRN),旨在提高通道的对比度和选择性。提出的GRN单元由三个步骤组成:1)全局特征聚合,2)特征归一化,和3)特征校准。
作者可视化了FCMAE预训练的ConvNeXt-Base模型的激活,并注意到一个有趣的“特征崩溃”现象:有许多停滞或饱和的特征图,并且激活在通道之间变得多余。这种行为主要在ConvNeXt区块中的尺寸扩展MLP层中观察到。

将每个特征通道的激活图可视化为小方块。为了清晰起见,在每个可视化中显示64个通道。可以看到,ConvNeXt V1模型存在特征崩溃问题,其特征是跨通道存在冗余激活(死亡或饱和神经元)。为了解决这个问题,作者引入了一种新的方法来提高训练过程中的特征多样性:全局响应归一化(GRN)层。该技术应用于每个块中的高维特征,从而开发了ConvNeXt V2架构。
3.ConvNeXt V2 Block
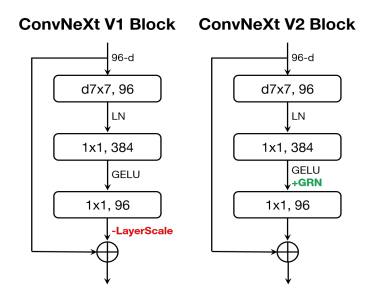
作者根据实验发现,当使用 GRN 时,LayerScale 不是必要的并且可以被删除。利用这种新的块设计,该研究创建了具有不同效率和容量的多种模型,并将其称为 ConvNeXt V2 模型族,模型范围从轻量级(Atto)到计算密集型(Huge)。
4.结果测试
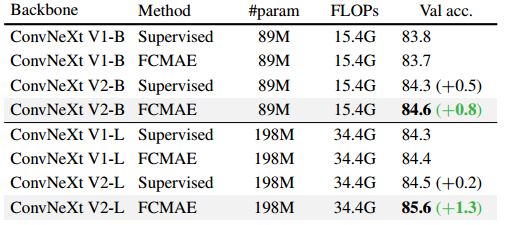
这张图展示了ConvNeXt重新设计的重要性。可以看到配备了FCMAE预训练的ConvNeXt V2巨型模型优于其他架构,在仅使用公共数据的方法中创下了88.9%的最新准确率。
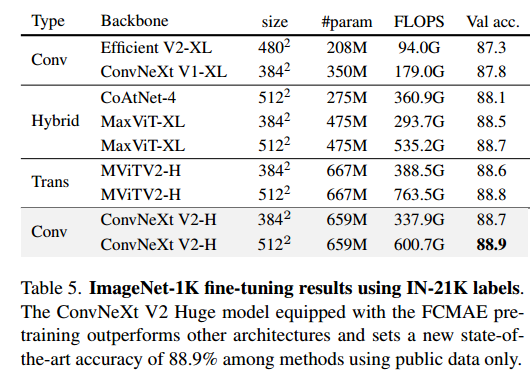
这张图展示了在ImageNet-1K使用IN-21K标签的微调结果。可以看到配备了FCMAE预训练的ConvNeXt V2巨型模型优于其他架构,在仅使用公共数据的方法中创下了88.9%的最新准确率。
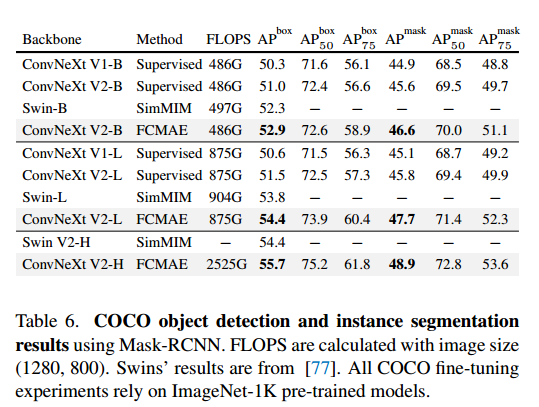
这张图展示了对迁移学习的表现进行基准测试,使用Mask RCNN的COCO对象检测和实例分割结果。FLOPS是用图像大小(1280800)来计算的。可以看到在FCMAE上预训练的ConvNeXt V2,在所有模型尺寸上都优于Swin transformer,在巨大的模型体系中实现了最大的差距。
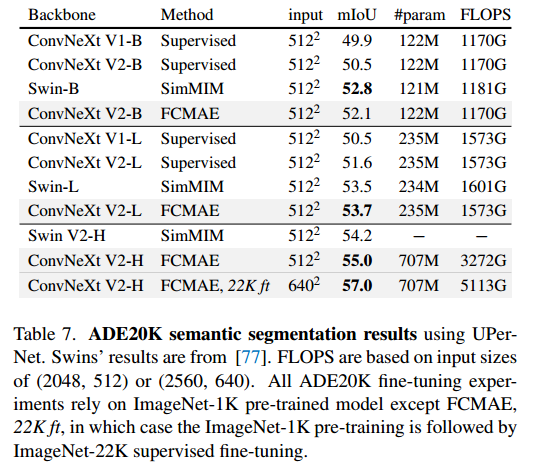
这张图展示了在ADE20K上的语义分割测试结果,结果显示出与目标检测实验类似的趋势,并且ConvNeXt V2最终模型比V1监督的模型显著改进。
5.代码
网络代码(pytorch实现):
# coding=gbkimport torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import trunc_normal_, DropPathclass Block(nn.Module):""" ConvNeXtV2 Block.Args:dim (int): Number of input channels.drop_path (float): Stochastic depth rate. Default: 0.0"""def __init__(self, dim, drop_path=0.):super().__init__()self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise convself.norm = LayerNorm(dim, eps=1e-6)self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layersself.act = nn.GELU()self.grn = GRN(4 * dim)self.pwconv2 = nn.Linear(4 * dim, dim)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()def forward(self, x):input = xx = self.dwconv(x)x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)x = self.norm(x)x = self.pwconv1(x)x = self.act(x)x = self.grn(x)x = self.pwconv2(x)x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)x = input + self.drop_path(x)return xclass LayerNorm(nn.Module):""" LayerNorm that supports two data formats: channels_last (default) or channels_first.The ordering of the dimensions in the inputs. channels_last corresponds to inputs withshape (batch_size, height, width, channels) while channels_first corresponds to inputswith shape (batch_size, channels, height, width)."""def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):super().__init__()self.weight = nn.Parameter(torch.ones(normalized_shape))self.bias = nn.Parameter(torch.zeros(normalized_shape))self.eps = epsself.data_format = data_formatif self.data_format not in ["channels_last", "channels_first"]:raise NotImplementedErrorself.normalized_shape = (normalized_shape,)def forward(self, x):if self.data_format == "channels_last":return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)elif self.data_format == "channels_first":u = x.mean(1, keepdim=True)s = (x - u).pow(2).mean(1, keepdim=True)x = (x - u) / torch.sqrt(s + self.eps)x = self.weight[:, None, None] * x + self.bias[:, None, None]return xclass GRN(nn.Module):""" GRN (Global Response Normalization) layer"""def __init__(self, dim):super().__init__()self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))def forward(self, x):Gx = torch.norm(x, p=2, dim=(1, 2), keepdim=True)Nx = Gx / (Gx.mean(dim=-1, keepdim=True) + 1e-6)return self.gamma * (x * Nx) + self.beta + xclass ConvNeXtV2(nn.Module):""" ConvNeXt V2Args:in_chans (int): Number of input image channels. Default: 3num_classes (int): Number of classes for classification head. Default: 1000depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]drop_path_rate (float): Stochastic depth rate. Default: 0.head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1."""def __init__(self, in_chans=3, num_classes=1000,depths=[3, 3, 9, 3], dims=[96, 192, 384, 768],drop_path_rate=0., head_init_scale=1.):super().__init__()self.depths = depthsself.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layersstem = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),LayerNorm(dims[0], eps=1e-6, data_format="channels_first"))self.downsample_layers.append(stem)for i in range(3):downsample_layer = nn.Sequential(LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),nn.Conv2d(dims[i], dims[i + 1], kernel_size=2, stride=2),)self.downsample_layers.append(downsample_layer)self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocksdp_rates = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]cur = 0for i in range(4):stage = nn.Sequential(*[Block(dim=dims[i], drop_path=dp_rates[cur + j]) for j in range(depths[i])])self.stages.append(stage)cur += depths[i]self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layerself.head = nn.Linear(dims[-1], num_classes)self.apply(self._init_weights)self.head.weight.data.mul_(head_init_scale)self.head.bias.data.mul_(head_init_scale)def _init_weights(self, m):if isinstance(m, (nn.Conv2d, nn.Linear)):trunc_normal_(m.weight, std=.02)nn.init.constant_(m.bias, 0)def forward_features(self, x):for i in range(4):x = self.downsample_layers[i](x)x = self.stages[i](x)return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)def forward(self, x):x = self.forward_features(x)print(x.size())x = self.head(x)return xdef convnextv2_atto(num_classes=100, kwargs):model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[40, 80, 160, 320], num_classes=num_classes, kwargs)return modeldef convnextv2_femto(num_classes=100, kwargs):model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[48, 96, 192, 384], num_classes=num_classes, kwargs)return modeldef convnext_pico(num_classes=100, kwargs):model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[64, 128, 256, 512], num_classes=num_classes, kwargs)return modeldef convnextv2_nano(num_classes=100, kwargs):model = ConvNeXtV2(depths=[2, 2, 8, 2], dims=[80, 160, 320, 640], num_classes=num_classes, kwargs)return modeldef convnextv2_tiny(num_classes=100, kwargs):model = ConvNeXtV2(depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], num_classes=num_classes, kwargs)return modeldef convnextv2_base(num_classes=100, kwargs):model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[128, 256, 512, 1024], num_classes=num_classes, kwargs)return modeldef convnextv2_large(num_classes=100, kwargs):model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[192, 384, 768, 1536], num_classes=num_classes, kwargs)return modeldef convnextv2_huge(num_classes=100, kwargs):model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[352, 704, 1408, 2816], num_classes=num_classes, kwargs)return modelif __name__ == "__main__":m = convnextv2_atto(num_classes=3)params = sum(p.numel() for p in m.parameters())print(params)input = torch.randn(1, 3, 256, 256)out = m(input)print(out.shape)训练代码:
import sysimport torch
from torch import nn
from net import MyGoogLeNet
import numpy as np
from torch.optim import lr_scheduler
import os
from tqdm import tqdmfrom torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoaderimport matplotlib.pyplot as pltdef main():# 解决中文显示问题# plt.rcParams['font.sans-serif'] = ['SimHei']# plt.rcParams['axes.unicode_minus'] = FalseROOT_TRAIN = r'D:/other/ClassicalModel/data/flower_data'ROOT_TEST = r'D:/other/ClassicalModel/data/flower_data'# 创建定义文件夹以及文件filename = 'record.txt'save_path = 'runs'path_num = 1while os.path.exists(save_path + f'{path_num}'):path_num += 1os.mkdir(save_path + f'{path_num}')os.mkdir(save_path + f'{path_num}/save_model')f = open(save_path + f'{path_num}/' + filename, 'w')save_path = save_path + f'{path_num}/save_model'# 将图像的像素值归一化到【-1, 1】之间normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])train_transform = transforms.Compose([transforms.Resize((224, 224)),#重调尺寸transforms.RandomVerticalFlip(),#随即裁剪transforms.ToTensor(),normalize])val_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),normalize])train_dataset = ImageFolder(ROOT_TRAIN, transform=train_transform)val_dataset = ImageFolder(ROOT_TEST, transform=val_transform)val_num = len(val_dataset)train_dataloader = DataLoader(train_dataset, batch_size=4, shuffle=True)val_dataloader = DataLoader(val_dataset, batch_size=4, shuffle=True)# 使用GPU加速device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")model = MyGoogLeNet(num_classes=5, aux_logits=True, init_weights=False).to(device)# 定义一个损失函数,交叉熵损失函数loss_function = nn.CrossEntropyLoss()# 定义一个优化器optimizer = torch.optim.SGD(model.parameters(), lr=0.005, momentum=0.9)epochs = 30best_acc = 0.0train_steps = len(train_dataloader)for epoch in range(epochs):# trainmodel.train()running_loss = 0.0train_bar = tqdm(train_dataloader, file=sys.stdout)for step, data in enumerate(train_bar):images, labels = dataoptimizer.zero_grad()logits, aux_logits2, aux_logits1 = model(images.to(device))loss0 = loss_function(logits, labels.to(device))loss1 = loss_function(aux_logits1, labels.to(device))loss2 = loss_function(aux_logits2, labels.to(device))loss = loss0 + loss1 * 0.3 + loss2 * 0.3loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)# validatemodel.eval()acc = 0.0 # accumulate accurate number / epochwith torch.no_grad():val_bar = tqdm(val_dataloader, file=sys.stdout)for val_data in val_bar:val_images, val_labels = val_dataoutputs = model(val_images.to(device)) # eval model only have last output layerpredict_y = torch.max(outputs, dim=1)[1]acc += torch.eq(predict_y, val_labels.to(device)).sum().item()val_accurate = acc / val_numprint('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch + 1, running_loss / train_steps, val_accurate))f.write('[epoch %d] train_loss: %.3f val_accuracy: %.3f\\n' %(epoch + 1, running_loss / train_steps, val_accurate))if val_accurate > best_acc:best_acc = val_accuratetorch.save(model.state_dict(), save_path+'/best_model.pth')# 保存最后一轮的权重文件if epoch == epochs - 1:torch.save(model.state_dict(), save_path + '/last_model.pth')f.close()print('Done!')
if __name__ == '__main__':main()
训练结果:
我们以3分类的马铃薯为例,convnextv2_atto仅有3.38M的参数,而准确率达到96.11%,相比上代95.23%确实有显著的提升。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R9DIgX7E-1680524869391)(ConfusionMatrix.jpg)]](https://img-blog.csdnimg.cn/7d23827a81054469b87185e3a0f6d14f.jpeg)
结论:ConvNeXt V2显著提高了纯ConvNet在各种视觉基准上的性能,在一定程度上超越了transformer!