分布式系统唯一ID

目录
什么是分布式系统唯一ID
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。
如在金融、电商、支付、等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求,此时一个能够生成全局唯一ID的系统是非常必要的。
分布式系统唯一ID的特点
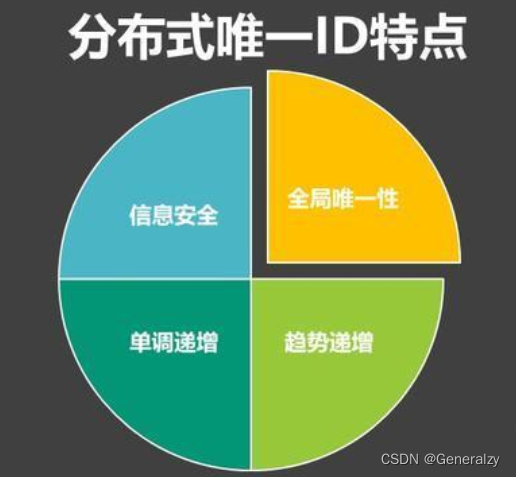
- 全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
- 趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
- 单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
- 信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
同时除了对ID号码自身的要求,业务还对ID号生成系统的可用性要求极高,想象一下,如果ID生成系统瘫痪,这就会带来一场灾难。
由此总结下一个ID生成系统应该做到如下几点:
- 平均延迟和TP999延迟都要尽可能低(TP90就是满足百分之九十的网络请求所需要的最低耗时。TP99就是满足百分之九十九的网络请求所需要的最低耗时。同理TP999就是满足千分之九百九十九的网络请求所需要的最低耗时);
- 可用性5个9(99.999%);
- 高QPS。
分布式系统唯一ID的实现方案

UUID
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:550e8400-e29b-41d4-a716-446655440000,到目前为止一共有5种方式生成UUID,详情见IETF发布的UUID规范 A Universally Unique IDentifier (UUID) URN Namespace。
优点:
性能非常高:本地生成,没有网络消耗。
缺点:
- 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
- ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用
数据库生成
以MySQL举例,利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增,每次业务使用下列SQL读写MySQL得到ID号。
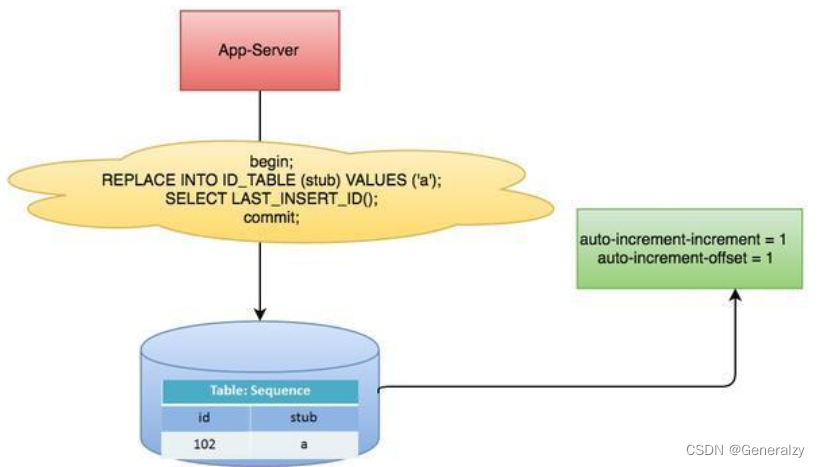
优点:
- 非常简单,利用现有数据库系统的功能实现,成本小,有DBA专业维护。
- ID号单调自增,可以实现一些对ID有特殊要求的业务。
缺点:
- 强依赖DB,当DB异常时整个系统不可用,属于致命问题。配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。
- ID发号性能瓶颈限制在单台MySQL的读写性能。
Redis生成ID
当使用数据库来生成ID性能不够要求的时候,可以尝试使用Redis来生成ID。
这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
2)需要编码和配置的工作量比较大。
利用zookeeper(分布式应用程序协调服务)生成唯一ID
zookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号。
很少会使用zookeeper来生成唯一ID。主要是由于需要依赖zookeeper,并且是多步调用API,如果在竞争较大的情况下,需要考虑使用分布式锁。因此,性能在高并发的分布式环境下,也不甚理想。
snowflake(雪花算法)方案
这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等。

雪花算法的原理就是生成一个的 64 位比特位的 long 类型的唯一 id。
- 最高 1 位固定值 0,因为生成的 id 是正整数,如果是 1 就是负数了。
- 接下来 41 位存储毫秒级时间戳,2^41/(1000606024365)=69,大概可以使用 69 年。
- 再接下 10 位存储机器码,包括 5 位 datacenterId 和 5 位 workerId。最多可以部署 2^10=1024 台机器。
- 最后 12 位存储序列号。同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成 2^12=4096 个不重复 id。
可以将雪花算法作为一个单独的服务进行部署,然后需要全局唯一 id 的系统,请求雪花算法服务获取 id 即可。
对于每一个雪花算法服务,需要先指定 10 位的机器码,这个根据自身业务进行设定即可。例如机房号+机器号,机器号+服务号,或者是其他可区别标识的 10 位比特位的整数值都行。
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
go简易实现
import ("errors""fmt""sync""time"
)const (// 时间戳的位数timeBits = 41// 机器ID的位数machineBits = 10// 序列号的位数sequenceBits = 12// 最大机器ID,1023maxMachineID = -1 ^ (-1 << machineBits)// 最大序列号,4095maxSequence = -1 ^ (-1 << sequenceBits)// 时间戳左移位数,机器ID占10位,序列号占12位,所以左移22位timeShift = machineBits + sequenceBits// 机器ID左移位数,序列号占12位,所以左移12位machineShift = sequenceBits
)type Snowflake struct {machineID int64 // 机器IDsequence int64 // 序列号lastTimestamp int64 // 上一次生成ID的时间戳mu sync.Mutex
}// NewSnowflake 创建一个新的Snowflake实例
func NewSnowflake(machineID int64) (*Snowflake, error) {if machineID < 0 || machineID > maxMachineID {return nil, errors.New("invalid machine ID")}return &Snowflake{machineID: machineID,sequence: 0,lastTimestamp: -1,}, nil
}// NextID 生成新的ID
func (sf *Snowflake) NextID() (int64, error) {sf.mu.Lock()defer sf.mu.Unlock()// 获取当前时间戳timestamp := time.Now().UnixNano() / int64(time.Millisecond)// 如果当前时间戳小于上一次生成ID的时间戳,说明系统时间发生了回退,这种情况下无法继续生成IDif timestamp < sf.lastTimestamp {return 0, errors.New("system clock moved backwards")}// 如果当前时间戳与上一次生成ID的时间戳相同,说明需要生成的ID数量已经达到了最大值,此时需要等待下一毫秒再生成IDif timestamp == sf.lastTimestamp {sf.sequence = (sf.sequence + 1) & maxSequenceif sf.sequence == 0 {timestamp = sf.waitNextMillis(timestamp)}} else {sf.sequence = 0}// 记录上一次生成ID的时间戳sf.lastTimestamp = timestamp// 生成新的IDid := (timestamp << timeShift) | (sf.machineID << machineShift) | sf.sequencereturn id, nil
}// 等待下一毫秒
func (sf *Snowflake) waitNextMillis(currentTimestamp int64) int64 {for {timestamp := time.Now().UnixNano() / int64(time.Millisecond)if timestamp > currentTimestamp {return timestamp}}
}
-1 的二进制表示为全 1 的二进制数,它与任何数进行异或运算,结果等于这个数的按位取反。所以,-1 ^ (-1 << machineBits) 的作用是生成 machineBits 位的二进制数,这个数的最高位为 0,其它位为 1,相当于是一个二进制位全为 1 的掩码。
例如,当 machineBits = 10 时,生成的掩码为 0b1111111111(十进制为 1023),这个掩码可以用来限制机器ID的范围,保证机器ID在 0 到 1023 之间。
使用掩码的方式,可以确保生成的数值只使用了指定位数的二进制位,并将其它位设置为 0,从而避免了可能出现的溢出和数据类型转换问题。
实际上,对于任意的非负整数 n,(1<<n)-1 都可以生成一个 n 位的二进制位全为 1 的掩码,这个掩码可以用于限制 n 位二进制数的范围。
因此,在使用生成二进制位全为 1 的掩码时,可以选择使用 -1 ^(-1<<n) 或者 (1<<n)-1,两种方式得到的结果是一样的,具体选择哪一种方式取决于个人喜好和代码实现的需要。