机器学习-特征缩放

机器学习中, 特征值通常相差比较巨大, 不同维度的特征值相差巨大,导致部分特征影响微乎其微, 用来做训练效果不好。
举个例子, 工作年数和 工资收入作为特征值,来构建预测模型。
工作年数 一般比较小 1-10 , 工资收入 都是3000-100 0000 不等。 从数值来看, 年份和工资相比数值太小, 对整个模型的影响基本上可以忽略。
因此,我们需要对特征值进行缩放, 已规避数值差异带来的影响。
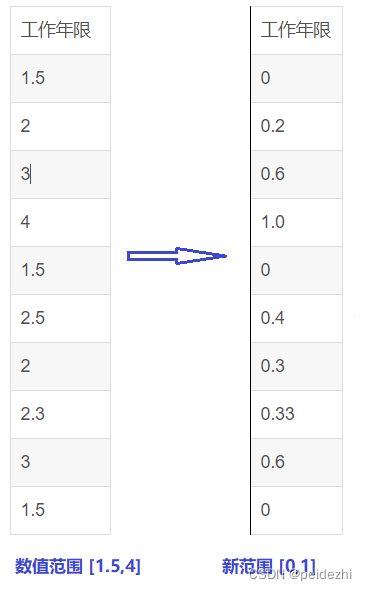
1 特征缩放:线性归一化 (min-max normalization)
Xnew = x - min(x)/ max(x)-min(x)
也称最大最小值归一化 。 计算公式如下。
2 标准差归一化 ( Z-score normalization)
Xnew = x - mean(x) / std(x) [均值 标准差】
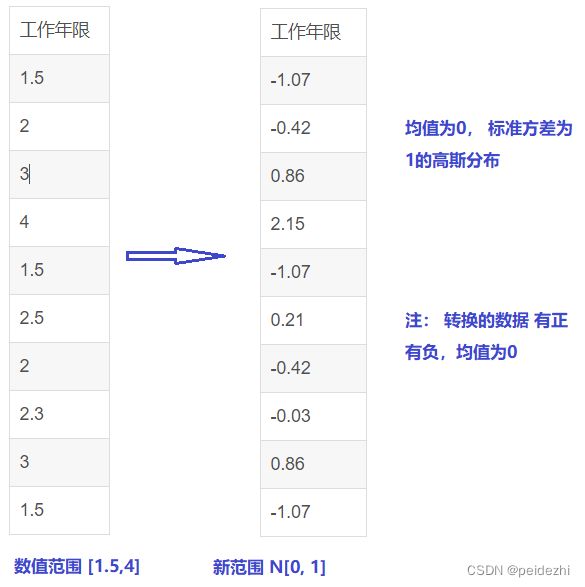

标准差std(x) = 方差的算术平方根 。(方差计算的是数据平方, 个体数据相差值会放大,所以开方求平方根可以缩小换算回来。 即标准差)
3 特征标准化方法选择。
具体哪一种 标准化方法比较好,依据实际效果来。
5 特征值离散化
一般在搭建机器学习分类模型时,需要对连续型的特征进行离散化,也就是分箱。
5.1 无监督分箱
1) 等距分箱
特征的取值范围等间隔分割,从最小值到最大值之间,均分N等份,如果最小值和最大值分 别为A、B,则每个区间的长度为W=(B-A)/N,则区间的边界为A+W,A+2W,A+3W,..., A+(N-1)W
该方法对异常值比较敏感,比如远大于正常范围的数值会影响区间的划分。
2)等频分箱
每个区间包含大致相等的实例数量。比如说 N=10 ,每个区间应该包含大约10%的实例。
5.2 有监督分箱
卡方分箱 、最优分箱等。
TODO
举例: 年龄特征 (21 22 23 21 24 25 22 23 25 24 21 26 28 30)
X<=22 ==> X = 1
22 < X <=24 ==> X =2
X > 24 ==> X =3
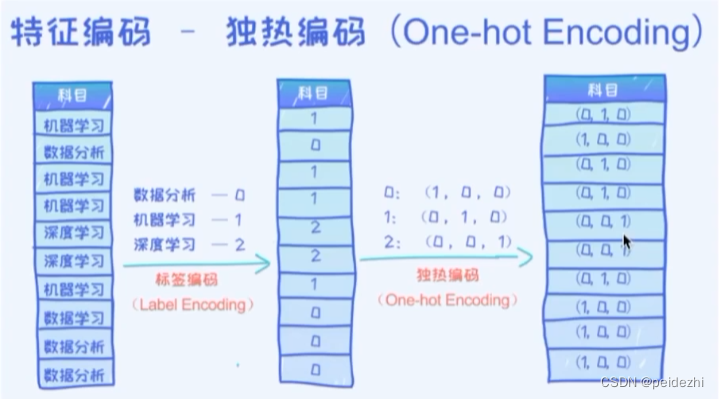
6 类别特征分类编码 one-hot编码
在机器学习中,我们常用到分类。比如 经典的 手写 1-9 数值分类识别。 如果分类特征 按, 1 ,2, 3 ...9来分类的话, 会把这些数值明显差异大小有别带入到模型中。 实际上 只是一个分类,没有大小。
针对类别特征的编码,常用的是 one-hot编码。
7 交叉验证与参数调优
一份数据集,我们一般取 80%作为训练集, 20%作为测试集。
但是,仅一次选择, 可能效果泛化不好,特别是20%跟训练集比较接近的时候。
因此, 为达到更好效果,我们经常使用交叉验证。
1)S-fold交叉验证。 即S折交叉验证
将数据集分成S份 (常用的是10折)。 以10折为例
取1份作为验证数据。 另外9份作为训练集。
取第2份作为验证数据。另外9份作为训练集。
......
取第10份作为验证数据。另外9份作为训练集。
将上述验证效果最好的参数模型,作为开发侧的输出,提交給测试团队进行下一步操作。